

聚类是一种无监督学习。与分类不同的是,分类的数据集都是有标签的已经指明了该样本是哪一类,而对于聚类其数据集样本是没有标签的,需要我们根据特征对这些数据进行聚类。
K-Means算法是一种无监督学习的聚类方法。
1.K-Means算法
算法接受参数K,然后将事先输入的n个数据对象划分成K个聚类以便使得所获得得聚类满足:同一聚类中得对象相似的较高,而不同聚类中的对象相似度较小。
算法思想:以空间中K个点为中心进行聚类,对著靠近他们得对象归类。通过迭代的方法,逐次更新聚类中心得值,直至得到最好的聚类结果。
K—MEANS算法步骤:
1.先从没有标签得元素集合A中随机取k个元素,作为k个子集各自的重心
2.分别计算剩下得元素到k个子集重心得距离(这里的距离也可以使用欧氏距离),根据距离将这些元素分别划归到最近的子集。
3.根据聚类得结果,重新计算重心((重心得计算方法是计算子集中所有元素各个维度得算数平均数)
4.将集合A中全部元素按照新的重心然后在重新聚类。
5.重复第4步,直到聚类结果不再发生改变。
举例:
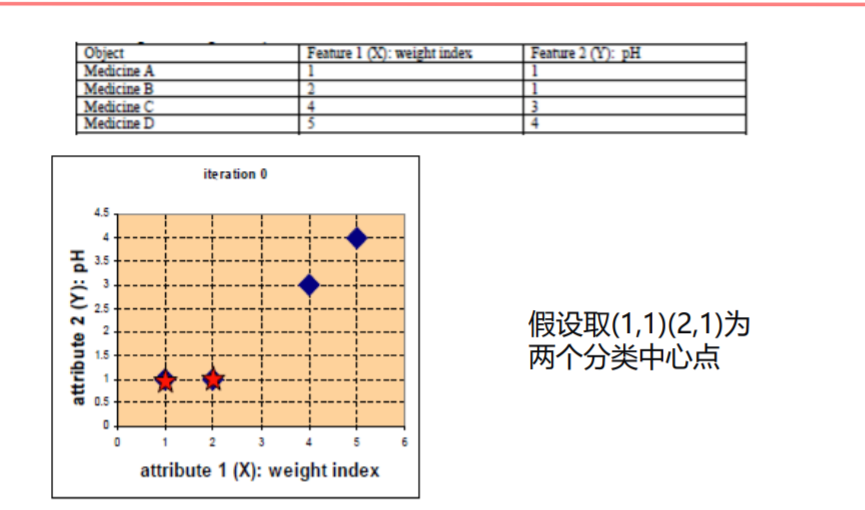

以上边得数据为例,给定k=2,假设第一次我们选取得重心为(1,1)(2,1),分别计算所有得点到重心的距离,结果如下图的D0所示,按照每个元素到达重心的距离远近将其划分到相应的子集中,结果如G0所示;
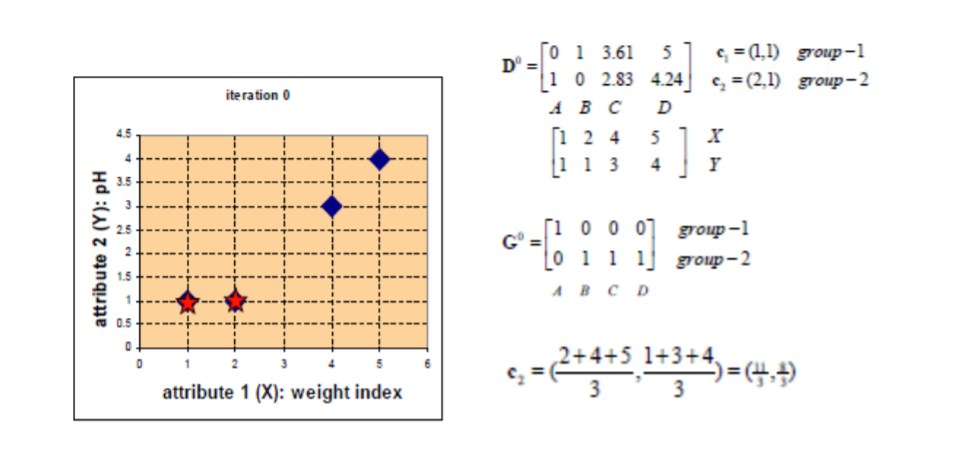
在重新计算新的重心,对应第一个类别,由于就只有(1,1)一个点,所以其重心就是(1,1)本身,对于第二个类别其重心就是所以点的X,Y轴坐标分别相加求平均值,为c2。所以新的重心就变成了图上五角星所表示的点。
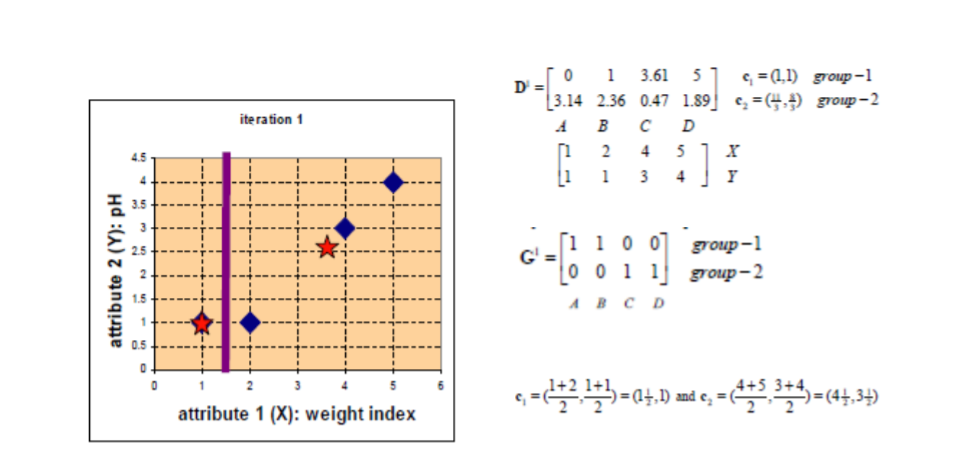
再次计算各个点到重心的距离得到D1,按照计算出来的距离进行划分得到新的划分结果G1,再次重新计算重心C1,c2。

接着照着上边的步骤进行计算得到D2,G2,发现聚类结果不再发生改变,聚类停止迭代。
代码:
import numpy as np
import matplotlib.pyplot as plt
data=np.genfromtxt('kmeans.txt',delimiter=' ')
print(data.shape)
print(data[:5])
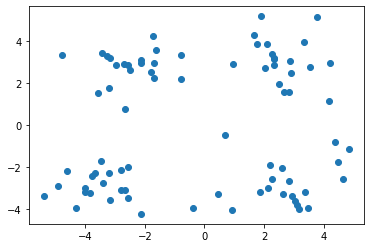
plt.scatter(data[:,0],data[:,1])
plt.show()
(80, 2)
[[ 1.658985 4.285136]
[-3.453687 3.424321]
[ 4.838138 -1.151539]
[-5.379713 -3.362104]
[ 0.972564 2.924086]]
def calDistence(x1,x2):
return np.sqrt(sum((x1-x2)**2))
def initCenter(data,k):
numbSamples,dim=data.shape
center=np.zeros((k,dim))
for i in range(k):
index=int(np.random.uniform(0,numbSamples))
center[i,:]=data[index,:]
return center
