

聚类的概念
聚类是一种机器学习技术,它涉及到数据点的分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习的方法,是许多领域中常用的统计数据分析技术。
聚类和分类最大的不同在于:分类的目标是事先已知的,而聚类则不一样,聚类事先不知道目标变量是什么,类别没有像分类那样被预先定义出来。这也是聚类存在的意义。
聚类的过程
- 数据准备:包括 特征标准化和降维;
- 特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中;
- 特征提取:通过对所选择的特征进行转换形成新的突出特征;
- 聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度 量,而后执行聚类或分组;
- 聚类结果评估:是指对聚类结果进行评估,评估主要有3种:外部有效性评估、内部有效性评估和相关性测试评估。
良好聚类算法的特征
- 良好的可伸缩性
- 处理不同类型数据的能力
- 处理噪声数据的能力
- 对样本顺序的不敏感性
- 约束条件下的表现
- 易解释性和易用性
聚类分析的要求
不同的聚类算法有不同的应用背景,有的适合于大数据集,可以发现任意形状的聚簇;有的算法思想简单,适用于小数据集。总的来说,数据挖掘中针对聚类的典型要求包括:
(1)可伸缩性: 当数据量从几百上升到几百万时,聚类结果的准确度能一致。
(2) 处理不同类型属性的能力:许多算法针对的数值类型的数据。但是,实际应用场景中,会遇到二元类型数据,分类/标称类型数据,序数型数据。
(3)发现任意形状的类簇:许多聚类算法基于距离(欧式距离或曼哈顿距离)来量化对象之间的相似度。基于这种方式,我们往往只能发现相似尺寸和密度的球状类簇或者凸型类簇。但是,实际中类簇的形状可能是任意的。
(4)初始化参数的需求最小化:很多算法需要用户提供一定个数的初始参数,比如期望的类簇个数,类簇初始中心点的设定。 聚类的结果对这些参数十分敏感,调参数需要大量的人力负担,也非常影响聚类结果的准确性。
(5)处理噪声数据的能力: 噪声数据通常可以理解为影响聚类结果的干扰数据,包含孤立点,错误数据等,一些算法对这些噪声数据非常敏感,会导致低质量的聚类。
(6)增量聚类和对输入次序的不敏感:一些算法不能将新加入的数据快速插入到已有的聚类结果中,还有一些算法针对不同次序的数据输入,产生的聚类结果差异很大。
(7)高维性:有些算法只能处理2到3维的低纬度数据,而处理高维数据的能力很弱, 高维空间中的数据分布十分稀疏,且高度倾斜。
(8)可解释性和可用性:我们希望得到的聚类结果都能用特定的语义、知识进行解释,和实际的应用场景相联系。
聚类的分类
- 基于划分的聚类(k‐均值算法、k‐medoids算法、k‐prototype算法)
- 基于层次的聚类
- 基于密度的聚类(DBSCAN算法、OPTICS算法、DENCLUE算法)
- 基于网格的聚类
- 基于模型的聚类(模糊聚类、Kohonen神经网络聚类)
下面以K-均值聚类算法为例:
KMeans
聚类算法有很多种(几十种),K-Means是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是 只能应用于连续型的数据,并且一定要在聚类前需要手工指定要分成几类
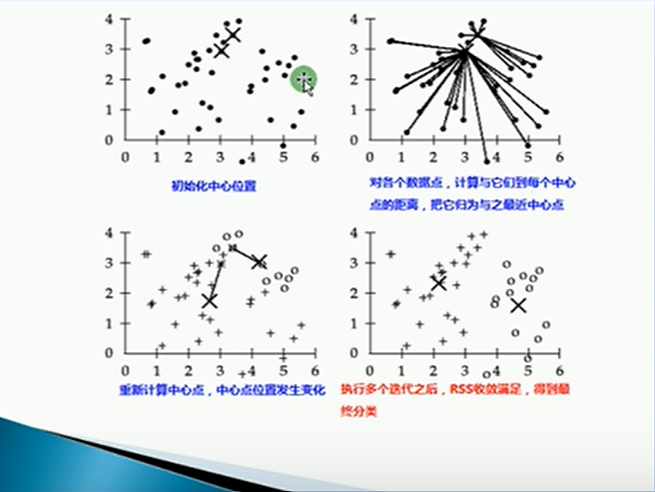

上面两张图应该很好理解
注意问题
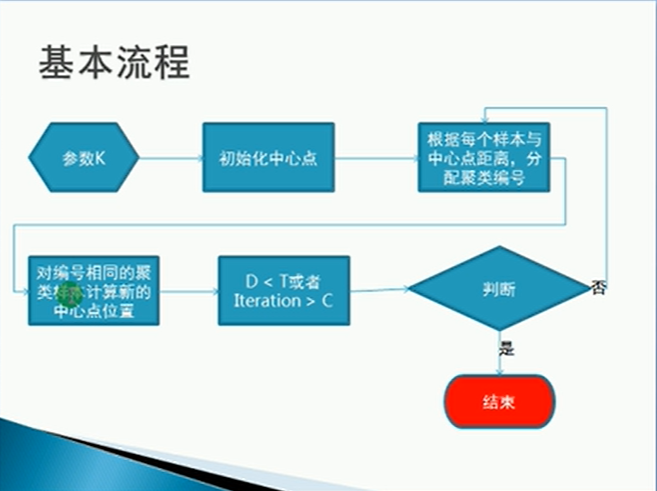
K如何确定
kmenas算法 首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。这样做的前提是我们已经知道数据集中包含多少个簇,但很多情况下,我们并不知道数据的分布情况,实际上聚类就是我们发现数据分布的一种手段,这就陷入了鸡和蛋的矛盾。如何有效的确定K值,这里大致提供几种方法,若各位有更好的方法,欢迎探讨。
1. 与层次聚类结合
经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果粗的数目,并找到一个初始聚类,然后用迭代重定位来改进该聚类。
2. 稳定性方法
稳定性方法对一个数据集进行2次重采样产生2个数据子集,再用相同的聚类算法对2个数据子集进行聚类,产生2个具有k个聚类的聚类结果,计算2个聚类结果的相似度的分布情况。2个聚类结果具有高的相似度说明k个聚类反映了稳定的聚类结构,其相似度可以用来估计聚类个数。采用次方法试探多个k,找到合适的k值
API
double cv::kmeans(
InputArray data,
int K,
InputOutputArray bestLabels,
TermCriteria criteria,
int attempts,
int flags,
OutputArray centers = noArray()
)
参数说明
data
待聚类的数据集,数据集的每一个样本是一个N维的点,点坐标都是float型的,例如:有m个样本,每个样本有n个维度,那data的格式就为cv::Mat dataSet(m,n,CV_32F)
K
聚类数,即要把数据集聚成k类
bestLabels
存储data中每一个样本的标签,数据类型为int型
criteria
opencv中
迭代算法的终止条件
,例如迭代的次数限制,或者迭代的精度达到要求时,算法迭代终止
attempts
使用不同的初始聚类中心执行算法的次数
flags
