

自从美赛过去后好久没玩Python了,很多函数忘了,好不熟练。因为学科作业和舍友问我些了个python的作业,打算记录一下。


这个是我舍友网上自学Python时的一个问题,常规的切片操作。
import pandas as pd
Data=pd.Series(data=['大数据','互联网',
'技术','数据','结构化',
'处理','难点','分析',
'很大','合适','平台'])
x='互联网大数据技术与分析平台'
x+=' '
ans=''
while len(x)>1:
f=0
for i in range(-1,-len(x),-1):
y=x[:i]
for j in range(11):
if y==Data[j]:
ans+=Data[j]
ans+='/'
x=x[i:]
f=1
break
if f==1:
break
if f==0:
ans+=x[0:1]
ans+='/'
x=x[1:]
print(ans[:-1])
因为我逆取,最后一位涉及不到,所以加了个空字符,还能化简,但这思路简单。
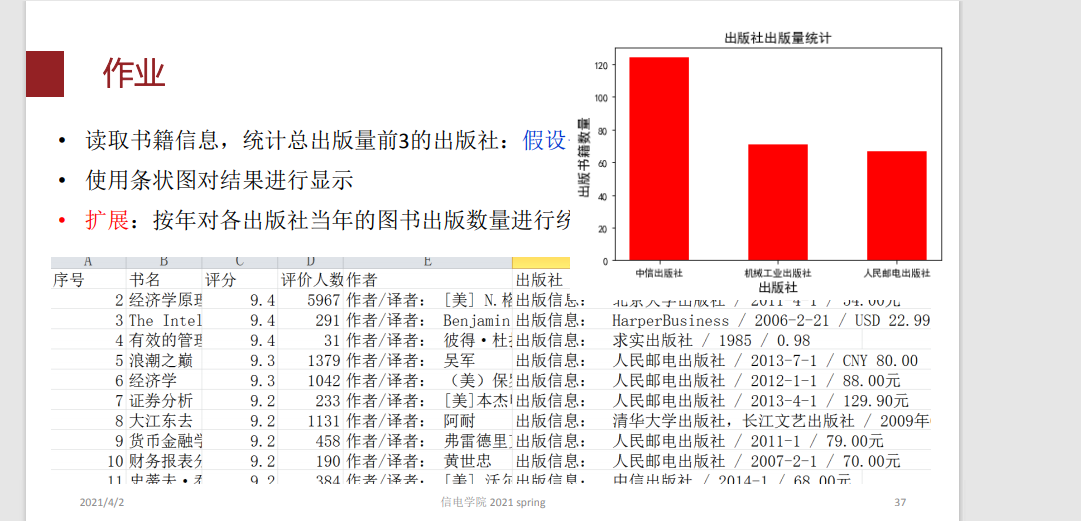
读取书籍信息,统计总出版量前3的出版社:假设书名没有重复
• 使用条状图对结果进行显示
• 扩展:按年对各出版社当年的图书出版数量进行统计 2014-2019
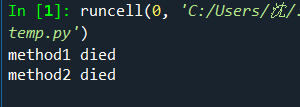
读入中文文件时经常有不理解的编码问题,你可以用下面这个函数判断自己可以用哪种方法来读入。
上面那个是分析的链接,复制了别人的代码,讲真我只会下面这代码的方法一、三。
def open_CSV_file(file_name):
import pandas as pd
import csv
try:
f=open(file_name,'r',encoding='utf-8')
data1=pd.read_csv(f,engine='python')
except Exception:
print('method1 died')
try:
csv_reader = csv.reader(open(file_name, encoding='utf-8'))
data2=pd.DataFrame(csv_reader)
except Exception:
print('method2 died')
try:
data3=pd.read_csv(file_name,encoding='gbk',header=None)
except Exception:
print('method3 died')
try:
csv_reader = csv.reader(open(file_name, encoding='gbk'))
data4=pd.DataFrame(csv_reader)
except Exception:
print('method4 died')
try:
data5=pd.read_csv(file_name,header=0,encoding='gbk',error_bad_lines=False)
except Exception:
print('method5 died')
try:
f=open(file_name,'r',encoding='ISO-8859-1')
data6=pd.read_csv(f,engine='python')
except Exception:
print('method6 died')
try:
f=open(file_name,'r',encoding='gb18030')
data7=pd.read_csv(f,engine='python')
except Exception:
print('method7 died')
open_CSV_file(r"C:\Users\沈\Desktop\book_list.csv")
自己调试了的结果。然后就可以用第三种方法读入。
根据美赛习惯,我总喜欢先输出下面这行代码
ps:不要问我为什么地址这么长,因为我懒得换目录,各个文件也是分散的,干脆复制路径了
data=pd.read_csv(r"C:\Users\沈\Desktop\book_list.csv",encoding='gbk')
print(data.describe())
毕竟数据不能这么简单分析,我还没做数据规范化,也看不出什么。
下面正文:
ps:下面这个是我同学写的,和他同时写,没他写得快,干脆用他的代码了。
import re
import pandas as pd
import matplotlib.pyplot as plt
def main():
data=read(r'book_list.csv')
draw(data,3)
def read(file):
data = pd.read_csv(file,encoding='gbk')
rows = data.shape[0]
publisher = []
for i in range(rows):
