

系列文章目录
实践数据湖iceberg 第一课 入门
实践数据湖iceberg 第二课 iceberg基于hadoop的底层数据格式
实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
实践数据湖iceberg 第四课 在sqlclient中,以sql方式从kafka读数据到iceberg(升级版本到flink1.12.7)
实践数据湖iceberg 第五课 hive catalog特点
实践数据湖iceberg 第六课 从kafka写入到iceberg失败问题 解决
实践数据湖iceberg 第七课 实时写入到iceberg
实践数据湖iceberg 第八课 hive与iceberg集成
实践数据湖iceberg 第九课 合并小文件
实践数据湖iceberg 第十课 快照删除
实践数据湖iceberg 第十一课 测试分区表完整流程(造数、建表、合并、删快照)
实践数据湖iceberg 第十二课 catalog是什么
实践数据湖iceberg 第十三课 metadata比数据文件大很多倍的问题
实践数据湖iceberg 第十四课 元数据合并(解决元数据随时间增加而元数据膨胀的问题)
实践数据湖iceberg 第十五课 spark安装与集成iceberg(jersey包冲突)
实践数据湖iceberg 第十六课 通过spark3打开iceberg的认知之门
实践数据湖iceberg 第十七课 hadoop2.7,spark3 on yarn运行iceberg配置
实践数据湖iceberg 第十八课 多种客户端与iceberg交互启动命令(常用命令)
实践数据湖iceberg 第十九课 flink count iceberg,无结果问题
实践数据湖iceberg 第二十课 flink + iceberg CDC场景(版本问题,测试失败)
实践数据湖iceberg 第二十一课 flink1.13.5 + iceberg0.131 CDC(测试成功INSERT,变更操作失败)
实践数据湖iceberg 第二十二课 flink1.13.5 + iceberg0.131 CDC(CRUD测试成功)
实践数据湖iceberg 第二十三课 flink-sql从checkpoint重启
实践数据湖iceberg 第二十四课 iceberg元数据详细解析
实践数据湖iceberg 第二十五课 后台运行flink sql 增删改的效果
实践数据湖iceberg 第二十六课 checkpoint设置方法
实践数据湖iceberg 第二十七课 flink cdc 测试程序故障重启:能从上次checkpoint点继续工作
实践数据湖iceberg 第二十八课 把公有仓库上不存在的包部署到本地仓库
实践数据湖iceberg 第二十九课 如何优雅高效获取flink的jobId
实践数据湖iceberg 第三十课 mysql->iceberg,不同客户端有时区问题
实践数据湖iceberg 第三十一课 使用github的flink-streaming-platform-web工具,管理flink任务流,测试cdc重启场景
实践数据湖iceberg 第三十二课 DDL语句通过hive catalog持久化方法
实践数据湖iceberg 第三十三课 升级flink到1.14,自带functioin支持json函数
实践数据湖iceberg 第三十四课 基于数据湖icerberg的流批一体架构-流架构测试
实践数据湖iceberg 第三十五课 基于数据湖icerberg的流批一体架构–测试增量读是读全量还是仅读增量
实践数据湖iceberg 第三十六课 基于数据湖icerberg的流批一体架构–update mysql select from icberg语法是增量更新测试
实践数据湖iceberg 第三十七课 kakfa写入iceberg的 icberg表的 enfource ,not enfource测试
实践数据湖iceberg 第三十八课 spark sql, Procedures语法进行数据治理(小文件合并,清理快照)
实践数据湖iceberg 更多的内容目录
文章目录
- 系列文章目录
- 前言
- 一、流数据写入iceberg特点观察
* - 1.1启动程序:
- 1.2 flink 流程序(测试代码)
- 1.2 建表初始化:
- 1.3 写入1条数据,观察变化
- 1.4 再写一条数据,过段事件观察,观察
- 二、重写manifests命令(rewrite_manifests)
* - 2.1 重写manifests命令
- 2.2 观察运行结果:
- 2.3 重写后的效果
- 三、清理过期快照:
* - 3.1 现状
- 3.2 执行清理命令expire_snapshots
- 3.3 清理前后对比
- 四、如何只保留最新的一个快照
* - 4.1 方法
- 4.2 测试
- 4.3 困惑
- 总结
前言
从kafka源写入iceberg,会生成大量的小文件,合并小文件,有代码的方式,spark3结合iceberg0.11后,支持使用sql方式实现文件治理,本文记录 expire_snapshots,rewrite_manifests的运行效果与底层文件的变化
一、流数据写入iceberg特点观察
1.1启动程序:
spark-sql –packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:0.14.0 –conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions –conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog –conf spark.sql.catalog.spark_catalog.type=hive –master yarn
1.2 flink 流程序(测试代码)
代码思路: kakfa(数据源)-> flink-> iceberg (sink的目标)
CREATE TABLE IF NOT EXISTS KafkaTableTest7_XXZH (
data STRING,
dt STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test2_xxzh',
'properties.bootstrap.servers' = 'hadoop101:9092,hadoop102:9092,hadoop103:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'csv.ignore-parse-errors'='true',
'format' = 'csv'
);
CREATE CATALOG hive_iceberg_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://hadoop101:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs:
);
use catalog hive_iceberg_catalog;
CREATE TABLE IF NOT EXISTS ods_base.IcebergTest7_XXZH (
data STRING,
dt STRING
)PARTITIONED BY (
dt
)with(
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'write.distribution-mode'='hash',
'format-version'='2'
