

Hive|Spark DDL语句 | ALTER 语法
*
– SQL Syntax – DDL Statements:SQL语法之DDL语句
–
+ 一、ALTER DATABASE
+
* ALTER PROPERTIES – 修改库属性
* ALTER LOCATION – 修改文件存储位置
+ 二、ALTER TABLE
+
* RENAME – 更改表名
* ADD COLUMNS – 增加字段
* DROP COLUMNS – 删除字段
* RENAME COLUMN – 修改字段
* ALTER OR CHANGE COLUMN – 修改字段
* REPLACE COLUMNS – 替换字段
* ADD AND DROP PARTITION – 增删分区
* SET TABLE PROPERTIES – 设置属性
* SET SERDE – 设置序列化方式
* SET LOCATION And SET FILE FORMAT – 设置文件存储路径及文件格式化
* MSCK TABLE – 修复分区
+ 三、ALTER VIEW
SQL Syntax – DDL Statements:SQL语法之DDL语句
DDL语句主要用于创建或修改数据库中数据库对象的结构
一、ALTER DATABASE
ALTER DATABASE 语句更改数据库的属性或位置
注意,DATABASE、SCHEMA 和 NAMESPACE 的用法是可以互换的,并且可以用一个来代替其他的,如果在系统中找不到数据库,则会发出错误消息
ALTER PROPERTIES – 修改库属性
ALTER DATABASE SET DBPROPERTIES 语句更改与数据库关联的属性。 指定的属性值会覆盖具有相同属性名称的任何现有值。 此命令主要用于记录数据库的元数据,并可用于审计目的
语法介绍
ALTER { DATABASE | SCHEMA | NAMESPACE } database_name
SET { DBPROPERTIES | PROPERTIES } ( property_name = property_value [ , ... ] )
使用示例
CREATE DATABASE inventory;
ALTER DATABASE inventory SET DBPROPERTIES ('Edited-by' = 'John', 'Edit-date' = '01/01/2001');



ALTER LOCATION – 修改文件存储位置
ALTER DATABASE SET LOCATION 语句更改将为数据库添加新表的默认父目录
注意,它不会将数据库当前目录的内容移动到新指定的位置或更改与指定数据库下的任何表/分区关联的位置(自 Spark 3.0.0 和 Hive 元存储版本 3.0.0 及更高版本起可用 )
语法介绍
