

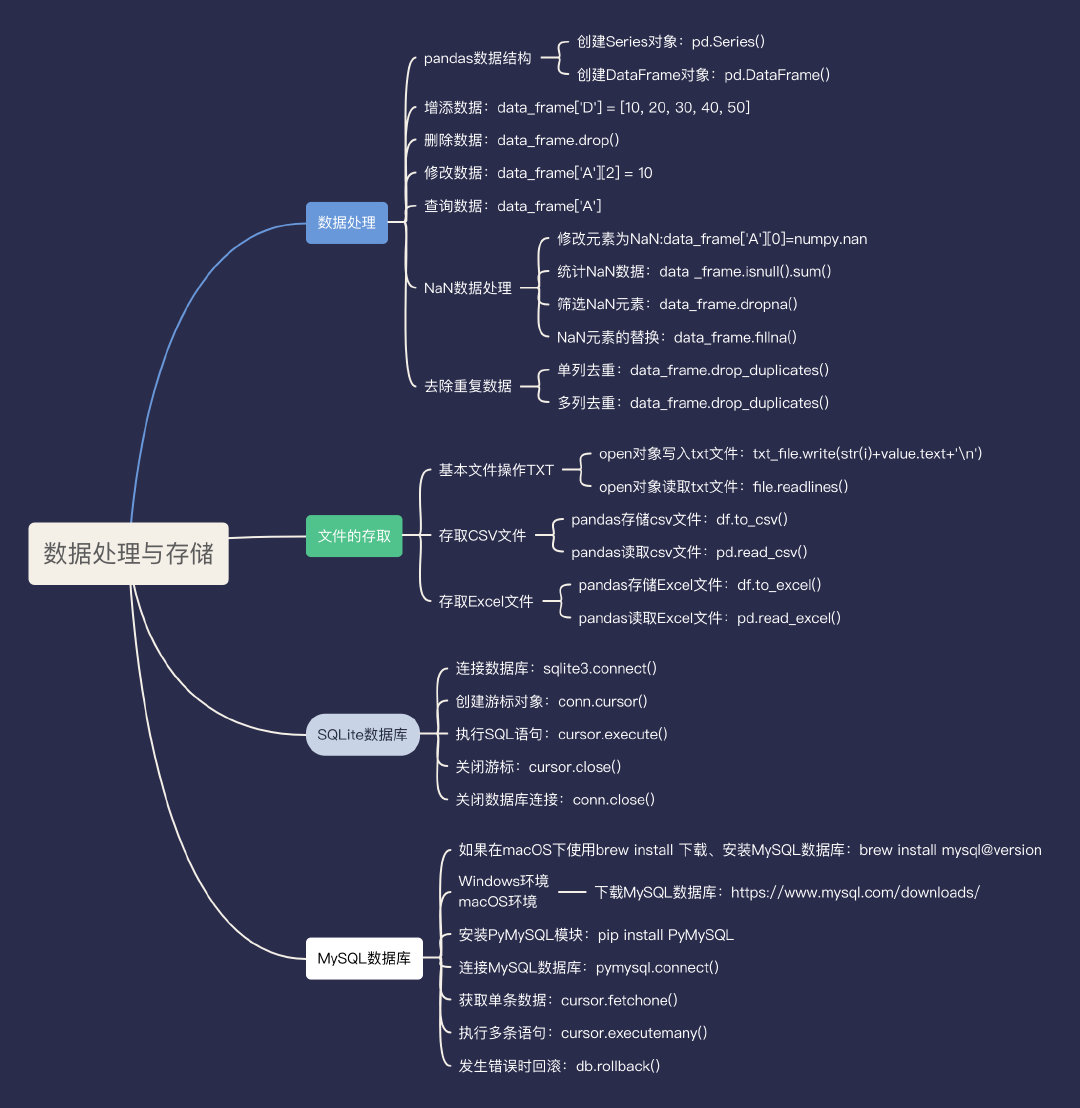
Python爬虫-数据处理与存储
数据处理
可以使用pandas模块来实现数据处理,pandas是一个开源的并且通过BSD许可的库。它主要为Python语言提供高性能、易于使用数据结构和数据分析工具,此外还提供了多种数据操作和数据处理方法。由于pandas是第三方模块所以在使用前需要安装并导入该模块。
pandas 数据结构
pandas的数据结构中有两大核心,分别是Series与DataFrame。 其中Series是一维数组,它与Python中基本数据结构List相近。Series可以保存多种数据类型的数据,如布尔值、字符串、数字类型等。DataFrame是一种表格形式的数据结构,类似于Excel表格,是一种二维的表格型数据结构。
1.Series对象
§ 创建Series对象
在创建Series对象时,只需要将数组形式的数据传入Series()构造函数中即可。示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
series = pd.Series(data)
print(series)
程序运行结果如下:
0 A
1 B
2 C
dtype: object
Process finished with exit code 0
说 明
在上述程序的运行结果中,左侧数字列为索引列,右侧字母列为索引对应的元素。Series对象在没有指定索引时,将默认生成从0开始依次递增的索引值。
§ 在创建Series对象时,是可以指定索引名称的,例如指定索引项为a、b、c。示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
index = ['a', 'b', 'c']
series = pd.Series(data, index=index )
print(series)
程序运行结果如下:
a A
b B
c C
dtype: object
Process finished with exit code 0
§ 访问数据
在访问Series对象中的数据时,可以单独访问索引数组或者元素数组。示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
index = ['a', 'b', 'c']
series = pd.Series(data, index=index )
print('索引数组为:', series.index)
print('元素数组为:', series.values)
程序运行结果为:
索引数组为: Index(['a', 'b', 'c'], dtype='object')
元素数组为: ['A' 'B' 'C']
Process finished with exit code 0
当需要获取指定下标的数组元素时,可以直接通过”Series对象[下标]”的方式进行数组元素的获取,数组下标从0开始。示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
index = ['a', 'b', 'c']
series = pd.Series(data, index=index )
print('指定下标的数组元素为:', series[1])
print('指定索引的数组元素为:', series['a'])
程序运行结果如下:
指定下标的数组元素为: B
指定索引的数组元素为: A
Process finished with exit code 0
当需要获取多个下标对应的Series对象时,可以指定下标范围,示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
index = ['a', 'b', 'c']
series = pd.Series(data, index=index)
print('获取多个下标对应的Series对象:')
print(series[0:3])
程序运行结果如下:
获取多个下标对应的Series对象:
a A
b B
c C
dtype: object
Process finished with exit code
除了通过指定下标范围的方式获取Series对象之外,还可以通过指定多个索引的方式获取Series对象。示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
index = ['a', 'b', 'c']
series = pd.Series(data, index=index)
print('获取多个索引对应的Series对象:')
print(series[['a', 'b']])
程序运行结果如下:
获取多个索引对应的Series对象:
a A
b B
dtype: object
Process finished with exit code 0
§ 修改元素值
修改Series对象的元素值时,同样可以通过指定下标或者指定索引的方式来实现。示例代码如下:
import pandas as pd
data = ['A', 'B', 'C']
index = ['a', 'b', 'c']
series = pd.Series(data, index=index )
series[0] = 'D'
print('修改下标为0的元素值:\n')
print(series)
series['b'] = 'A'
print('修改索引为b的元素值:')
print(series)
程序运行结果如为:
修改下标为0的元素值:
a D
b B
c C
dtype: object
修改索引为b的元素值:
a D
b A
c C
dtype: object
Process finished with exit code 0
2. DataFrame对象
在创建DataFrame对象时,需要通过字典来实现。其中每列的名称为键,而每个键对应的是一个数组,这个数组作为值。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
print(data_frame)
程序运行结果如下:
A B C
0 1 6 11
1 2 7 12
2 3 8 13
3 4 9 14
4 5 10 15
Process finished with exit code 0
说 明
上面运行结果中看到,左侧单独的数字(0-4)为索引列,在没有指定特定的索引时,DataFrame对象默认的索引将从0开始递增。右侧A、B、C列名为键,列名对应的值为数组。
DataFrame对象同样可以单独指定索引名称,指定方式与Series对象类似,示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
index = ['a', 'b', 'c', 'd', 'e']
data_frame = pd.DataFrame(data, index = index)
print(data_frame)
程序运行结果如下:
A B C
a 1 6 11
b 2 7 12
c 3 8 13
d 4 9 14
e 5 10 15
Process finished with exit code 0
如果数据中含有不需要的数据列时,可以在创建DataFrame对象时指定需要的数据列名。示例代码如如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data, columns=['B', 'C'])
print(data_frame)
程序运行结果如下:
B C
0 6 11
1 7 12
2 8 13
3 9 14
4 10 15
Process finished with exit code 0
数据的增、删、改、查
1. 增添数据
当为DataFrame对象添加一列数据时,可以先创建列名,然后为其赋值数据。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['D'] = [10, 20, 30, 40, 50]
print(data_frame)
程序运行结果如下:
A B C D
0 1 6 11 10
1 2 7 12 20
2 3 8 13 30
3 4 9 14 40
4 5 10 15 50
Process finished with exit code 0
2. 删除数据
pandas 模块中提供了drop()函数,用于删除DataFrame对象中的某行或某列数据,该函数提供了多个参数,其中比较常用的参数及含义如下表所示:
drop()函数常用参数及含义
参 数 名含 义labels需要删除的行或列的名称,接收string或arrayaxis默认为0,表示删除行,当axis = 1时表示删除列index指定需要删除的行columns指定需要删除的列inplace设置为False表示不改变原数据,返回一个执行删除后的新DataFrame对象;设置为True将对原数据进行删除操作
