

博雯 萧箫 发自 凹非寺 量子位 报道 | 公众号 QbitAI
现在,AI已经能克隆任意人的声音了!
比如,还有一秒,美玉姐姐还在宿舍里登记:
[En]
For example, one second Sister Mei Yu was still checking in the dormitory:
后一秒就打算吃个桃桃:
简直就是幽灵畜牧区的福利!
[En]
It is simply the welfare of the ghost livestock area!


此外,还有正经的 方言版,比如台湾腔就完全冇问题:
这就是GitHub博主 Vega最新的语音克隆项目 MockingBird,能够在5秒之内克隆任意中文语音,并用这一音色合成新的说话内容。
这一模型短短2个月就狂揽 7.6k星,更是一度登上GitHub趋势榜第一:
社区里充斥着无数寻求培训前模型和保姆级别教程的人。
[En]
The community is flooded with countless people seeking pre-training models and nanny-level tutorials.
因此,我们也借此尝试了这款“柯南模拟器”,并与开发者本人进行了一次深度的♂对话。
[En]
Therefore, we also took this opportunity to try this “Conan simulator” and had a deep ♂ conversation with the developer himself.
5秒合成一段语音,效果如何?
让我们先从一位路人身上选择一位小姐姐的声音,试着让他像华强一样说一句:这瓜熟了吗?效果如何?
[En]
Let’s first choose the voice of a little sister from a passer-by and try to make him like Huaqiang to say, “is this melon ripe?” what’s the effect?

好吧,果然,小姐姐的语气没有华强那么猛,但也准确地还原了我的音色:
[En]
Well, sure enough, the tone of the little sister is not as fierce as Huaqiang, but it also accurately restores my timbre:
这不禁让我们有了一些大胆的想法。
[En]
This can not help but let us have some bold ideas.
试试只用一声 喊叫的语音(甚至小于5s),让AI直接输出一段”我从未见过如此……之人”:
从视频上看,虽然有一些破损,但整体效果还可以。
[En]
From the video, although there are some broken, but the overall effect is OK.
至于 诸葛村夫本人,我们反向操作,让他吃起了桃桃:
在我有生之年,听到诸葛村的丈夫撒娇,我感到很惊讶。
[En]
In my lifetime, I was surprised to hear the husband of Zhuge Village acting coquettish.
现在的输出效果看起来不错,那么输出的语音质量如何呢?
[En]
The output effect now looks good, so what is the quality of the output voice?
我们决定用开头 台湾腔生成的语音作为样本,再次合成语音试试。

模型再次顺利地合成了”我要买一百个瓜”,看来合成的音频质量效果也是不错的:
除此之外,我们还试了一下其他文本,基本效果都挺OK。
然而,我们发现,如果我们使用强烈的情感/语气声音(影视剧中演员的声音效果),效果会与我们预期的略有不同。
[En]
However, we found that if we use strong emotional / tone voice (actors’ voice effects in movies and TV dramas), the effect will be a little different from what we expected.
例如,在一位同事的强烈建议下,我们要求作者用最新的预训模式免费学习华强:
[En]
For example, at the strong suggestion of a colleague, we asked the author to learn Huaqiang for nothing with the latest pre-training model:
嗯?原来的黑社会黑帮,真的变成了内向的白种人。
[En]
Yeah? The original underworld gangster has really become an introverted leukologist.
事实上,为了防止不法分子使用,笔者并没有上传最新款。
[En]
In fact, in order to prevent lawbreakers from using it, the author did not upload the latest model.
不过,现在几个预训练版本的 音色模仿效果都已经挺不错了,你也可以上手调戏一下这个AI。
已有预训练模型,可直接试玩
那么,这个AI模型究竟要怎么用呢?
作者表示,模型支持在 Windows、Linux系统上运行,在苹果系统M1版上也有成功运行案例。
但我们偏偏用双核英特尔Core i3(1.1GHz)的苹果系统试着运行了一下……

事实证明,Mac系统也可以直接将调教好的预训练模型拿来用!
