

目录
一、简介
Pandas是一个构建在NumPy之上的较新的包,提供了DataFrame的有效实现。
DataFrames本质上是带有行和列标签的多维数组,通常具有异构类型和/或缺失数据。
Pandas有三种基本的数据结构:
- Series
- DataFrame
- Index
二、主要内容:
1、Series数据结构
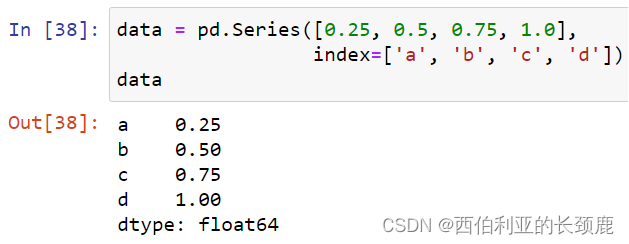
Pandas Series是索引数据的一维数组。
Series可以从列表或数组创建。
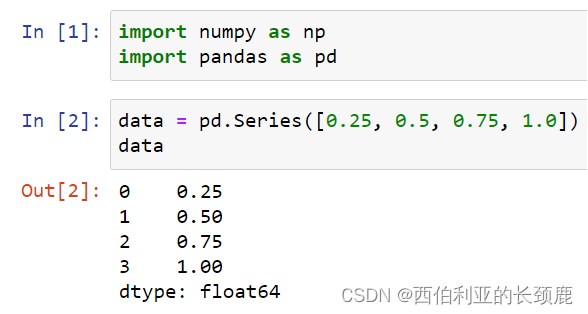

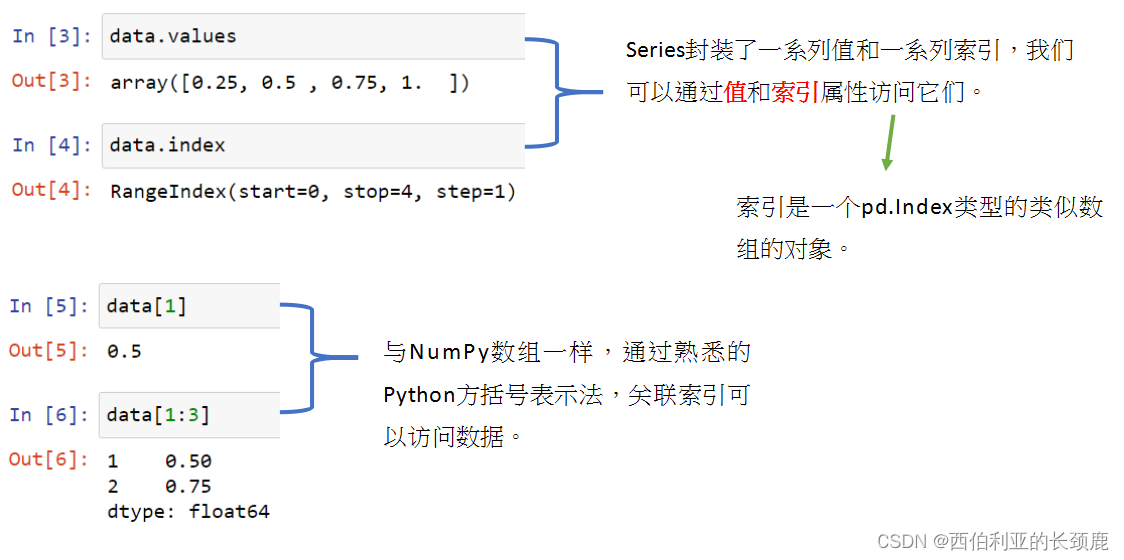
(1)通用NumPy数组定义Series
Pandas Series有一个与这些值关联的显式定义的索引。
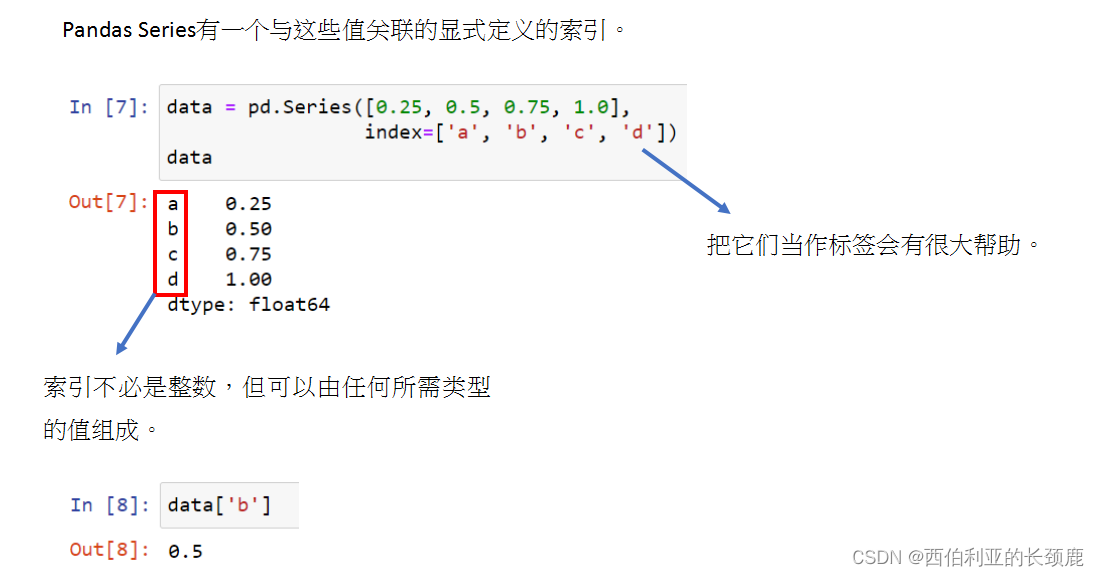
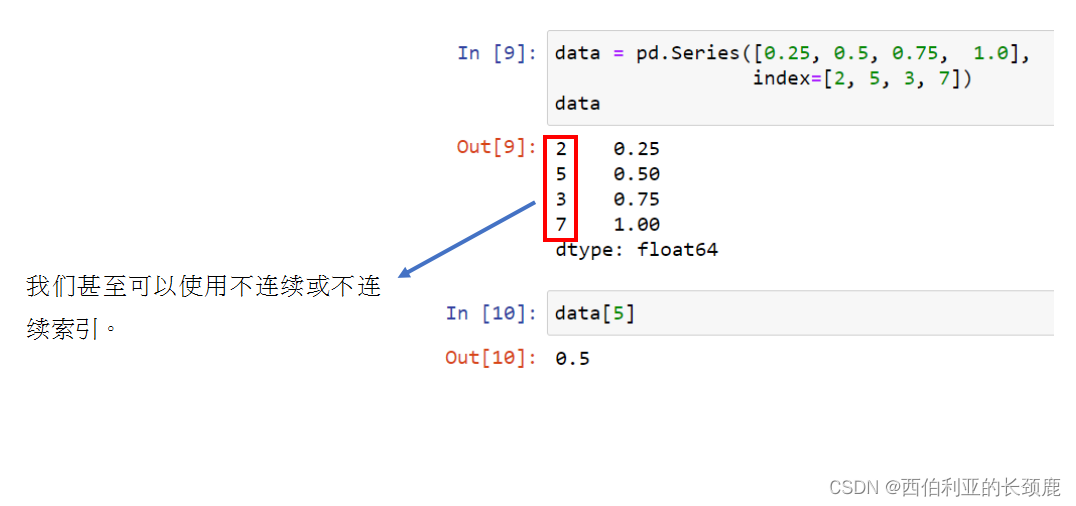
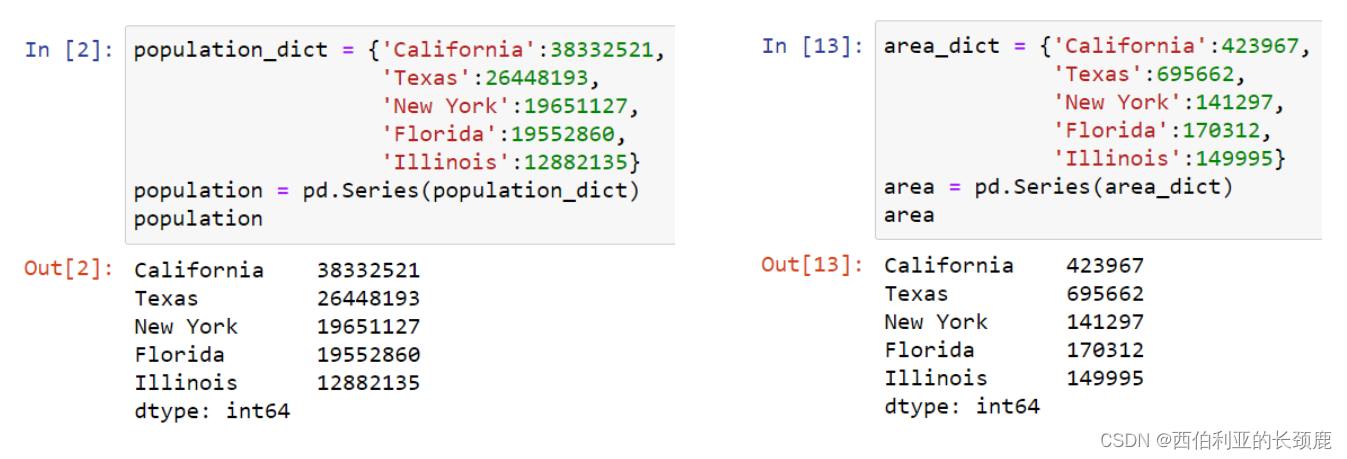
(2)通过Dictionary定义Series

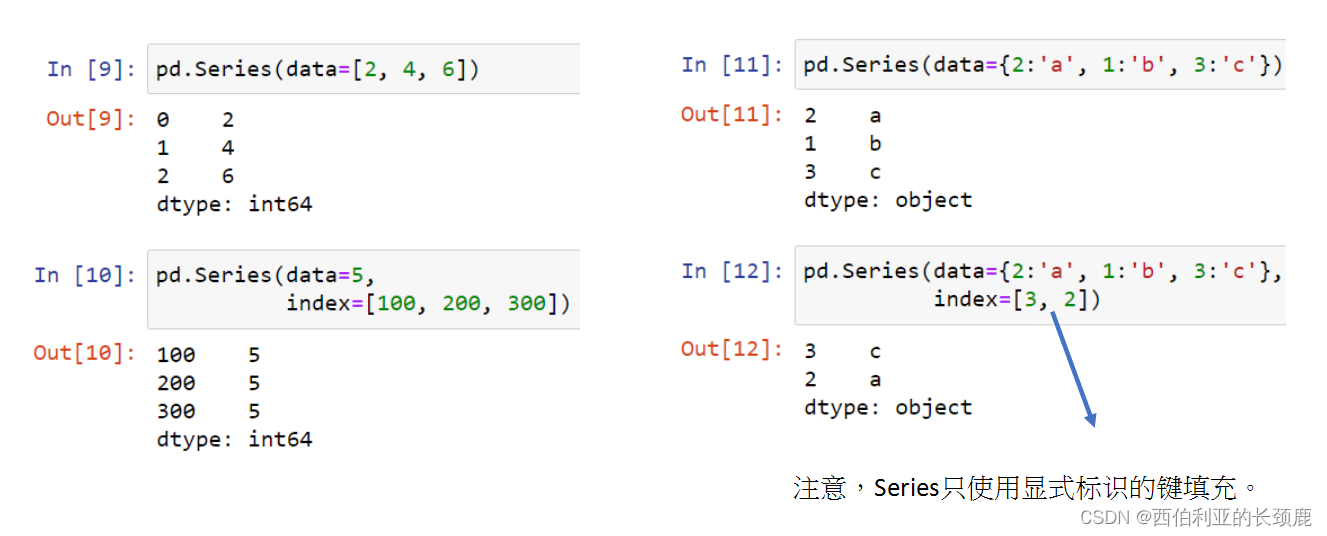
(3)构建系列对象
基本结构pd.Series(data=data, index=index)
2、DataFrame 数据结构
DataFrame既可以看作是NumPy数组的泛化,也可以看作是Python字典的专门化。
- DataFrame作为一个通用的NumPy数组