);
insert into hive_iceberg_catalog.ods_base.IcebergTest7_XXZH select * from default_catalog.default_database.KafkaTableTest7_XXZH;
1.2 建表初始化:
[root@hadoop103 ~]# hadoop fs -ls -R hdfs:
drwxrwxrwx - root supergroup 0 2022-08-04 16:03 hdfs:
-rw-r--r-- 2 root supergroup 1201 2022-08-04 16:02 hdfs:
-rw-r--r-- 2 root supergroup 2322 2022-08-04 16:03 hdfs:
-rw-r--r-- 2 root supergroup 4125 2022-08-04 16:03 hdfs:
1.3 写入1条数据,观察变化
写入一条数据:
1,20220801
观察表数据:
[root@hadoop103 conf]# hadoop fs -ls -R hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH |awk '{print $6, $7,$8}'|sort
2022-08-04 16:03 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-7015540197464852328-1-180299cd-f163-4695-8759-85905c4d43e3.avro
2022-08-04 16:04 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-7144650321142379888-1-b31f02f1-4b8f-4003-baae-ecdc258180d8.avro
2022-08-04 16:05 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-3819154392661074521-1-b7eee28d-89a9-402c-b8ac-9a5def8a2245.avro
2022-08-04 16:06 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-8187734273894574790-1-f92a15bc-f57a-4580-8081-980e38bf1b1b.avro
2022-08-04 16:07 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-4248793097915233562-1-fc5ec98a-2709-4ec9-be1e-957ccc8e124a.avro
2022-08-04 16:08 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-1006348809607734885-1-bc344d40-6f23-4a9a-a701-b972b5e12d1c.avro
2022-08-04 16:08 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-1369813675709342441-1-ce3001db-93c2-43cf-93fb-d53f00964ce2.avro
2022-08-04 16:09 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-3072154423344214182-1-108aa7b5-5426-40b0-b77b-f3f61dab6057.avro
2022-08-04 16:10 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-2428208290769007949-1-3e191fbe-60ef-4a46-82a3-4a27d888a0ff.avro
2022-08-04 16:11 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6011233629641043795-1-003f319a-99dd-4ff1-b799-1205ff1ae33a.avro
2022-08-04 16:12 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data
2022-08-04 16:12 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data/dt=20220801
2022-08-04 16:12 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data/dt=20220801/00001-0-989c0c01-b69d-4c66-8c74-7a1a4be08f71-00001.parquet
2022-08-04 16:12 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/eec56515-195b-4b5f-a1a9-beafbae656bd-m0.avro
2022-08-04 16:12 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-5669443397673762268-1-2c16071a-3c1e-440d-8b0c-67d8b0a3702b.avro
2022-08-04 16:12 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6635568546667780520-1-eec56515-195b-4b5f-a1a9-beafbae656bd.avro
2022-08-04 16:13 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6452117411154735532-1-58cf7c5f-9f10-41be-9860-2abd2288fcbc.avro
2022-08-04 16:14 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6114394013141026250-1-ace0ccab-4f34-44d3-b74e-a830b28380c3.avro
2022-08-04 16:15 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-8532941383629006602-1-652902e7-8b6b-4a92-921b-bfe3179ae31d.avro
2022-08-04 16:16 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-1172930612474802936-1-d01a8927-70a1-48b2-8650-b0eff09fd4c1.avro
2022-08-04 16:16 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-1577282669537289637-1-baabf721-8b12-43c8-9cb6-84db7284ee27.avro
