

Self-Supervised Transformers for Unsupervised Object Discovery using Normalized Cut
Yangtao Wang1 , Xi Shen2,3,∗ , Shell Xu Hu4 , Yuan Yuan5 , James L. Crowley1 , Dominique Vaufreydaz1
1 Univ. Grenoble Alpes, CNRS, Grenoble INP, LIG, 38000 Grenoble, France
2 Tencent AI Lab 3 LIGM (UMR 8049) – Ecole des Ponts, UPE
4 Samsung AI Center, Cambridge 5 MIT CSAIL
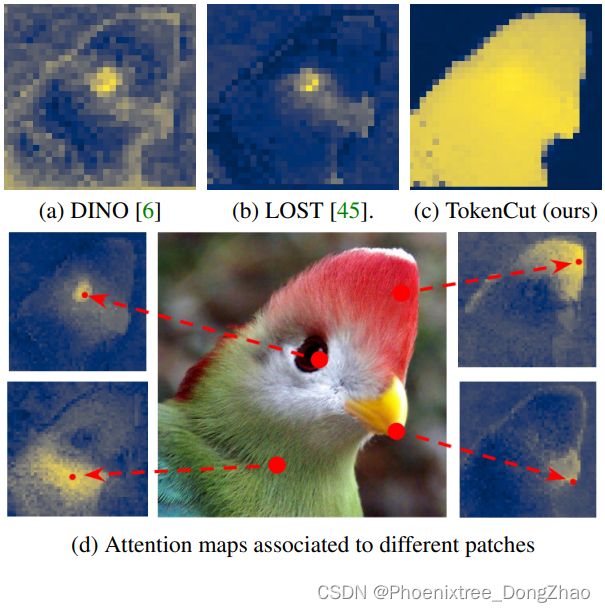