DataFrame可以看作是二维NumPy数组的泛化,其中的行和列都有一个用于访问数据的泛化索引。
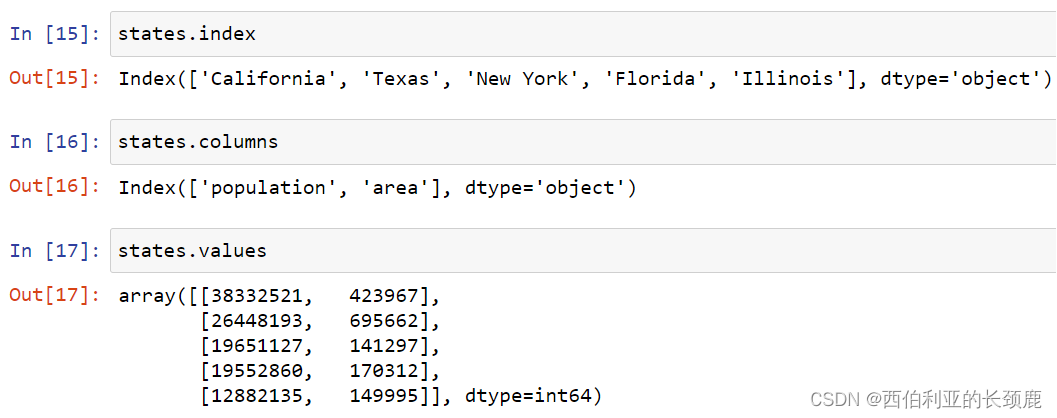
(1)DataFrame可以作为一个特殊的字典
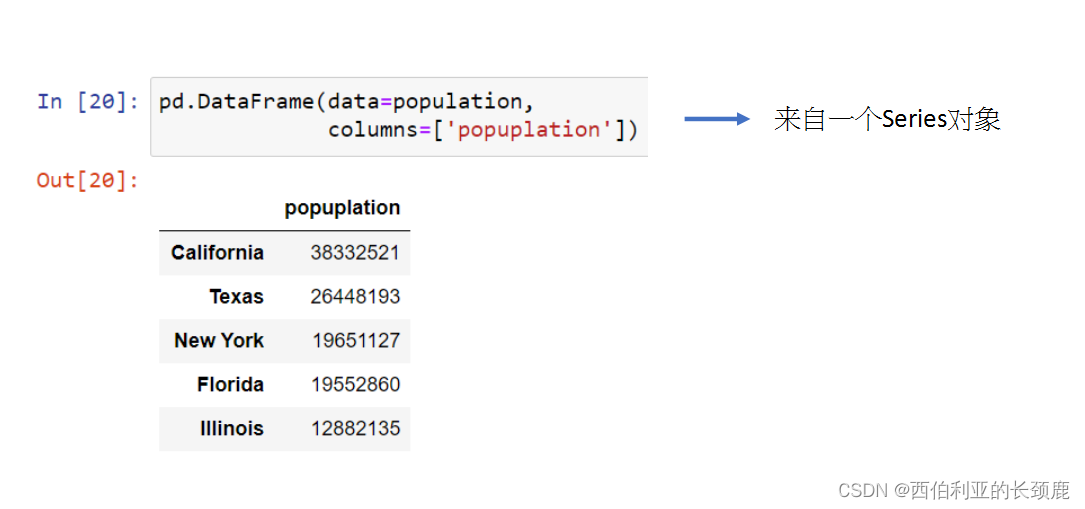
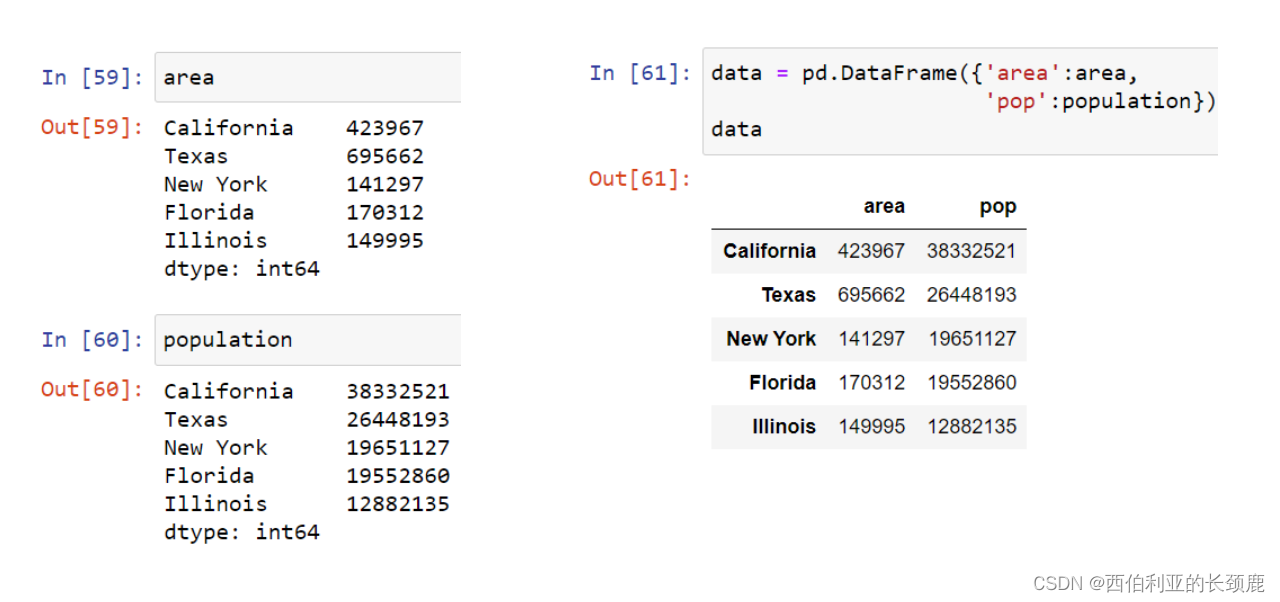
(2)从Series创建DataFrame

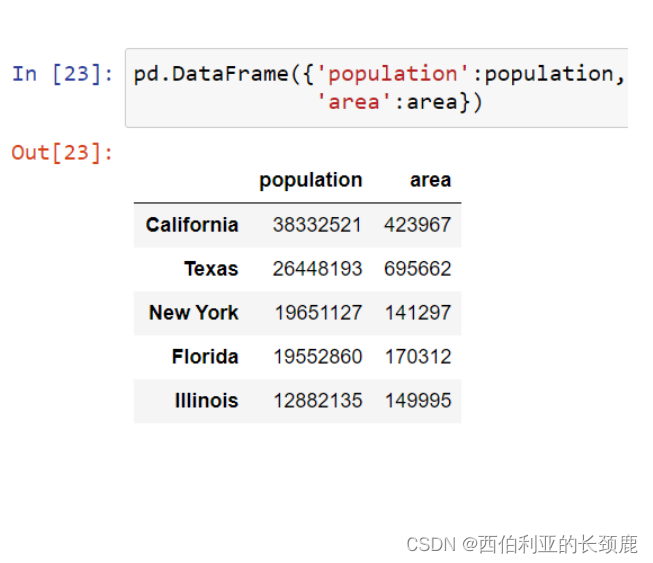
(3)从字典创建DataFrame

(4)Pandas的Index对象
Index对象既可以看作是不可变数组,也可以看作是有序的多集。


(5)数据的索引Index和选择
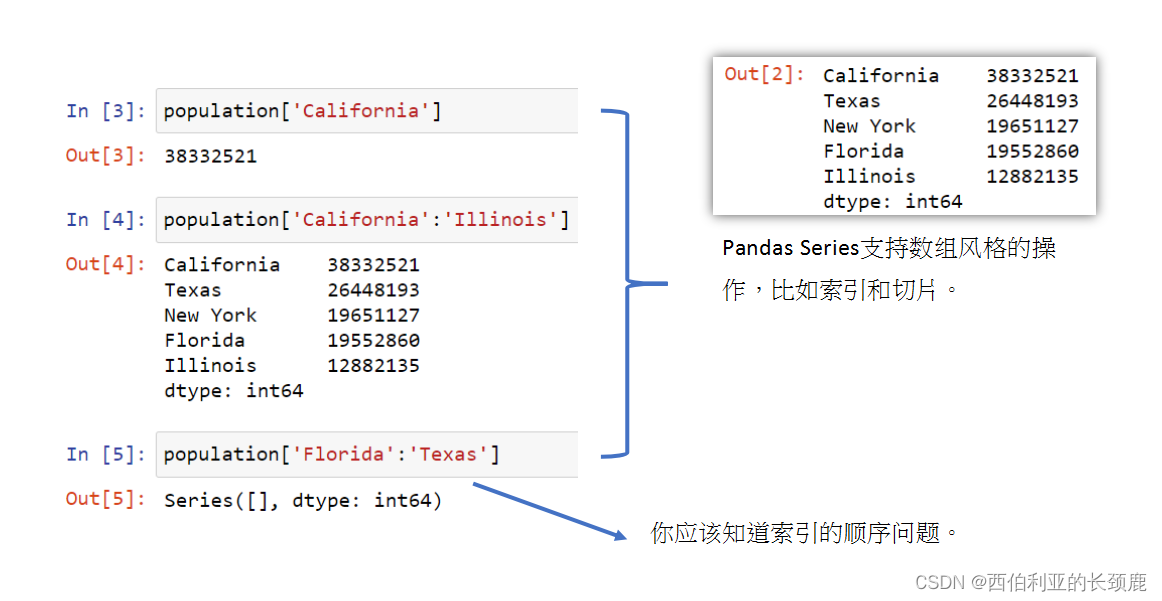
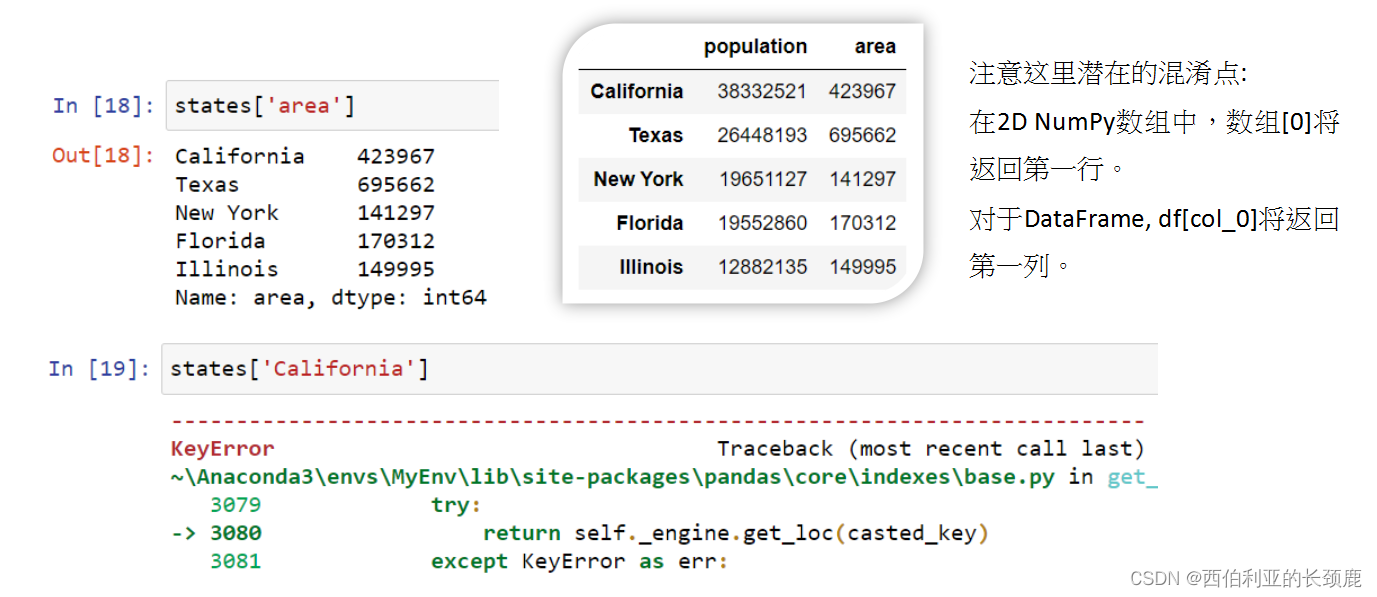
如果您使用过NumPy模式(索引、切片、屏蔽、花式索引和它们的组合),那么在Pandas中对应的模式将会非常熟悉,尽管有一些奇怪的地方需要注意。
请记住,Series对象在许多方面类似于1D NumPy数组,在许多方面类似于标准Python字典。