2022-08-04 16:17 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-530460642871764108-1-93516051-aa1c-4254-9c98-bed046c0b127.avro
2022-08-04 16:18 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-4680338974405521972-1-cd20b3c6-730e-4f00-ae27-cf2677495497.avro
2022-08-04 16:19 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-5544880175863673343-1-9f7e9d3a-8f71-4f96-a5db-1e4edec203e2.avro
2022-08-04 16:20 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-5272762953086455016-1-a83a2bf4-a766-4d7f-a431-2e1746591b16.avro
2022-08-04 16:21 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-2346169869347739328-1-ad3a47b7-b9e9-4c10-85eb-68a9e7d0da8e.avro
2022-08-04 16:21 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-8724483081204444198-1-28d8fde1-bf72-487e-b658-18d5fba5f809.avro
2022-08-04 16:22 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-9148228807971786797-1-5d7fc4ec-7d24-4ff3-a828-5cc9deb5b404.avro
2022-08-04 16:23 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6156800269843105536-1-16ebe8d7-e5f9-472b-972b-bf76ae3ba97f.avro
2022-08-04 16:24 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-9112397311397340901-1-70f431c5-385e-408c-ba8e-2dacbee1648d.avro
2022-08-04 16:25 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6482606870489008608-1-64c8eb70-42dd-4ddf-b23b-b623fe98bcb8.avro
2022-08-04 16:26 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-2419382668769143169-1-c8881b84-f089-47ad-9d43-cb1867e55618.avro
2022-08-04 16:26 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-6286593410434823611-1-01e7de9c-660a-4798-93be-17e67a856a31.avro
2022-08-04 16:27 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-57143902220252123-1-a9b51af8-7605-4eb0-b8e8-bb5abe92436a.avro
2022-08-04 16:28 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-7043870422200970250-1-b68cefa9-a8e8-4946-b78d-99f3e04ad282.avro
2022-08-04 16:29 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-3357030648636652240-1-4f2e72e5-b187-4be8-b882-70d353f5c095.avro
2022-08-04 16:30 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/00033-b39f61ad-9ad0-4897-8948-222ccb140716.metadata.json
2022-08-04 16:30 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-8082939696210937324-1-cd6b5068-1f66-4018-9b8f-b55574e75195.avro
2022-08-04 16:31 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/00034-df975976-929e-4719-a4cb-9707b4cbc928.metadata.json
2022-08-04 16:31 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/00035-be4cbee5-d2aa-4230-a8f3-34cf10b9fedf.metadata.json
2022-08-04 16:31 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-1645047173824264185-1-a9f12a05-358a-402a-a7fb-d8b990fb3484.avro
2022-08-04 16:31 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-3111474233869072402-1-15d82c4d-6580-4468-875c-f71fc34f3254.avro
2022-08-04 16:32 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/00036-ad3cc17e-b7ef-4a9e-93a3-aeb7a4ed8b82.metadata.json
2022-08-04 16:32 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-3367710178201430942-1-af803435-8789-42cb-a452-28a132105033.avro
2022-08-04 16:33 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/00037-5d660b47-d702-428d-8347-6c48e19eab6b.metadata.json
2022-08-04 16:33 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-3642153106573581282-1-319392a8-2756-4128-833d-4ee6c5549fb5.avro