cv::KmeansFlags见下表,选择
聚类中心的初始化方式 centers
集群中心输出矩阵,每个集群中心一行
. cv::KmeansFlags
KMEANS_RANDOM_CENTERS在每次尝试中选择随机的初始中心KMEANS_PP_CENTERSUse kmeans++ center initialization by Arthur and Vassilvitskii [Arthur2007].KMEANS_USE_INITIAL_LABELS
在第一次(可能是唯一一次)尝试中,使用用户提供的标签,而不是从初始中心计算它们。 对于第二次和以后的尝试,使用随机或半随机中心。 使用KMEANS_*_CENTERS标志之一来指定确切的方法
利用OpenCV 的 API 实现
#include <opencv2 opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Mat src = imread("tahiti.jpg");
Mat img(500, 500, CV_8UC3);
RNG rng(12345);
Scalar colorTab[] = {
Scalar(30,30,240),
Scalar(240, 30, 30),
Scalar(30, 240, 30),
Scalar(240, 240, 30),
Scalar(30,240,240)
};
int numCluster = rng.uniform(2, 5);
cout << "number of clusters: " << numCluster << endl;
int sampleCount = rng.uniform(5, 1000);
Mat points(sampleCount, 1, CV_32FC2);
Mat labels, centers;
// 生成随机数
for (int k = 0; k < numCluster; k++)
{
Point center;
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
Mat pointChunk = points.rowRange(k * sampleCount / numCluster, k == numCluster - 1 ? sampleCount: (k + 1) * sampleCount / numCluster);
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols * 0.05, img.rows * 0.05));
}
randShuffle(points, 1, &rng); // 随机化函数
// 使用kmeans
kmeans(points, numCluster, labels, TermCriteria(TermCriteria::EPS+TermCriteria::COUNT,10,0.1),3,KMEANS_PP_CENTERS,centers); // TermCriteria是迭代终止函数
// 用不同颜色显示分类
img = Scalar::all(255);
for (int i = 0; i < sampleCount; i++)
{
int index = labels.at<int>(i);
Point p = points.at<point2f>(i);
circle(img, p, 2, colorTab[index],-1,8);
}
for (int i = 0; i < centers.rows; i++)
{
int x = centers.at<float>(i, 0);
int y = centers.at<float>(i, 1);
cout << "c.x = "<< x << "c.y" << y << endl;
circle(img, Point(x, y), 40, colorTab[i], 1, LINE_AA);
}
imshow("KMeans-Data", img);
waitKey(0);
return 0;
}</float></float></point2f></int></iostream></opencv2>
导入的原图:

实现效果:

利用KMeans聚类算法实现用颜色进行图像分割
#include <opencv2 opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Scalar colorTab[] = {
Scalar(30,30,240),
Scalar(240, 30, 30),
Scalar(30, 240, 30),
Scalar(240, 240, 30),
Scalar(30,240,240)
};
Mat src = imread("tahiti.jpg");
if (src.empty())
{
cout << "could not load image\n";
return -1;
}
namedWindow("input image", WINDOW_AUTOSIZE);
imshow("原图", src);
int width = src.cols;
int height = src.rows;
int dims = src.channels();
// 初始化定义
int sampleCount = width * height;
int clusterCount = 4;