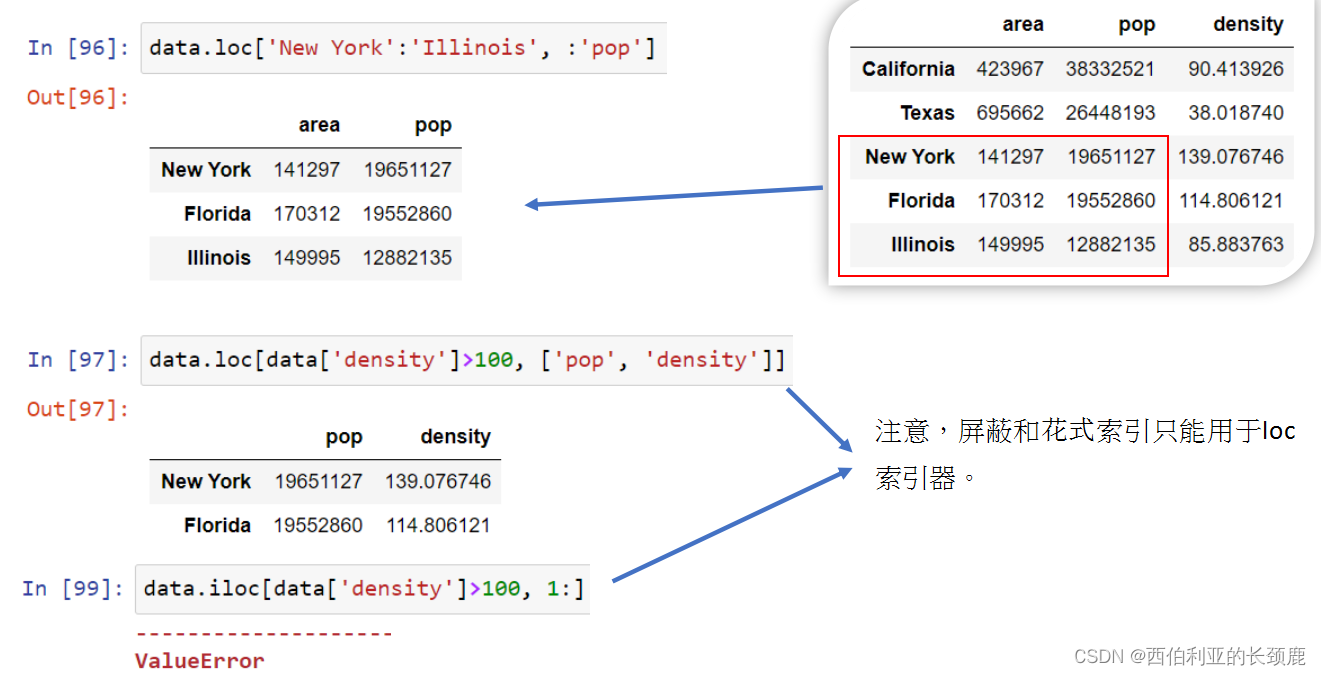
(6)loc 和iloc
上一节中的切片和索引可能会引起混淆,尤其是当Series的显式索引标签是整数时。