由于模型框架用的是PyTorch,需要提前安装一下环境,这里用的的版本是Python3.9.4和PyTorch1.9.1,再用pip安装一下ffmpeg、webrtcvad。
然后,下载MockingBird下requirements.txt中的必要包:
pip install -r requirements.txt
运行情况如图:
成功后,下载预训练模型,替换掉MockingBird中的相关文件夹:

再启动python demo_toolbox.py,当你看到这个界面的时候,就说明运行成功了:
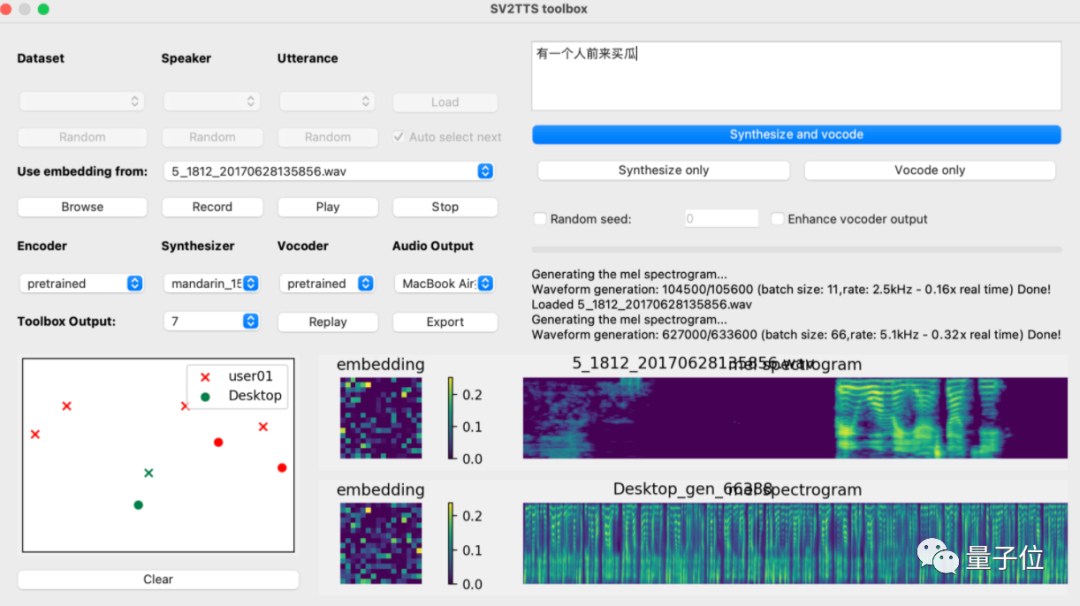
这个时候,就可以上传你想要”克隆”的对象的声音。(支持wav格式,噪音等干扰尽可能低)
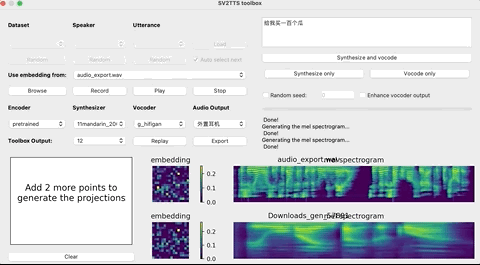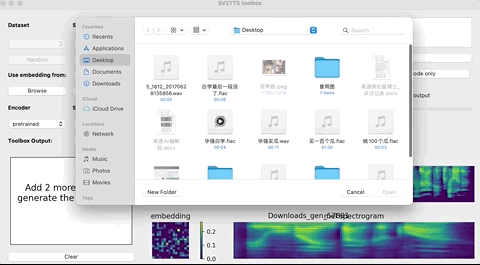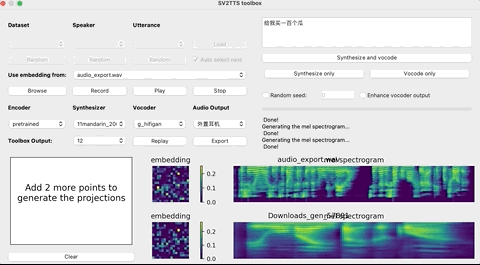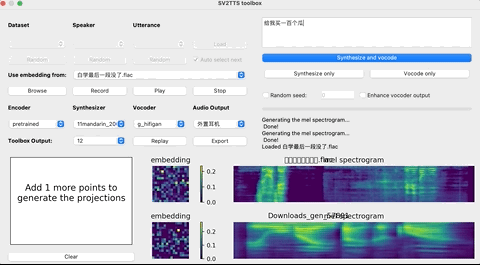
上传录音后,选择想要的合成器和声码器,然后在文本框中输出您要合成的语音文本,并等待片刻。
[En]
After uploading the recording, select the desired synthesizer and vocoder, and then output the voice text you want to synthesize in the text box and wait for a while.
