

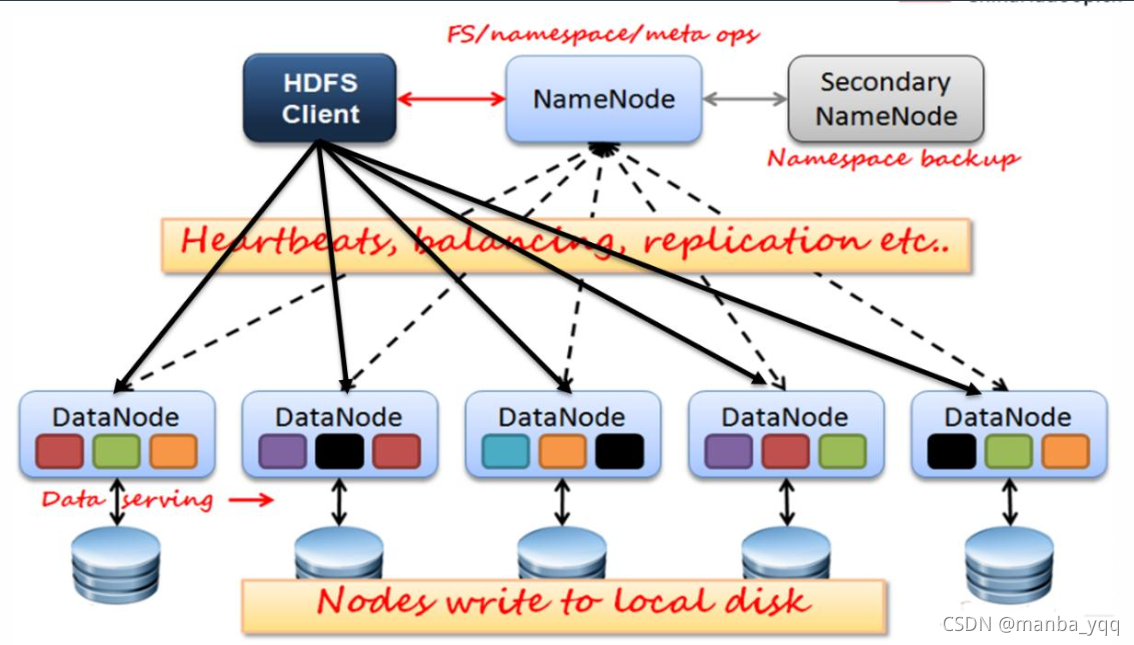

存在的意义
edits log会随着对文件系统的操作而无限制地增长,这对正在运行的NameNode而言没有任何影响,如果NameNode重启,则需要很长的时间执行edits log的记录以更新fsimage(元数据镜像文件)。在此期间,整个系统不可用。定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits log的合并。
SecondaryNameNode要和NameNode拥有相同的内存。对大的集群,SecondaryNameNode运行于一台专用的物理主机。
存储结构
[root@node1 name]/var/itbaizhan/hadoop/full/dfs/name|-current | |-edits_0000000000000000001-0000000000000000008| |-edits_0000000000000000009-0000000000000000038| |-edits_0000000000000000039-0000000000000000040| |-edits_0000000000000000041-0000000000000000041| |-edits_0000000000000000042-0000000000000000043| |-edits_0000000000000000044-0000000000000000045| |-edits_0000000000000000046-0000000000000000047| |-edits_0000000000000000048-0000000000000000049| |-edits_0000000000000000050-0000000000000000051| |-edits_0000000000000000052-0000000000000000053| |-edits_0000000000000000054-0000000000000000054| |-edits_0000000000000000055-0000000000000000056| |-fsimage_0000000000000000054| |-fsimage_0000000000000000054.md5| |-fsimage_0000000000000000056| |-fsimage_0000000000000000056.md5| |-edits_inprogress_0000000000000000057| |-seen_txid | |-VERSION|-in_use.lock[root@node2 namesecondary]/var/itbaizhan/hadoop/full/dfs/namesecondary|-current | |-edits_0000000000000000001-0000000000000000008| |-edits_0000000000000000009-0000000000000000038| |-edits_0000000000000000039-0000000000000000040| |-edits_0000000000000000041-0000000000000000041| |-edits_0000000000000000042-0000000000000000043| |-edits_0000000000000000044-0000000000000000045| |-edits_0000000000000000046-0000000000000000047| |-edits_0000000000000000048-0000000000000000049| |-edits_0000000000000000050-0000000000000000051| |-edits_0000000000000000052-0000000000000000053| |-edits_0000000000000000055-0000000000000000056| |-fsimage_0000000000000000054| |-fsimage_0000000000000000054.md5| |-fsimage_0000000000000000056| |-fsimage_0000000000000000056.md5| |-VERSION|-in_use.lock
1、SecondaryNameNode中checkpoint目录布局(dfs.namenode.checkpoint.dir)和NameNode中的基本一样。
2、如果NameNode完全坏掉,可以快速地从SecondaryNameNode恢复。有可能丢数据
3、如果SecondaryNameNode直接接手NameNode的工作,需要在启动NameNode进程的时候添加-importCheckpoint选项。该选项会让NameNode从由dfs.namenode.checkpoint.dir属性定义的路径中加载最新的checkpoint数据,但是为了防止元数据的覆盖,要求dfs.namenode.name.dir定义的目录中没有内容。

edits_inprogress_00000000001_0000000019 seen_txid=20
1、secondarynamenode请求namenode生成新的edits log文件(edits_inprogress_…)并向其中写日志。NameNode会在所有的存储目录中更新seen_txid文件
2、SecondaryNameNode通过HTTP GET的方式从NameNode下载fsimage和edits文件到本地。
3、SecondaryNameNode将fsimage加载到自己的内存,并根据edits log更新内存中的fsimage信息,然后将更新完毕之后的fsimage写到磁盘上。
4、SecondaryNameNode通过HTTP PUT将新的fsimage文件发送到NameNode,NameNode将该文件保存为.ckpt的临时文件备用。
5、NameNode重命名该临时文件并准备使用。此时NameNode拥有一个新的fsimage文件和一个新的很小的edits log文件(可能不是空的,因为在SecondaryNameNode合并期间可能对元数据进行了读写操作)。管理员也可以将NameNode置于safemode,通过hdfs dfsadmin -saveNamespace命令来进行edits log和fsimage的合并。
检查点创建时机:对于创建检查点(checkpoint)的过程,有三个参数进行配置:
Original: https://blog.51cto.com/u_15704423/5434917
Author: wx62be9d88ce294
Title: HDFS角色SecondaryNameNode
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516914/
转载文章受原作者版权保护。转载请注明原作者出处!