ALTER { DATABASE | SCHEMA | NAMESPACE } database_name
SET LOCATION 'new_location'
使用示例
ALTER DATABASE inventory SET LOCATION 'file:/user/hive/warehouse/new_inventory.db';
DESCRIBE DATABASE EXTENDED inventory;
二、ALTER TABLE
ALTER TABLE 语句更改表的结构或属性
RENAME – 更改表名
ALTER TABLE RENAME TO 语句更改数据库中现有表的表名
注意,table rename 命令不能用于在数据库之间移动表,只能重命名同一数据库中的表
如果表被缓存,命令清除表的缓存数据。 下次访问该表时,缓存将被延迟填充。 此外:
1. table rename 命令取消缓存所有表的依赖项,例如引用该表的视图,依赖项应再次显式缓存
2. 分区重命名命令清除所有表依赖项的缓存,同时将它们保持为缓存状态。 因此,下次访问它们时,它们的缓存将被延迟填充
使用语法
ALTER TABLE table_identifier RENAME TO table_identifier
ALTER TABLE table_identifier partition_spec RENAME TO partition_spec
参数说明
指定表名,可以选择用数据库名进行限定,示例: [ database_name. ] table_name
要重命名的分区,请注意,可以在分区规范中使用类型化文字(例如,日期'2019-01-02'),示例: PARTITION ( partition_col_name = partition_col_val [ , ... ] )
使用示例
ALTER TABLE customer RENAME TO customer_info;
ALTER TABLE test.customer_info PARTITION (state='AZ',city='Peoria') RENAME TO PARTITION (state='AZ',city='Payson');


ADD COLUMNS – 增加字段
向已有的表中增加字段
使用语法
ALTER TABLE table_identifier ADD COLUMNS ( col_spec [ , ... ] )
参数说明
指定表名,可以选择用数据库名进行限定
要增加的字段信息
使用示例
ALTER TABLE customer_info ADD columns (age int comment '年龄');
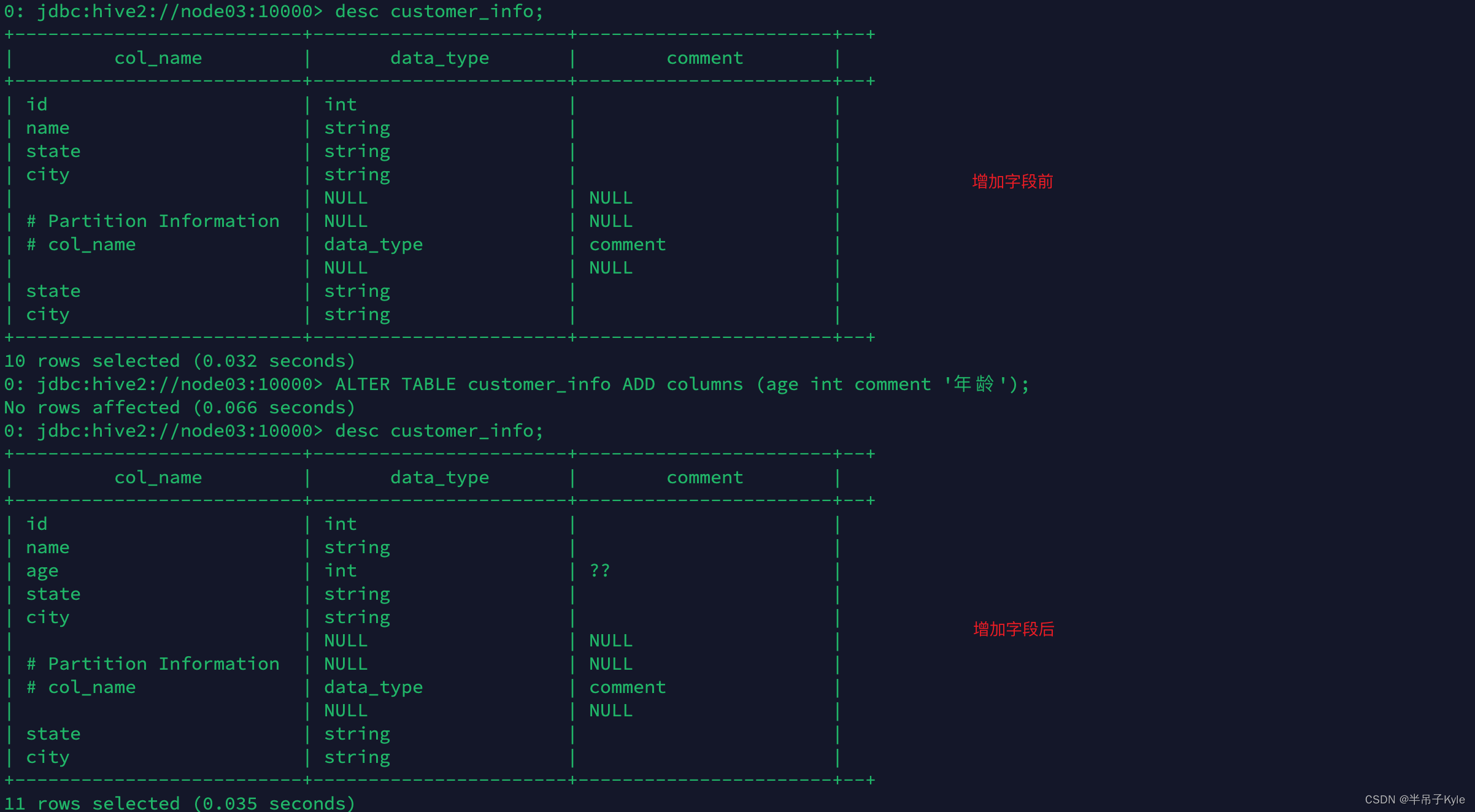
注意:如果是分区表,新增加字段后插数可能会出现字段为
NULL 的情况,解决方案请查看这篇博客
