

- 前言:修改代码时心生疑问,故写此文章,以便参考。
- *model.to(device)和model.cuda()的区别:
.to(device) 可以指定CPU 或者GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model,device_ids=[0,1,2,3])
model.to(device)
.cuda() 只能指定GPU
os.environ['CUDA_VISIBLE_DEVICE']='1'
model.cuda()
os.environment['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'
device_ids = [0,1,2,3]
net = torch.nn.Dataparallel(net, device_ids =device_ids)
net = torch.nn.Dataparallel(net)
net = net.cuda()
如若不知该设备有多少块GPU
Linux设备可以使用
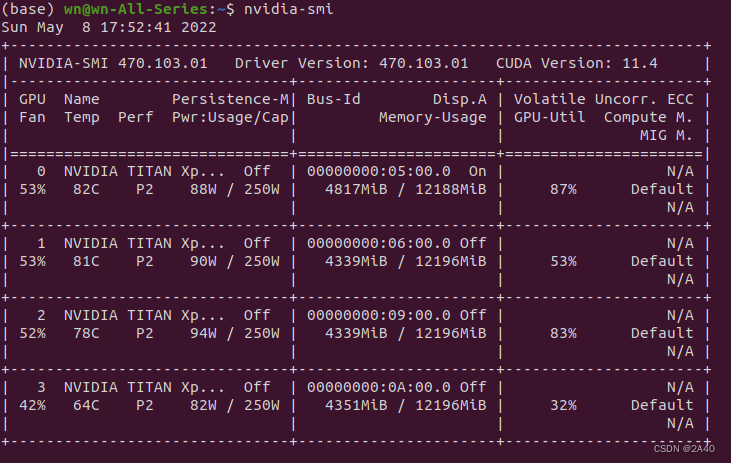
nvidia-smi
查看该设备有多少块GPU,如图,特需注意的是此处显示的Driver Version 470.103.01是显卡驱动版本号,而CUDA Version显示的并不是该设备所使用的的显卡CUDA版本,而是设备所支持的最大CUDA版本。由此图亦可以看出各个GPU
的使用情况。

另外使用.cuda()所需要注意的是:.cuda是要写在模型装载之后,下面是举例
net = resnet34()
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'
device_ids = [0, 1, 2, 3]
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, args.out_feature)
net = nn.DataParallel(net, device_ids=device_ids)
net.cuda()
最后也要注意选择不同,数据的载入也不同,下面是例子
logits = net(images.cuda())
loss = loss_function(logits, labels.cuda())
- 为什么使用多个GPU比一个GPU的时候还慢?
此处请看这位博主的文章『开发技术』GPU训练加速原理(附KerasGPU训练技巧)
Original: https://blog.csdn.net/m0_55256134/article/details/124651645
Author: 2A40
Title: 训练时是否使用显卡和怎么使用多张显卡的问题
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/709436/
转载文章受原作者版权保护。转载请注明原作者出处!