

重学深度学习系列—LeNet5实现手写数字识别(TensorFlow2-mnist数据集)
文章目录
- 重学深度学习系列—LeNet5实现手写数字识别(TensorFlow2-mnist数据集)
* - 我的环境:
- 一、LeNet5简单介绍
- 二、LeNet-5代码实现
- 三、训练
- 四、对图片进行预测
- 五、训练过程截图:
- 参考资料
我的环境:
TensorFlow2.3.0 、Pycharm、Windows10
代码已发布在 码云上:https://gitee.com/jiangyi-yan/re-learning-and-deep-learning/tree/master/1.LeNet5_Mnist
或者在 百度网盘下载:
链接:https://pan.baidu.com/s/1J–9eUJMDB9SbRB5xwIr8Q
提取码:2022
–来自百度网盘超级会员V4的分享
一、LeNet5简单介绍
LeNet-5模型由LeCun等人于1998年提出,主要用于手写数字识别和英文字符识别,是卷积神经网络的鼻祖,其网络结构简单,却能取到良好的识别的效果。在MNIST数据集上,LeNet-5模型可以达到99.2%的准确率。
论文链接:http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf
其网络结构图如下:
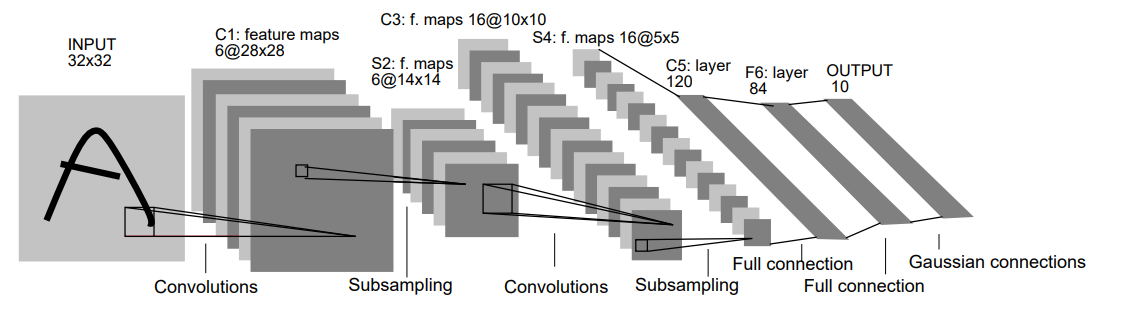

可以看到LeNet5网络 有7层:
1.第1层:卷积层
输入:原始的图片像素矩阵(长度、宽度、通道数),大小为32×32×1;
参数:滤波器尺寸为5×5,深度为6,不使用全0填充,步长为1;
输出:特征图,大小为28×28×6。
分析:因为没有使用全0填充,所以输出尺寸 = 32 – 5 + 1 = 28,深度与滤波器深度一致,为6。
2.第2层:池化层
输入:特征图,大小为28×28×6;
参数:滤波器尺寸为2×2,步长为2;
输出:特征图,大小为14×14×6。
3.第3层:卷积层
输入:特征图,大小为14×14×6;
参数:滤波器尺寸为5×5,深度为16,不使用全0填充,步长为1;
输出:特征图,大小为10×10×16。
分析:因为没有使用全0填充,所以输出尺寸 = 14 – 5 + 1 = 10,深度与滤波器深度一致,为16。
4.第4层:池化层
输入:特征图,大小为10×10×16;
参数:滤波器尺寸为2×2,步长为2;
输出:特征图,大小为5×5×6。
5.第5层:全连接层
输入节点个数:5×5×16 = 400;
参数个数:5×5×16×120+120 = 48120;
输出节点个数:120。
6.第6层:全连接层
输入节点个数:120;
参数个数:120×84+84 = 10164;
输出节点个数:84。
7.第7层:全连接层
输入节点个数:84;
参数个数:84×10+10 = 850;
输出节点个数:10。
; 二、LeNet-5代码实现
model = tf.keras.Sequential([
keras.layers.Conv2D(6,5),
keras.layers.MaxPooling2D(pool_size=2,strides=2),
keras.layers.ReLU(),
keras.layers.Conv2D(16,5),
keras.layers.MaxPooling2D(pool_size=2,strides=2),
keras.layers.ReLU(),
keras.layers.Flatten(),
keras.layers.Dense(120,activation='relu'),
keras.layers.Dense(84,activation='relu'),
keras.layers.Dense(10,activation='softmax')
])
由于MNIST数据集图片大小是28×28的,所以在训练时可以把卷积核尺寸调小为3×3。当然,不修改也没问题。
三、训练
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
batchsize = 32
model = tf.keras.Sequential([
keras.layers.Conv2D(6,5),
keras.layers.MaxPooling2D(pool_size=2,strides=2),
keras.layers.ReLU(),
keras.layers.Conv2D(16,5),
keras.layers.MaxPooling2D(pool_size=2,strides=2),
keras.layers.ReLU(),
keras.layers.Flatten(),
keras.layers.Dense(120,activation='relu'),
keras.layers.Dense(84,activation='relu'),
keras.layers.Dense(10,activation='softmax')
])
model.build(input_shape=(batchsize,28,28,1))
model.summary()
model.compile(optimizer=keras.optimizers.Adam(),
loss = keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
def preprocess(x,y):
x = tf.cast(x,dtype=tf.float32) / 255
x = tf.reshape(x,[-1,28,28,1])
y = tf.one_hot(y,depth=10)
return x,y
(x_train,y_train),(x_test,y_test) = tf.keras.datasets.mnist.load_data()
print('x_train=',type(x_train))
print('y_train=',type(y_train))
train_db = tf.data.Dataset.from_tensor_slices((x_train,y_train))
print('train_db=',type(train_db))
train_db = train_db.shuffle(10000)
train_db = train_db.batch(128)
train_db = train_db.map(preprocess)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
print('test_db=',type(test_db))
test_db = test_db.shuffle(10000)
test_db = test_db.batch(128)
test_db = test_db.map(preprocess)
model.fit(train_db,epochs=10)
model.evaluate(test_db)
model.save('./lenet5.h5')
四、对图片进行预测
前面已经训练过并已经保存了训练后的模型,因此可以调用模型进行预测。
from PIL import Image
import numpy as np
from tensorflow.keras.models import load_model
import cv2
model = load_model('./model/lenet5.h5')
def predict(image_path):
img = Image.open(image_path).convert('L')
img.resize((28,28))
img = np.reshape(img, (28, 28, 1)) / 255.
x = np.array([1 - img])
y = model.predict(x)
print(image_path)
print(y[0])
print('the number is :', np.argmax(y[0]))
if __name__ == "__main__":
img = cv2.imread('./imgs/1.jpg', 0)
img = cv2.resize(img, (28, 28))
cv2.imwrite('./test.jpg', img)
predict('./test.jpg')
我们预测的图片可以是任意尺寸的,但是送入网络预测时都必须resize成28×28的,这里由于我不太熟悉image库,格式调整起来比较麻烦,所以我先用opencv库进行resize再保存下来,然后对这张图片进行预测(比较笨的方法)。
预测结果:


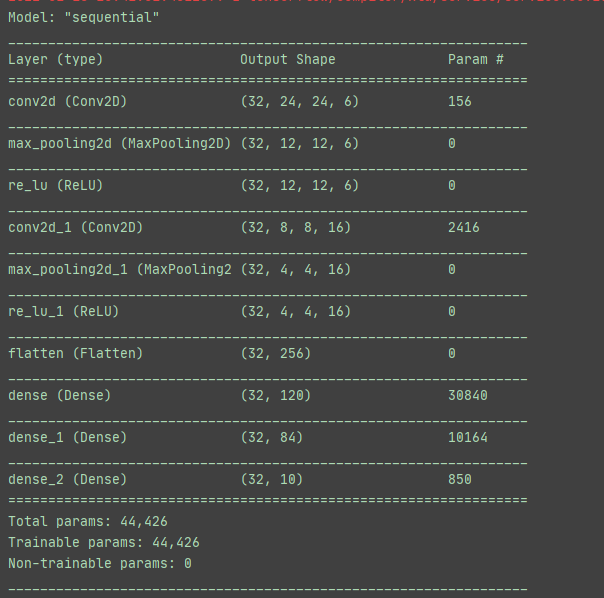
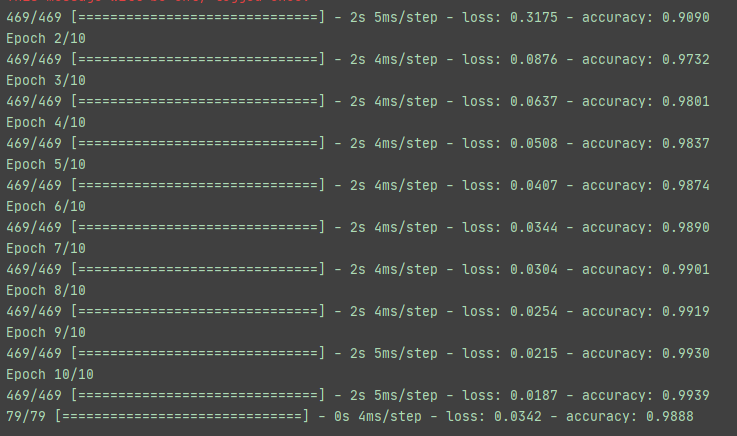
五、训练过程截图:
1.输出网络结构:
2.训练过程:
; 参考资料
1.《深度学习实践教程》吴微
2.LeNet-5论文链接:http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf
Original: https://blog.csdn.net/Aiden_yan/article/details/122999563
Author: 三个臭皮姜
Title: 重学深度学习系列—LeNet5实现手写数字识别(TensorFlow2-mnist数据集)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/496905/
转载文章受原作者版权保护。转载请注明原作者出处!