DROP COLUMNS – 删除字段
ALTER TABLE DROP COLUMNS 语句从现有表中删除指定的列
注意,仅 v2 表支持此语句(SPARK 2.x以上版本)
使用语法
ALTER TABLE table_identifier DROP { COLUMN | COLUMNS } [ ( ] col_name [ , ... ] [ ) ]
使用示例
ALTER TABLE customer_info DROP columns (age);
RENAME COLUMN – 修改字段
ALTER TABLE RENAME COLUMN 语句更改现有表的列名
注意,仅 v2 表支持此语句(SPARK 2.x以上版本)
语法介绍
ALTER TABLE table_identifier RENAME COLUMN col_name TO col_name
语法示例
ALTER TABLE customer_info RENAME COLUMN age TO age_info;
ALTER OR CHANGE COLUMN – 修改字段
ALTER TABLE ALTER COLUMN 或 ALTER TABLE CHANGE COLUMN 语句更改列的定义
注意,仅HIVE ON SPARK支持此语句
语法介绍
ALTER TABLE table_identifier { ALTER | CHANGE } [ COLUMN ] col_name alterColumnAction
语法示例
ALTER TABLE customer_info ALTER COLUMN name COMMENT 'customer name info';
REPLACE COLUMNS – 替换字段
ALTER TABLE REPLACE COLUMNS 语句删除所有现有列并添加新的列集
注意,仅 v2 表支持此语句(SPARK 2.x以上版本)
语法介绍
ALTER TABLE table_identifier [ partition_spec ] REPLACE COLUMNS
[ ( ] qualified_col_type_with_position_list [ ) ]
参数介绍
指定表名,可以选择用数据库名进行限定
要更换的分区。 请注意,可以在分区规范中使用类型化文字(例如,日期'2019-01-02'),例如, PARTITION ( partition_col_name = partition_col_val [ , ... ] )
要增加的字段列表,例如, col_name col_type [ col_comment ] [ col_position ] [ , ... ]
使用示例
CREATE TABLE IF NOT EXISTS customer_info
(
user_id string COMMENT '用户ID'
