

一、前言
ECA-NET(CVPR 2020)简介:
论文名:ECA-Net: Effificient Channel Attention for Deep Convolutional Neural Networks论文地址:https://arxiv.org/abs/1910.03151开源代码:https://github.com/BangguWu/ECANet
作为一种轻量级的注意力机制,ECA-Net其实也是通道注意力机制的一种实现形式。
ECA-Net可以看作是SE-Net的改进版。是天津大学、大连理工、哈工大多位教授于19年共同发布的。
ECA-Net的作者认为:SE-Net对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。在ECA-Net的论文中,作者认为:卷积具有良好的跨通道信息获取能力。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。既然用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量,用更专业的名词就是跨通道交互的覆盖率。
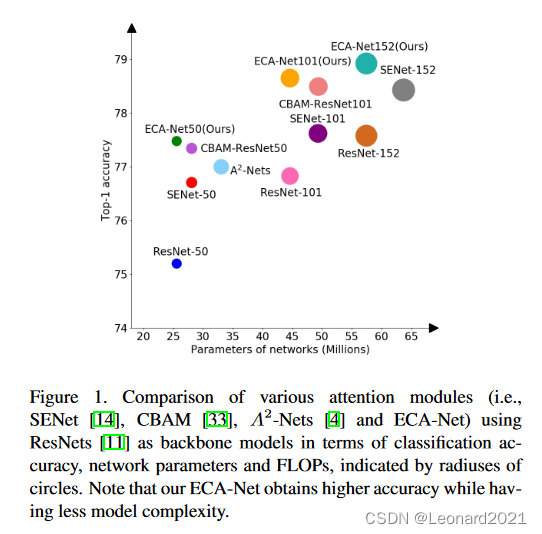

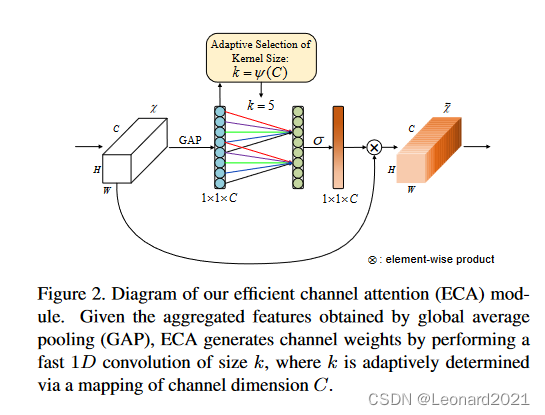

ECA-Net可以插入到其他CNN网络中来增强其性能,比如:插入到ResNet、MobileNetV2中。本文主要实现的是 将ECA注意力机制加入到ResNet50中 。且在性能上是可以说是全面超越了CBAM(ECCV 2018),且对比未使用ECA的原始ResNet,也有着不错的准确率提升。
论文的开源还提供了使用ECA的ResNet预训练模型,而未使用ECA机制的原始ResNet模型也可以导入使用。