def kmeans(data,k):
numSample=data.shape[0]
resultData=np.array(np.zeros((numSample,2)))
ischange=True
center=initCenter(data,k)
while(ischange):
ischange=False
for i in range(numSample):
minDist=10000
mindex=0
for j in range(k):
distance=calDistence(data[i,:],center[j,:])
if(distance<minDist):
minDist=distance
resultData[i,1]=minDist
mindex=j
if(resultData[i,0]!=mindex):
ischange=True
resultData[i,0]=mindex
for j in range(k):
cluster_index=np.nonzero(resultData[:,0]==j)
points=data[cluster_index]
center[j,:]=np.mean(points,axis=0)
return center,resultData
test=np.array([0,1,2,3,1,0,2,3,1,2,0])
print(test==0)
print(np.nonzero(test==0))
test[np.nonzero(test==0)]
[ True False False False False True False False False False True]
(array([ 0, 5, 10], dtype=int64),)
array([0, 0, 0])
def showData(data,k,center,resultData):
numSamples,dim=data.shape
if(dim!=2):
print('error')
return 1
mark=['or','ob','og','ok']
if(k>len(mark)):
print("your k is to large")
return 1
for i in range(numSamples):
markIndex=int(resultData[i,0])
plt.plot(data[i,0],data[i,1],mark[markIndex])
mark=['*r','*b','*g','*k']
for i in range(k):
plt.plot(center[i,0],center[i,1],mark[i],markersize=20)
plt.show()
k=4
center,resultData=kmeans(data,k)
showData(data,k,center,resultData)
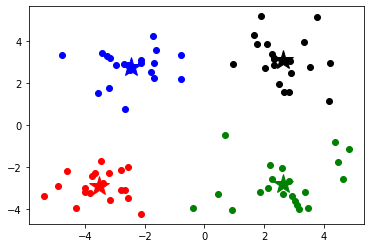
center
array([[-3.53973889, -2.89384326],
[-2.46154315, 2.78737555],
[ 2.65077367, -2.79019029],
[ 2.6265299 , 3.10868015]])
x_test=[0,1]
print(np.tile(x_test,[k,1]))