为了消除这些混淆,Pandas提供了一些”特殊的索引器属性”,这些属性显式地公开某些索引方案。

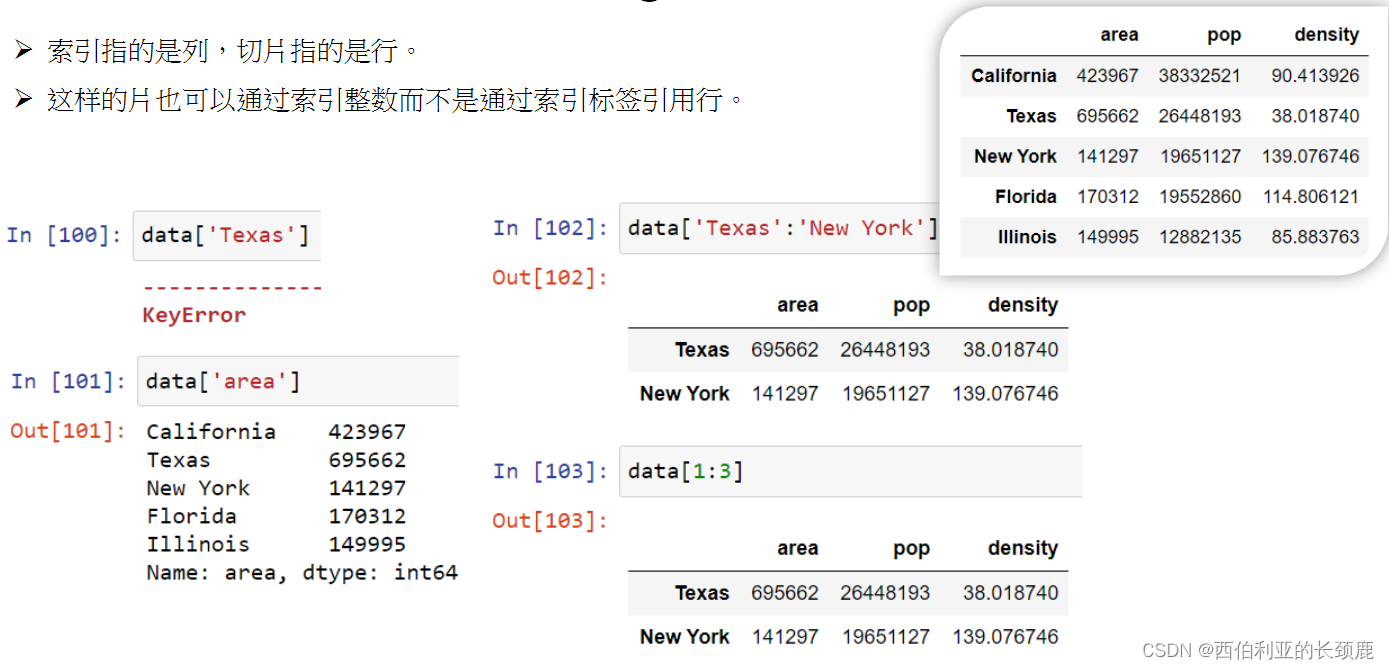
(7)在DataFrame中的Data选择
DataFrame在许多方面类似2D NumPy数组,在其他方面类似于共享相同索引的Series对象的字典。
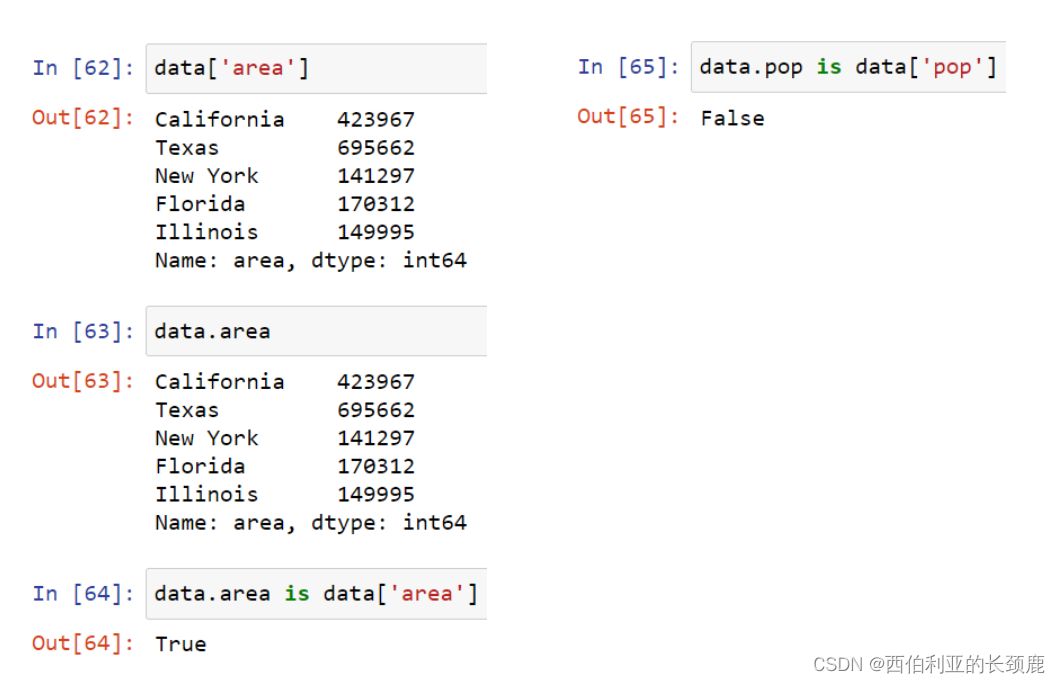
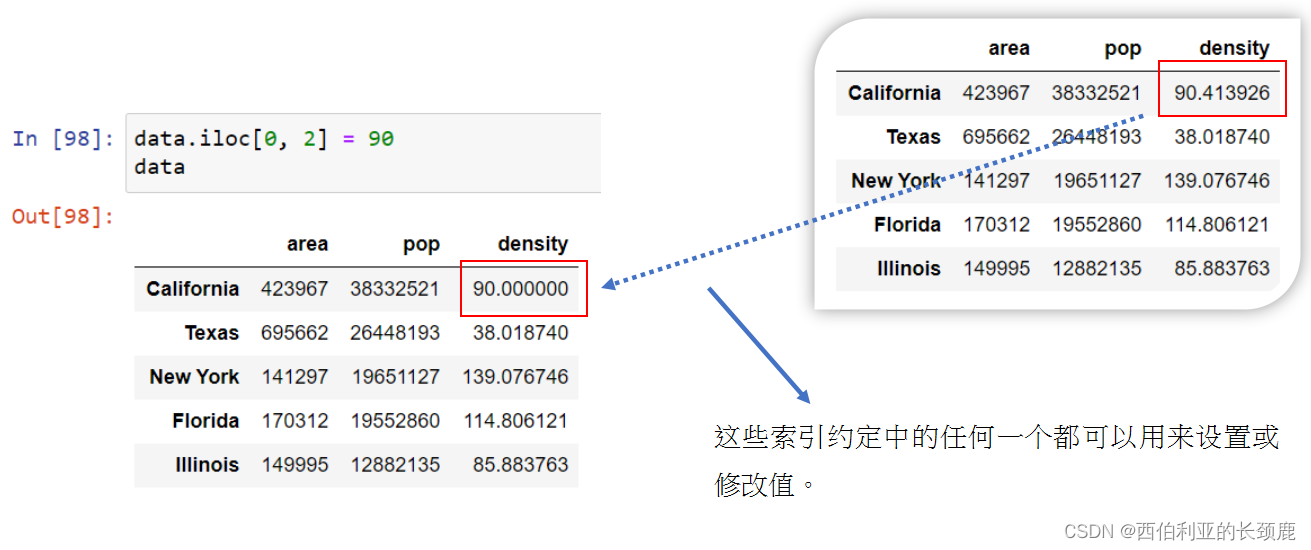
使用字典样式的语法修改DataFrame对象,在本例中添加一个新列。
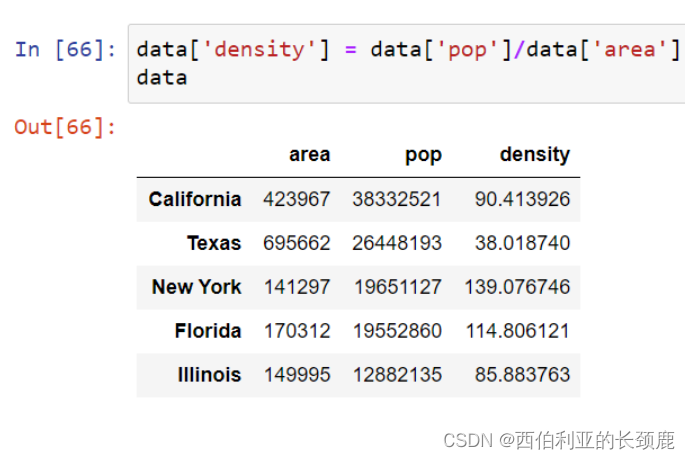
我们可以看到DataFrame是一个增强的二维NumPy数组。
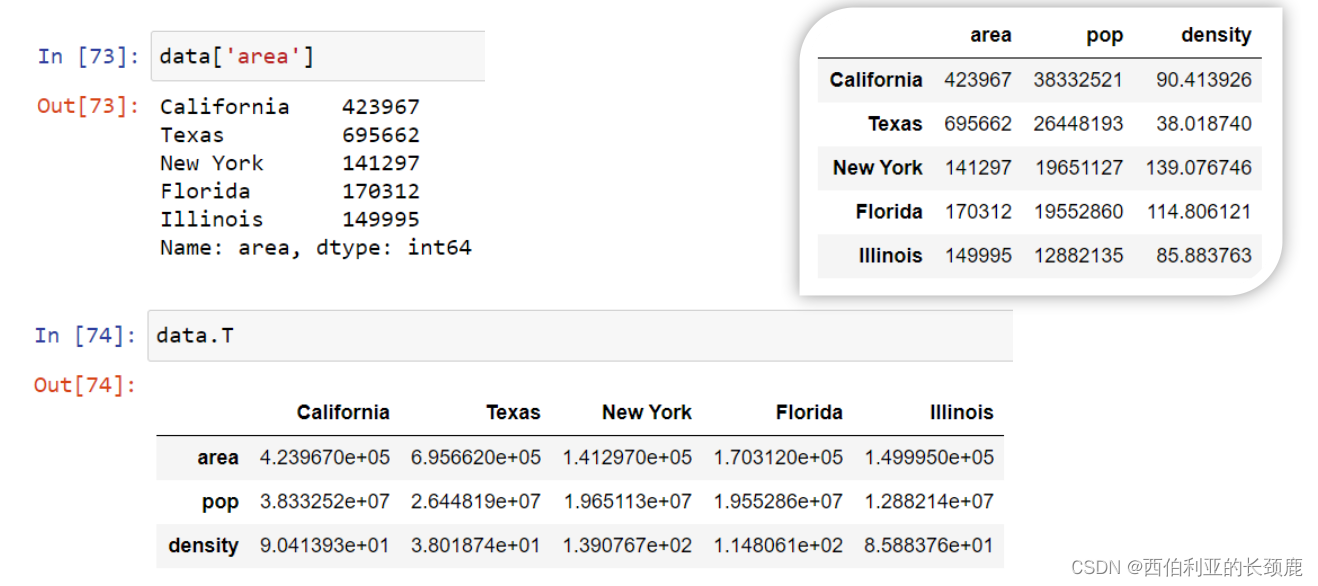
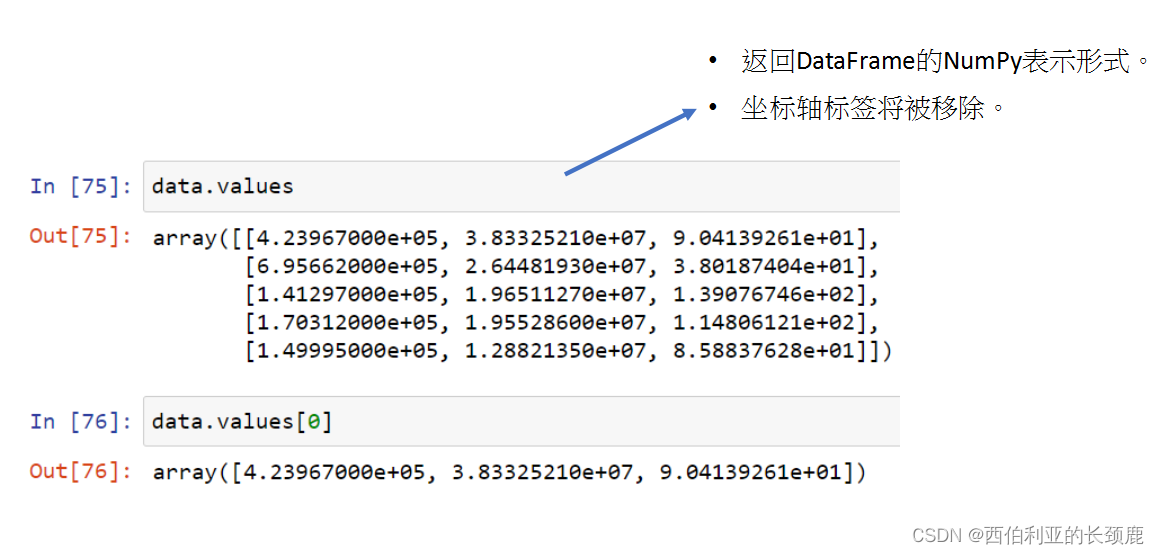
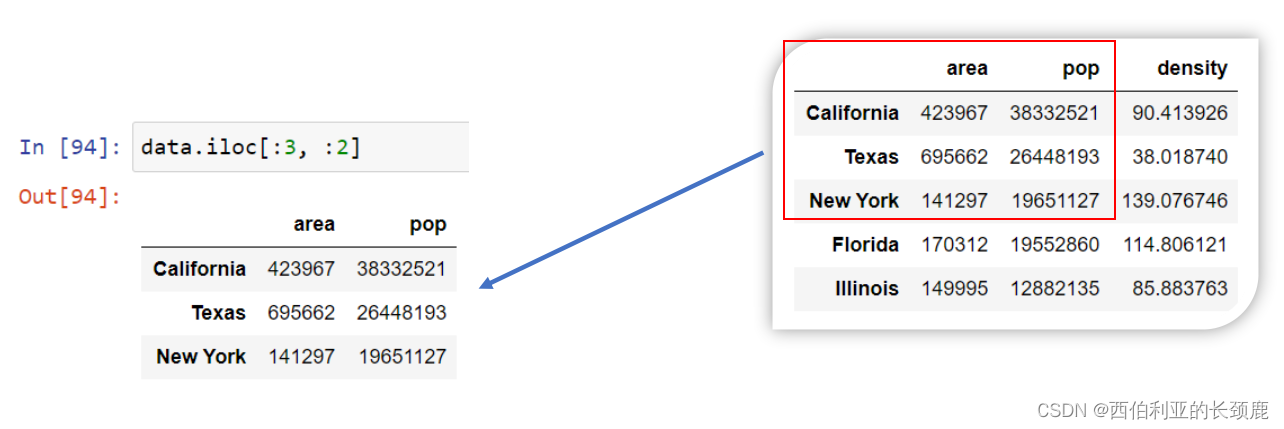
使用iloc索引器,我们可以使用隐式python风格的索引来索引底层数组,就好像它是一个单一的NumPy数组一样,但是DataFrame索引和列标签在结果中保持不变。
(8)Pandas的运算操作
Pandas继承了NumPy的大部分功能。