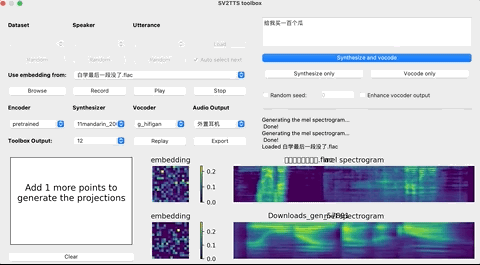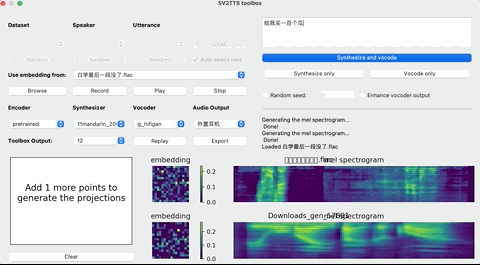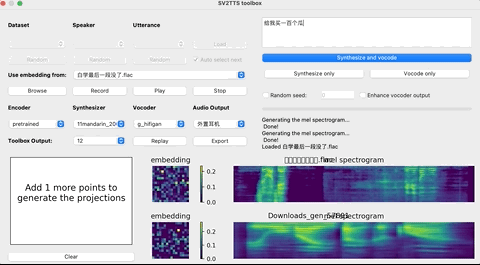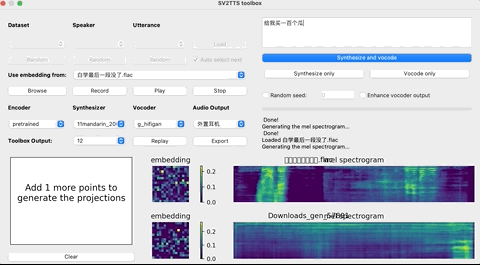
点击Replay,就能听见合成的声音了!
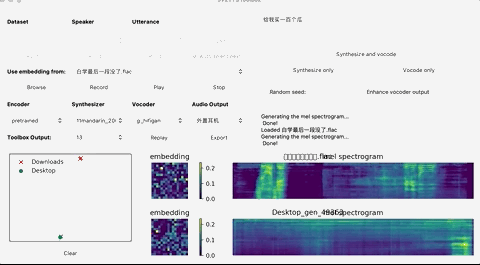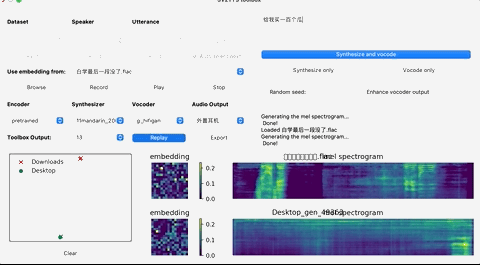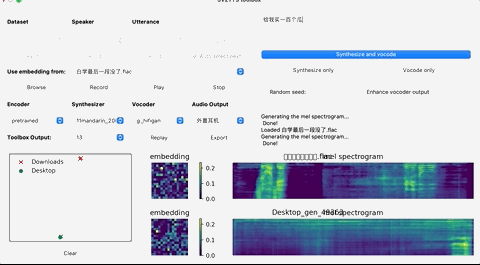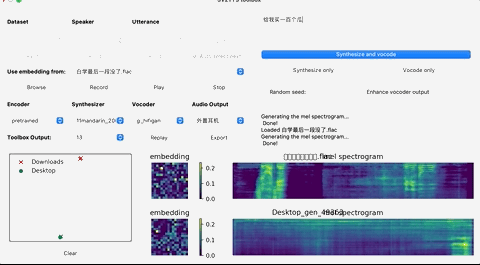
