

目录
定义
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
算法流程
将所有点标为未标记点,依次遍历所有点,判断该点是否被标记,如果被标记则遍历下个点,反之计算该点邻域点,判断邻域点个数,如果小于min_sample(邻域半径内最小邻域点个数)则将该点标记为噪声点,反之标记为簇Ci(i为不同簇标号),并将该点及其邻域点存入簇Ci,从Ci中选出一个点,判断该点是否为噪声点,若是将其标号改成簇Ci标号,反之判断该点邻域点个数是否大于min_sample,如果大于说明该点可继续扩充,将该点及其邻域点加入到Ci,继续遍历Ci中点,直到Ci中所有点被遍历完,则返回开头,遍历下一个点,如果该点邻域点个数小于min_sample,说明该点是簇Ci中的边界点,不可继续扩充,则标记该点为簇Ci点,继续遍历Ci中下一个点。直到原数据所有点被遍历完,算法结束,返回数据对应的簇标号。
代码
#寻找某点的邻域元素,返回对应的索引 便于后续判断该点的标签类别(即簇类别)
def find_nerighborhood(p, data, eps):
N = [] #存放某个点邻域元素的索引
for i in range(len(data)):
distance = np.sqrt(np.sum((p - data[i])**2))
if distance < eps:
N.append(i)
return N
#扩充簇元素
def expand_cluster(N, data, eps, min_sample, mask, clusters_label):
#遍历簇中每个元素,找到符合扩充条件的元素 添加到簇中
i = 0
while i < len(N):
#如果该点被标为噪声点,则将其改成簇标号 且不用计算该邻域元素因为以前被标为噪声点说明现在只是边缘点
if mask[N[i]] == -1:
mask[N[i]] = clusters_label
#如果该点未被标记则标为簇标号
elif mask[N[i]] == 0:
mask[N[i]] = clusters_label
#计算该点邻域点
N_new = find_nerighborhood(data[N[i]], data, eps)
if len(N_new) > min_sample:
#将该点邻域存入簇
N += N_new
i += 1
# return N
def DBSCAN_re(data, eps, min_sample):
#所有数据标为未标记数据
# mask = np.zeros_like(data[:, 0], dtype=bool) #存放标记号
mask = np.zeros(data.shape[0])
# clusters = [] #存放某种簇所有元素
clusters_label = 0 #簇类别号
for p in range(len(data)):
#如果该点被标记则跳过该点
if mask[p] != 0:
continue
#如果该点未被处理则计算该点邻域点
N = find_nerighborhood(data[p], data, eps)
num_ner = len(N)
#如果邻域元素过少则标为噪声点
if num_ner < min_sample:
mask[p] = -1
else:
#将该点标为第i类 i = 1, 2, ...
clusters_label += 1
mask[p] = clusters_label
#扩充簇元素
expand_cluster(N, data, eps, min_sample, mask, clusters_label)
return mask #返回每个点对应的类别标号
效果演示
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:dd0c18b6-7ec7-451c-973a-3ee19babf257
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:6f83b108-58c5-4a9a-b2f1-7c20f410c9c8



算法优势
(1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
(2)与K-MEANS比较起来,不需要输入要划分的聚类个数;
(3)聚类簇的形状没有偏倚;
(4)可以在需要时输入过滤噪声的参数。
算法劣势
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情况下参数MinPts和Eps选取困难。
(3)算法聚类效果依赖与距离公式选取,实际应用中常用欧式距离,对于高维数据,存在”维数灾难”。
算法待改进之处
(1)减小算法复杂度,便于处理大数据集
(2)邻域半径及邻域点个数阈值不易选取
参数选择方式
(1) K-距离:随机选中某个点,计算该点与所有点的距离,当某个距离对应的邻域点个数发生突变时,将该距离设定为Eps。(该方式不是原K距离方式)
原K-距离方式:给定K邻域参数k,对于数据中的每个点,计算对应的第k个最近邻域距离,并将数据集所有点对应的最近邻域距离按照降序方式排序,称这幅图为排序的k距离图,选择该图中第一个谷值点位置对应的k距离值设定为Eps。一般k选4。
(2) MinPts的选取与k相似时,效果较好。
参数选择效果
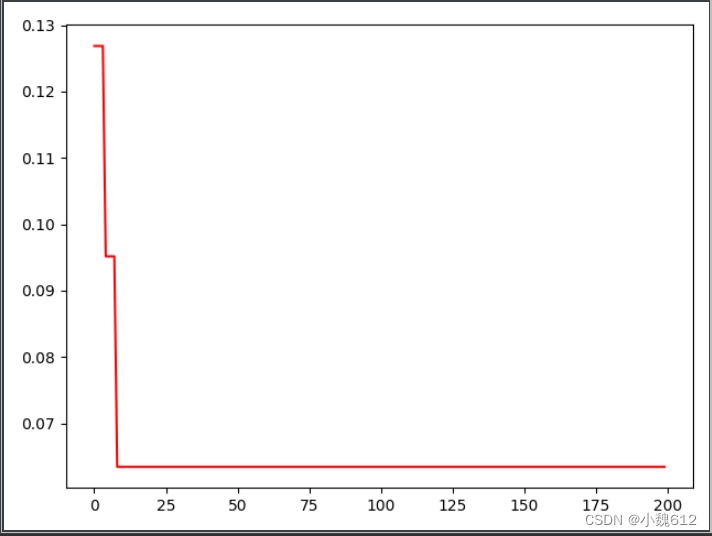
月牙数据集eps=0.1,min_sample=4

双圆加点簇数据集eps=0.4,k=4
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:f44b8a20-0b74-4a12-849f-3fd8af04c3a0
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:bc61c7aa-8a6d-4d34-a06e-4c3fb364f5fe
Original: https://blog.csdn.net/qq_62945476/article/details/124509474
Author: 小魏612
Title: DBSCAN算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/563354/
转载文章受原作者版权保护。转载请注明原作者出处!