2022-08-04 16:34 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata
2022-08-04 16:34 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/00038-0dc82ed4-9c32-44e3-a4dc-5fecd6bdbd6d.metadata.json
2022-08-04 16:34 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata/snap-1481475376486473777-1-e042a05d-637b-4b3a-a8e3-a1c3542f89c8.avro
发现不断产生新的snap文件。
1.4 再写一条数据,过段事件观察,观察
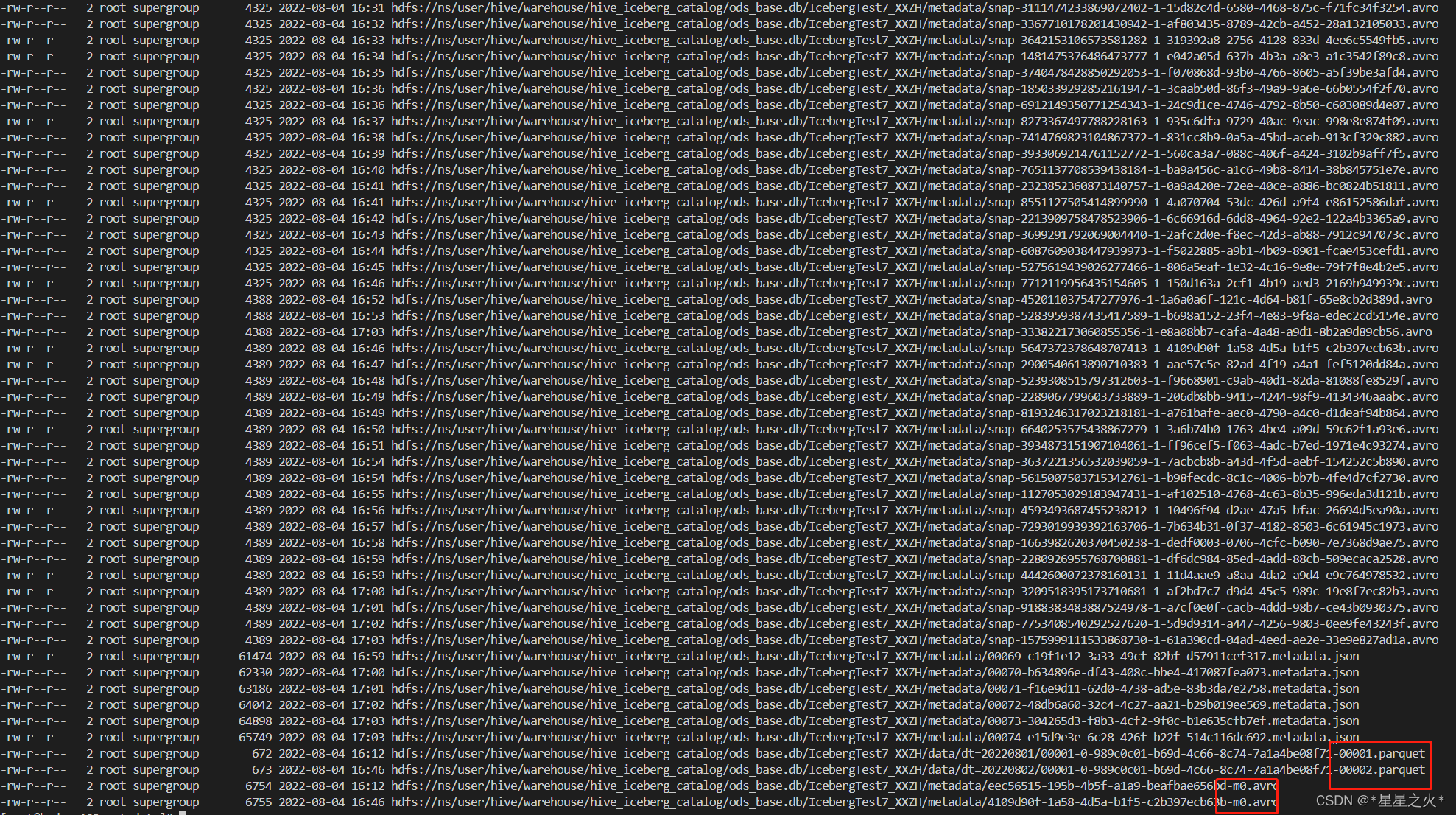

结论:
- 数据文件和 m0,m1.avro manifest文件是一致的,有写数据,就有新增。
- 其他snap文件,就算没有写数据,由于flink 流每分钟checkpoint一次,每分钟都会生成snap文件。
- metadata.json只保留5个。
; 二、重写manifests命令(rewrite_manifests)
2.1 重写manifests命令
spark-sql (default)> CALL hive_iceberg_catalog.system.rewrite_manifests('ods_base.IcebergTest7_XXZH')
rewritten_manifests_count added_manifests_count
2 1
Time taken: 9.08 seconds, Fetched 1 row(s)
2.2 观察运行结果:
-rw-r--r-- 2 root supergroup 6754 2022-08-04 16:12 hdfs:
-rw-r--r-- 2 root supergroup 6755 2022-08-04 16:46 hdfs:
-rw-r--r-- 2 root supergroup 6798 2022-08-04 17:11 hdfs:
hdfs结果,多了一个m0.avro文件
第二个m0文件的内容:
[root@hadoop103 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty 4109d90f-1a58-4d5a-b1f5-c2b397ecb63b-m0.avro
22/08/04 17:15:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"status" : 1,
"snapshot_id" : {
"long" : 5647372378648707413
},
"sequence_number" : null,
"data_file" : {
"content" : 0,
"file_path" : "hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data/dt=20220802/00001-0-989c0c01-b69d-4c66-8c74-7a1a4be08f71-00002.parquet",
"file_format" : "PARQUET",
"partition" : {
"dt" : {
"string" : "20220802"
}
},
"record_count" : 1,
"file_size_in_bytes" : 673,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 52
}, {
"key" : 2,
"value" : 59
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "2"
}, {
"key" : 2,
"value" : "20220802"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "2"
}, {
"key" : 2,
"value" : "20220802"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"equality_ids" : null,
"sort_order_id" : {
"int" : 0
}
}
}
2.3 重写后的效果
最新的manifest文件内容,发现包括签名两次写数据的文件地址。果然是重写了manifest
[root@hadoop103 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty fe4c8846-b07c-42e4-98c2-68aed69fbfd0-m0.avro
22/08/04 17:14:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"status" : 0,
"snapshot_id" : {
"long" : 6635568546667780520
},
"sequence_number" : {
"long" : 12
},
"data_file" : {
"content" : 0,
"file_path" : "hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data/dt=20220801/00001-0-989c0c01-b69d-4c66-8c74-7a1a4be08f71-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"dt" : {
"string" : "20220801"
}
},
"record_count" : 1,
"file_size_in_bytes" : 672,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 52
}, {
"key" : 2,
"value" : 58
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "1"
}, {
"key" : 2,
"value" : "20220801"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "1"
}, {
"key" : 2,
"value" : "20220801"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"equality_ids" : null,
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 0,
"snapshot_id" : {
"long" : 5647372378648707413
},
"sequence_number" : {
"long" : 53
},
"data_file" : {
"content" : 0,
"file_path" : "hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data/dt=20220802/00001-0-989c0c01-b69d-4c66-8c74-7a1a4be08f71-00002.parquet",