如果想要输出的话,点击Export输出就行,整个界面的基本操作如下:
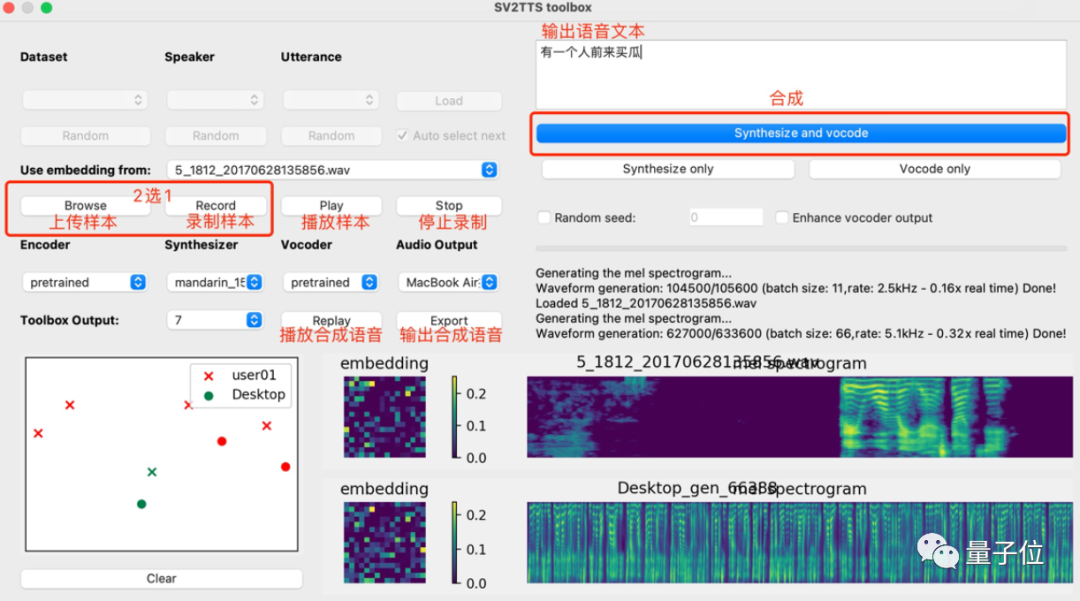
我们在这台电脑上尝试发现,10秒以内的样本+10个字语音文本,合成的时间比较快,如果vocoder采用 Hifi-GAN的话,几乎一秒就能训练完成。
当然,如果你想用自己的数据集和方法训练一个语音克隆模型、或是想训练声码器(vocoder),也可以查看项目中的相关说明(文末附项目地址)。
据作者表示,当出现注意力模型、同时loss(损失)足够低的时候,就表明训练完成了:
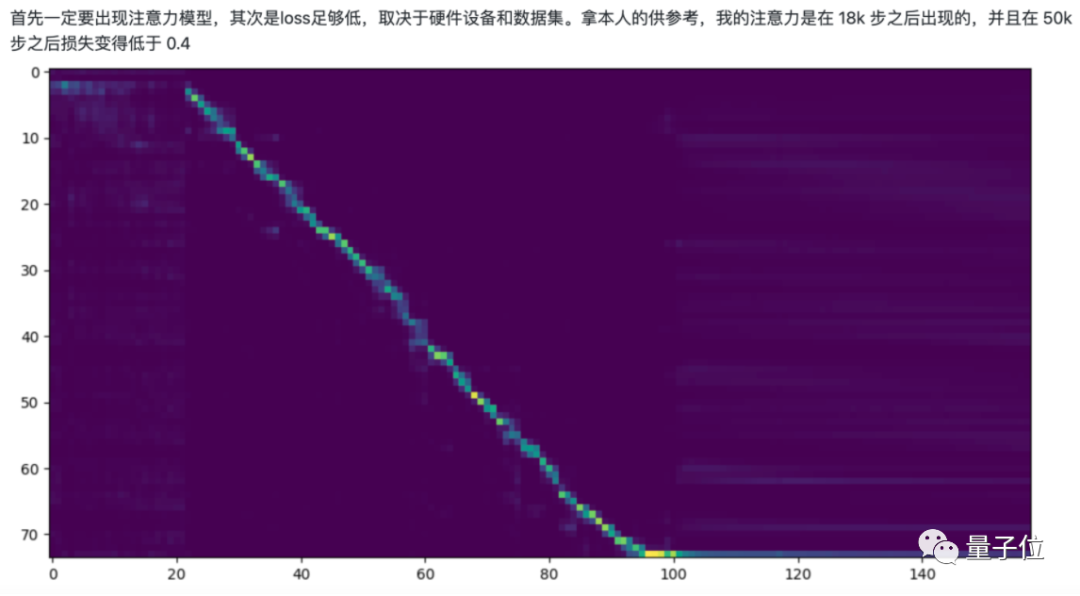
“中文版”SV2TTS模型已开源
那么这个柯南变声器……哦不,实时语音克隆是如何实现的呢?