我的数据集结构:
其中train : val : test = 8 : 1 : 1,种类都是三种,只是数量不一样。
train
├── Huanglong_disease
│ ├── 000000.jpg
│ ├── 000001.jpg
│ ├── 000002.jpg
│ ├── .............
│ ├── 000607.jpg
├── Magnesium_deficiency
└── Normal
二、代码
eca_module.py
import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
eca_resnet.py
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
from eca_module import eca_layer
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class ECABasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, k_size=3):
super(ECABasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.eca = eca_layer(planes, k_size)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.eca(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ECABottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, k_size=3):
super(ECABottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.eca = eca_layer(planes * 4, k_size)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.eca(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, k_size=[3, 3, 3, 3]):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], int(k_size[0]))
self.layer2 = self._make_layer(block, 128, layers[1], int(k_size[1]), stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], int(k_size[2]), stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], int(k_size[3]), stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, k_size, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, k_size))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, k_size=k_size))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def eca_resnet18(k_size=[3, 3, 3, 3], num_classes=1_000, pretrained=False):
"""Constructs a ResNet-18 model.
Args:
k_size: Adaptive selection of kernel size
pretrained (bool): If True, returns a model pre-trained on ImageNet
num_classes:The classes of classification
"""
model = ResNet(ECABasicBlock, [2, 2, 2, 2], num_classes=num_classes, k_size=k_size)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def eca_resnet34(k_size=[3, 3, 3, 3], num_classes=1_000, pretrained=False):
"""Constructs a ResNet-34 model.
Args:
k_size: Adaptive selection of kernel size
pretrained (bool): If True, returns a model pre-trained on ImageNet
num_classes:The classes of classification
"""
model = ResNet(ECABasicBlock, [3, 4, 6, 3], num_classes=num_classes, k_size=k_size)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def eca_resnet50(k_size=[3, 3, 3, 3], num_classes=1000, pretrained=False):
"""Constructs a ResNet-50 model.
Args:
k_size: Adaptive selection of kernel size
num_classes:The classes of classification
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
print("Constructing eca_resnet50......")
model = ResNet(ECABottleneck, [3, 4, 6, 3], num_classes=num_classes, k_size=k_size)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def eca_resnet101(k_size=[3, 3, 3, 3], num_classes=1_000, pretrained=False):
"""Constructs a ResNet-101 model.
Args:
k_size: Adaptive selection of kernel size
num_classes:The classes of classification
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(ECABottleneck, [3, 4, 23, 3], num_classes=num_classes, k_size=k_size)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
def eca_resnet152(k_size=[3, 3, 3, 3], num_classes=1_000, pretrained=False):
"""Constructs a ResNet-152 model.
Args:
k_size: Adaptive selection of kernel size
num_classes:The classes of classification
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(ECABottleneck, [3, 8, 36, 3], num_classes=num_classes, k_size=k_size)
model.avgpool = nn.AdaptiveAvgPool2d(1)
return model
train.py
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter
from eca_resnet import eca_resnet50
import xlwt
book = xlwt.Workbook(encoding='utf-8') # 创建Workbook,相当于创建Excel
创建sheet,Sheet1为表的名字,cell_overwrite_ok为是否覆盖单元格
sheet1 = book.add_sheet(u'Train_data', cell_overwrite_ok=True)
向表中添加数据
sheet1.write(0, 0, 'epoch')
sheet1.write(0, 1, 'Train_Loss')
sheet1.write(0, 2, 'Train_Acc')
sheet1.write(0, 3, 'Val_Loss')
sheet1.write(0, 4, 'Val_Acc')
sheet1.write(0, 5, 'lr')
sheet1.write(0, 6, 'Best val Acc')
def train_one_epoch(model, optimizer, data_loader, device, epoch):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
accu_loss = torch.zeros(1).to(device) # 累计损失
accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数
optimizer.zero_grad()
sample_num = 0
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
loss.backward()
accu_loss += loss.detach()
data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
@torch.no_grad()
def evaluate(model, data_loader, device, epoch):
loss_function = torch.nn.CrossEntropyLoss()
model.eval()
accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数
accu_loss = torch.zeros(1).to(device) # 累计损失
sample_num = 0
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
accu_loss += loss
data_loader.desc = "[valid epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
tb_writer = SummaryWriter()
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "D:\pyCharmdata\Vit_myself_bu\datasets") # 数据集地址
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)#nw
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)#nw
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = eca_resnet50()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet50-19c8e357.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path),False)
# for param in net.parameters():
# param.requires_grad = False #是否冻结网络
# change fc layer structure
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 28) #数据集种类
net.to(device)
images = torch.zeros(1, 3, 224, 224).to(device)#要求大小与输入图片的大小一致
tb_writer.add_graph(net, images, verbose=False)
epochs = 100 # 训练轮数
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
best_acc = 0.0
save_path = './weight/ECA_ResNet50_Myself.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
sheet1.write(epoch + 1, 0, epoch + 1)
sheet1.write(epoch + 1, 5, str(optimizer.state_dict()['param_groups'][0]['lr']))
# train
train_loss, train_acc = train_one_epoch(model=net,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
sheet1.write(epoch + 1, 1, str(train_loss))
sheet1.write(epoch + 1, 2, str(train_acc))
# validate
val_loss, val_acc = evaluate(model=net,
data_loader=validate_loader,
device=device,
epoch=epoch)
sheet1.write(epoch + 1, 3, str(val_loss))
sheet1.write(epoch + 1, 4, str(val_acc))
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
if val_acc > best_acc:
best_acc = val_acc
torch.save(net.state_dict(), save_path)
sheet1.write(1, 6, str(best_acc))
book.save('.\Train_data.xlsx')
print("The Best Acc = : {:.4f}".format(best_acc))
if __name__ == '__main__':
main()
predict.py
单个图片预测:
import os
import json
import torch.nn as nn
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from eca_resnet import eca_resnet50
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = r"D:\pyCharmdata\Vit_myself_bu\datasets\test\defective1\19.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = eca_resnet50()
# load model weights
weights_path = "./weight/ECA_ResNet50_Myself.pth"
#assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
in_channel = model.fc.in_features
model.fc = nn.Linear(in_channel, 28)
assert os.path.exists(weights_path), "file {} does not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path), False)
model.to(device)
# prediction
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print("class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy()))
'''
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))'''
plt.show()
if __name__ == '__main__':
main()
batch_predict.py
对文件夹内的图片进行批量预测
import os
import json
import torch.nn as nn
import torch
from PIL import Image
from torchvision import transforms
from eca_resnet import eca_resnet50
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
# 指向需要遍历预测的图像文件夹
imgs_root = r"D:\pyCharmdata\Vit_myself_bu\datasets\test\defective1"
assert os.path.exists(imgs_root), f"file: '{imgs_root}' dose not exist."
# 读取指定文件夹下所有jpg图像路径
img_path_list = [os.path.join(imgs_root, i) for i in os.listdir(imgs_root) if i.endswith(".jpg")]
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), f"file: '{json_path}' dose not exist."
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = eca_resnet50()
# load model weights
weights_path = "./weight/ECA_ResNet50_Myself.pth"
# assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
in_channel = model.fc.in_features
model.fc = nn.Linear(in_channel, 28)
assert os.path.exists(weights_path), "file {} does not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path), False)
model.to(device)
# prediction
model.eval()
batch_size = 8 # 每次预测时将多少张图片打包成一个batch
with torch.no_grad():
for ids in range(0, len(img_path_list) // batch_size):
img_list = []
for img_path in img_path_list[ids * batch_size: (ids + 1) * batch_size]:
assert os.path.exists(img_path), f"file: '{img_path}' dose not exist."
img = Image.open(img_path)
img = data_transform(img)
img_list.append(img)
# batch img
# 将img_list列表中的所有图像打包成一个batch
batch_img = torch.stack(img_list, dim=0)
# predict class
output = model(batch_img.to(device)).cpu()
predict = torch.softmax(output, dim=1)
probs, classes = torch.max(predict, dim=1)
for idx, (pro, cla) in enumerate(zip(probs, classes)):
print("image: {} class: {} prob: {:.3}".format(img_path_list[ids * batch_size + idx],
class_indict[str(cla.numpy())],
pro.numpy()))
if __name__ == '__main__':
main()
三、数据处理和可视化
模型训练默认100次,使用Adam优化器,初始学习率为0.01,使用余弦退火学习率。
在训练过程中或者训练完成后,可以在终端输入:
tensorboard --logdir=runs/
来观察训练数据的可视化图片,包括train_loss、train_acc、val_acc、val_loss、lr等,还有神经网络的可视化图片。