,user_name string COMMENT '用户姓名'
,user_age int COMMENT '用户年龄'
)
COMMENT '客户信息表'
PARTITIONED BY (ds STRING COMMENT'分区')
;
INSERT INTO customer_info partition(ds = '20220223') VALUES('001', 'kyle', 23),('002', 'jack', 24);
INSERT INTO customer_info partition(ds = '20220224') VALUES('003', 'lisa', 23);
ALTER TABLE customer_info REPLACE COLUMNS (ecif string, name string COMMENT 'new comment', age_info int);

ALTER TABLE customer_info REPLACE COLUMNS (user_id string);
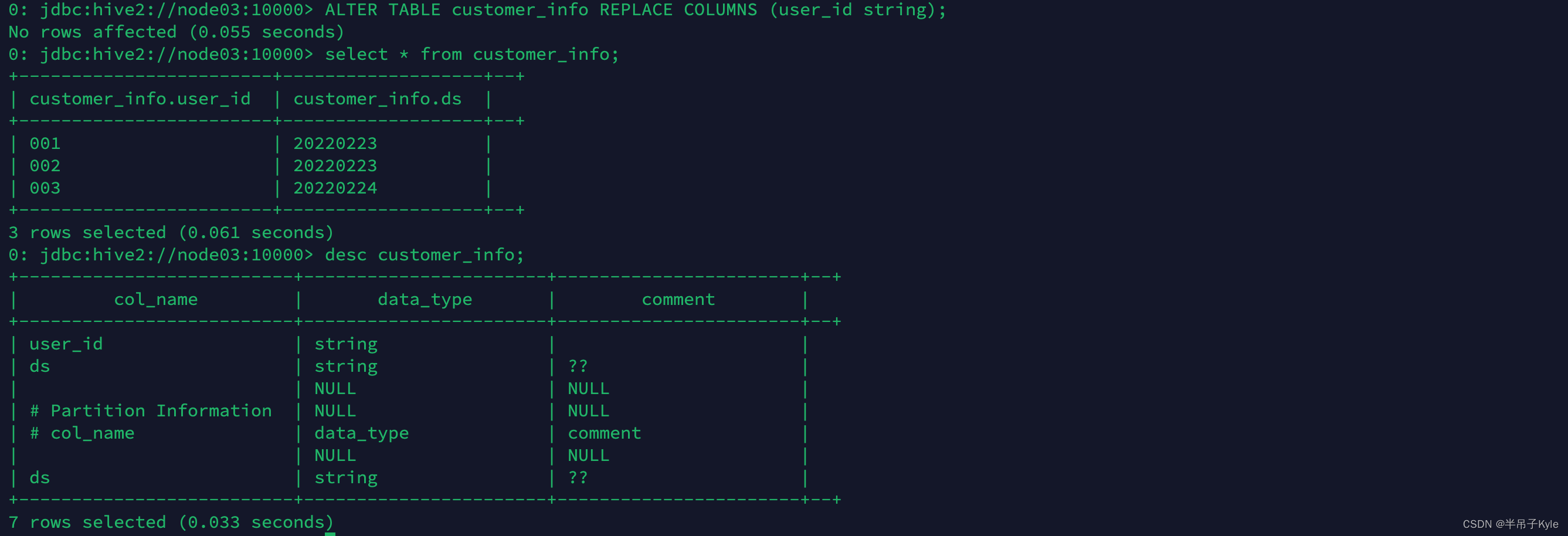
ADD AND DROP PARTITION – 增删分区
ALTER TABLE ADD 该语句用于向表中增加分区
如果表被缓存,则该命令清除表的缓存数据及其引用它的所有依赖项,下次访问表或依赖项时,缓存将被延迟填充
语法介绍
ALTER TABLE table_identifier ADD [IF NOT EXISTS] ( partition_spec [ partition_spec ... ] )
ALTER TABLE table_identifier DROP [ IF EXISTS ] partition_spec [PURGE]
SET TABLE PROPERTIES – 设置属性
ALTER TABLE SET 命令用于设置表属性,如果已经设置了特定属性,则会用新值覆盖旧值
语法说明
ALTER TABLE table_identifier SET TBLPROPERTIES ( key1 = val1, key2 = val2, ... )
ALTER TABLE table_identifier UNSET TBLPROPERTIES [ IF EXISTS ] ( key1, key2, ... )
语法示例
ALTER TABLE customer_info SET TBLPROPERTIES ('winner' = 'loser');
ALTER TABLE customer_info SET TBLPROPERTIES ('comment' = 'A table comment.');
ALTER TABLE customer_info SET TBLPROPERTIES ('comment' = 'This is a new comment.');