Figure 1: The attention map of the class token used in DINO [6] (a) and the map of the inverse degrees used in LOST [45] (b) are noisy for foreground / background separation. Our proposed method provides a clean attention map that can be used to segment salient objects (c). Considering the attention map associated to different patches highlight different regions of the object (d), it is reasonable to build a graph computing attention maps from multiple patches.
本博客只简单介绍,对算法感兴趣的,详情还请看原文。
Abstract
Transformers trained with self-supervised learning using self-distillation loss (DINO) have been shown to produce attention maps that highlight salient foreground objects. In this paper, we demonstrate a graph-based approach that uses the self-supervised transformer features to discover an object from an image. Visual tokens are viewed as nodes in a weighted graph with edges representing a connectivity score based on the similarity of tokens. Foreground objects can then be segmented using a normalized graph-cut to group self-similar regions. We solve the graph-cut problem using spectral clustering with generalized eigen-decomposition and show that the second smallest eigenvector provides a cutting solution since its absolute value indicates the likelihood that a token belongs to a foreground object. Despite its simplicity, this approach significantly boosts the performance of unsupervised object discovery: we improve over the recent state of the art LOST by a margin of 6.9%, 8.1%, and 8.1% respectively on the VOC07, VOC12, and COCO20K. The performance can be further improved by adding a second stage class-agnostic detector (CAD). Our proposed method can be easily extended to unsupervised saliency detection and weakly supervised object detection. For unsupervised saliency detection, we improve IoU for 4.9%, 5.2%, 12.9% on ECSSD, DUTS, DUT-OMRON respectively compared to previous state of the art. For weakly supervised object detection, we achieve competitive performance on CUB and ImageNet.
使用自蒸馏损失 (self-distillation loss, DINO) 进行自监督学习的 Transformers 已经被证明可以生成突出前景物体的注意力图。
本文演示了一种基于图的方法 (graph-based),该方法使用自监督 transformer 特征从图像中发现对象。视觉 tokens 被视为加权图中的节点,其边表示基于标记相似性的连通性得分。
使用归一化图形切割(normalized graph-cut)对自相似区域分组,这样前景对象可以被分割。
再使用光谱聚类和广义特征分解解决了图切割问题,并表明第二个最小的特征向量提供了切割解决方案,因为它的绝对值表明了一个 token 属于前景对象的可能性。
尽管它很简单,但这种方法显著提高了无监督对象发现的性能: 在 VOC07、VOC12 和 COCO20K上分别比 SOTA 提高了 6.9%、8.1% 和 8.1%。
可以通过添加第二级类无关检测器 (CAD) 来进一步提高性能。该方法可以很容易地推广到无监督显著性检测和弱监督目标检测。
对于无监督显著性检测,将 ECSSD、DUTS、DUT-OMRON 的 IoU 分别提高了 4.9%、5.2%、12.9%。
对于弱监督对象检测,在 CUB 和 ImageNet 上实现了具有竞争力的性能。
Introduction
当前最先进的目标检测器的性能受限于注释足够的训练数据。当使用迁移学习来适应一个预先训练的对象检测器到一个新的应用领域时,这种限制变得更加明显。主动学习 (active learning [1])、半监督学习[34 ]和弱监督学习[39] 等方法试图通过提供更有效的学习来克服这一障碍,但只取得了有限的成功。
本文专注于在没有人工标记的自然图像中的目标检测。目前解决这一问题的方法采用了一些形式的bounding box proposal mechanism,并将目标检测作为一个优化问题。然而,这种方法的计算成本很高[55],因为需要对不同图像上的每一对 bounding box proposals 进行比较,而且由于二次方计算开销(quadratic computation overhead),优化可能无法扩展到更大的数据集。
Transformers 最近被证明在视觉识别方面优于卷积神经网络。最近关于 DINO [6] 的研究结果表明,当使用 self-distillation loss 进行训练时,关联于来自最后一层的类别 token 的注意力图,可以表示为显著前景区域(the attention maps associated to the class token from the last layer indicate salient foreground regions)。然而,如图 1a 所示,这样的注意图是有噪声的,它们是否可以用于无监督目标发现尚不清楚。
文献 [45]利用 LOST构造一个图,利用节点的 inverse degrees 来分割对象。采用 seed expansion strategy 克服噪声 (图 1b),并检测前景目标的单个边界框。与不同节点相关联的注意图通常包含有意义的信息,如图 1d 所示。本文研究了是否可能利用整个图中的信息,通过特征分解将图投影到一个低维子空间。本文发现,这样的投影可以与归一化切割 (Normalized Cut [43]) 一起使用,以显著改善前景/背景分割 (图 1c)。
本文提出了一个简单但有效的基于图的无监督目标检测方法,TokenCut。其以 DINO[6] 为 backbone 特征编码器训练的自监督 vision transformer,利用得到的特征对目标进行定位。本文的方法不再只使用类 tokens,而是使用所有 taoken 特性。基于最后一个自注意层中的 token 特征构造了一个无向图,其中 visual tokens 被视为图节点,其边表示基于特征相似性的连通性得分。然后,使用标准化的图形切割来分组自相似区域,并划定前景对象。本文使用光谱聚类(spectral clustering)和广义特征分解解决图切割问题,并表明第二最小特征向量提供了一个切割解决方案,表明一个标记属于前景对象的可能性。本文的方法可以被认为是一个 run-time adaptation,这意味着模型能够适应每个特定的测试图像,尽管共享的训练模型。
尽管简单,但我们的方法显著改进了无监督对象发现。该方法在 VOC07[19]、VOC12[20]、COCO20K[33] 上分别达到 68.8%、72.1% 和 58.8%,分别超过 LOST[45] 的 6.9%、8.1% 和 8.1%。采用第二阶段 CAD 的 TokenCut 进一步将 VOC07、VOC12、COCO20k 的性能分别提高到 71.4%、75.3% 和 62.6%,分别比 LOST + CAD 提高了 5.7%、4.9% 和 5.1%。
此外,本文表明,TokenCut 可以很容易地扩展到弱监督对象检测和无监督显著性检测。对于弱监督对象检测,目标是仅使用图像级注释检测对象。首先,冻结编码器和微调线性分类器与弱监督图像标签。然后,对从微调编码器中提取的特征应用 TokenCut。该方法在 CUB 数据集 [59] 上产生了明显改善的结果,并在 ImageNet-1K [14] 上具有竞争力的性能。对于无监督显著性检测,使用该方法发现的前景区域,并使用双边求解器[5] 作为后处理步骤来细化前景区域的边缘。在结果方面,本文的方法显著改善了 ECSSD [44]、DUTS [60] 和 DUT-OMRON [67] 上之前最先进的方法。
[1] Hamed H Aghdam, Abel Gonzalez-Garcia, Joost van de Weijer, and Antonio M Lopez. Active learning for deep detection neural networks. In ICCV, 2019.
[6] Mathilde Caron, Hugo Touvron, Ishan Misra, Herve J ´ egou, ´ Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
[43] Jianbo Shi and Jitendra Malik. Normalized cuts and image segmentation. TPAMI, 2000.
[45]Oriane Simeoni, Gilles Puy, Huy V. Vo, Simon Roburin, ´ Spyros Gidaris, Andrei Bursuc, Patrick Perez, Renaud ´ Marlet, and Jean Ponce. Localizing objects with selfsupervised transformers and no labels. In BMVC, 2021.
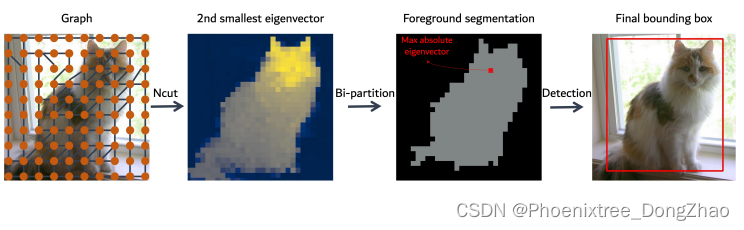
Figure 2: An overview of the TokenCut approach. We construct a graph where the nodes are tokens and the edges are similarities between the tokens using transformer features. The foreground and background segmentation can be solved by Ncut [43]. Performing bi-partition on the second smallest eigenvector allows to detect foreground object.

Original: https://blog.csdn.net/u014546828/article/details/125179845
Author: Phoenixtree_DongZhao
Title: 无监督目标检测、显著度检测(简介):Unsupervised Object Discovery using Normalized Cut
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/650545/
转载文章受原作者版权保护。转载请注明原作者出处!