实现删除DataFrame对象原数据中指定列与索引的行数据。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame.drop([0], inplace=True)
data_frame.drop(labels='A', axis=1, inplace=True)
print(data_frame)
程序运行结果如下:
B C
1 7 12
2 8 13
3 9 14
4 10 15
Process finished with exit code 0
补 充
在实现删除DataFrame对象中指定列名的数据时,也可以通过del关键字来实现,例如删除原来数据中列名为A的数据,可以用del data_frame[‘A’]代码
drop()函数除了可以删除指定的列或者行数据以外,还可以通过指定行索引的范围,实现删除多行数据的功能。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame.drop(labels=range(0, 3), axis=0, inplace=True)
print(data_frame)
程序运行结果如下:
A B C
3 4 9 14
4 5 10 15
Process finished with exit code 0
3. 修改数据
当需要修改DataFrame对象中某一列的某个元素时,可以通过赋值的方式来进行元素的修改。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['A'][2] = 10
print(data_frame)
程序运行结果如下:
A B C
0 1 6 11
1 2 7 12
2 10 8 13
3 4 9 14
4 5 10 15
Process finished with exit code 0
在修改DataFrame对象中某一列的所有数据时,需要了解当前修改列名所对应的元素数组中包含的元素个数,然后根据原有元素的个数进行对应元素的修改。代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['B'] = [5, 4, 3, 2, 1]
print(data_frame)
程序运行结果如下:
A B C
0 1 5 11
1 2 4 12
2 3 3 13
3 4 2 14
4 5 1 15
Process finished with exit code 0
注 意
当修改B列中的所有数据且修改的元素数量与原有的元素数了不匹配时,将报错。
说 明
将某一列赋值为单个元素时,例如,data_frame[‘B’] = 1, 此时B列所对应的数据将都被修改为1
data_frame['B'] = 1
结果如下:
A B C
0 1 1 11
1 2 1 12
2 3 1 13
3 4 1 14
4 5 1 15
Process finished with exit code 0
4.查询数据
在获取DataFrame对象中某一列数据时,可以通过直接指定列名或者直接调用列名属性的方式来获取指定列的数据。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
print('指定列名的数据为:\n', data_frame['A'])
print('指定列名属性的数据为:\n', data_frame.B)
程序运行结果如下:
指定列名的数据为:
0 1
1 2
2 3
3 4
4 5
Name: A, dtype: int64
指定列名属性的数据为:
0 6
1 7
2 8
3 9
4 10
Name: B, dtype: int64
Process finished with exit code 0
在获取DataFrame对象从第1行至第3行范围内的数据时,可以通过指定索引范围的方式来获取数据,行索引从0开始,行索引0对应的是DataFrame对象中的第1行数据。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
print('指定行索引范围的数据:\n', data_frame[0:3])
程序运行结果如下:
指定行索引范围的数据:
A B C
0 1 6 11
1 2 7 12
2 3 8 13
Process finished with exit code 0
说 明
在获取指定行索引范围的示例代码中,0为起始行索引,3为结束行索引的位置,所以此次获取内容并不包含行索引为3的数据。
在获取DataFrame对象中某一列的某个元素时,可以通过依次指定列名称、行索引的方式来进行数据的获取。示例代码如下:
import pandas as pd
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
print('获取指定列中的某个数据:\n', data_frame['B'][2])
程序运行结果如下:
获取指定列中的某个数据:
8
Process finished with exit code 0
NaN数据处理
1.修改元素为NaN
NaN数据在numpy模块中表示空缺数据,所以在数据分析中偶尔会需要将数据结构中的某个元素修改为NaN值,这时只需要调用numpy.NaN,为需要修改的元素赋值即可实现修改元素的目的。示例代码如下:
import pandas as pd, numpy
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['A'][0] = numpy.nan
print(data_frame)
程序运行结果如下:
A B C
0 NaN 6 11
1 2.0 7 12
2 3.0 8 13
3 4.0 9 14
4 5.0 10 15
Process finished with exit code 0
2.统计NaN数据
pandas模块提供了两个可以快速识别空缺值的方法,isnull()方法用于判断数值是否为空缺值,如果是空缺值将返回True。notnull()方法用于识别非空缺值,该方法在检测出不是空缺值的数据时将返回True。通过这两个方法与统计函数sum()方法即可获取数据中空缺值与非空缺值的具体数量。示例代码如下:
import pandas as pd, numpy
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['A'][0] = numpy.nan
print('每列空缺值数量为:\n', data_frame.isnull().sum())
print('每列非空缺值数量为:\n', data_frame.notnull().sum())
程序运行结果如下:
每列空缺值数量为:
A 1
B 0
C 0
dtype: int64
每列非空缺值数量为:
A 4
B 5
C 5
dtype: int64
Process finished with exit code 0
3. 筛选NaN元素
在实现NaN元素的筛选时,可以使用dropna()函数,例如,将包含NaN元素所在的整行数据删除。示例代码如下:
import pandas as pd, numpy
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['A'][0] = numpy.nan
data_frame.dropna(axis=0, inplace=True)
print(data_frame)
程序运行结果如下:
A B C
1 2.0 7 12
2 3.0 8 13
3 4.0 9 14
4 5.0 10 15
Process finished with exit code 0
说 明
如果需要将数据中包含NaN元素所在的整列数据删除,可以将axis参数设置为1
dropna()函数提供了一个how参数,如果将该参数设置为all, dropna()函数将会删除某行或者是某列所有元素全部为NaN的值。示例代码如下:
import pandas as pd, numpy
data = {'A':[1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10],
'C':[11, 12, 13, 14, 15]}
data_frame = pd.DataFrame(data)
data_frame['A'][0] = numpy.nan
data_frame['A'][1] = numpy.nan
data_frame['A'][2] = numpy.nan
data_frame['A'][3] = numpy.nan
data_frame['A'][4] = numpy.nan
data_frame.dropna(how='all', axis=1,inplace=True)
print(data_frame)
程序运行结果如下:
B C
0 6 11
1 7 12
2 8 13
3 9 14
4 10 15
Process finished with exit code 0
说 明
因为axis的默认值0,所以只对行数据进行删除,而所有元素都为NaN的是列,所以在指定how参数时还需要指定删除目标列axis=1