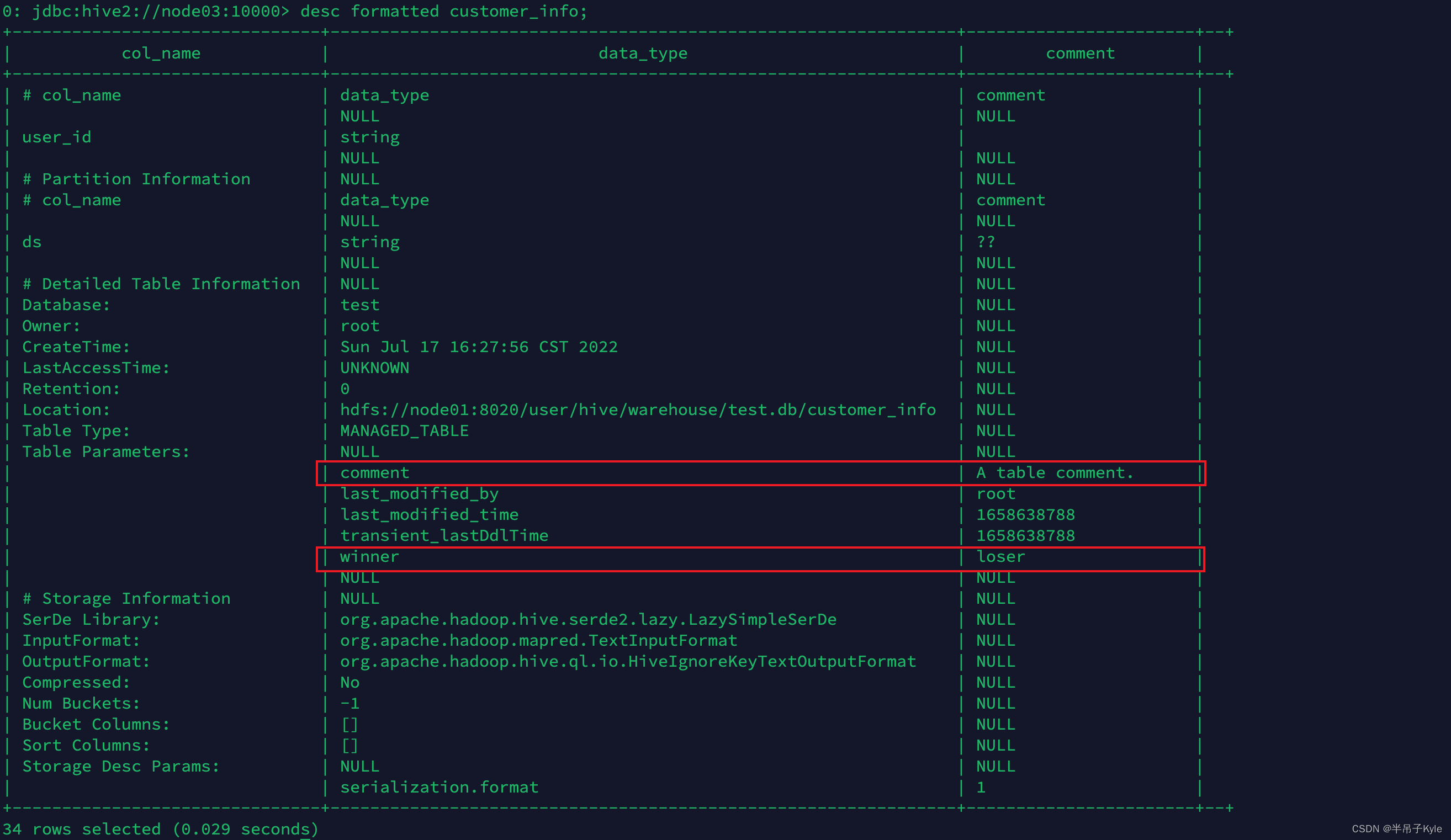
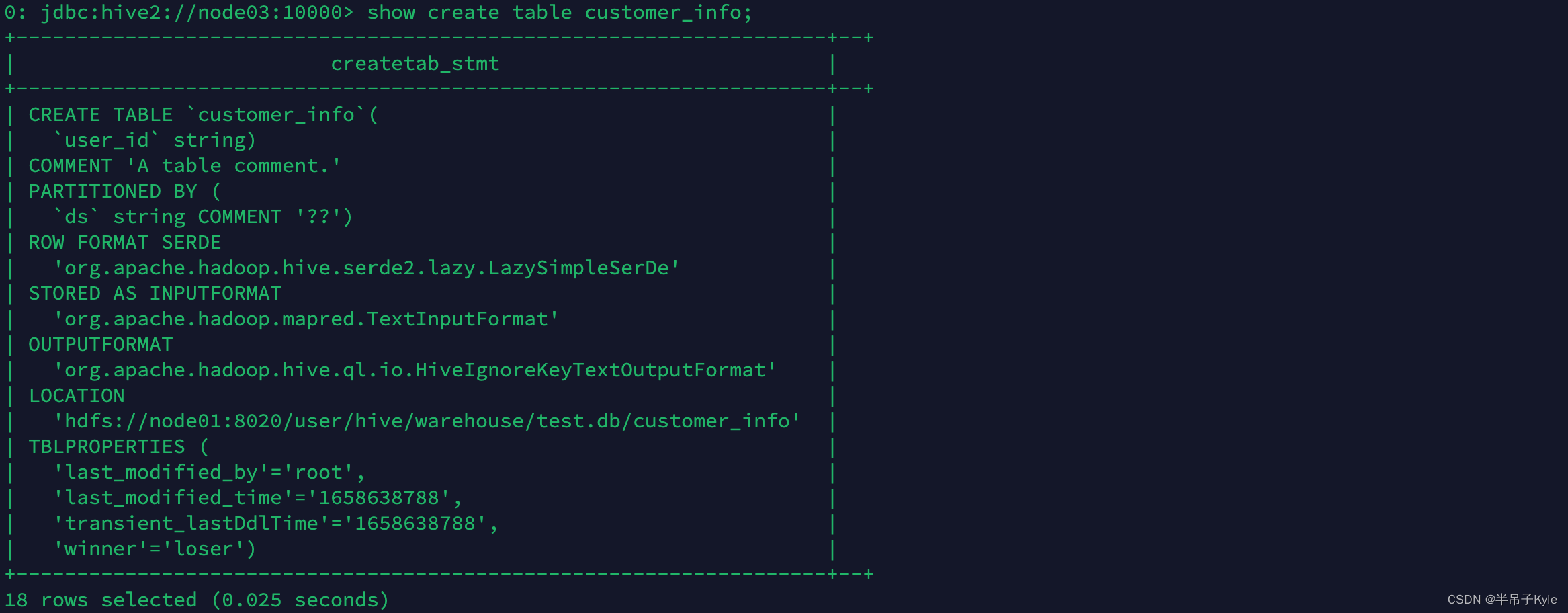
sql'
-- 移除 'winner' 属性
ALTER TABLE customer_info UNSET TBLPROPERTIES ('winner');</p>
<pre><code>

##### SET SERDE - 设置序列化方式
ALTER TABLE SET 命令用于设置 Hive 表中的 SERDE 或 SERDE 属性,如果已经设置了特定属性,则会用新值覆盖旧值
**语法介绍**
ALTER TABLE table_identifier [ partition_spec ]
SET SERDEPROPERTIES ( key1 = val1, key2 = val2, … )
ALTER TABLE table_identifier [ partition_spec ] SET SERDE serde_class_name
[ WITH SERDEPROPERTIES ( key1 = val1, key2 = val2, … ) ]
语法示例
ALTER TABLE test_tab SET SERDE 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe';
ALTER TABLE dbx.tab1 SET SERDE 'org.apache.hadoop' WITH SERDEPROPERTIES ('k' = 'v', 'kay' = 'vee')
SET LOCATION And SET FILE FORMAT – 设置文件存储路径及文件格式化
语法介绍
ALTER TABLE SET 命令还可用于更改现有表的文件位置和文件格式
注意,如果表被缓存,则 ALTER TABLE SET LOCATION 命令清除表的缓存数据及其引用它的所有依赖项,下次访问表或依赖时,缓存将被延迟填充
ALTER TABLE table_identifier [ partition_spec ] SET FILEFORMAT file_format
ALTER TABLE table_identifier [ partition_spec ] SET LOCATION 'new_location'
语法示例
ALTER TABLE customer_info SET fileformat orc;
ALTER TABLE customer_info partition (month=2, day=2) SET fileformat parquet;
ALTER TABLE customer_info PARTITION (a='1', b='2') SET LOCATION '/path/to/part/ways'