然而,Pandas包含了一些有用的变化:
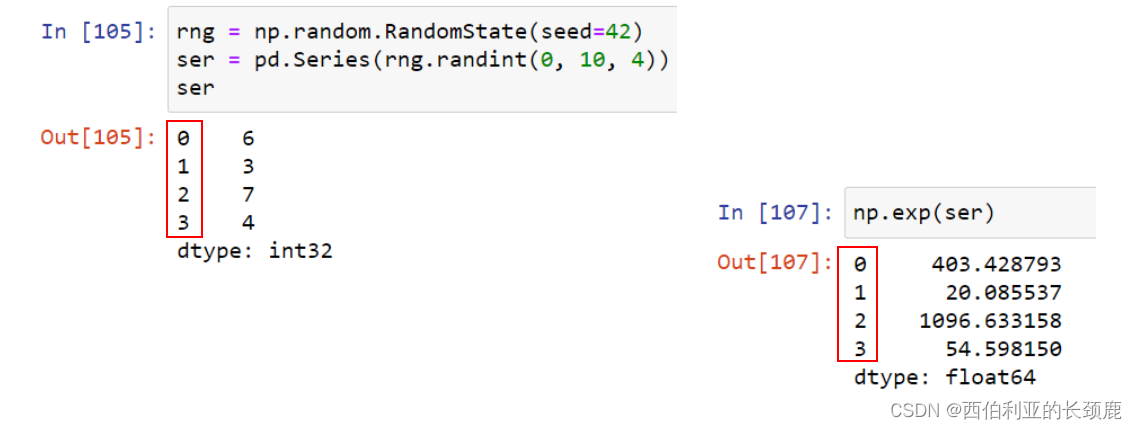
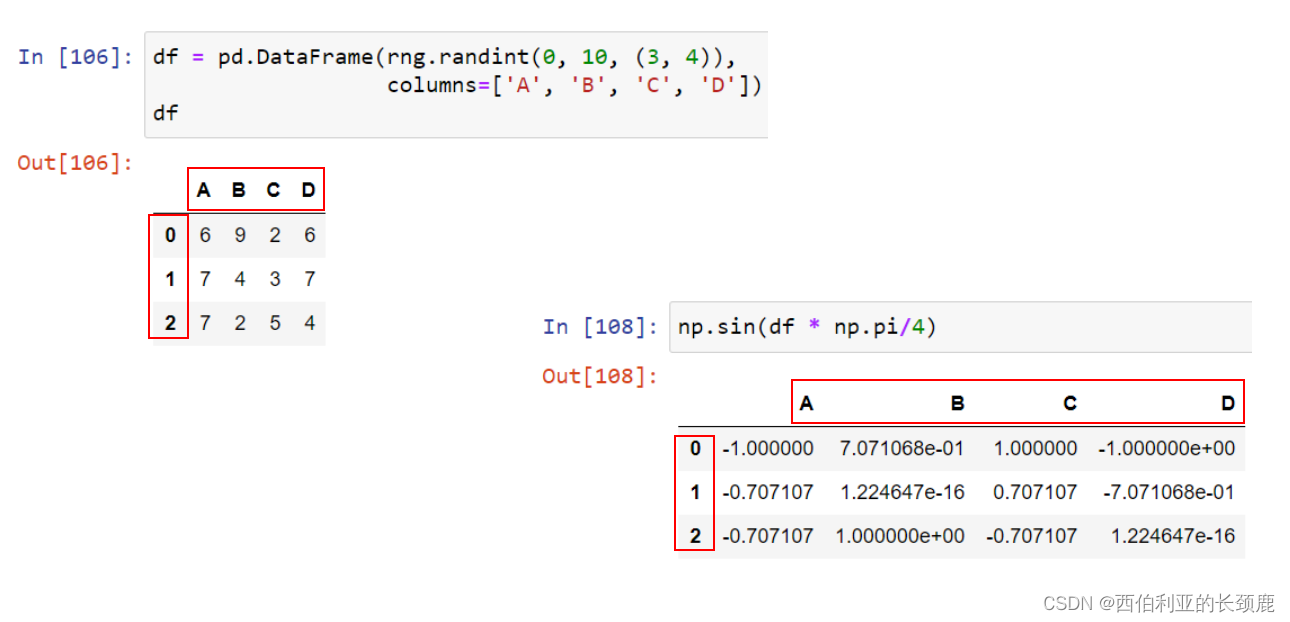
对于一元运算,如反运算和三角函数,这些ufuncs将在输出中保留索引和列标签。
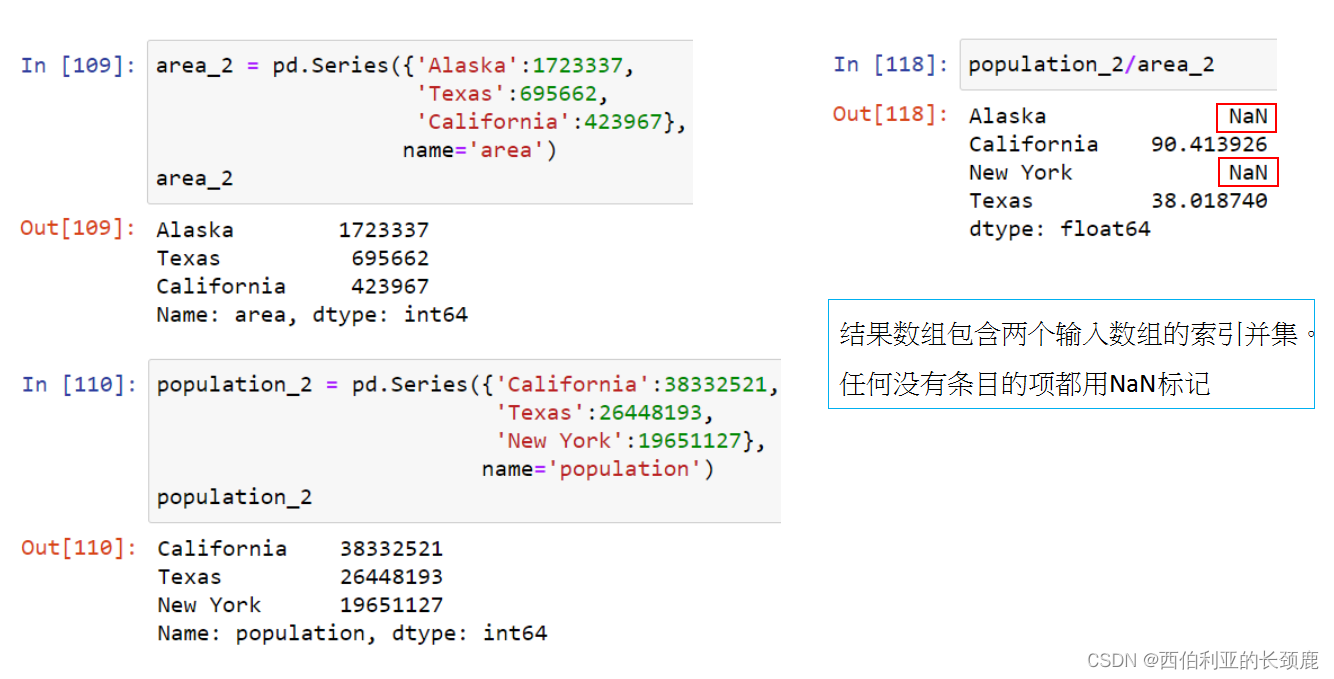
对于加法和乘法等二进制操作,Pandas将在将对象传递给ufunc时自动对齐索引。
如果我们对这些Pandas对象中的任何一个应用NumPy ufunc,结果将是另一个保留索引的Pandas对象。
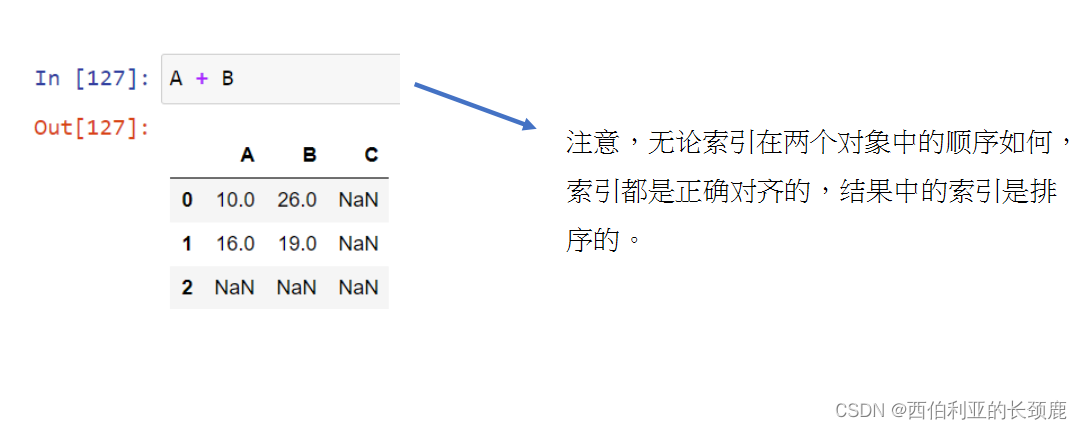
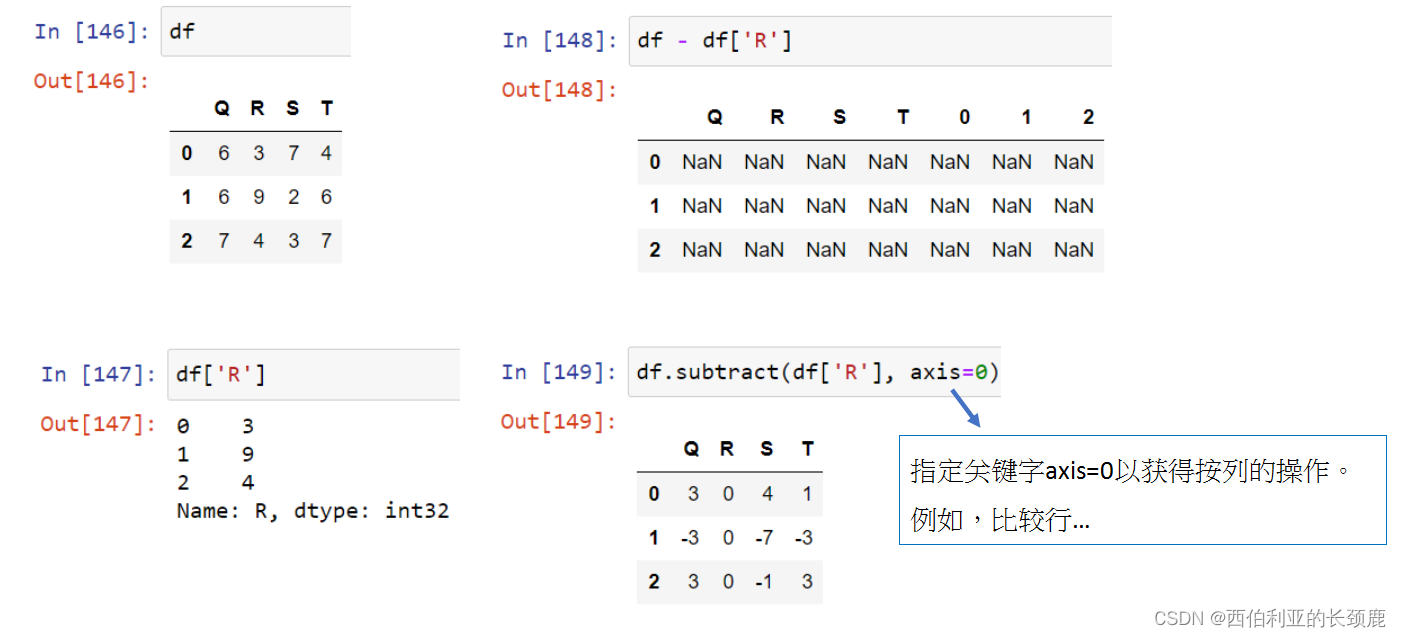
对于两个Series或DataFrame对象的二进制操作,Pandas将在执行操作的过程中对齐索引。
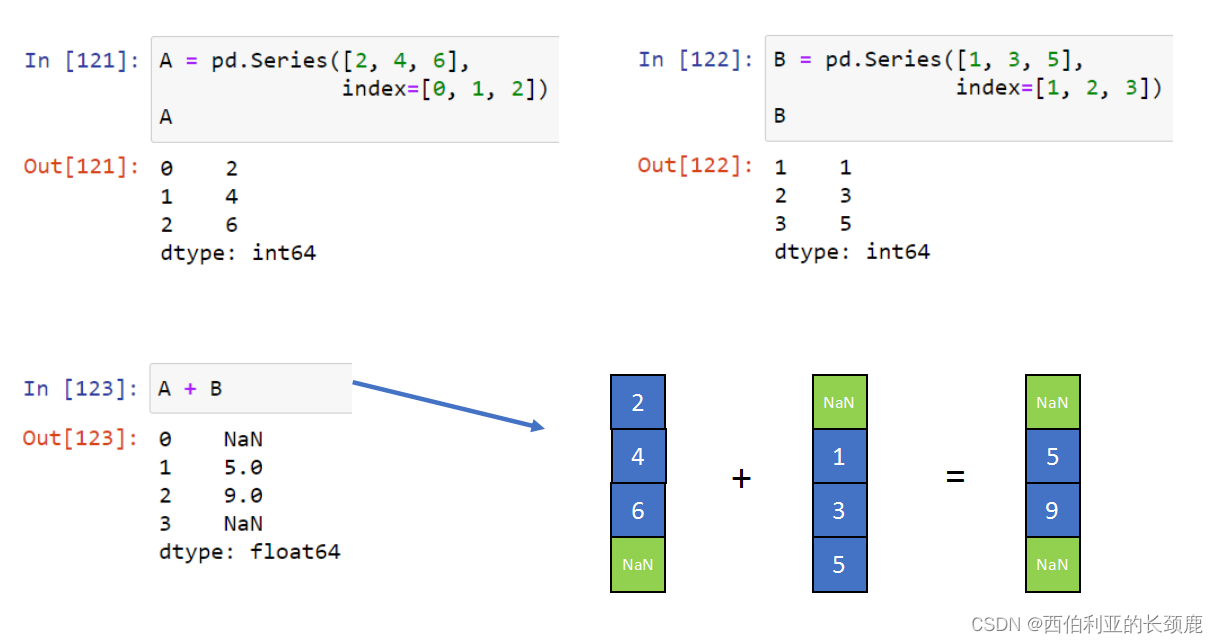
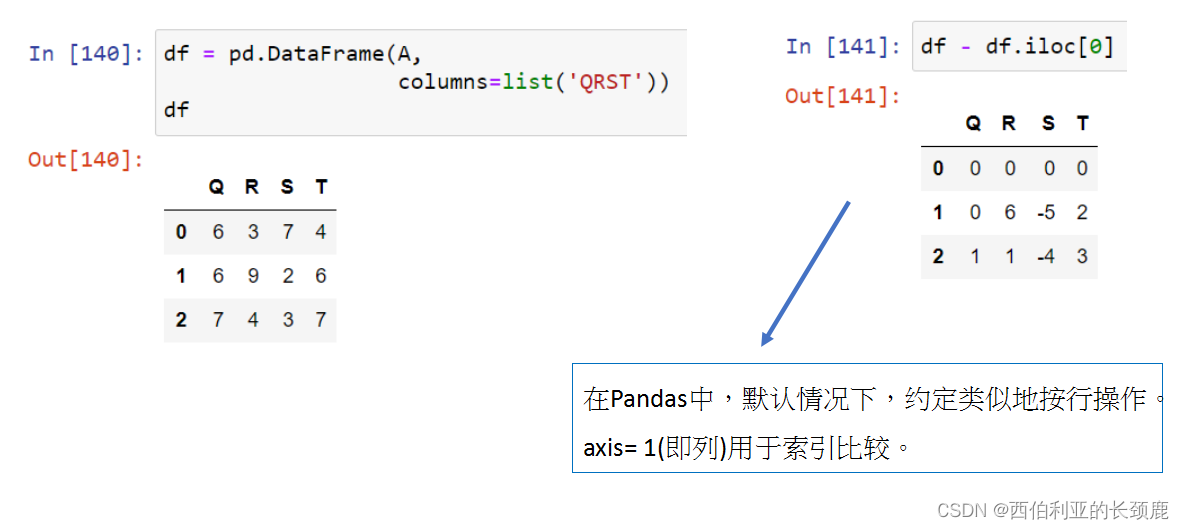
当您在数据帧上执行操作时,列和索引也会发生类似的对齐类型。
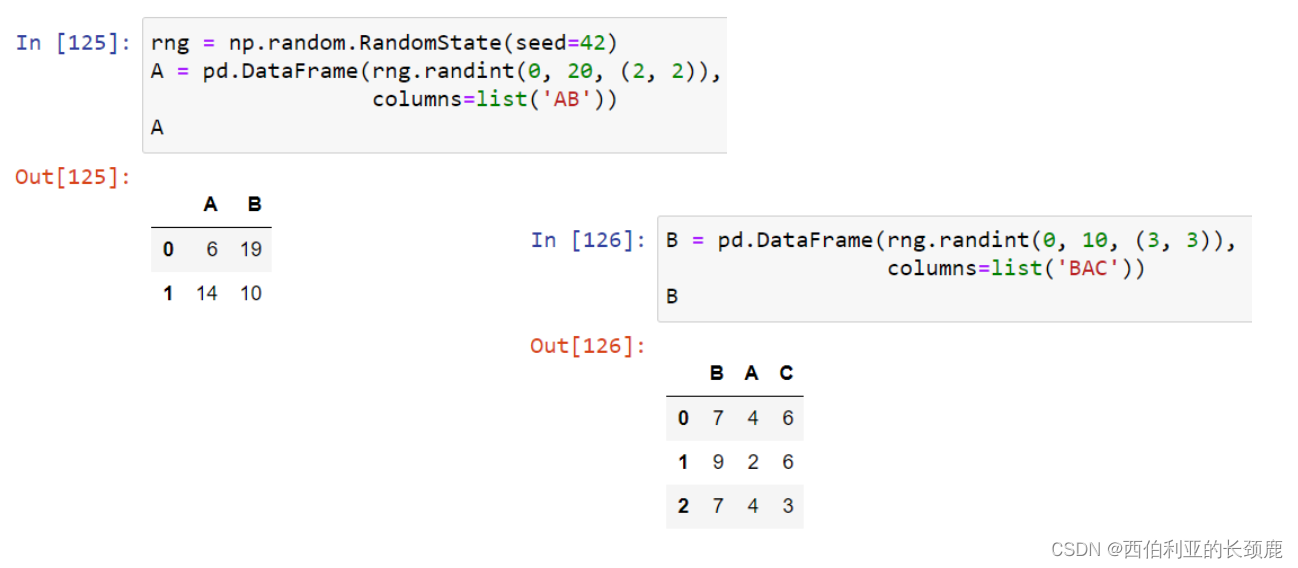
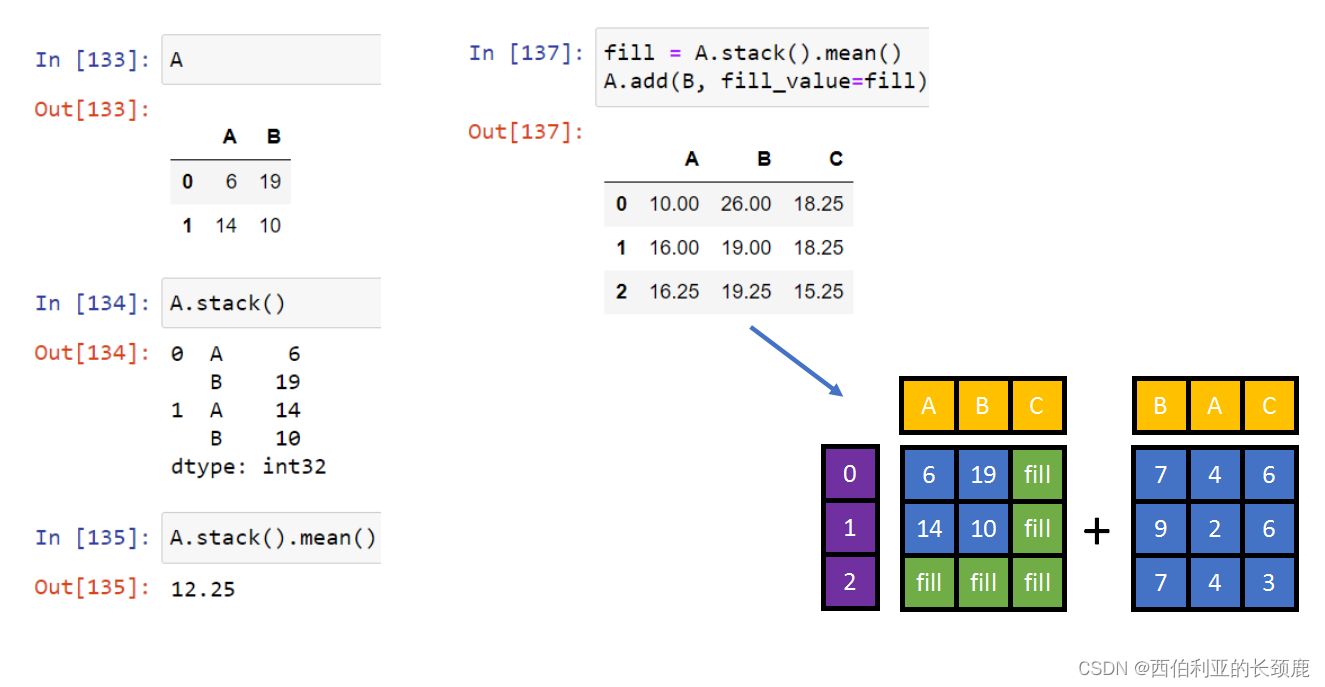

