

Flink常用API之转换算子->Map、reduce、Filter、KeyBy、Aggregations
原创
wx62be9d88ce294博主文章分类:大数据 ©著作权
文章标签 flink big data hdfs 数据集 数据 文章分类 Hadoop 大数据
©著作权归作者所有:来自51CTO博客作者wx62be9d88ce294的原创作品,请联系作者获取转载授权,否则将追究法律责任
DataStream 转换算子:
即通过从一个或多个 DataStream 生成新的 DataStream 的过程被称为 Transformation 操作。在转换过程中,每种操作类型被定义为不同的 Operator,Flink 程序能够将多个 Transformation 组成一个 DataFlow 的拓扑。
- Map [DataStream->DataStream]
调 用 用 户 定 义 的 MapFunction 对 DataStream[T] 数 据 进 行 处 理 , 形 成 新 的 Data-Stream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。例 如将输入数据集中的每个数值全部加 1 处理,并且将数据输出到下游数据集。
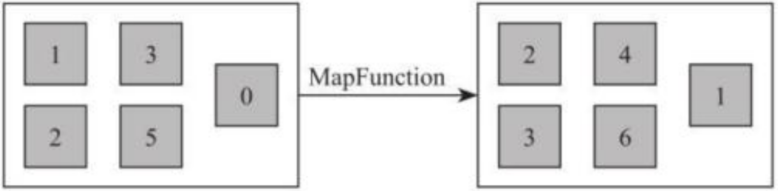

- FlatMap [DataStream->DataStream]
该算子主要应用处理输入一个元素产生一个或者多个元素的计算场景,比较常见的是在 经典例子 WordCount 中,将每一行的文本数据切割,生成单词序列如在图所示,对于输入 DataStream[String]通过 FlatMap 函数进行处理,字符串数字按逗号切割,然后形成新的整 数数据集。

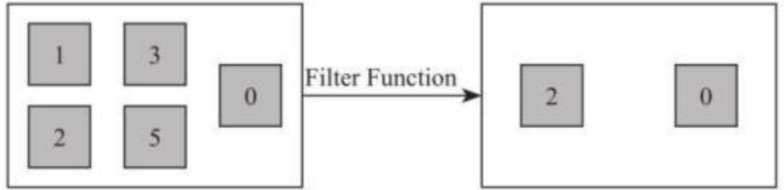
- Filter [DataStream->DataStream]
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条 件的数据过滤掉。如下图所示将输入数据集中偶数过滤出来,奇数从数据集中去除。
- KeyBy [DataStream->KeyedStream]
该算子根据指定的 Key 将输入的 DataStream[T]数据格式转换为 KeyedStream[T],也就 是在数据集中执行 Partition 操作,将相同的 Key 值的数据放置在相同的分区中。如下图所 示,将白色方块和灰色方块通过颜色的 Key 值重新分区,将数据集分为具有灰色方块的数据 集合。
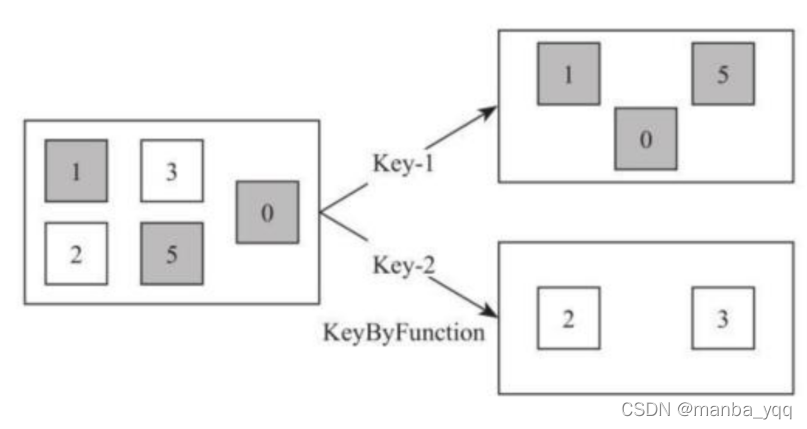
将数据集中第一个参数作为 Key,对数据集进行 KeyBy 函数操作,形成根据 id 分区的 KeyedStream 数据集。其中 keyBy 方法输入为 DataStream[T]数据集。 - Reduce [KeyedStream->DataStream]
该算子和 MapReduce 中 Reduce 原理基本一致,主要目的是将输入的 KeyedStream 通过 传 入 的 用 户 自 定 义 的 ReduceFunction 滚 动 地 进 行 数 据 聚 合 处 理 , 其 中 定 义 的 ReduceFunciton 必须满足运算结合律和交换律。如下代码对传入 keyedStream 数据集中相 同的 key 值的数据独立进行求和运算,得到每个 key 所对应的求和值。 - Aggregations[KeyedStream->DataStream]
Aggregations 是 KeyedDataStream 接口提供的聚合算子,根据指定的字段进行聚合操 作,滚动地产生一系列数据聚合结果。其实是将 Reduce 算子中的函数进行了封装,封装的 聚合操作有 等,这样就不需要用户自己定义 Reduce 函数。 如下代码所示,指定数据集中第一个字段作为 key,用第二个字段作为累加字段,然后滚动 地对第二个字段的数值进行累加并输出。
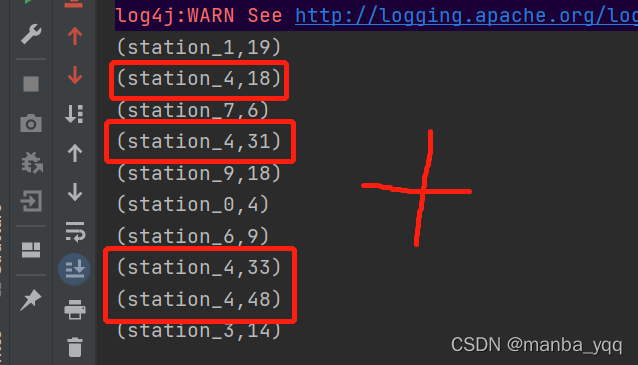
package transformationimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport source.{MyCustomerSource, StationLog} object TestTransformation{ def main(args: Array[String]): Unit = { val en = StreamExecutionEnvironment.getExecutionEnvironment en.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[StationLog] = en.addSource(new MyCustomerSource) stream.filter(_.callType.equals("success")) .map(log=>{(log.sid,log.duration)}) .keyBy(0) .reduce((t1,t2)=>{ var duration = t1._2+t2._2 (t1._1,duration) }).print() en.execute() }}
- 赞
- 收藏
- 评论
- *举报
Original: https://blog.51cto.com/u_15704423/5434849
Author: wx62be9d88ce294
Title: Flink常用API之转换算子->Map、reduce、Filter、KeyBy、Aggregations
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516962/
转载文章受原作者版权保护。转载请注明原作者出处!