4. NaN元素的替换
当处理数据中的NaN元素时,为了避免删除数据中比较重要的参考数据。可以使用fillna()函数将数据中NaN元素替换为同一个元素,这样在进行数据分析时,可以很清楚地知道哪些元素无用(即为NaN元素)。示例代码如下:
import pandas as pd
data = {'A':[1, None, 3, 4, 5],
'B':[6, 7, 8, None, 10],
'C':[11, 12, None, 14, None]}
data_frame = pd.DataFrame(data)
print('修改前的数据:\n', data_frame)
data_frame.fillna(0, inplace=True)
print('修改后代数据:\n', data_frame)
程序运行结果如下:
修改前的数据:
A B C
0 1.0 6.0 11.0
1 NaN 7.0 12.0
2 3.0 8.0 NaN
3 4.0 NaN 14.0
4 5.0 10.0 NaN
修改后代数据:
A B C
0 1.0 6.0 11.0
1 0.0 7.0 12.0
2 3.0 8.0 0.0
3 4.0 0.0 14.0
4 5.0 10.0 0.0
Process finished with exit code 0
去除重复数据
pandas模块提供的drop_duplicates()方法用于去除指定列中的重复数据。语法格式如下:
pandas.dataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
drop_duplicates()方法的常用参数及含义如下表:
drop_duplicates()方法中常用的参数及含义
参 数 名含 义subset表示指定需要去重的列名,也可以是多个列名组成的列表。默认None,表示全部列keep表示保存重复数据的哪一条数据,first表示保留第一条、last表示保留最后一条、False表示重复项数据都不留。默认firstinplace表示是否在原数据中进行操作,默认为False
在指定去除某一列中重复数据时,需要在subset参数位置指定列名。示例代码如下:
import pandas as pd
data = {'A':['A1','A1','A3'],
'B':['B1','B2','B1']}
data_frame = pd.DataFrame(data)
data_frame.drop_duplicates('A', inplace=True)
print(data_frame)
程序运行结果如下:
A B
0 A1 B1
2 A3 B1
Process finished with exit code 0
注 意
在去除DataFrame对象中的重复数据时,将会删除指定列中重复数据所对应整行数据。
说 明
drop_duplicates()方法除了删除DataFrame对象中的数据行以外,还可以对DataFrame对象中的某一列数据进行重复数据的删除。例如,删除DataFrame对象中A列内重复数据,可使用此行代码: new_data = data_frame[‘A’].drop_duplicates()
drop_duplicates()方法不仅可以实现DataFrame对象中单列的去重复操作,还可以实现多列的去重操作。示例代码如下:
import pandas as pd
data = {'A':['A1', 'A1', 'A1', 'A2', 'A2'],
'B':['B1', 'B1', 'B3', 'B4', 'B5'],
'C':['C1', 'C2', 'C3', 'C4', 'C5']}
data_frame = pd.DataFrame(data)
data_frame.drop_duplicates(subset=['A', 'B'], inplace=True)
print(data_frame)
程序运行结果如下:
A B C
0 A1 B1 C1
2 A1 B3 C3
3 A2 B4 C4
4 A2 B5 C5
Process finished with exit code 0
文件的存取
基本文件操作TXT
1. TXT文件存储
如果想要简单地进行TXT文件存储工作,可以通过open()函数操作文件实现,即需要先创建或者打开指定的文件并创建文件对象。open()函数的基本语法格式如下:
file = open(filename[, mode[,buffering]])
参数说明
§ file:被创建的文件对象
§ filename:要创建或打开文件的文件名称,需要使用单引号或双引号将其括起来。如果要打开的文件和当前文件在同一目录下,那么直接写文件名即可,否则需要指定完整路径。例如,要打开当前路径下的名称为status.txt的文件,可以使用”status.txt”。
§ mode:可选参数,用于指定文件的打开模式。其参数如下表。默认的打开模式为只读(即r)
mode参数的参数值说明
值说 明注 意r以只读模式打开文件。文件的指针将会放在文件的开头文件必须存在rb以二进制格式打开文件,并且采用只读模式。文件的指针将会放在文件的开头,一般用于非文本文件,如图片、声音等文件必须存在r+打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖)文件必须存在rb+以二进制格式打开文件,并且采用读写模式,文件的指针将会放在文件的开头,一般用于非文本文件、如图片、声音等文件必须存在w以只写模式打开文件文件存在,则将其覆盖,否则创建新文件wb以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等文件存在,则将其覆盖,否则创建新文件w+打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限文件存在,则将其覆盖,否则创建新文件wb+以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等文件存在,则将其覆盖,否则创建新文件 值说 明注 意a以追加模式打开一个文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于写入ab以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入已有内容之后),否则,创建新文件用于写入a+以读写模式打开文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写ab+以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写
§ buffering:可选参数,用于指定读写文件的缓冲模式,值为0表达式不缓存;值为1表示缓存;值大于1,则表示缓冲区的大小。默认为缓存模式。
以爬取某网页中的励志名句为例,首先通过requests发送网络请求,然后接收响应结果并通过BeautifulSoup解析HTML代码,接着提取所有信息,最后将信息逐条写入data.txt文件当中。示例代码如下:
import requests
from lxml import etree
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36"
}
for i in range(2):
url = f'http://quotes.toscrape.com/tag/inspirational/page/{i+1}/'
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
html = etree.HTML(resp.text)
text_all = html.xpath('//span[@class="text"]')
txt_file = open('data.txt', 'a', encoding='utf-8')
for i1, value in enumerate(text_all):
txt_file.write(str(i1)+value.text+'\n')
txt_file.close()
运行以上示例代码后,当前目录中将自动生成data.txt文件,打开文件如下图所示:
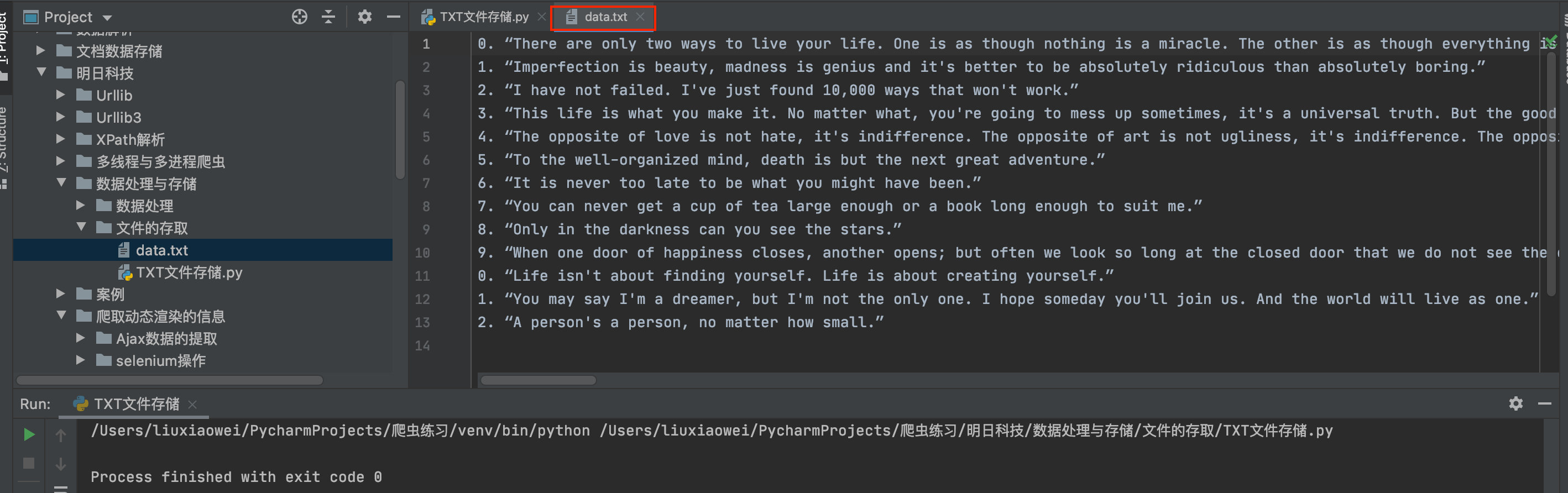

2. 读取TXT文件
在Python中打开TXT文件后,除了可以向其写入或追加内容,还可以读取文件中的内容。读取文件内容主要是分为以下几种情况。
§ 读取指定字符
文件对象提供了read()方法用于读取指定个数的字符。其语法格式如下:
file.read([size])
其中,file为打开的文件对象;size为可选参数,用于指定要读取的字符个数,如果省略则一次性读取所有内容。读取上例中的data.txt文件中的示例代码如下:
with open('data.txt', 'r') as f:
string = f.read(46)
print(string)
执行结果如下:
0. "There are only two ways to live your life.