Mat points(sampleCount, dims, CV_32F, Scalar(10));
Mat labels;
Mat centers(clusterCount, 1, points.type());
// RGB 数据转换到样本数据
for (int row = 0; row < height; row++)
{
for (int col = 0; col < width; col++)
{
int index = row * width + col;
Vec3b bgr = src.at<vec3b>(row, col);
points.at<float>(index, 0) = static_cast<int>(bgr(0));
points.at<float>(index, 0) = static_cast<int>(bgr(1));
points.at<float>(index, 0) = static_cast<int>(bgr(2));
}
}
// 运行K-means
TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1);
kmeans(points, clusterCount, labels, criteria, 3, KMEANS_PP_CENTERS, centers);
// 显示图像分割结果
Mat result = Mat::zeros(src.size(), src.type());
for (int row = 0; row < height; row++)
{
for (int col = 0; col < width; col++)
{
int index = row * width + col;
int label = labels.at<int>(index, 0);
result.at<vec3b>(row, col)[0] = colorTab[label](0);
result.at<vec3b>(row, col)[1] = colorTab[label](1);
result.at<vec3b>(row, col)[2] = colorTab[label](2);
}
}
imshow("output", result);
waitKey(0);
return 0;
}</vec3b></vec3b></vec3b></int></int></float></int></float></int></float></vec3b></iostream></opencv2>

用C++ 实现KMeans
(我只能说我看不懂)
#include<iostream>
#include<graphics.h>
#include<cmath>
#include<cstdlib>
#include<easyx.h>
#include<vector>
using namespace std;
//随机生成的点的数目
#define POINT_NUM 8000
//窗口的大小
#define WIDTH 600
#define HEIGHT 600
struct point
{
double x; //该点的X坐标
double y; //该点的Y坐标
int cluster; //该店所属聚类的索引
};
/**
绘制每个聚类所用的颜色
**/
COLORREF color[15]=
{
WHITE,YELLOW,RED,BLUE,GREEN,
BROWN,LIGHTCYAN,MAGENTA,LIGHTRED,
CYAN,LIGHTBLUE,LIGHTGREEN, DARKGRAY,
LIGHTMAGENTA,LIGHTGRAY,
};
//初始化聚类点
void initCluster(vector<struct point*>& pointList,int num);
//随机生成聚类中心
void generateCenter(vector<struct point*>& center,int Num);
//画出所有的点
void drawCluster(vector<struct point*>& pointList);
//获得一个聚类的中心
struct point* getCenter(vector<struct point*>& cluster);
//获得两点之间的欧式距离
double getDistance(struct point* pt1,struct point* pt2);
//获得该点所属的聚类的索引
int getNearestCluster(vector<struct point*>& center,struct point* tempPoint);
//进行迭代
void iteration(vector<struct point*>& pointList,vector<struct point*>& center,int iterNum,int Knum);
//更新聚类中心
void updateCenter(vector<struct point*>& pointList,vector<struct point*>& center,int num);
//单独画出每个聚类的中心
void drawCenter(vector<struct point*>& center);
int main()
{
//用来存放这些点的坐标
vector<struct point*> pointList;
//用于存储聚类的中心
vector<struct point*> center;