简单地说,这是一个从语音到文本,然后再到语音的任务。
[En]
Simply put, this is a voice-to-text and then-to-voice task.
要完成这项任务,需要一个由以下三个组件组成的模型结构:
[En]
To accomplish this task, a model structure consisting of the following three components is required:
- 说话人编码器(Speaker encoder)
- 合成器(Synthesizer)
- 声码器(Vocoder)

首先,由说话人编码器( 绿色部分)来提取指定音频的特征向量,相当于学习说话人的音色。
具体地说,使用高度可扩展的神经网络框架来将从语料库计算的对数谱帧序列映射到固定维度的嵌入向量。
[En]
Specifically, a highly scalable neural network framework is used to map the logarithmic spectral frame sequence calculated from the corpus to a fixed-dimensional embedded vector.
在得到这种数字化的音频之后,我们就进入了传统的TTS(Text-to-Speech)环节:
换句话说,说话人的上述语音特征被整合到指定的文本中,以产生相应的语音频谱。
[En]
In other words, the above-mentioned speech features of the speaker are integrated into the specified text to produce the corresponding speech spectrum.
这一部分的合成器( 蓝色部分)采用典型的解码器-编码器结构,中间还加了注意力机制。

再以梅尔频谱(Mel-Spectrogram)作为中间变量,将合成器中生成的语音频谱传到声码器( 红色部分)中。
在这里使用深度自回归模型WaveNet作为声码器,用频谱生成最终的语音。
其实,上述流程基本都来自谷歌在2019年开发的框架 SV2TTS。
当时的预训练模型是 英文的,但也可以在不同的数据集上单独训练,以支持另一种语言。
开发者对”开发另一种语言的模型”给出的建议是:
1、一个足够大的无标注数据集(1000人/1000小时以上),用来训练第一部分Speaker encoder。
2、一个相对小的有标注数据集(300-500小时),用来训练第二、三部分Synthesizer和Vocoder。

这正是Vega在” 汉化“这一模型时所遇到的最大的困难。
他提到,中文多人组的开源数据集比较小,质量没有达到预期效果,在训练中往往很难甚至不可能收敛。
[En]
He mentioned that the open source data sets of Chinese multi-speakers are relatively small, the quality has not achieved the desired results, and it is often difficult or even impossible to converge in training.
在多方搜寻之后,他最终确定了三个中文语音数据集:aidatatang_200zh、magicdata、aishell3。
其中aidatatang_200zh包含了600人200小时的语音数据,magicdata包含1080人755小时的语音数据,aishell3则有85小时的88035句中文语音数据,
而针对难以收敛的问题,Vega在训练早期加入了 Guided Attention以提高收敛速度,再进行多个数据集混合训练的方式,提高中文版的训练成功率。
在不修改模型的核心架构的基础上,他又引入了 HiFi-GAN,使vocoder的推理速度比原先的WaveRNN两到三倍,基本可以在5秒内输出克隆语音。
“希望更多人一起来玩”
那么这个项目背后的故事是什么呢?
[En]
So what’s the story behind this project?