Process finished with exit code 0
使用read()方法读取文件时,是从文件的开头读取的。如果想要读取部分内容,可以先使用文件对象的seek()方法将文件的指针移动到新的位置,然后再应用read()方法读取。seek()方法的基本语法格式如下:
file.seek(offset[,where])
参数说明:
- file:表示已经打开的文件对象
- offset:用于指定移动的字符个数,其具体位置与whence有关
- whence:用于指定从什么位置开始计算。值为0表示从文件头开始计算;1 表示从当前位置开始计算;2 表示从文件尾开始计算,默认为0
想要从文件的第49个字符开始读取38个字符,示例代码如下:
with open('data.txt', 'r') as f:
f.seek(49)
string = f.read(38)
print(string)
上面的程序执行结果如如下:
One is as though nothing is a miracle.
Process finished with exit code 0
说 明
使用seek()方法时,如果采用GBK编码,那么offset的值是按一个汉字(包括中文标点符号)占两个字符计算,而采用UTF-8编码,则一个汉字占3个字符,不过无论采用何种编码英文和数字都按一个字符计算的。这与read()方法不同。
§ 读取一行
在使用read()方法读取文件时,如果文件很大,一次读取全部内容到内存容易造成内存不足,所以通常会采用逐行读取。文件对象提供了readline()方法用于每次读取一行数据。readline()方法基本语法格式如下:
file.readline()
其中,file为打开的文件对象。同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写)。逐行读取Python经典应用文件,示例代码如下:
print("\n","="*20,"Python经典应用","="*20,"\n")
with open('message.txt','r') as file:
number = 0
while True:
number += 1
line = file.readline()
if line =='':
break
print(number,line,end= "\n")
print("\n","="*20,"over","="*20,"\n")
程序运行结果如下:
==================== Python经典应用 ====================
1 1 Zope :应用服务器
2 2 Plone :内容管里系统
3 3 Django :鼓励快速开发的Web应用框架
4 4 Python Wikipedia Robot Framework:MediaWiki的机器人程序
5 5 tornado :非阻塞式服务器
6 6 Reddit :社交分享网站
7 7 Dropbox :文件分享服务
8 8 Trac :使用Python编写的BUG管里系统
9 9 Blender :以C与Python开发的开源3D绘图软件
==================== over ====================
Process finished with exit code 0
§ 读取全部行
读取全部行的作用同调用readd()方法时不指定size类似,只不过读取全部行时,返回的是一个字符串列表,每个元素为文件的一行内容。读取全部行,使用的是文件对象的readlines()方法,其语法格式如下:
file.readlines()
其中,file为打开的文件对象。同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写),通过readlines()方法读取message.txt文件中的所有内容,并输出读取结果,代码如下:
print("\n","="*20,"Python经典应用","="*20,"\n")
with open('message.txt','r') as file:
message = file.readlines()
print(message)
print("\n","="*25,"over","="*25,"\n")
程序运行结果如下:
==================== Python经典应用 ====================
['1 Zope :应用服务器\n', '2 Plone :内容管里系统\n', '3 Django :鼓励快速开发的Web应用框架\n', '4 Python Wikipedia Robot Framework:MediaWiki的机器人程序\n', '5 tornado :非阻塞式服务器\n', '6 Reddit :社交分享网站\n', '7 Dropbox :文件分享服务\n', '8 Trac :使用Python编写的BUG管里系统\n', '9 Blender :以C与Python开发的开源3D绘图软件']
========================= over =========================
从该运行结果中可以看出readlines()方法的返回值为一个字符串列表。在这个字符串列表中,每个元素记录一行内容。如果文件比较大时,采用这种方法输出读取的文件内容会很慢。这时可以将列表的内容逐行输出。代码如下:
print("\n","="*20,"Python经典应用","="*20,"\n")
with open('message.txt','r') as file:
messageall = file.readlines()
for message in messageall:
print(message)
print("\n","="*25,"over","="*25,"\n")
程序运行结果如下:
==================== Python经典应用 ====================
1 Zope :应用服务器
2 Plone :内容管里系统
3 Django :鼓励快速开发的Web应用框架
4 Python Wikipedia Robot Framework:MediaWiki的机器人程序
5 tornado :非阻塞式服务器
6 Reddit :社交分享网站
7 Dropbox :文件分享服务
8 Trac :使用Python编写的BUG管里系统
9 Blender :以C与Python开发的开源3D绘图软件
========================= over =========================
Process finished with exit code 0
存取CSV文件
CSV文件是文本文件的一种,该文件中每一行数据的各元素使用逗号进行分隔。其实存取CSV文件时同样可以使用open()函数,不过还可以使用更好的办法,那就是使用pandas模块实现CSV文件的存取。
1.CSV文件的存储
Pandas提供了to_csv()函数用于实现CSV文件的存储,该函数中常用的参数及含义如下表:
to_csv()函数常用参数及含义
参 数 名含 义filepath_or_buffer表示文件路径的字符串sepstr类型,表示分隔符,默认为逗号”,”na_repstr类型,用于替换缺失值,默认为””空float_formatstr类型,指定浮点数据的格式,例如,’%.2f’表示保留两位小数columns表示指定写入哪列数据的列名,默认为Noneheader表示是否写入数据中的列名,默认为False,表示不写入index表示是否将行索引写入文件,默认为Truemodestr类型,表示写入模式默认为’w’encodigstr类型,表示写入文件的编码格式
例如,创建A,B,C三列数据,然后将数据写入CSV文件中,代码如下:
import pandas as pd
data = {'A':[1, 2, 3], 'B':[4, 5, 6], 'C':[7, 8, 9]}
df = pd.DataFrame(data)