"file_format" : "PARQUET",
"partition" : {
"dt" : {
"string" : "20220802"
}
},
"record_count" : 1,
"file_size_in_bytes" : 673,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 52
}, {
"key" : 2,
"value" : 59
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "2"
}, {
"key" : 2,
"value" : "20220802"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "2"
}, {
"key" : 2,
"value" : "20220802"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"equality_ids" : null,
"sort_order_id" : {
"int" : 0
}
}
}
三、清理过期快照:
3.1 现状
[root@hadoop103 metadata]# hadoop fs -count hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/*
3 2 1345 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/data
1 114 1015402 hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/IcebergTest7_XXZH/metadata
3.2 执行清理命令expire_snapshots
CALL hive_iceberg_catalog.system.expire_snapshots('ods_base.IcebergTest7_XXZH', TIMESTAMP '2022-08-04 17:20:00.000', 10);
22/08/04 17:29:58 INFO ExpireSnapshotsSparkAction: Deleted 96 total files
22/08/04 17:29:58 INFO CodeGenerator: Code generated in 5.686129 ms
deleted_data_files_count deleted_position_delete_files_count deleted_equality_delete_files_count deleted_manifest_files_count deleted_manifest_lists_count
0 0 0 2 94
3.3 清理前后对比

观察hadoop文件:
[root@hadoop103 metadata]# hadoop fs -ls -R hdfs:
ls: {print $6, $7,$8}': No such file or directory
ls: ': No such file or directory
drwxrwxrwx - root supergroup 0 2022-08-04 16:12 hdfs:
drwxrwxrwx - root supergroup 0 2022-08-04 16:46 hdfs:
drwxrwxrwx - root supergroup 0 2022-08-04 16:46 hdfs:
drwxrwxrwx - root supergroup 0 2022-08-04 17:31 hdfs:
-rw-r--r-- 2 root supergroup 12657 2022-08-04 17:29 hdfs:
-rw-r--r-- 2 root supergroup 13515 2022-08-04 17:30 hdfs:
-rw-r--r-- 2 root supergroup 14373 2022-08-04 17:31 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:20 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:21 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:22 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:23 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:23 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:27 hdfs:
-rw-r--r-- 2 root supergroup 4328 2022-08-04 17:28 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:24 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:25 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:26 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:28 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:29 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:30 hdfs:
-rw-r--r-- 2 root supergroup 4329 2022-08-04 17:31 hdfs:
-rw-r--r-- 2 root supergroup 672 2022-08-04 16:12 hdfs:
-rw-r--r-- 2 root supergroup 673 2022-08-04 16:46 hdfs:
-rw-r--r-- 2 root supergroup 6798 2022-08-04 17:11 hdfs:
-rw-r--r-- 2 root supergroup 91448 2022-08-04 17:28 hdfs:
-rw-r--r-- 2 root supergroup 92306 2022-08-04 17:28 hdfs:
-rw-r--r-- 2 root supergroup 93164 2022-08-04 17:29 hdfs:
四、如何只保留最新的一个快照
4.1 方法
设置一个未来的时间,保留快照数改为1:
spark-sql (default)> CALL hive_iceberg_catalog.system.expire_snapshots(‘ods_base.IcebergTest7_XXZH’, TIMESTAMP ‘2022-08-04 18:40:00.000’, 1);
4.2 测试
亲测可用,在直接在另一个表上使用,效果如下:
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61241 2888554340 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 20221 232584490 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]#