print([k,1])
[[0 1]
[0 1]
[0 1]
[0 1]]
[4, 1]
a=(np.tile(x_test,[k,1])-center)**2
print(a)
print(sum(a))
print(a.sum(axis=1))
[[12.52975144 15.16201536]
[ 6.05919468 3.19471136]
[ 7.02660103 14.3655424 ]
[ 6.89865932 4.44653198]]
[32.51420647 37.16880109]
[27.6917668 9.25390604 21.39214343 11.34519129]
np.argmin(((np.tile(x_test,[k,1])-center)**2).sum(axis=1))
1
def predict(datas):
return np.array([np.argmin(((np.tile(data,[k,1])-center)**2).sum(axis=1)) for data in datas])
x_min,x_max=data[:,0].min()-1,data[:,0].max()+1
y_min,y_max=data[:,1].min()-1,data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),
np.arange(y_min,y_max,0.02))
z=predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
cs=plt.contourf(xx,yy,z)
showData(data,k,center,resultData)

from sklearn.cluster import KMeans
model=KMeans(n_clusters=4)
model.fit(data)
KMeans(n_clusters=4)
centers=model.cluster_centers_
print(centers)
[[-3.38237045 -2.9473363 ]
[ 2.6265299 3.10868015]
[-2.46154315 2.78737555]
[ 2.80293085 -2.7315146 ]]
2.Mini Batch K-Means
Mini Batch K-Means 算法是K—Means算法的变种,采用小批量的数据子集减小计算时间。这里的小批量是指每次训练算法时所随机抽取的数据子集,采用这些随机产生的子集进行训练,大大减少了计算时间,结果一般只略差与标准算法。
该算法的迭代步骤有两步:
1.从数据集中随机抽取一些数据形成小批量,把他们分配给更近的重心
2.更新重心
Mini Batch K-Means比K-Means 相比有更快的收敛速度,但同时也降低了聚类效果
Original: https://blog.csdn.net/m0_51456926/article/details/122658561
Author: 是忘生啊
Title: 聚类(一)——K-Means算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/550424/
转载文章受原作者版权保护。转载请注明原作者出处!