df.to_csv('test.csv')
运行代码后, 文件夹目录中将自动生成一个test.csv文件,在Pycharm中打开该文件,将显示如下图所示内容:
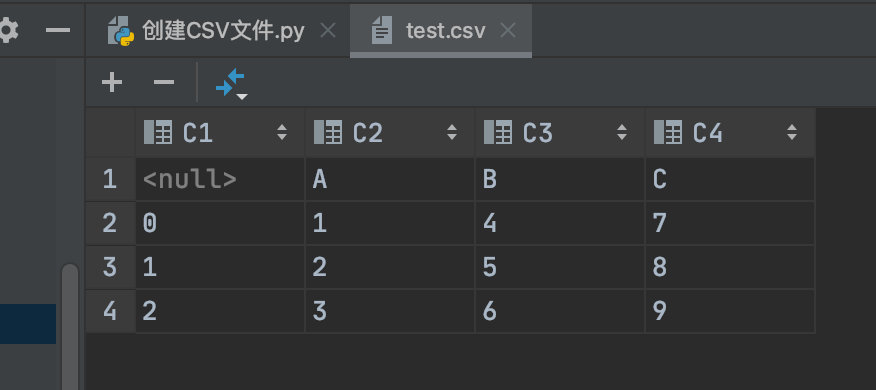
说 明
图中第一列数据为默认生成的索引列,在写入数据时如果不需要默认的索引列,可以在to_csv()函数中设置index参数为False即可。
2. CSV文件的读取
pandas模块提供了read_csv()函数用于CSV文件的读取工作。read_csv()函数中常用的参数及含义如下表:
read_csv()函数常用的参数及含义
参 数 名含 义filepath_or_buffer表示文件路径的字符串sepstr类型,表示分隔符,默认为逗号”,”header表示将哪一行数据作为列名index_col通过列索引指定列的位置,默认为Nonenames为读取后的数据设置列名,默认为Noneskiprowsint类型,需要跳过的行号,从文件内数据的开始处算起skipfooterint类型,需要跳过的行好,从文件内数据的末尾处算起na_values将指定的值设置为NaNnrowsint类型,设置需要读取数据中的前n行数据 参 数 名含 义encodingstr类型,用于设置文本编码格式。例如,”utf-8″表示UTF-8编码squeeze设置为True,表示如果解析的数据只包含一列,则返回一个Series。默认为Falseengine表示数据解析的引擎,可以指定为c或python,默认为c
在实现一个简单的读取CSV文件时,直接调用pandas.read_csv()函数,然后指定文件路径即可。示例代码如下:
import pandas as pd
data = pd.read_csv('test.csv')
print('读取的CSV文件内容为:\n', data)
程序运行结果如下:
读取的CSV文件内容为:
Unnamed: 0 A B C
0 0 1 4 7
1 1 2 5 8
2 2 3 6 9
Process finished with exit code 0
还可以将读取出来的数据指定列,写入到新的文件当中。示例代码如下:
import pandas as pd
data = pd.read_csv('test.csv')
data.to_csv('new_test.csv', columns=['B', 'C'], index=False)
new_data = pd.read_csv('new_test.csv')
print('读取新的csv文件内容为:\n', new_data)
程序运行结果如下:
读取新的csv文件内容为:
B C
0 4 7
1 5 8
2 6 9
Process finished with exit code 0
存取Excel文件
1. Excel文件的存储
Excel文件是一种大家都比较熟悉的常用办公表格文件,是微软公司推出的办公软件中的一个组件。Excel文件的扩展名目前两种,一种为.xls,另一种为.xlsx,其扩展名主要根据办公软件版本决定。
通过DataFrame的数据对象直接调用to_excel()方法即可实现Excel文件的写入功能,该方法的参数含义与to_csv()方法类似。通过to_excel()方法向Excel文件写入信息的代码如下:
import pandas as pd
data = {'A':[1, 2, 3],'B':[4, 5, 6], 'C':[7, 8, 9]}
df = pd.DataFrame(data)
df.to_excel('test.xlsx')
2. Excel文件的读取
pandas 模块的read_excel()函数用于Excel文件的读取,该函数中常用的参数及含义如下表:
read_excel()函数常用参数及含义
参 数 名含 义io表示文件路径的字符串sheet_name表示指定Excel文件内的分表位置,返回多表可以使用sheet_name=[0,1],默认为0header表示指定哪一行数据作为列名,默认为0skiprowsint类型,需要跳过的行号,从文件内数据的开始处算起skip footerint类型,需要跳过的行好,从文件内数据的末尾处算起index_col通过列索引指定列的位置,默认为Nonenames指定列的名字
在没有特殊情况下,读取Excel文件内容与读取CSV文件内容相同,直接调用pandas.read_excel()函数即可。示例代码如下:
import pandas as pd
data = pd.read_excel('test.xlsx')
print('读取的Excel文件内容为:\n', data)
程序运行结果如下:
读取的Excel文件内容为:
Unnamed: 0 A B C
0 0 1 4 7
1 1 2 5 8
2 2 3 6 9
Process finished with exit code 0
SQLite数据库
与许多其他数据库管理系统不同,SQLite不是一个客户端/服务器结构的数据库引擎,而是一种 嵌入式数据库,它的数据库就是一个文件。SQLite将整个数据库,包括定义、表、索引以及数据本身,作为一个单独的、可跨平台使用的文件存储在主机中。由于SQLite本身是C语言编写的,而且体积很小,所以经常被集成到各种应用程序中。Python就内置了SQLite3,所以,在Python中使用SQLite数据库,不需要安装任何模块,可以直接使用。
创建数据库文件
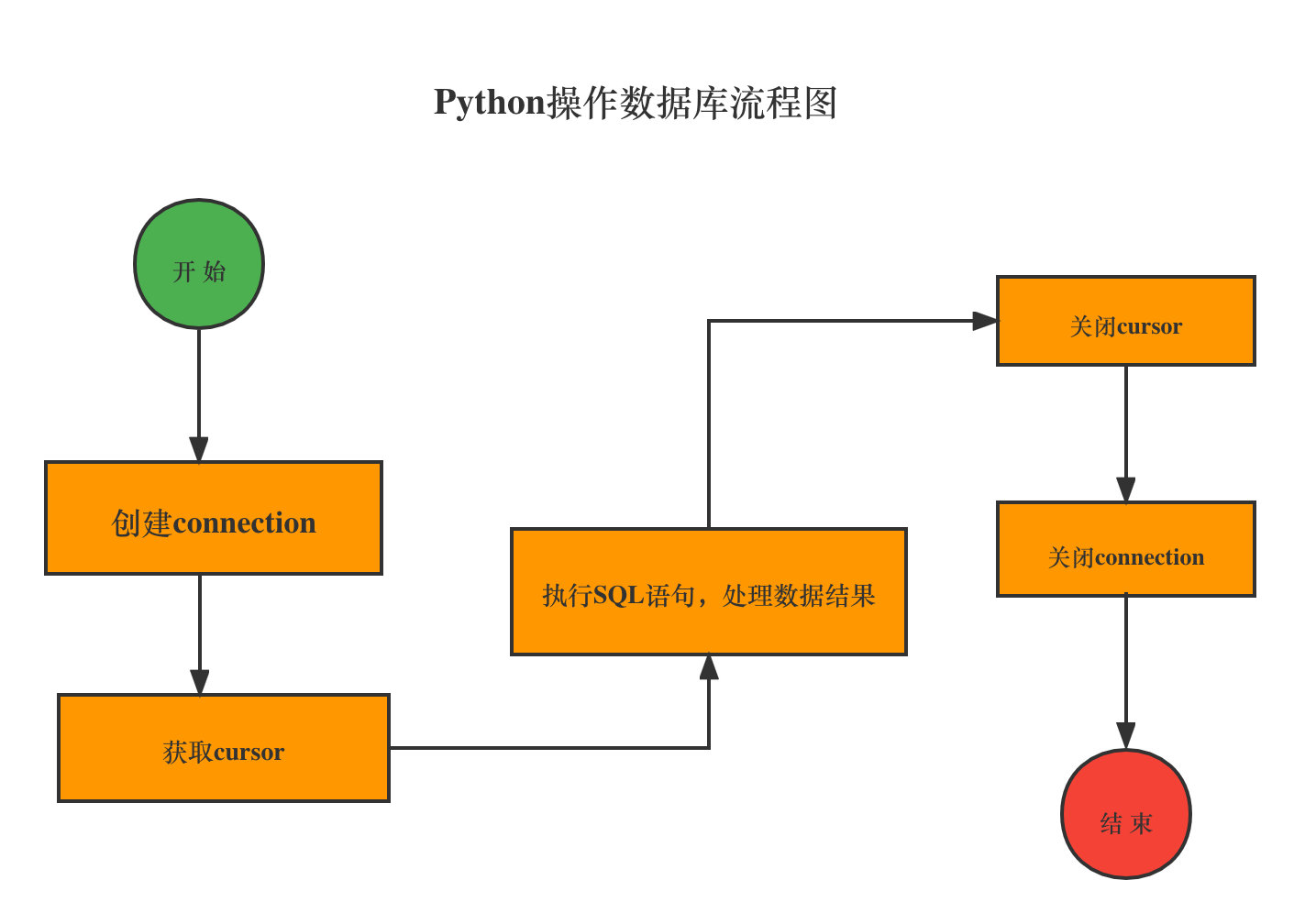
由于Python中已经内置了SQLite3, 所以可以直接使用import语句导入SQLite3模块。Python操作数据库的通用的流程如图所示:
例如,创建一个名称为mySoft.db的SQLite数据库文件,然后执行SQL语句创建一个user(用户表),user表包含id和name两个字段,示例代码如下:
import sqlite3
conn = sqlite3.connect('mySoft.db')
cursor = conn.cursor()
cursor.execute('create table user(id int(10) primary key, name varchar(20))')
cursor.close()
conn.close()
说 明
上面代码只能运行一次,再次运行时,会提示错误信息:sqlite3.OperationalError:table user already exists。这是因为user表已经存在
操作SQLite
1. 新增用户数据信息
为了向数据表中新增数据,可以使用如下SQL语句:
insert into 表名(字段名1, 字段名2,....,字段名n) values(字段值1, 字段值2,.....,字段值n)
例如,在user表中有2个字段,字段名分别为id和name。而 字段值需要根据字段的数据类型来赋值,例如,id是一个长度为10的整型,name是长度为20的字符串型数据。向user表中插入3条用户信息记录,SQL语句如下:
import sqlite3
conn = sqlite3.connect('mySoft.db')
cursor = conn.cursor()
cursor.execute('create table user (id int(10) primary key, name varchar(20))')
cursor.execute('insert into user (id, name) values("1", "Bruce_liu")')
cursor.execute('insert into user (id, name) values("2", "Andy")')
cursor.execute('insert into user (id, name) values("3", "光辉岁月")')
cursor.commit()
cursor.close()
conn.close()
2. 查看用户数据信息
查找user表中的数据可以使用如下SQL语句:
selec 字段名1, 字段名2, 字段名3,.... from 表名 where 查询条件
查看用户信息的代码与插入数据信息的代码大致相同,不同之处在于使用的SQL语句不同。此外,查询数据时通常使用如下3种方式:
§ fetching():获取查询结果集中的下一条记录
§ fetch many(size):获取指定数量的记录
§ fetch all():获取结果集的所有记录
下面通过示例来练习这3种查询方式的区别:
例如,分别使用fetchone()、fetch many(size)、fetchall()这3种方式查询用户信息,代码如下:
import sqlite3
conn = sqlite3.connect('mySoft.db')
cursor = conn.cursor()
cursor.execute('select * from user')
result1 = cursor.fetchone()
print(result1)
result2 = cursor.fetchmany(2)
print(result2)
result3 = cursor.fetchall()
print(result3)
cursor.close()
conn.close()
程序运行结果如下:
(1, 'Bruce_liu')
[(2, '小薇'), (3, '海阔天空')]
[(1, 'Bruce_liu'), (2, '小薇'), (3, '海阔天空')]
修改上面代码为条件查询,示例如下:
cursor.execute('select * from user where id > ?', (1, ))
result3 = cursor.fetchall()
print(result3)
程序运行结果如下:
[(2, '小薇'), (3, '海阔天空')]
Process finished with exit code 0
在select查询语句中,使用问号作为占位符代替具体的数值,然后使用一个元组来替换问号(注意,不要忽略元组中最后的逗号)。上述条件查询语句等价于:
cursor.execute('select * from user where id > 1')
说 明
使用占位符的方式可以避免SQL注入的风险,推荐使用这样的方式
3. 修改用户数据信息
修改user表中的数据可以使用如下SQL语句:
update 表名 set 字段名 = 字段值 where 查询条件
例如,将SQLite数据库中user表id 为1的数据name字段值修改为’李小龙’,代码如下:
import sqlite3
conn = sqlite3.connect('mySoft.db')
cursor = conn.cursor()
cursor.execute('delete from user where id = ?', (1, ))
conn.commit()
cursor.close()
conn.close()
MySQL数据库
MySQL服务器下载及安装
本人的运行环境为macOS系统,在terminal下执行brew install mysql@5.7进行安装,这里不再赘述。
liuxiaowei@MacBookAir ~ % brew install mysql@5.7
==> Downloading https://ghcr.io/v2/homebrew/core/mysql/5.7/manifests/5.7.36
Already downloaded: /Users/liuxiaowei/Library/Caches/Homebrew/downloads/3bd8201ca705f862e6a7e4c71ec30e87f77b9372889bd10d37989ac9edf694b1--mysql@5.7-5.7.36.bottle_manifest.json
==> Downloading https://ghcr.io/v2/homebrew/core/mysql/5.7/blobs/sha256:5289b664
Already downloaded: /Users/liuxiaowei/Library/Caches/Homebrew/downloads/e6da9b8d37c53e90332bc6c290ce514b6913c16310d45cad80490b191d45c903--mysql@5.7--5.7.36.monterey.bottle.tar.gz
==> Pouring mysql@5.7--5.7.36.monterey.bottle.tar.gz
==> Caveats
We've installed your MySQL database without a root password. To secure it run:
mysql_secure_installation
MySQL is configured to only allow connections from localhost by default
To connect run:
mysql -uroot
mysql@5.7 is keg-only, which means it was not symlinked into /usr/local,
because this is an alternate version of another formula.
If you need to have mysql@5.7 first in your PATH, run:
echo 'export PATH="/usr/local/opt/mysql@5.7/bin:$PATH"' >> ~/.zshrc
For compilers to find mysql@5.7 you may need to set:
export LDFLAGS="-L/usr/local/opt/mysql@5.7/lib"
export CPPFLAGS="-I/usr/local/opt/mysql@5.7/include"
To restart mysql@5.7 after an upgrade:
brew services restart mysql@5.7
Or, if you don't want/need a background service you can just run:
/usr/local/opt/mysql@5.7/bin/mysqld_safe --datadir=/usr/local/var/mysql
==> Summary
🍺 /usr/local/Cellar/mysql@5.7/5.7.36: 320 files, 234.3MB
==> Running brew cleanup mysql@5.7...
Disable this behaviour by setting HOMEBREW_NO_INSTALL_CLEANUP.
Hide these hints with HOMEBREW_NO_ENV_HINTS (see man brew).
说 明
如果安装遇到问题,本人之前已经发布一篇解决问题的博客,链接地址:
https://blog.csdn.net/weixin_41905135/article/details/122583513?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164488355516780261997164%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164488355516780261997164&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-122583513.nonecase&utm_term=%E5%AE%89%E8%A3%85mysql5.7&spm=1018.2226.3001.4450
启动SQL
使用MySQL数据库前,需要先启动MySQL。在terminal窗口中,输入命令:
MacBookAir:~ root
启动结果如下:
Starting MySQL
. SUCCESS!