(9)DataFrame和Series之间的操作
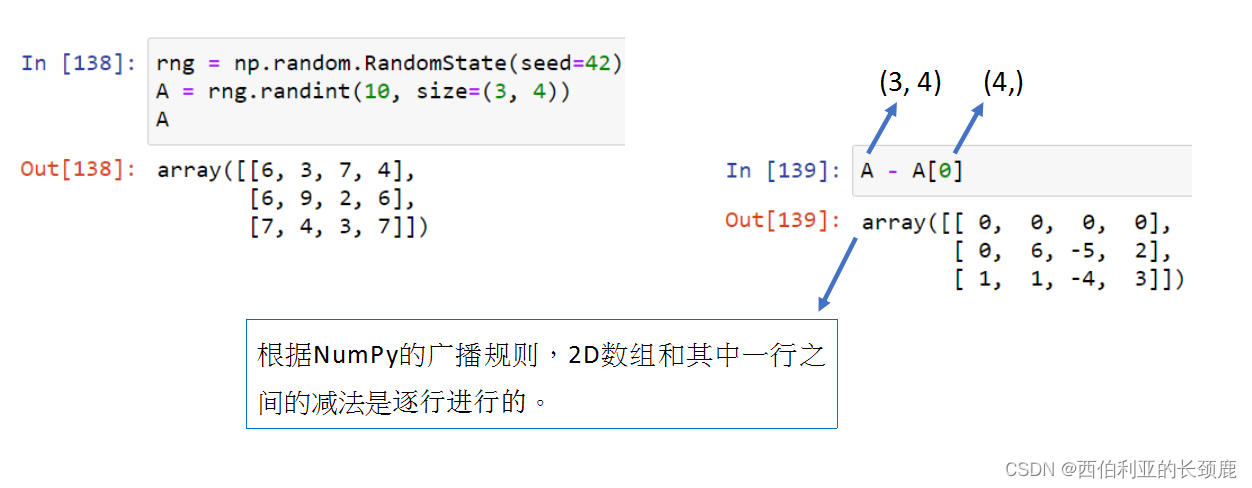
DataFrame和Series之间的操作类似于二维和一维NumPy数组之间的操作。
(10)处理缺失数据
- 处理缺失数据 真实世界的数据很少是整洁,相同的。
- 特别是,许多有趣的数据集可能会丢失一些数据。
- 麻烦的是,不同的数据源可能以不同的方式表示缺失的数据。
- 在本文中,我们通常将缺失的数据称为null、NaN或NA值。
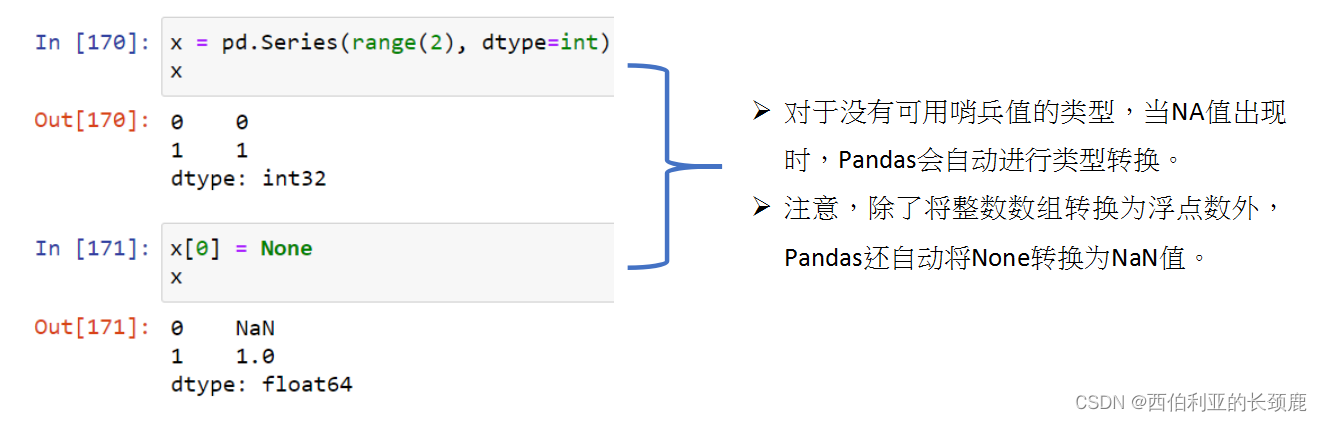
- Pandas选择对丢失的数据使用哨兵值,并进一步选择使用两个已经存在的Python空值:特殊的浮点NaN值和Python None对象。
- Pandas使用的第一个哨兵值是None,这是一个Python单例对象,通常用于Python代码中缺失的数据。
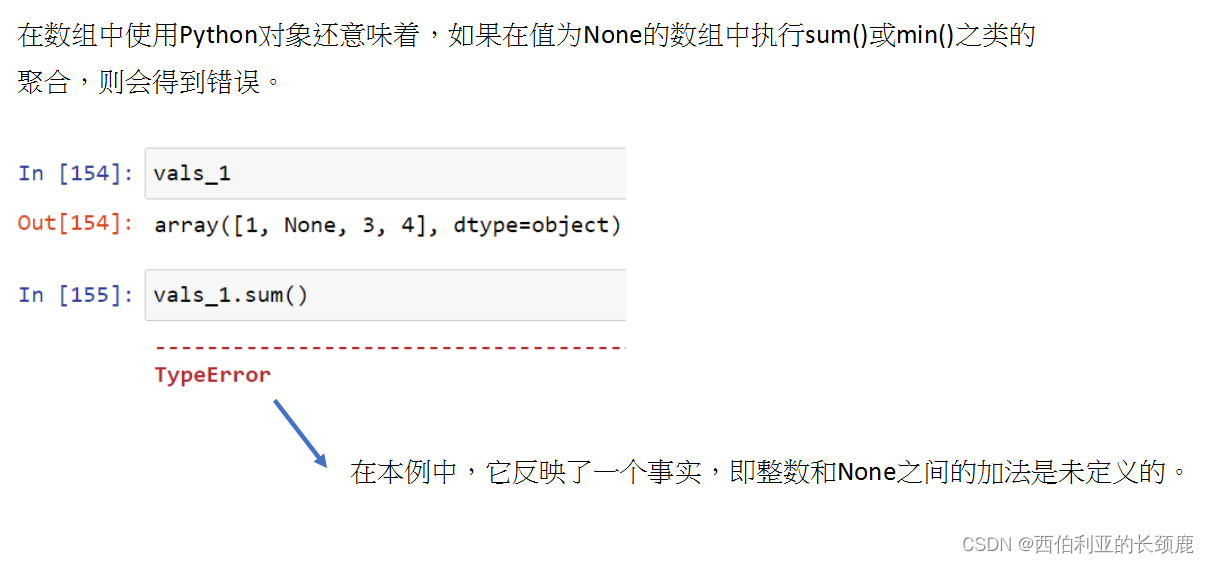
- 因为None是Python对象,所以它不能在任意NumPy/Pandas数组中使用,只能在数据类型为’ object ‘的数组中使用(即Python对象数组)。
- 这意味着NumPy可以推断数组内容的最佳通用类型表示形式是它们是Python对象。