name = re.findall(r"出版信息:(.*?)/.*?", data['出版社'][i])
name = name[0].strip()
publisher.append(name)
dic_count = {}
for item in publisher:
dic_count[item] = dic_count.get(item, 0) + 1
result = sorted(dic_count.items(), key=lambda item: item[1], reverse=True)
return result
def draw(data,num):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
publisher_name = [data[i][0] for i in range(min(len(data),num))]
publisher_name = tuple(publisher_name)
publish_num = [data[i][1] for i in range(min(len(data),num))]
print(publisher_name)
print(publish_num)
plt.bar(publisher_name,publish_num,color='r')
plt.title('出版社出版量统计',fontsize=20)
plt.xlabel('出版社',fontsize=16)
plt.ylabel('出版书籍数量',fontsize=16)
plt.show()
if __name__ == "__main__":
main()
str.strip() : 去除字符串两边的空格(’\n’,’\t’,’ ‘,’\r’)
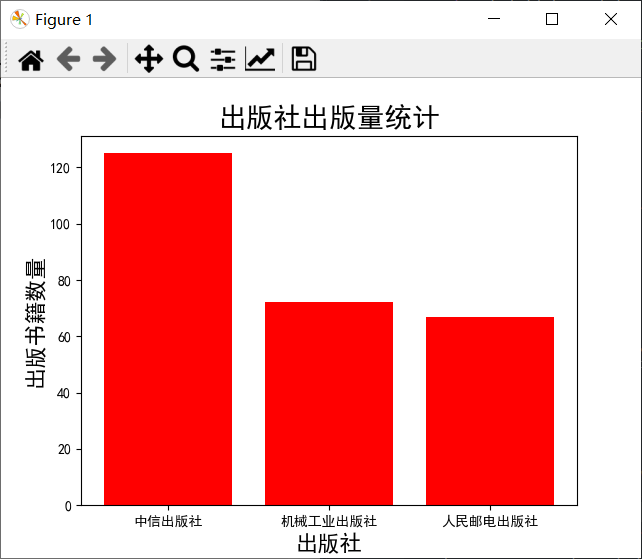
幸好这题只是取前三的,图可以出来。
但这代码里还是有问题的,我发现有一组样例的’出版社’是 出版信息: Marc P. Cosentino / Burgee Press / 2005-09-05。我们正则表达式是以 ‘/’ 为界限,而这个样例没有价格,前面第一个是作者,第二个才是出版社。
再如 出版信息: 邱凯生 / 2008-4 / 45.00元或 出版信息: Little, Brown and Company / 2008-11-18 / CAD 30.99这种不含’出版社’或’Press’的。
正则表达式需要修改。
什么你要问我价格怎么办?其实很多样例中价格的形式还是 USD +数字(美元)或其它面值(还有空值,没有单位的),得转换相同单位,而且这题没问价格相关的题,完全可以无视。
举几个特例(啊,像极了美赛时处理各种数据的时候)
出版信息: 北京联合出版公司·后浪出版公司 / 2015-6 / 36.00元
出版信息: Ecco / 2015-5-19 / USD 28.99
出版信息: Little, Brown and Company / 2008-11-18 / CAD 30.99
出版信息: Marc P. Cosentino / Burgee Press / 2005-09-05
出版信息: 100PAGES PRESS / 2004 / 120
出版信息: 滚石文化股份有限公司 / 1997.12 / 新台币 1800
出版信息: 机械工业出版社 / 2011年 / 48.00元
出版信息: 邱凯生 / 2008-4 / 45.00元
之后我假设:
字符中只有”press”(不区分大小写)或”出版社”的才算严格意义上的出版社,其他个人名义或公司名义的不算。
复习一下:
re函数:compile、match、search、findall的区别
要注意以下几点:
1、数量词的贪婪模式与非贪婪模式
2、反斜杠的运用
3、匹配模式
于是正则表达式改成下面这两种,分别匹配中文和英文的情况。
`python
a=’出版信息: 滚石文化股份有限公司 / 1997.12 / 新台币 1800′
b=’出版信息: 机械工业出版社 / 2011年 / 48.00元’
x=’出版信息: Marc P. Cosentino / Burgee Press / 2005-09-05′
y=’出版信息: 100PAGES PRESS / 2004 / 120′
regex1=re.compile(r'(\w+\s+press)’,re.I)
regex2=re.compile(r'([\u4e00-\u9fff]+出版社)’)
print(regex1.findall(x))
print(regex2.findall(b))
Original: https://blog.csdn.net/weixin_45606191/article/details/115433047
Author: 蒲公英之殇
Title: Python日常练习二
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/755969/
转载文章受原作者版权保护。转载请注明原作者出处!