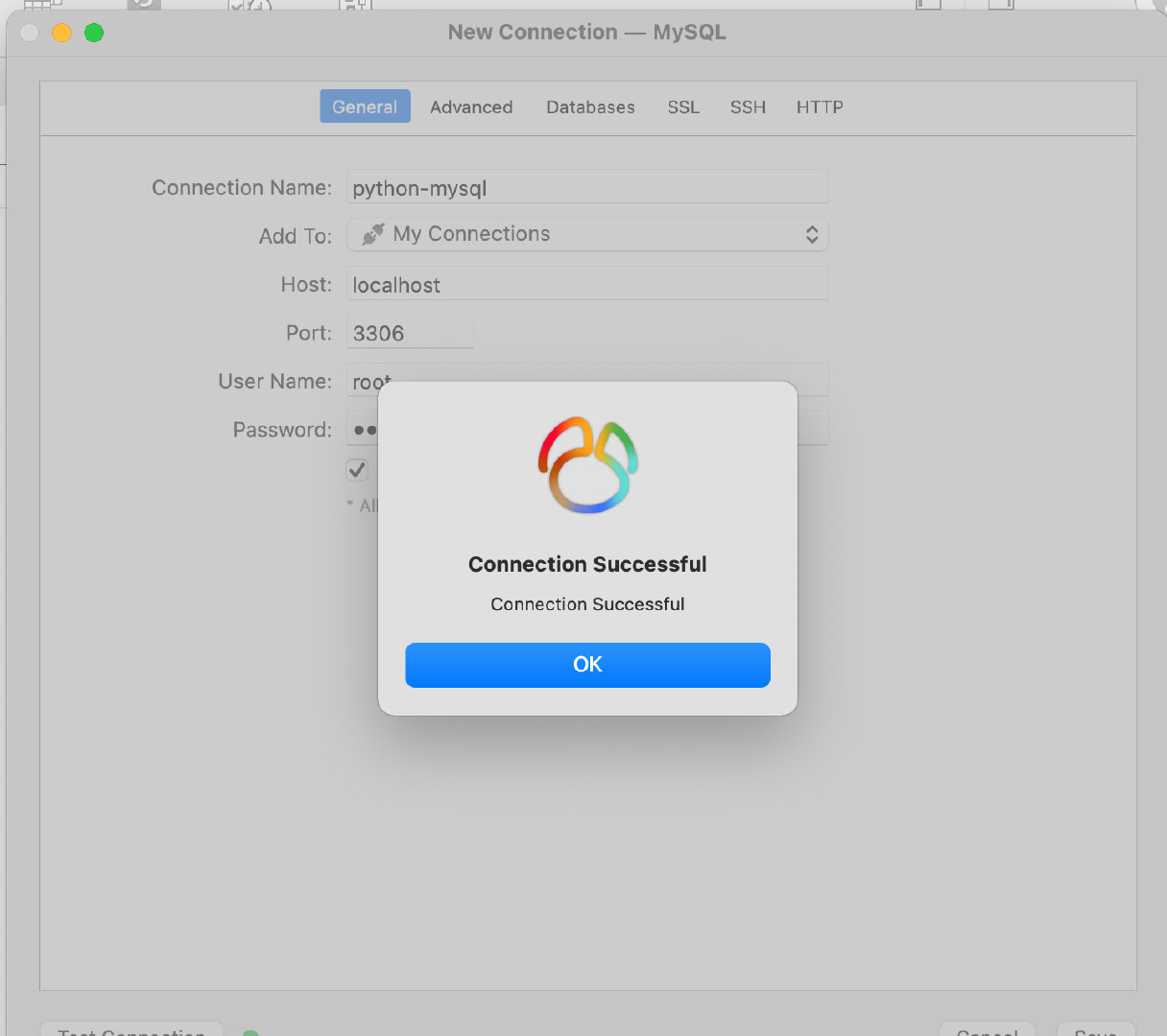
§ 1. 打开Navicat,新建MySQL连接,输入连接信息。(本例)连接名:python-mysql,输入主机名后IP地址”localhost”或”127.0.0.1″,输入密码,如下图:
§ 2. 创建完成以后,双击python-mysql,进入数据库。如下图:
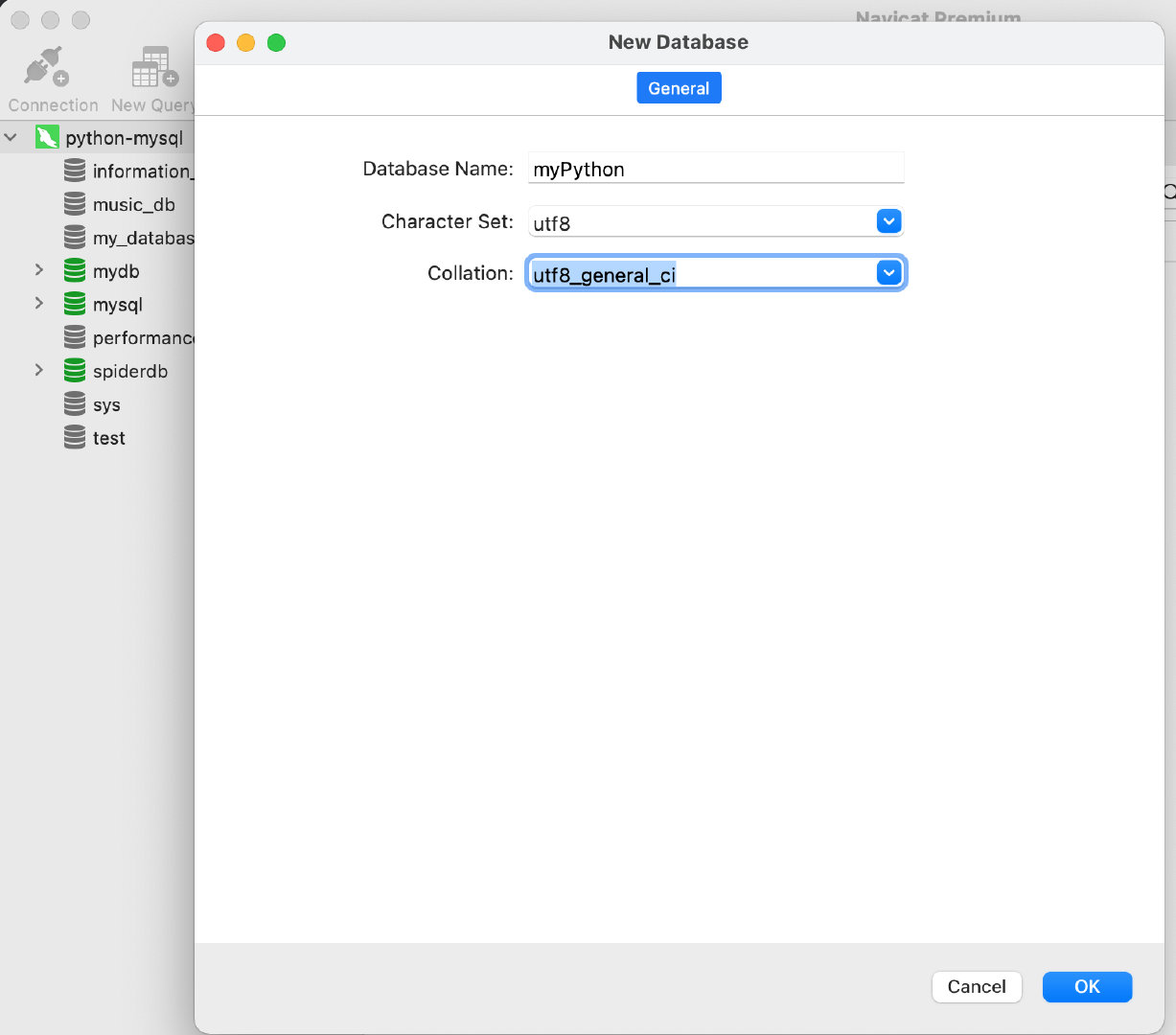
§ 3. 创建一个名为”myPython”的数据库,步骤为:右键单击python-mysql,选择”新建数据库”,填写数据库信息,如下图:
; 安装PyMySQL
由于MySQL服务器独立的进程行,并通过网络对外服务,所以,需要支持Python的MySQL驱动连接到MySQL服务器。在Python中支持MySQL的数据库模块有很多,我们选择使用PyMySQL模块。
PyMySQL模块的安装比较简单,在CMD命令行窗口中运行如下命令即可:
pip install PyMySQL
连接数据库
使用数据库的第一步是连接数据库。接下来使用PyMySQL模块连接数据库。由于PyMySQL模块页遵循Python Database API2.0规范,所以操作MySQL数据库的方式与SQLite相似。前面已经创建了一个MySQL连接”python-mysql”,并且在安装数据库时设置了数据库的用户名”root”和密码”12345″。下面通过以上信息,使用connect()方法连接MySQL数据库,代码如下:
import pymysql
db = pymysql.connect(host='localhost', database='myPython', port=3306, user='root', password='12345')
cursor = db.cursor()
cursor.execute('SELECT VERSION()')
data = cursor.fetchone()
print('Database version :%s '% data)
db.close()
上述代码中,首先使用connect()方法连接数据库,然后使用cursor()方法创建游标,接着使用execute()方法执行SQL语句查看MySQL数据库版本,然后使用fetchone()方法获取数据,最后使用close()方法关闭数据库连接,运行结果如下:
Database version :5.7.36
Process finished with exit code 0
创建数据库表
数据库连接成功以后,接下来就可以为数据库创建数据表了。创建数据库表需要使用excute()方法,本例使用该方法创建一个books图书表,books表包含id(主键)、name(图书名称)、category(图书分类)、price(图书价格)和publish_time(出版时间)5个字段。创建books表SQL语句如下:
CREATE TABLE books(
id int(8) NOT NULL AUTO_INCREMENT,
name varchar(50) NOT NULL,
category varchar(50) NOT NULL,
price decimal(10,2) DEFAULT NULL,
publish_time date DEFAULT NULL,
PRIMARY KEY(id)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET = utf8;
备注 在创建表之前,使用如下语句实现当前数据库表存在时先删除:
DROP TABLE IF EXISTS 'books';
示例代码如下:
import pymysql