虽然类型对象数组在某些用途上很有用,但对数据的任何操作都将在Python级别上完成,十分耗费时间
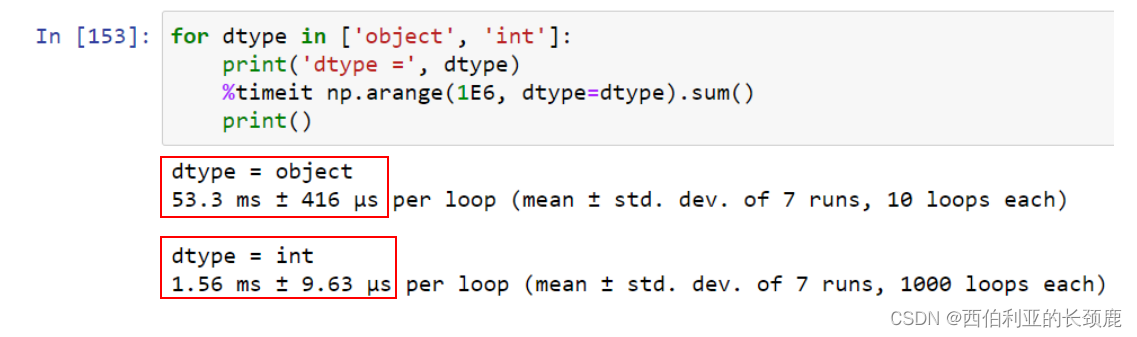

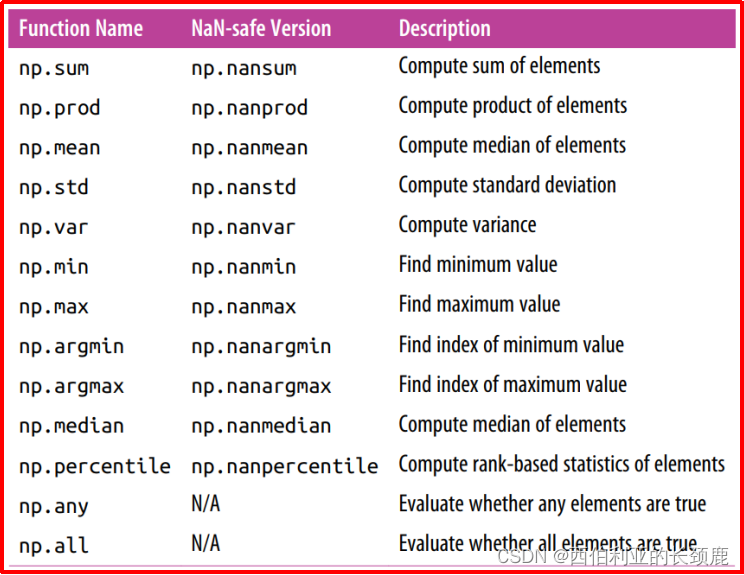
NumPy确实提供了一些特殊的聚合,这些聚合将忽略这些缺失的值。

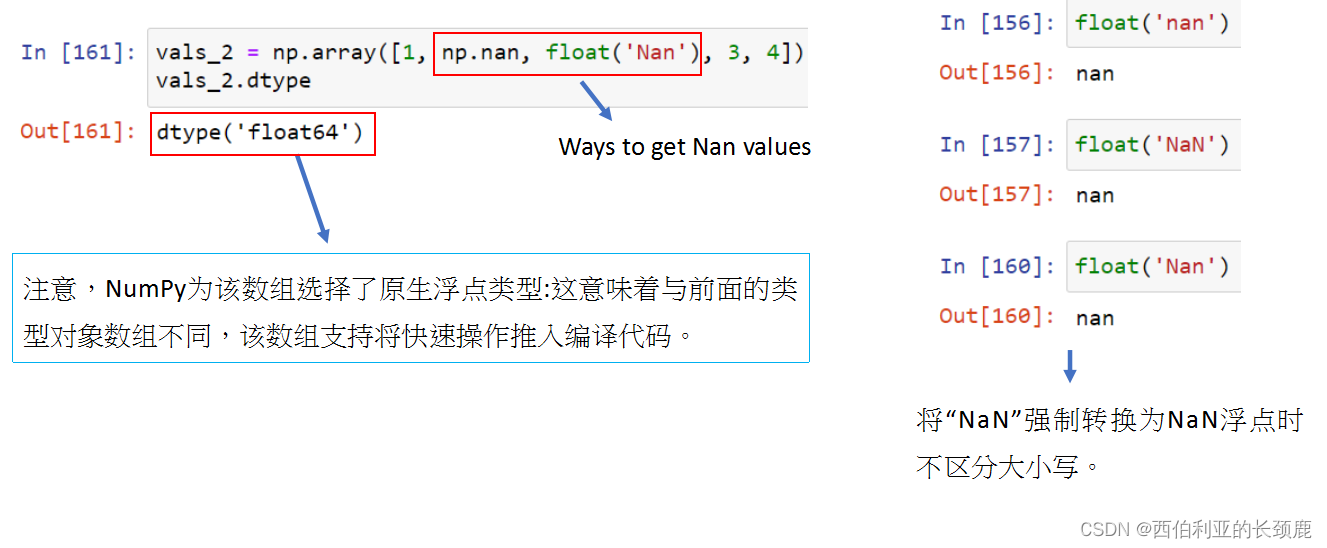
NaN和None都有自己的位置,而Pandas几乎可以交换地处理它们,在适当的地方在它们之间进行转换。
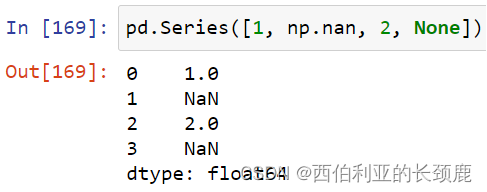

