

利用python库 pandas完成数据分析
导读


- Pandas是一个强大的分析结构化数据的工具集,它的使用基础是Numpy(提供高性能的矩阵运算),用于数据挖掘和数据分析,同时也提供数据清洗功能。
- 本文收集了Python数据分析库Pandas及相关工具的日常使用方法,备查,持续更新中。
缩写说明
- df:任意的 Pandas DateFrame 对象
- s: 任意的Pandas Series对象
- 注: 有些属性方法df和s都可以使用。
; 推荐资源:
- pandas在线教程
- https://www.gairuo.com/p/pandas-tutorial
- 书籍《深入浅出Pandas:利用Python进行数据处理和分析》
一、导入数据
'先导库'
import pandas as pd
import numpy as np
imoport matplotlib.pyplot as plt
%matplotlib inline
pd.read_csv('file.csv',names=['列名1','列名2',.]
pd.read_table(filename,header=0)
pd.read_excel('file.xlsx',sheet_name='表1',header=0)
pd.read_sql(query,connect_object)
pd.read_json(json_string)
pd.read_html(url)
pd.read_clipboard()
pd.DataFrame(dict)
from io import StringIO
pd.read_csv(StringIO(web_data.text))
二、导出数据
df.to_csv('filename.csv')
df.to_excel('filename.xlsx',index=True)
df.to_sql(table_name,connect_object)
df.to_json(filename)
df.to_html()
df.to_markdown()
df.to_sting()
df.to_latex(index=False)
df.to_dict('split')
df.to_clipboard(sep=',',index=False)
writer=pd.ExcelWriter('nes.xlsx')
df_1.to_excel(writer,sheet_name='第一个',index=False)
df_2.to_excel(writer,sheet_name='第二个',index=False)
writer.save()
with pd.ExcelWriter('new.xlsx') as writer:
df1.to_excel(writer,sheet_name='第一个')
df2.to_excel(writer,sheet_name='第二个')
创建测试对象
pd.DataFrame(np.random.rand(20,5))
pd.Series(my_list)
df.index=pd.date_range('1900/1/30',periods=df.shape[0])
df.pt.util.testing.makeDataFrame()
df=pd.util.testing.makePeriodFrame()
df=pd.util.testing.makeTimeDateFrame()
df=pd.util.testig.makeMixeDataFrame()
查看、检查、统计、属性
df.head(n)
df.tail(n)
df.sample(n)
df.shape
df.info()
df.describe()
df.dtypes
df.axes
df.mean()
df.mean(1)
df.corr()
df.count()
df.max()
df.min()
df.median()
df.std()
df.var()
s.mode()
s.cumprod()
df.cumsum(axis=0)
s.nunique()
df.idxmax()
df.idmin()
df.columns
df.team.unique()
s.values_counts(drona=False)
df.apply(pd.Series.value_counts)
df.duplicated()
df.drop_option()
pd.get_option()
pd.options.display.max_rows=None
pd.options.display.max_columns=None
df.col.argmin()
df.col.idxmin()
ds.cunsum()
ds.cumprod()
ds.cummax()
ds.cummin()
ds.rolling(x).sum()
ds.rolling(x).mean()
ds.rolling(x).val()
ds.rolling(x).std()
ds.rolling(x).min()
ds.rolling(x).max()
缺失值的处理
df.info() #摘要包括所有列的列表及其数据类型以及每列中非空值的数量

; 数据清洗
df.columns=['a','b','c']
df.columns=df.columns.str.replace(' ','_')
data.loc[:, 'a']
data.loc[:, ['a', 'b']]
df.drop(['name'], axis=1)
df.drop([0,10] ,axis=0)
del df['name']
df.dropna()
df.dropna(axis=0,subset=["toy"])
df.dropna(axis=1)
df.dropna(axis=1,thresh=n)
df.fillna(x)
df.fillna(value={'prov':'未知'})
s.astype(float)
df.index.astype('datetime64[ns]')
s.replace(1,'one')
s.replace([1,3],['one',three'])
df.set_index('column_one')
df.rename(index=lambda x:x+1)
df.reset_index()
数据处理
df.round(2)
df.round({'A':1,'c':2})
df[ df['team'] == 'A') & (df['Q1']>80) & df.utype.isin(['老客','老访客'])]
df[df.name.str.contains('张')]
DataFrame.sort_values(by='
df.apply(np.max,axis=1)
df.insert(3, '两倍',df['值']*2)
样式显示
**
df['per_cost'] = df['per_cost'].map('{:,.2f}%'.format)
df.style.applymap(lambda x: 'background-color: grey' if x>0 else '',
subset=pd.IndexSlice[:, ['B', 'C']])
df.style.highlight_max(color='lightgreen').highlight_min(color='#cd4f39')
df.style.format('{:.2%}', subset=pd.IndexSlice[:, ['B']])
format_dict = {'sum':'${0:,.0f}',
'date': '{:%Y-%m}',
'pct_of_total': '{:.2%}'
'c': str.upper}
(df.style.format(format_dict)
.hide_index()
.background_gradient(subset=['sum_num'], cmap='BuGn')
.bar(color='#FFA07A', vmin=100_000, subset=['sum'], align='zero')
.bar(color='lightgreen', vmin=0, subset=['pct_of_total'], align='zero')
.bar(color=['#ffe4e4','#bbf9ce'], vmin=0, vmax=1, subset=['增长率'], align='zero')
.set_caption('2018 Sales Performance')
.hide_index())
def background_color(row):
if row.pv_num >= 10000:
return ['background-color: red'] * len(row)
elif row.pv_num >= 100:
return ['background-color: yellow'] * len(row)
return [''] * len(row)
df.style.apply(background_color, axis=1)**
Jupyter notebooks问题
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15.0, 8.0)
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
from IPython.core.display import display, HTML
display(HTML(".container { width:100% !important; }"))
from IPython.display import IFrame
IFrame('https://arxiv.org/pdf/1406.2661.pdf', width=800, height=450)
key = utils.uuid().slice(2,6)+encodeURIandParens(blob.name);
key = utils.uuid().slice(2,6)+Object.keys(that.attachments).length;
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
https://plot.ly/create
三、可视化
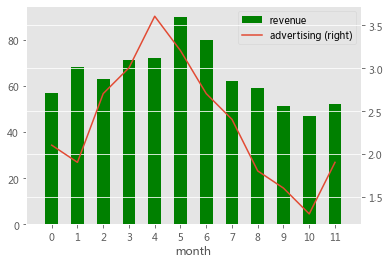
- 创建组合图
df = pd.DataFrame({"revenue":[57,68,63,71,72,90,80,62,59,51,47,52],
"advertising":[2.1,1.9,2.7,3.0,3.6,3.2,2.7,2.4,1.8,1.6,1.3,1.9],
"month":range(12)})
ax = df.plot.bar("month", "revenue", color = "green")
df.plot.line("month", "advertising", secondary_y = True, ax = ax)
ax.set_xlim((-1,12));
!](https://img-blog.csdnimg.cn/7054729c7d2a4f339cc3a07e99ac09e8.png)

Original: https://blog.csdn.net/weixin_52001949/article/details/123751722
Author: 麻辣清汤
Title: 利用python库 pandas完成数据分析(持续更新中~)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/751093/
转载文章受原作者版权保护。转载请注明原作者出处!