简单训练10次。训练完成还会在项目根目录产生Excel文件,里面记录了训练全过程的数据,你也可以使用Matlab 对其进行高度自定义化的可视化。
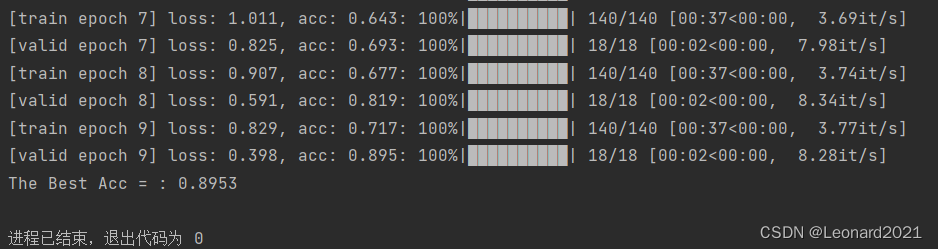
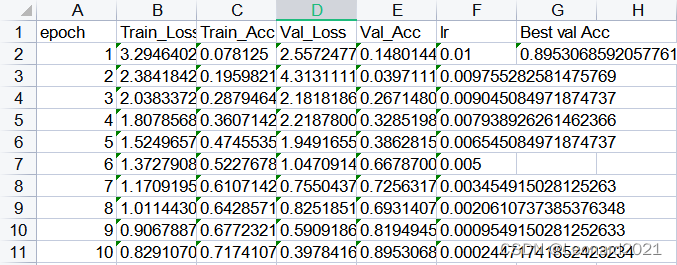
我的项目架构,需要的自取:
ECA_ResNet.zip-深度学习文档类资源-CSDN下载
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果本文对你有帮助,欢迎一键三连!
Original: https://blog.csdn.net/weixin_51331359/article/details/124772274
Author: Leonard2021
Title: 【pytorch】ECA-NET注意力机制应用于ResNet的代码实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/705877/
转载文章受原作者版权保护。转载请注明原作者出处!