

以往的算法改进中,网络结构一般直接是用代码写好的,个人感觉这样的方式其实更利于算法的改进,更简单明了。但也有很多算法,比如v5,YOLOR,YOLOV7等等,是用yaml文件进行模型的定义,然后通过pare_model()函数读取模型,如果你需要 在模型中添加若干个其他模块,增添自己的想法,通过修改yaml是不易的,但在实际中这又是不可避免的。因此本文章将以YOLOv5 6.0为例,在yaml中添加注意力机制来改进网络。
本文将在yolov5s结构中插入通道注意力机制SENet为例。分别从以下两个方面添加注意力机制:
1.不改变网络深度的改进(直接替换某些层)
2.改变原网络深度(增加层数)
目录
在添加注意力之前,需要在models/common.py中添加SENet代码。代码如下:
class SE_Block(nn.Module):
def __init__(self, c1, c2):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化
self.fc = nn.Sequential(
nn.Linear(c1, c2 // 16, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c2 // 16, c2, bias=False),
nn.Sigmoid()
)
def forward(self, x):
# 添加注意力模块
b, c, _, _ = x.size() # 分别获取batch_size,channel
y = self.avg_pool(x).view(b, c) # y的shape为【batch_size, channels】
y = self.fc(y).view(b, c, 1, 1) # shape为【batch_size, channels, 1, 1】
out = x * y.expand_as(x) # shape 为【batch, channels,feature_w, feature_h】
return out
1.不改变网络深度的改进
网络的修改需要修改两个位置: yaml文件、 models/yolo.py
1.1yaml修改
首先是打开models/yolov5s.yaml文件,我们在backbone中的SPPF之前增加SENet。增添位置如下,是将backbone中第4个C3模块替换为SE_Block,如下图。
【需要注意的是通道数要匹配,SENet并不改变通道数,由于原C3的输出通道数为1024*0.5=512,所以我们这里的写的是1024,这里的1024是传入到上面我们定义的Class SE_Block(nn.Moudel)中的c2参数,c1参数是由上一层的输出通道数控制的】。


backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 conv1(3,32,k=6,s=2,p=2)
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 conv2(32,64,k=3,s=2,p=1)
[-1, 3, C3, [128]], # C3_1 有Bottleneck
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 conv3(64,128,k=3,s=2,p=1)
[-1, 6, C3, [256]], # C3_2 Bottleneck重复两次
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 conv4(128,256,k=3,s=2,p=1)
[-1, 9, C3, [512]], # C3_3 Bottleneck重复三次 输出256通道
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 Conv5(256,512,k=3,s=2,p=1)
#[-1, 3, C3, [1024]], # C3_4 Bottleneck重复1次 输出512通道
[-1, 1, SE_Block, [1024]], # 增加通道注意力机制 输出为512通道
[-1, 1, SPPF, [1024, 5]], # 9 每个都是K为5的池化
]
1.2yolo.py修改
主要是在下面的代码中,在列表中添加SE_Block,这样可以获得我们要传入的参数。 这样就改完了。
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, SE_Block]:
改完以后可以随便训练几轮试试,或者打印一下模型,看看改的对不对。可以看到在我自己的数据集上训练是可以正常进行的,
Epoch gpu_mem box obj cls labels img_size
1/299 1.4G 0.05173 0.03137 0 5 640: 100%|████████████████████████████████████████████████████████████████████████| 180/180 [04:09
2.改变原网络深度
比如我要在第一个C3后面加一个SE。yaml的修改如下。接下来稍微麻烦一点了【需要你了解v5的每层结构】,由于我们在backbone中加入了一层,也就是相当于后面的网络与之前相比都往后移动了一层,那么在后面的Concat部分中融合的特征层的索引也会收到影响,因此我们需要的是修改Concat层的from参数。
会改变原来网络中的这些地方:

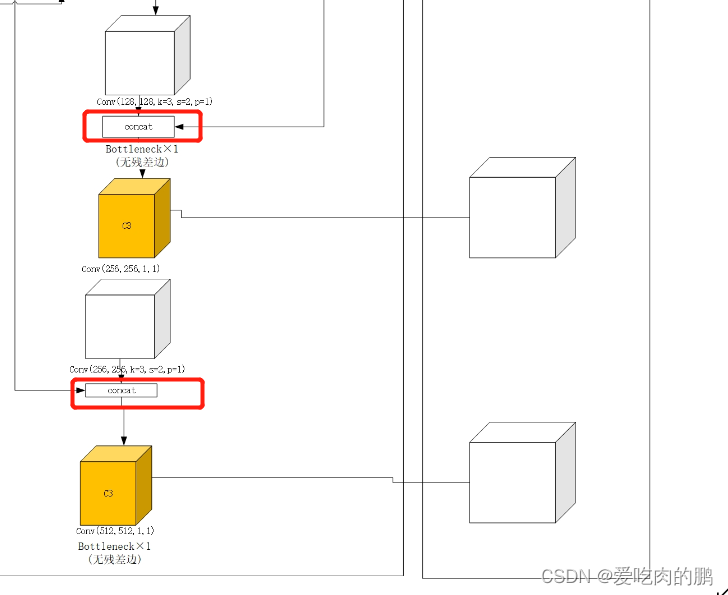
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 conv1(3,32,k=6,s=2,p=2)
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 conv2(32,64,k=3,s=2,p=1)
[-1, 3, C3, [128]], # C3_1 有Bottleneck
[-1, 1, SE_Block, [128]], # 增加通道注意力机制 输出为512通道
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 conv3(64,128,k=3,s=2,p=1)
[-1, 6, C3, [256]], # C3_2 Bottleneck重复两次
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 conv4(128,256,k=3,s=2,p=1)
[-1, 9, C3, [512]], # C3_3 Bottleneck重复三次 输出256通道
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 Conv5(256,512,k=3,s=2,p=1)
[-1, 3, C3, [1024]], # C3_4 Bottleneck重复1次 输出512通道
[-1, 1, SPPF, [1024, 5]], # 9 每个都是K为5的池化
]
可以看到实际就是每个Concat也后面移动一层,因此yaml修改为一下。最终的Detect的from也需要修改。
head:
[[-1, 1, Conv, [512, 1, 1]], # conv1(512,256,1,1)
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4 将C3_3与SPPF出来后的上采样拼接 拼接后的通道为512
[-1, 3, C3, [512, False]], # 13 conv(256,256,k=1,s=1) 没有残差边
[-1, 1, Conv, [256, 1, 1]], # conv2(256,128,1,1)
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3 与C3_2拼接,输出256通道
[-1, 3, C3, [256, False]], # 17 (P3/8-small) conv3(128,128,1,1)
[-1, 1, Conv, [256, 3, 2]],# conv4(128,128,3,2,1)
[[-1, 15], 1, Concat, [1]], # cat head P4 拼接后256通道
[-1, 3, C3, [512, False]], # 20 (P4/16-medium) conv5(256,256,1,1)
[-1, 1, Conv, [512, 3, 2]],# conv6(256,256,3,2,1)
[[-1, 11], 1, Concat, [1]], # cat head P5 拼接后是512
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
同理,也需要在models/yolo.py中修改如下,增加SE_Block:
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, SE_Block]:
也可以训练一个epoch看看,或者打印一下网络。这样就改完啦。
Starting training for 300 epochs...
Epoch gpu_mem box obj cls labels img_size
0/299 0.419G 0.09617 0.03019 0 13 640: 12%|████████▉ | 22/180 [00:15
Model(
(model): Sequential(
(0): Conv(
(conv): Conv2d(3, 32, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(1): Conv(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(2): C3(
(cv1): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(3): SE_Block(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=64, out_features=4, bias=False)
(1): ReLU(inplace=True)
(2): Linear(in_features=4, out_features=64, bias=False)
(3): Sigmoid()
)
)
(4): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(5): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(6): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(7): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(8): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(9): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(10): SPPF(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(11): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(12): Upsample(scale_factor=2.0, mode=nearest)
(13): Concat()
(14): C3(
(cv1): Conv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(15): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(16): Upsample(scale_factor=2.0, mode=nearest)
(17): Concat()
(18): C3(
(cv1): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(19): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(20): Concat()
(21): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(22): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(23): Concat()
(24): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(25): Detect(
(m): ModuleList(
(0): Conv2d(128, 255, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 255, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 255, kernel_size=(1, 1), stride=(1, 1))
)
)
)
)
不论哪种网络的修改,都需要注意的一点是通道维度的对应,如果报错了,例如mat1和mat2无法相乘,或者shape匹配问题,都是你修改后的网络channels不匹配导致的,要细心检查,在增删网络的时候,要注意yaml中from列表参数的影响,因为你修改了一层,将会影响后面的后面层。
Original: https://blog.csdn.net/z240626191s/article/details/126970095
Author: 爱吃肉的鹏
Title: YOLOv5算法改进–通过yaml文件添加注意力机制【附代码】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/720554/
转载文章受原作者版权保护。转载请注明原作者出处!