

1. 摘要
基于上次分享的分词技术介绍,本次继续分享在分词后与词相关联的两个技术:词性标注和命名实体识别。词性是词汇基本的语法属性,也可以称为词类。词性标注的行为就是在给定的中文句子中判定每个词的语法作用,确定每个词的词性并加以标注。命名实体识别在信息检索方面有着很重要作用,检测出代表性的名称,下面我们深入了解下这两个技术。
2. 词性标注
首先简单举例说明一下中文词性标注的应用效果。例如,表示地点、事物、姓名的这类词语称为名词,表示状态变化的称为动词,描述或修饰名词的称为形容词。示例句子:”中国是非常繁荣稳定的国家”。对这句话做词性标注结果如下:”中国/名词 是/动词 非常/副词 繁荣/形容词 稳定/形容词 的/结构助词 国家/名词”。
在中文句子中,一个同音同形的词处在不同的上下文时,语法的属性是截然不同的,由于这个原因,这就给中文词性标注带来很大的困难。但是从中文词语整体的使用情况来看,大多数的词语,尤其是实词,一般是有一到二个词性,并且通过统计发现,其中一个词性的使用频次远大于另外词性。所以即使每次都将高频的词性作为其词性,也能够实现很高的准确率。只要我们对常用词的词性能够进行很精准的识别,使用时也能够覆盖绝大多数的场景。
词性标注最简单的方法就是从语料库中统计每个词所对应的高频词性,将其作为默认的词性,但基于这种方法的词性标注还是有提醒空间的。目前较为主流的方法和分词相似,将句子的词性标注作为一个序列标注问题看待,这样隐马尔可夫模型、条件随机场模型都可以应用于词性标注任务中。
词性标注规范表
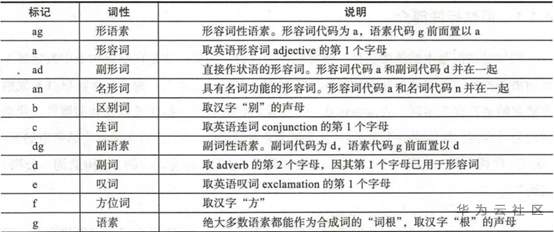

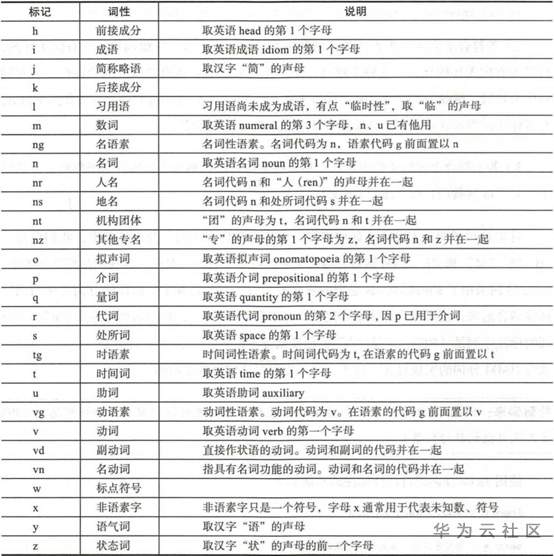
图1:词性标注规范表
3. 命名体识别
与自动分词、词性标注技术相同,命名体识别也是自然语言处理领域的一个基础任务,是信息抽取、信息检索、机器翻译以及问答系统等多种自然语言处理技术必不可少的组成部分。其主要目的是识别语料中的人名、地方名、组织机构名等一些命名实体。由于这些命名实体数量在不断的增加,通过词典是不可能完全列出的,且这些命名实体构成方法具有各自的规律性,因此,通常需要将这些词的识别在词汇形态处理任务中单独处理,称为命名体识别(Named Entities Recognition,NER)。通常情况下命名体识别可以分为三大类:实体类、时间类、数字类,和七个小类:人名、地名、组织机构名、时间、日期、货币、百分比。在识别数量、时间、日期、货币这些小类别实体的时候,可以采用模式匹配的方式获得较好的识别效果,难点在于人名、地名、组织机构名,因为这三类实体名称结构复杂,因此研究方向主要以这三类实体名称为主。
并且中文的命名体识别对比英文难度更大。命名体识别效果的评判主要看实体的边界是否划分正确以及实体的类型是否标注正确。在英文中,命名实体一般是具有较为明显的形式标志,因为英文命名实体的每个词的首字母都是大写形式,因此英文中实体边界识别相对容易很多,重点是在对实体类型的确定。而在汉语当中,相较于实体类别标注任务,实体边界的识别更加困难。
中文命名实体识别主要有一下的难点:各类命名实体数量众多、命名实体的构成规律复杂、嵌套情况复杂、长度不确定。
在分词的介绍中,我们主要列出来三种方式:基于规则的方法、基于统计的方法以及混合使用方法。在整个NLP的命名实体识别中也不例外。
基于规则的命名实体识别:规则加词典是早期命名实体识别中最行之有效的方法,主要依赖于手工规则的系统,结合命名实体库,对每一条规则进行权重的赋值,然后再通过实体与规则的相符程度进行类型的判断。当提取的规则能够较好的反应语言的现象时,此方法的效果明显优于其他方法。但是在大多数的情境下,规则往往依赖于具体的语言、领域和文本的风格,并且其编制的过程非常耗时,也难以涵盖所有的语言现象,更新维护非常困难。
基于统计的命名实体识别:目前主流的基于统计的命名实体识别方法主要有隐马尔可夫模型、最大熵模型、条件随机场等等。主要的思想是:基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计方法对语料库质量的依赖比较大,而规模大质量高的语料库很少,是此类方法的一个制约。
混合方法:NLP并不完全是随机的过程,如果仅使用基于统计的方法会使搜索空间非常的庞大,所以需要提前借助规则方法进行过滤修剪处理。所以在很多情况下是使用混合方法的。
