

需求
之前写过一个blog,是通过基本的bs4完成爬取的:
传送门
这样写动态爬虫的缺点包括:
1.速度慢
2.需要额外的解析
3.要额外判断blink信息,没有容错机制
因此,我们考虑使用scrapy框架,源码在我的github仓库
scrapy爬取博客源码
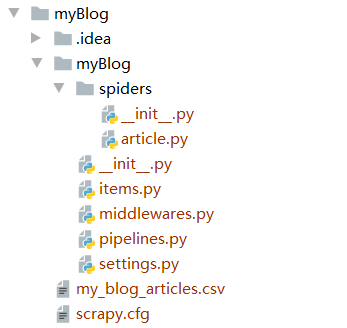
scrapy框架
scrapy框架是一个全家桶爬虫
item定义需要爬取的对象和属性
pipeline定义过滤规则
settings定义配置信息
article是爬虫程序,定义如何迭代访问不同的url
核心就是article的编写!!

; 关于scrapy的创建
1.首先是下载scrapy库
2.创建一个scrapy项目
scrapy startproject 项目名
3.创建一个爬虫脚本
scrapy genspider article 主网页名
完成了以上三步之后就可以开始编写scrapy项目了
定义items对象
import scrapy
class Article(scrapy.Item):
title = scrapy.Field()
read = scrapy.Field()
like = scrapy.Field()
review = scrapy.Field()
collect = scrapy.Field()
我们需要爬取的是文章信息,这里我们定义了题目、浏览量、点赞量、评论量和收藏量
最核心的爬虫脚本(这里是article.py)
1.首先,我们需要定义主网站和起始网站
name = 'article'
allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net']
2.整理一下我们的逻辑(看一下文章顶的链接,另一篇动态爬虫的文章有详细解释)
先通过api获取所有的文章url信息,所以我们需要定义一个函数来浏览全部api,把所有文章url存起来
3.获取全部文章的url
def get_all_my_articles(self):
article_urls = []
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'referer': 'https://bridge-killer.blog.csdn.net/'
}
menu_url = "https://blog.csdn.net/community/home-api/v1/get-business-list?page={}&size=20&businessType=lately&noMore=false&username=weixin_40986490"
for page in range(1, 44):
r = requests.get(menu_url.format(page), headers = header)
for article in r.json()['data']['list']:
article_urls.append(article['url'])
return article_urls
4.文章页的解析(这里可以结合scrapy shell 验证reponse.css的结果,也可以通过”检查”中的元素复制css选择器结果)
这一步是关键的一步,需要分析目标网页
def parse_article(self, response):
article = Article()
article['title'] = response.css('#articleContentId::text').get()
article['read'] = response.css('.read-count::text').get()
article['like'] = response.css('#spanCount::text').get().strip()
article['review'] = response.css('li.tool-item:nth-child(3) > a:nth-child(1) > span:nth-child(2)::text').get().strip()
article['collect'] = response.css('#get-collection::text').get().strip()
yield article
5.迭代遍历全部的博客url,使用parse(override)
def parse(self, response):
article_urls = self.get_all_my_articles()
for article_url in article_urls:
yield response.follow(article_url, self.parse_article)
过滤
好了,我们获取完全部的信息后,可以过滤一下:
假如我们只要记录200阅读量以上的文章,就可以使用DropItems来完成
这里是pipelines.py
from scrapy.exceptions import DropItem
class MyblogPipeline:
def process_item(self, item, spider):
if item.get('read'):
item['read'] = int(item['read'])
if item['read'] < 200:
raise DropItem('去掉200阅读量以下的文章')
return item
存储和配置
settings.py
ITEM_PIPELINES = {
'myBlog.pipelines.MyblogPipeline': 300,
}
FEED_FORMAT = 'csv'
FEED_URI = 'my_blog_articles.csv'
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_TARGET_CONCURRENCY = 5
这里的配置提供了存储的格式和文件名,以及并发数
成果

得到一个csv文件
; 总结
scrapy是一个保姆式的爬虫框架
我们只需要定义数据格式,定义url抓取顺序,然后再定义数据过滤模式,和数据存储方式即可
简化了很多逻辑,关键是如何分析页面,通过response.css获取对应的元素
Original: https://blog.csdn.net/weixin_40986490/article/details/123553012
Author: 白速龙王的回眸
Title: 【scrapy实战】获取我的博客信息
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788659/
转载文章受原作者版权保护。转载请注明原作者出处!