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61241 2888554340 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 17821 205501422 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61241 2888554340 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 16263 182039573 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61241 2888554340 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 11450 108681997 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61241 2888554340 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 10157 100110951 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61239 2888516037 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 8932 91926494 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61239 2888516037 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 7662 83453284 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61241 2888552336 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 6432 75322270 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]#
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61239 2888501351 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 5458 65798470 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61239 2888501351 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 4303 47515641 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61239 2888501351 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 2110 15801935 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61089 2802851696 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 1030 8542583 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
[root@hadoop101 ~]# hadoop fs -count /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/*
1160 61089 2802851696 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/data
1 28 1867063 /user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_client_log/metadata
4.3 困惑
有的表怎么清理都清不掉。。。什么原因?????????
总结
自动清理元数据配置:
每次发生变更,都会造成元数据的变化,iceberg会生成新的metadata数据,
就的元数据默认保存下来,频繁更新的表,需要定时清理元数据,
也有自动清理元数据的方法:把一下配置增加到表属性就可以。
write.metadata.delete-after-commit.enabled=true
write.metadata.previous-versions-max=10
清理快照
CALL hive_iceberg_catalog.system.expire_snapshots(‘ods_base.xx_table_name’, TIMESTAMP ‘2022-08-03 00:00:00.000’, 10);
重写数据文件,但不回删原来文件,删除还需要清理快照
CALL hive_iceberg_catalog.system.rewrite_data_files(‘ods_base.xx_table_name’);
//false 就是不用spark的cache,避免OOM
CALL hive_iceberg_catalog.system.rewrite_manifests(‘ods_base.xx_table_name’, false)
CALL hive_iceberg_catalog.system.rewrite_manifests(‘ods_base.xx_table_name’)
清理孤儿文件,孤儿文件指没有被元数据引用到的文件
CALL hive_iceberg_catalog.system.remove_orphan_files(table => ‘ods_base.xx_table_name’, dry_run => true)
tablelocation 改为具体的表地址,会清理不用的文件,
CALL hive_iceberg_catalog.system.remove_orphan_files(table => ‘ods_base.xx_table_name’, location => ‘tablelocation/data’)
CALL hive_iceberg_catalog.system.remove_orphan_files(table => ‘ods_base.xx_table_name’, location => ‘hdfs://ns/user/hive/warehouse/hive_iceberg_catalog/ods_base.db/xx_table_name/data’)
Original: https://blog.csdn.net/spark_dev/article/details/126161429
Author: 星星之火
Title: 实践数据湖iceberg 第三十八课 spark sql, Procedures语法进行数据治理(小文件合并,清理快照)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/818084/
转载文章受原作者版权保护。转载请注明原作者出处!