(11)处理空值
- Pandas将None和NaN视为本质上可互换的,以指示缺失值或空值。
- 为了促进这种约定,有几种有用的方法可以检测、删除和替换Pandas数据结构中的空值。
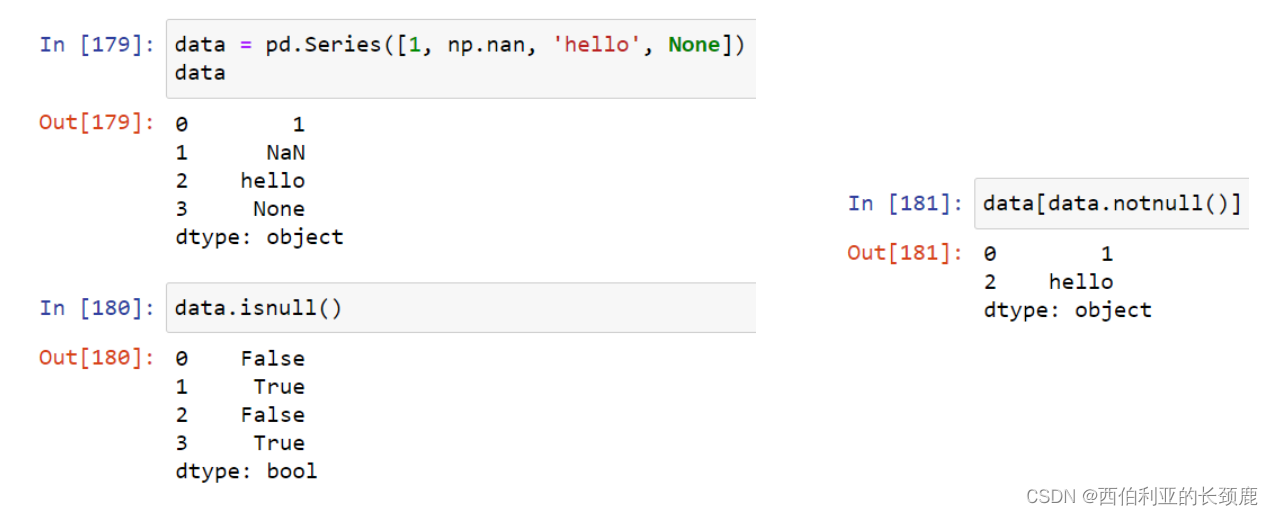
- Isnull()(它是isna()的别名) 生成一个指示缺失值的布尔掩码。
- notnull () 相反isnull ()
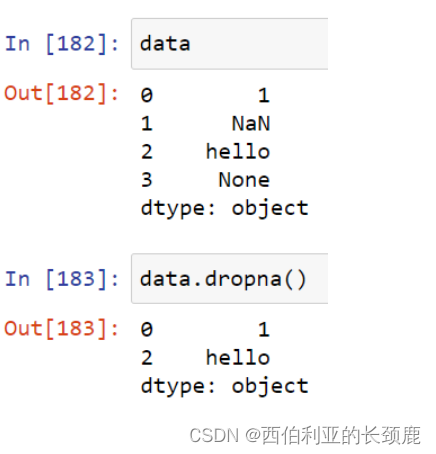
- dropna () 返回经过筛选的数据版本
- fillna () 返回数据的副本,其中填充或计算了缺失的值


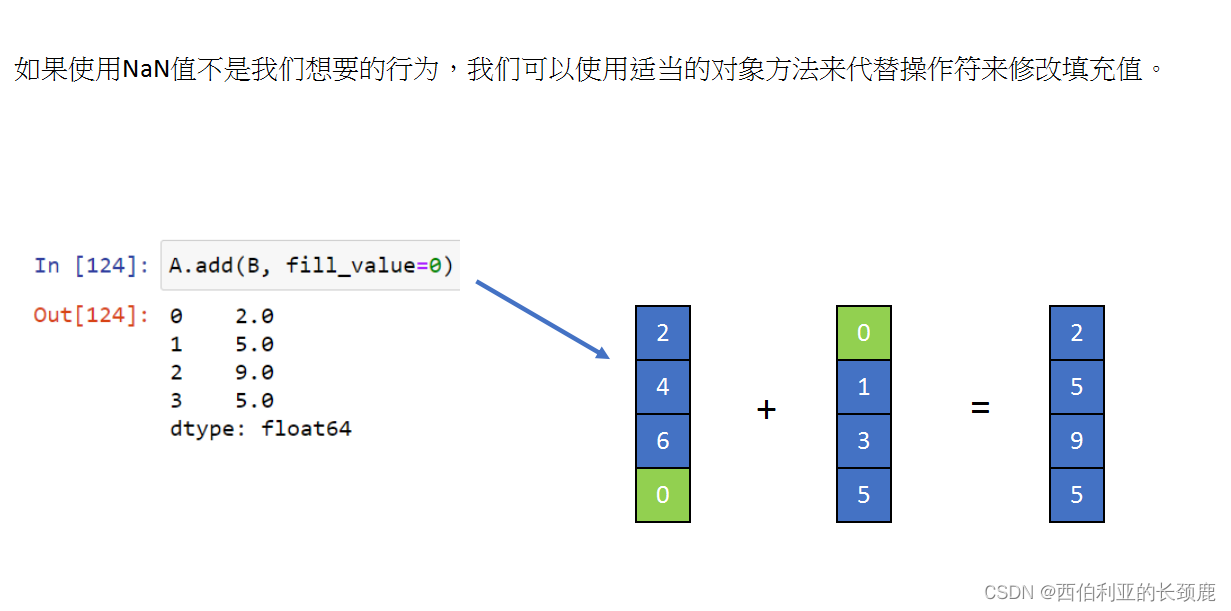
有时,我们不想删除NA值,而是希望用有效值替换它们。 这个值可能是一个单独的数字,比如0,或者它可能是由好的值进行的某种imputation或插值。
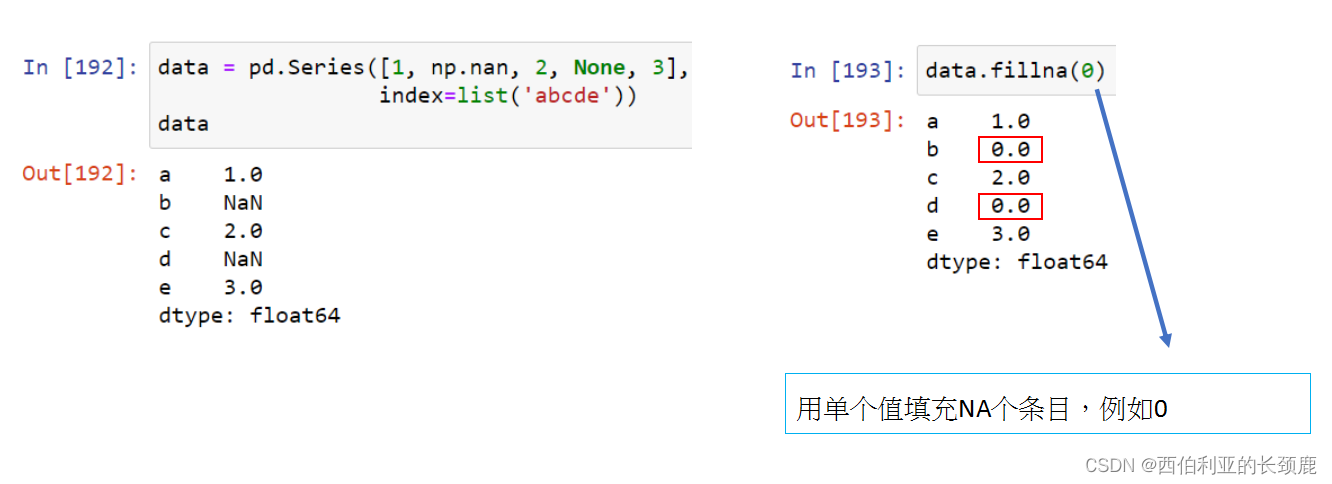
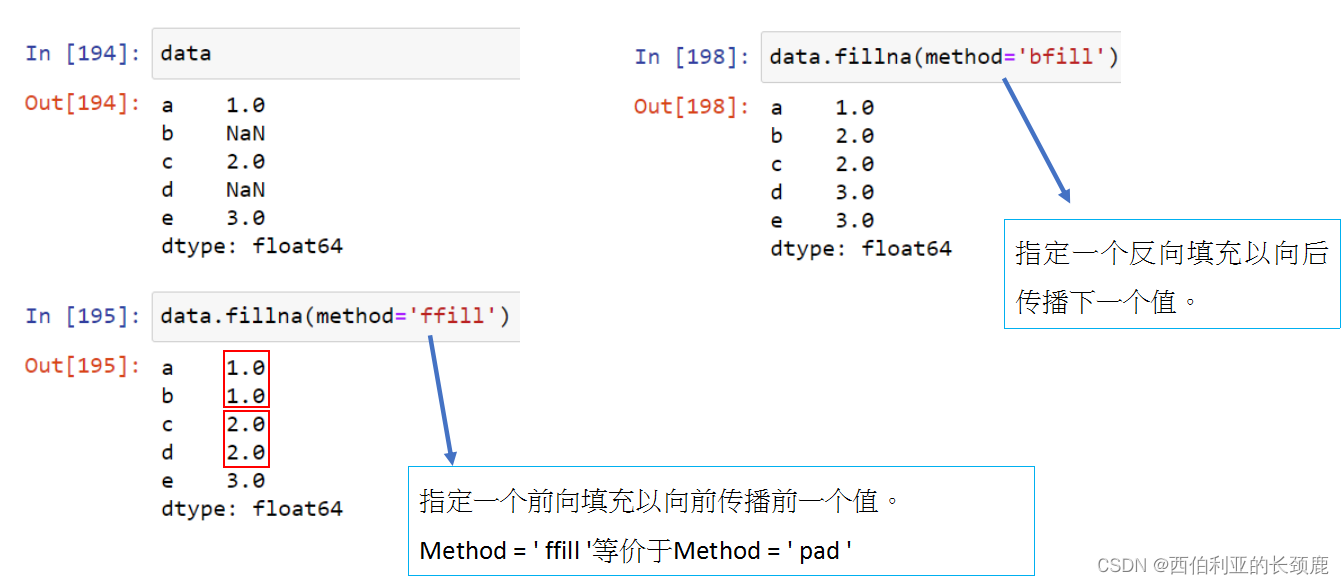
指定一个反向填充以向后传播下一个值。
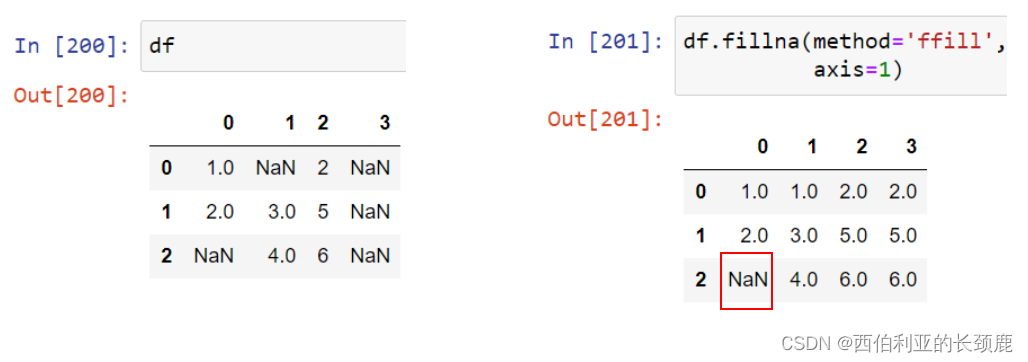
对于数据帧,选项是类似的,但是我们还可以指定填充发生的轴。
注意,如果前一个值在向前填充期间不可用,NA值仍然保留。
Original: https://blog.csdn.net/m0_59160272/article/details/126607778
Author: 西伯利亚的长颈鹿
Title: 数据分析快速入门_Pandas详解(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/754722/
转载文章受原作者版权保护。转载请注明原作者出处!