我们与作者 Vega聊了聊。
事实上,当被问及开发该项目的初衷时,他说:一开始只是出于兴趣。
[En]
In fact, when asked about the original intention of developing the project, he said: at first it was just out of interest.
业内已经成熟的TTS技术、可以实时克隆语音的SV2TTS、还有近期的小冰发布会,这都使Vega对语音合成产生了极大的兴趣。
因此,他一方面想尝试提高这类学术项目的可玩性,同时希望国内开发者能一起探索更多的中文语音合成,于是他利用业余时间开始了开发。
[En]
Therefore, on the one hand, he wanted to try to improve the playability of such academic projects, and at the same time, in the hope that domestic developers could explore more Chinese speech synthesis together, he began to develop in his spare time.
但这个完全是个人的项目在早期意外地受到了欢迎。
[En]
But this completely personal project received unexpected popularity in the early days.
不仅标星数有7.6k,社区中也涌现出了大量新的改进反馈,包括不少模型改进建议和项目优化点。
这使得项目越来越完整。
[En]
This makes the project more and more complete.
现在,Vega已经把这次的经验分享给做 西班牙语等其他外语的开发者,未来也可能会把相关成果补充到现在项目中。
他还提到,这种模式有很多潜在的商业场景。
[En]
He also mentioned that there are many potential commercial scenarios for this model.
比如为不想录音或懒得补录的音视频制作者们合成语音,或者帮助主播给打赏DD们发送(合成的)个性语音等等。
在交谈中,Vega也向我们透露了他正在拓展的方向。
例如,跨语言语音合成可以使实时翻译人员最终翻译说话人的音色,或者帮助将分布在多个地区的影视作品配音成语言。
[En]
For example, cross-language speech synthesis can enable real-time translators to finally translate the timbre of the speaker, or help dubbing into languages in film and television works distributed in multiple regions.
当然,现阶段暂时不会去落地太具体的应用,而是把接口和基础能力做好,让社区其他开发者去实现多个有价值的场景。
Vega笑道,在应用这方面主要是广大网友们在探索,他打辅助。
当然,他也提到:
项目现在还是处在一个萌芽阶段,要在实时性、泛性、效果中找到最佳效果还面临着许多困难。
例如,由于模型逻辑会根据标点符号将句子分解成多段文本输入,并独立地并行处理,因此文本的标点符号会影响语音合成的质量。
[En]
For example, because the model logic will break sentences into multi-paragraph text input according to punctuation marks and process them in parallel independently, the * punctuation marks * of the text will affect the quality of speech synthesis.
还有情感语调、方言口音、自然停顿等,也是现在模式面临的问题。
[En]
There are also emotional tone, dialect accent, natural pause and so on, which are also the problems facing the model now.
因此,他希望更多的开发者和爱好者共同努力,加快项目的演进。
[En]
Therefore, he hopes that more developers and enthusiasts will work together to accelerate the evolution of the project.
而关于自己,Vega表示,他在16年就从北美Facebook回国创业,目前正在BAT工作。
他现阶段的工作项目内容包括提供更低成本的沉浸式AI语音互动,主要方向与AI、云原生和元宇宙方向探索比较一致。
而这也是他最大的个人爱好。
[En]
And this is also his biggest personal hobby.
在最后,Vega表示:
我们可以期盼未来,在元宇宙等虚拟世界里面,跟我们互动的不再是念固定台词的NPC,而是一些生动的AI人物,以及一个熟悉或者你想象应该有的声音在对话。
项目地址:
https://github.com/babysor/MockingBird/blob/main/README-CN.md
训练者教程:
https://vaj2fgg8yn.feishu.cn/docs/doccn7kAbr3SJz0KM0SIDJ0Xnhd
参考链接:
[1]https://www.bilibili.com/video/BV1sA411P7wM/
[2]https://www.bilibili.com/video/BV1uh411B7AD/
[3]https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/30
Original: https://blog.csdn.net/QbitAI/article/details/120643961
Author: QbitAl
Title: 只要5秒就能“克隆”本人语音!美玉学姐不再查寝,而是吃起了桃桃丨开源
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/513016/
转载文章受原作者版权保护。转载请注明原作者出处!