//聚类的数目
int Knum;
int iteratorNum; //迭代次数
cout<<"please input the k number"<<endl; cin>>Knum;
cout<<"please input the iteratornum number"<<endl; cin>>iteratorNum;
initgraph(WIDTH,HEIGHT,SHOWCONSOLE);
setbkcolor(BLACK);
cleardevice();
//初始化种群
initCluster(pointList,POINT_NUM);
//随机生成聚类中心
generateCenter(center,Knum);
//迭代处理
iteration(pointList,center,iteratorNum,Knum);
//画出所有的点
drawCluster(pointList);
drawCenter(center);
system("pause");
closegraph();
return 0;
}
/**
随机生成种子点
**/
void initCluster(vector<struct point*>& pointList,int num)
{
cout<<"************************************"<<endl; cout<<" init cluster "<<endl; for(int num="0;num<POINT_NUM;num++)" { struct point* temppoint="new" point; temppoint->x=rand()%WIDTH;
tempPoint->y=rand()%HEIGHT;
pointList.push_back(tempPoint);
}
cout<<"************************************"<<endl; } ** 这个是最终的绘图函数 void drawcluster(vector<struct point*>& pointList)
{
cout<<"***********************************"<<endl; cout<<" draw cluster"<<endl; for(vector<struct point*>::iterator it=pointList.begin();it!=pointList.end();it++)
{
setfillcolor(color[(*it)->cluster]);
bar((int)(*it)->x,(int)(*it)->y,(int)(*it)->x+2,(int)(*it)->y+2);
}
cout<<"***********************************"<<endl; } ** 初始化聚类中心 void generatecenter(vector<struct point*>& center,int Num)
{
cout<<"************************************"<<endl; cout<<" generate cluster center "<<endl; for(int i="0;i<Num;i++)" { struct point* tempcenter="new" point; tempcenter->x = rand()%WIDTH;
tempCenter->y = rand()%HEIGHT;
center.push_back(tempCenter);
}
for(vector<struct point*>::iterator it=center.begin();it!=center.end();it++)
{
cout<<"x "<<(*it)->x<<" y "<<(*it)->y<<endl; } cout<<"************************************"<<endl; ** * 使用均值求得一个点群的中心 struct point* getcenter(vector<struct>& cluster)
{
double x=0;
double y=0;
struct point* tempCenter=new point;
for(vector<struct point*>::iterator it=cluster.begin();it!=cluster.end();it++)
{
x+=(*it)->x;
y+=(*it)->y;
}
tempCenter->x = x/cluster.size();
tempCenter->y = y/cluster.size();
return tempCenter;
}
/**
*得到一个点所属的聚类的索引
**/
int getNearestCluster(vector<struct point*>& center,struct point* tempPoint)
{
//第一个点和中心的一个点之间的坐标
vector<struct point*>::iterator it=center.begin();
double min =getDistance(tempPoint,*it);
int index=0;
double dist;
for(int i=0;it!=center.end();it++,i++)
{
dist=getDistance(tempPoint,*it);