db = pymysql.connect(host='localhost', database='myPython', port=3306, user='root', password='12345')
cursor = db.cursor()
sql = '''
CREATE TABLE books(
id int(8) NOT NULL AUTO_INCREMENT,
name varchar(50) NOT NULL,
category varchar(50) NOT NULL,
price decimal(10,2) DEFAULT NULL,
publish_time date DEFAULT NULL,
PRIMARY KEY(id)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET = utf8;
'''
cursor.execute(sql)
db.close()
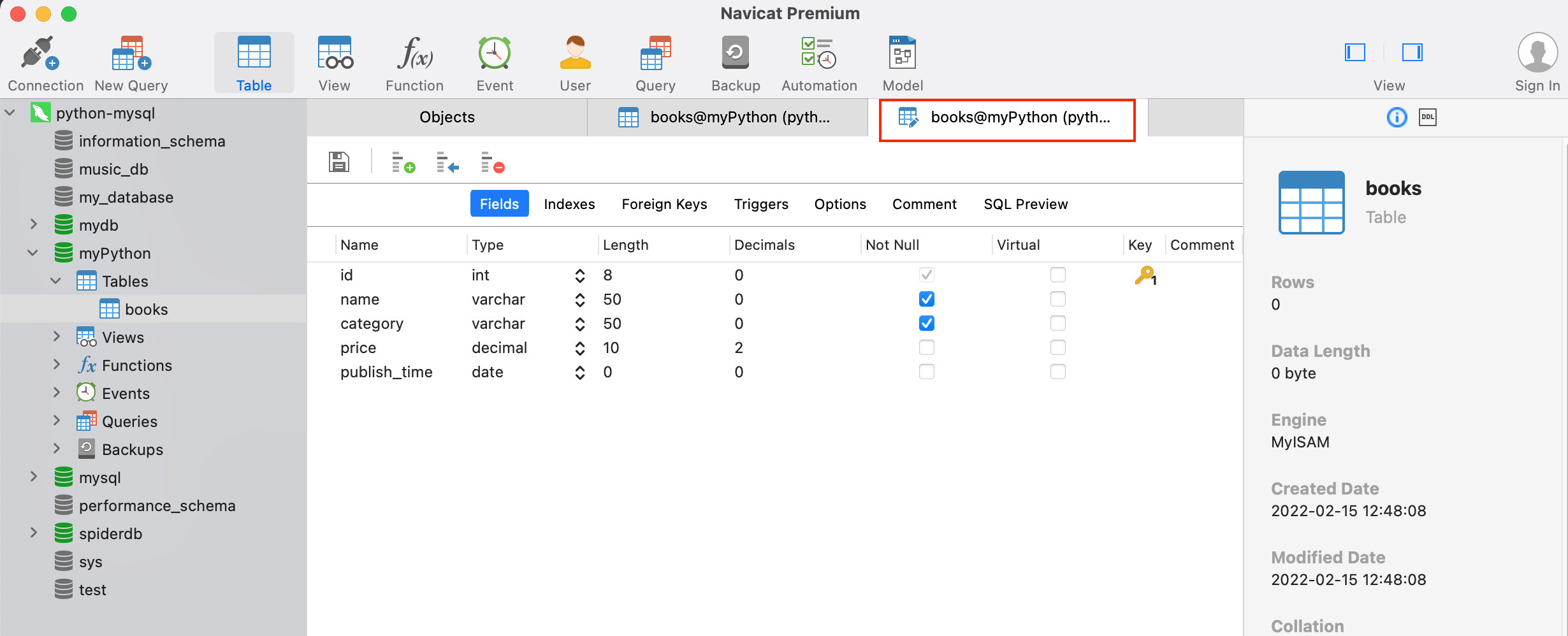
运行上述代码后,myPython数据库下会创建一个books表。打开Navicat(如果已经打开按下键刷新),发现myPython数据库下多了一个books表,右键单击books,选择设计表,如下图所示:
操作MySQL数据表
MySQL数据表的操作主要包括数据的增、删、改、查,与操作SQLite类似,我们使用executemany()方法向数据表中批量添加多条记录,executemany()方法格式如下:
exeutemany(operation, seq_of_params)
§ operation:操作的SQL语句
§ seq_of_params:参数序列
示例代码如下:
import pymysql
db = pymysql.connect(host="localhost", user="root", password="12345", database="myPython",charset="utf8")
cursor = db.cursor()
data = [("零基础学Python",'Python','79.80','2018-5-20'),
("Python从入门到精通",'Python','69.80','2018-6-18'),
("零基础学PHP",'PHP','69.80','2017-5-21'),
("PHP项目开发实战入门",'PHP','79.80','2016-5-21'),
("零基础学Java",'Java','69.80','2017-5-21'),
]
try:
cursor.executemany("insert into books(name, category, price, publish_time) values (%s,%s,%s,%s)", data)
db.commit()
except:
db.rollback()
db.close()
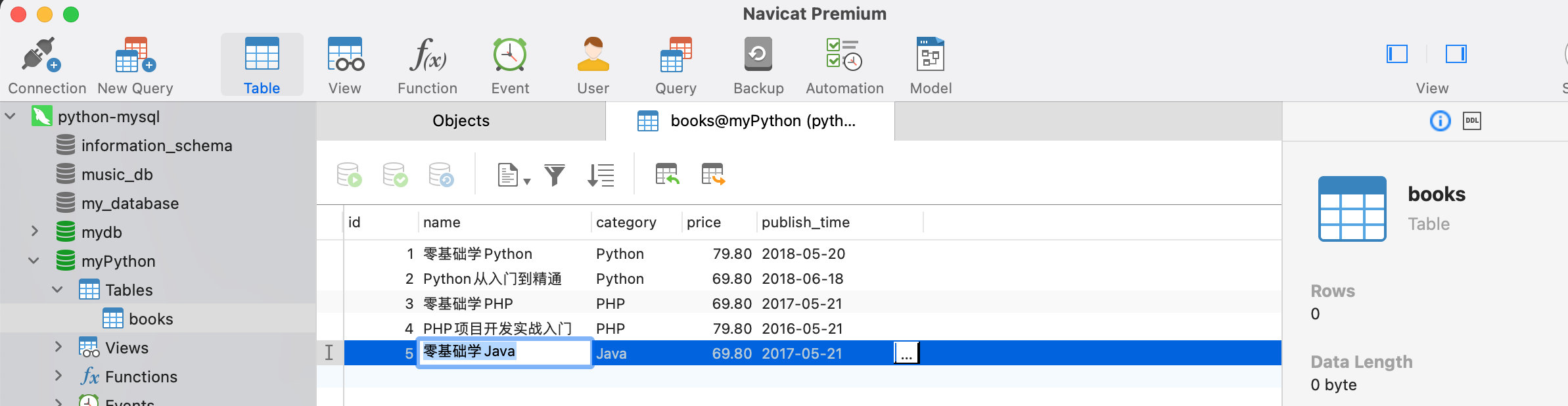
运行上述代码,在Navicat中查看books表数据,如下图:
注 意
§ 使用connect()方法连接数据库时,额外设置字符集”charset=utf-8″, 可以防止插入中文出错。
§ 在使用insert语句插入数据时,使用“%s”作为占位符,可以防止SQL注入。
总 结
Original: https://blog.csdn.net/weixin_41905135/article/details/122942676
Author: Bruce_Liuxiaowei
Title: Python爬虫-数据处理与存储
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/815670/
转载文章受原作者版权保护。转载请注明原作者出处!