

1.Pandas中有两个主要的数据结构:Series和DataFrame。
Serise:一维的数据结构。Series是一个类似一维数组的对象,它能够保存任何类型的数据,主要由一组数据和与之相关的索引两部分构成。
构造方法创建:class pandas.Series(data = None,index = None,dtype = None, name = None,copy = False,fastpath = False);
通过传入一个列表来创建一个Series类对象:例:# 创建Series类对象 ser_obj = pd.Series([1, 2, 3, 4, 5])
创建Series类对象,并指定索引 例:ser_obj = pd.Series([1, 2, 3, 4, 5], index=[‘a’, ‘b’, ‘c’, ‘d’, ‘e’]);
除了使用列表构建Series类对象外,还可以使用dict进行构建,例:year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5} ser_obj2 = pd.Series(year_data)
DataFrame:二维的、表格型的数据结构。DataFrame是一个类似于二维数组或表格(如excel)的对象,它每列的数据可以是不同的数据类型。
Pandas的DataFrame类对象可以使用以下构造方法创建:pandas.DataFrame(data = None,index = None,columns = None, dtype = None,copy = False )
通过传入数组来创建DataFrame类对象:例:# 创建数组 demo_arr = np.array([[‘a’, ‘b’, ‘c’], [‘d’, ‘e’, ‘f’]]) # 基于数组创建DataFrame对象 df_obj = pd.DataFrame(demo_arr)
在创建DataFrame类对象时,如果为其指定了列索引,则DataFrame的列会按照指定索引的顺序进行排列。例:df_obj = pd.DataFrame(demo_arr, columns=[‘No1’, ‘No2’, ‘No3’])
可以使用列索引的方式来获取一列数据,返回的结果是一个Series对象。例:# 通过列索引的方式获取一列数据 element = df_obj[‘No2’] # 查看返回结果的类型 type(element)
还可以使用访问属性的方式来获取一列数据,返回的结果是一个Series对象。例:# 通过属性获取列数据 element = df_obj.No2 # 查看返回结果的类型 type(element)
在获取DataFrame的一列数据时,推荐使用列索引的方式完成,主要是因为在实际使用中,列索引的名称中很有可能带有一些特殊字符(如空格),这时使用”点字符”进行访问就显得不太合适了。
2.索引对象
Pandas中的索引都是Index类对象,又称为索引对象,该对象是不可以进行修改的,以保障数据的安全。
重置索引
Pandas中提供了一个重要的方法是reindex(),该方法的作用是对原索引和新索引进行匹配,也就是说,新索引含有原索引的数据,而原索引数据按照新索引排序。
reindex()方法的语法格式如下:
DataFrame.reindex(labels = None,index = None, columns = None,axis = None,method = None, copy = True,level = None,fill_value = nan,limit = None,tolerance = None )
索引操作
Series有关索引的用法类似于NumPy数组的索引,只不过Series的索引值不只是整数。如果我们希望获取某个数据,既可以通过索引的位置来获取,也可以使用索引名称来获取。
虽然DataFrame操作索引能够满足基本数据查看请求,但是仍然不够灵活。为此,Pandas库中提供了操作索引的方法来访问数据,具体包括:loc:基于标签索引(索引名称),用于按标签选取数据。当执行切片操作时,既包含起始索引,也包含结束索引。 iloc:基于位置索引(整数索引),用于按位置选取数据。当执行切片操作时,只包含起始索引,不包含结束索引。
3.算术运算与数据对齐
Pandas执行算术运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没有对齐的位置会用NaN进行补齐。




4.数据排序
01.按索引排序
Pandas中按索引排序使用的是sort_index()方法,该方法可以用行索引或者列索引进行排序 例:sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =’ quicksort ‘,na_position =’last’,sort_remaining = True )
按索引对Series进行分别排序,示例如下。按索引对Series进行分别排序,示例如下。ser_obj = pd.Series(range(10, 15), index=[5, 3, 1, 3, 2]) # 按索引进行升序排列 ser_obj.sort_index() # 按索引进行降序排列 ser_obj.sort_index(ascending = False)
按索引对DataFrame进行分别排序,示例如下。
df_obj = pd.DataFrame(np.arange(9).reshape(3, 3), index=[4, 3, 5]) # 按行索引升序排列 df_obj.sort_index() # 按行索引降序排列 df_obj.sort_index(ascending=False)
Pandas中用来按值排序的方法为sort_values(),该方法的语法格式如下。
sort_values(by,axis=0, ascending=True, inplace=False, kind=’quicksort’,na_position=’last’)
02.按值排序
Pandas中用来按值排序的方法为sort_values(),该方法的语法格式如下。
sort_values(by,axis=0, ascending=True, inplace=False, kind=’quicksort’,na_position=’last’)
按值的大小对Series进行排序的示例如下:ser_obj = pd.Series([4, np.nan, 6, np.nan, -3, 2]) # 按值升序排列 ser_obj.sort_values()
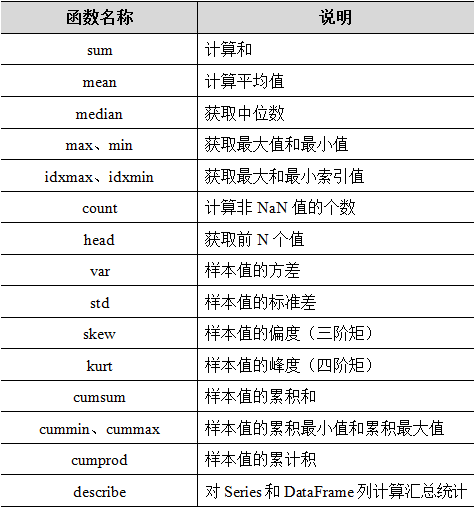
5.统计计算与描述
常用的统计计算:Pandas为我们提供了非常多的描述性统计分析的指标方法,比如总和、均值、最小值、最大值等。
- 层次化索引
什么是层次化索引?前面所涉及的Pandas对象都只有一层索引结构,又称为单层索引,层次化索引可以理解为单层索引的延伸,即在一个轴方向上具有多层索引
Series和DataFrame均可以实现层次化索引,最常见的方式是在构造方法的index参数中传入一个嵌套列表。
7.读写数据操作
01.读写文本文件
在进行数据分析时,通常不会将需要分析的数据直接写入到程序中,这样不仅造成程序代码臃肿,而且可用率很低。常用的解决方法是将待分析的数据存储到本地中,之后再对存储文件进行读取
02.读写Excel文件
Excel文件也是比较常见的存储数据的文件,它里面均是以二维表格的形式显示的,可以对数据进行统计、分析等操作。Excel的文件扩展名有.xls和.xlsx两种。
03.读取HTML表格数据
在浏览网页时,有些数据会在HTML网页中以表格的形式进行展示。对于网页中的表格,可以使用read_html()函数进行读取,并返回一个包含多个DataFrame对象的列表
04.读写数据库
大多数情况下,海量的数据是使用数据库进行存储的,这主要是依赖于数据库的数据结构化、数据共享性、独立性等特点。Pandas 支持Mysql、Oracle、SQLite等主流数据库的读写操作。
总结:简单介绍了常用的数据结构、索引操作、算术运算、数据排序、统计计算与描述、层次化索引和读写数据操作
Original: https://blog.csdn.net/m0_59871294/article/details/123310534
Author: m0_59871294
Title: Pandas数据整理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674274/
转载文章受原作者版权保护。转载请注明原作者出处!