FILEFORMAT 的类型有这些:

Hive LanguageManual+DDL CREATE TABLE
MSCK TABLE – 修复分区
Hive 会将分区列表存储到元数据中,但是,如果新分区直接添加到 HDFS(例如通过使用 hadoop fs -put 命令)或从 HDFS 中删除,除非用户运行 ALTER TABLE table_name ADD/DROP PARTITION命令对每一个分区进行处理 ,否则元数据(以及 Hive)将不会知道这些分区信息的更改
语法介绍
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
ALTER TABLE table_identifier RECOVER PARTITIONS
语法示例
MSCK TABLE customer_info ADD PARTITIONS;
① 我们先来看一个表底下有哪些分区
show partitions customer_info;

② 通过
HDFS 命令创建 ds=20220225 文件夹,并复制 ds=20220223 分区的文件到 ds=20220225(模拟直接上传文件到表目录下)
dfs -mkdir /user/hive/warehouse/test.db/customer_info/ds=20220225;
dfs -cp /user/hive/warehouse/test.db/customer_info/ds=20220223/000000_0 /user/hive/warehouse/test.db/customer_info/ds=20220225;
③ 此时查看分区,发现并没有 ds=20220225 分区

④ 检查分区
MSCK REPAIR TABLE customer_info;
说明:题主用的版本是 hive-2.1.0 ,发现使用该命令后报错,后来 google 了下,发现是 2.1.0 的 bug,在 2.1.1 修复,很遗憾没有验证该功能,不过可以参考其他网友的示例
三、ALTER VIEW
ALTER VIEW 语句可以更改与视图关联的元数据,可以更改视图的定义,将视图的名称更改为不同的名称,通过设置 TBLPROPERTIES 设置和取消设置视图的元数据
Original: https://blog.csdn.net/hell_oword/article/details/125711132
Author: 半吊子Kyle
Title: 彻底搞懂 Hive|Spark DDL语句 | ALTER 语法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/818281/
转载文章受原作者版权保护。转载请注明原作者出处!