if(dist<min) { 只有出现更近的点时才会出现 min="dist;" index="i;" } return index; ** 返回两个坐标点之间的欧式距离 double getdistance(struct point* pt1,struct pt2) deltax="pt1-">x - pt2->x;
double deltaY=pt1->y - pt2->y;
return sqrt(deltaX*deltaX+deltaY*deltaY);
}
/**
* 迭代处理
**/
void iteration(vector<struct point*>& pointList,vector<struct point*>& center,int itNum,int Knum)
{
int iterNum=0;
//迭代的次数
while(iterNum++<itnum) { cout<<"第 "<<iternum-1<<" 次迭代"<<endl; 找到每个聚类的中心 for(vector<struct point*>::iterator it=pointList.begin();it!=pointList.end();it++)
{
int index=getNearestCluster(center,*it);
(*it)->cluster = index;
}
//更新聚类的中心
updateCenter(pointList,center,Knum);
}
}
/**
*然后得到]每个聚类的中心
**/
void updateCenter(vector<struct point*>& pointList,vector<struct point*>& center,int num)
{
//清空以前的中心
center.clear();
double x;
double y;
int pointNumber;
int count=0;
//得到每个聚类的中心
while(count<num) { x="0;" y="0;" pointnumber="0;" for(vector<struct point*>::iterator it=pointList.begin();it!=pointList.end();it++)
{
if((*it)->cluster==count)
{
x+=(*it)->x;
y+=(*it)->y;
pointNumber++;
}
}
struct point* tempCenter= new point;
tempCenter->x = x/pointNumber;
tempCenter->y = y/pointNumber;
center.push_back(tempCenter);
count++;
}
}
/**
在窗口上绘制聚类的中心
**/
void drawCenter(vector<struct point*>& center)
{
cout<<"***********************************"<<endl; cout<<" draw center"<<endl; for(vector<struct point*>::iterator it=center.begin();it!=center.end();it++)
{
setfillcolor(WHITE);
fillcircle((int)(*it)->x,(int)(*it)->y,3);
}
cout<<"***********************************"<<endl; }< code></"***********************************"<<endl;></"***********************************"<<endl;></struct></num)></struct></struct></itnum)></struct></struct></min)></struct></struct></struct></endl;></"></"x></struct></"************************************"<<endl;></"***********************************"<<endl;></"***********************************"<<endl;></"************************************"<<endl;></"************************************"<<endl;></struct></"please></"please></struct></struct></struct></struct></struct></struct></struct></struct></struct></struct></struct></struct></vector></easyx.h></cstdlib></cmath></graphics.h></iostream>
Original: https://blog.csdn.net/m0_61897853/article/details/123956282
Author: DDsoup
Title: 聚类算法——KMeans(K-均值)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/703060/
转载文章受原作者版权保护。转载请注明原作者出处!