基于条件随机场的命名实体识别
在进入条件随机场之前,我们首先要了解下HMM。上次我们分享到HMM是将分词作为字标注问题解决的,这里面有两个非常关键的假设:一是输出观察值之间相互独立,二是状态的转移过程中当前状态只与前一状态有关。因为这两个假设的成立,使得HMM便于计算。但是在多数的场景下,尤其是在大量真实语料中,观察序列更多是以一种多重的交互特征形式表现出来的,观察到元素之间广泛存在着长程相关性。此时的HMM就受到很大的限制。
基于上述原因,条件随机场被开创出来,主要的思想是源于HMM的,也是一种用来标记和切分序列化数据的统计模型。不同的是,条件随机场是在给定的标记序列下,计算整个标记序列的联合概率,而HMM则是在给定当前状态下,去定义下一个状态的分布。
条件随机场的定义:
假设X=(X1,X2,X3,…,Xn)和Y=(Y1,Y2,Y3,…,Ym)是联合随机变量,若随机变量Y构成一个无向图G=(V,E)表示的马尔可夫模型,则其条件概率分布P(Y|X)就称为条件随机场(Conditional Random Field,CRF),公式表示为
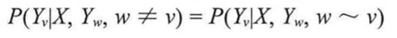
图2:条件随机场表达式
其中w-v表示图G=(V,E)中与节点v有边连接的所有结点,w!=v表示节点v以外的所有结点。
在这里简单的说明一下随机场的概念:现有若干个位置组成的整体,当给某一个位置按照某种分布随机的赋予一个值后,则该整体被称为随机场。如果以机构地名为例子,并假定如下规则。
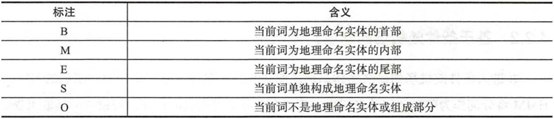
图3:标注表
现有n个字符构成的NER的句子,每个字符的标签都在我们已知的标签集合中选择好,当我们为每个字符选定标签后,就形成一个随机场。若在其中加入一些约束,比如所有的字符的标签只与相邻的字符的标签相关,那么此时就是马尔可夫随机场问题。马尔可夫随机场中有X和Y两种变量,X一般是给定的,Y是在给定X条件下的输出。那么在这里,X是字符,Y是标签,P(X|Y)就是条件随机场。
在条件随机场的定义中,我们并未规定变量X与Y具有相同的结构,实际在自然语言处理中,很多情况下假设其结构是相似的,表示为
X=(X1,X2,X3,…,Xn),Y=(Y1,Y2,Y3,…,Ym)
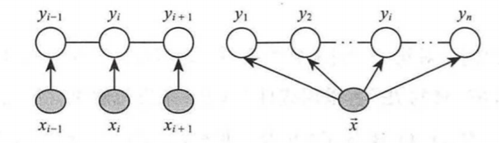
图4:线性条件随机场
一般称这种结构为线性链条件随机场,可以定义为:假设X=(X1,X2,X3,…,Xn和Y=(Y1,Y2,Y3,…,Ym)均为线性链表示的随机变量序列,若在给定的随机变量序列X的条件下,随机变量序列Y的条件概率分布P(Y|X)构成条件随机场,并且满足马尔可夫性质:
P(Yi|X,Y1,Y2,…,Ym)=P(Yi|X,Yi-1,Yi+1)
那么,可以称P(Y|X)为线性链的条件随机场。
对比于HMM,这里的线性链不仅考虑了上一个状态Yi-1,还考虑了后面一个状态Yi+1。可以通过下图直观表示。
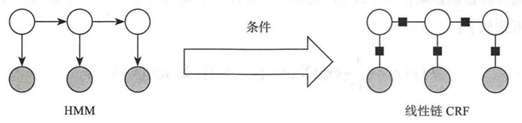
图5:HMM与线性链
在该图中可以看到HMM属于一个有向图,而本次重点的线性链是一个无向图,也因此,HMM处理时,本次状态依赖于上一个状态,而线性链则是依赖于当前状态的周围节点的状态。
当解决标注问题时,HMM和条件随机场都是不错的选择,然而相较于HMM性质,线性链更能够捕捉到全局的信息,并且效果很好,但在模型计算复杂度上比起HMM要高出很多。
4. 总结
本次分享的首先是词性标注内容,说明了词性标注环节在自然语言处理中起到的作用,分析了常用的词性标注方法和该技术目前所受到的限制。然后是命名实体识别原理和作用的说明,重点描述了基于条件随机场模型的命名实体识别技术,以及和HMM模型效果和复杂度上的的对比。
本次的词性标注和命名实体识别技术已分享完成,由于本人水平有限,文章中难免会出现错误的地方,欢迎大家在下方指正讨论
Original: https://blog.csdn.net/xi_xiyu/article/details/122682271
Author: xi_xiyu
Title: 自然语言处理之——词性标注和命名实体识别
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531440/
转载文章受原作者版权保护。转载请注明原作者出处!