

文章目录
- 常用工具包
- 读取 xls 结尾的文件
- 删除整列(或行)都为 nan 的列(或行)
- 筛选文中是否存在异常值
- 数据标准化和归一化
- 对 dataframe 中的不同列计算相关性
- 对 dataframe 分箱
- 对 dataframe 中的 Series 排序
- 数据相关性可视化
* - heatmap 产生相关性矩阵
- 通过 sns.regplot() 可视化两组数据是否存在相关关系
- plt 作图的中文显示问题
常用工具包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import seaborn as sns
读取 xls 结尾的文件
- 今天面对一个
xxxx.xls的文件,我本来想用pd.read_excel来读取,但是失败了,最后通过下面语句读取成功:
df = pd.read_csv(filepath, encoding='gbk', sep='\t')
- 注意编码格式,文本中包含中文字符的时候,可能默认的编码格式会失败,因此选用 ‘gbk’ 格式进行编码
删除整列(或行)都为 nan 的列(或行)
df.dropna(axis=1, how='all')
df.dropna(axis=0, how='all')
筛选文中是否存在异常值
- 当我对拿到的数据想要进行归一化和标准化操作的时候,编译器提醒我,有些数据不是 float 类型,这个时候我知道我的数据中一定存在缺失值
- 但是不同的系统或者生成数据的机构在生成数据的时候往往会使用不同的符号来代替缺失的值,例如在本文的例子中,数据中缺失的值都用
-一个横线来表示 - 遍历每一列查看有多少异常值
for column in df_new.columns:
print(np.sum(df[column] == '-'))
- 将所有的异常值
-替换成 nan:
for column in df_new.columns:
df_new[column][df_new[column] == '-'] = np.nan
- 删除这些存在 nan 的行或者列,并将操作覆盖原来的
df:
df_new.dropna(axis=0, how='any', inplace=True)
数据标准化和归一化
'''数据标准化和归一化'''
std_scale = StandardScaler()
m_m_scale = MinMaxScaler()
m_m_data = m_m_scale.fit_transform(df)
std_data = std_scale.fit_transform(m_m_data)
- 这里的
df指的是要进行归一化和标准化的 pandas 的 dataframe
对 dataframe 中的不同列计算相关性
corrs =df.corr()
corrs是df中各个列的相关性矩阵
对 dataframe 分箱
- 假设现在有下面的 dataframe;我想把年龄分成 3 段,然后分别统计各自的数量或者进行其他计算
bins = np.arange(20,35,5)
print(bins)
cats = pd.cut(df['年龄'],bins=bins,labels=bins[:-1])
df.loc[:,"label"] = cats
df = df.astype(np.float64)


- 经过分箱的
df - 这里出现了一个问题,就是有些在边界上的值划分需要小心
- 在df.cut() 的函数介绍里你可以获得更多相关的内容

; 对 dataframe 中的 Series 排序
- 对于上面的例子,假设我想按照年龄排序,使用下列语句:
sorted_df = df.sort_values(by='年龄', ascending=False)

数据相关性可视化
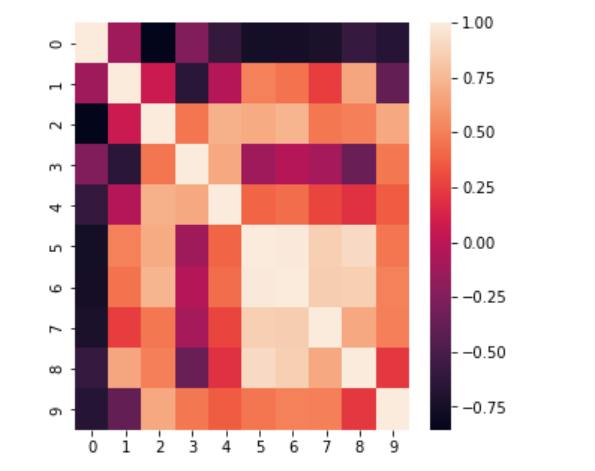
heatmap 产生相关性矩阵
- 第一步:使用
df.corr()产生相关性矩阵 - 第二步:调用 seaborn 中的 heatmap 来可视化相关性矩阵
import seaborn as sns
corrs = df.corr()
sns.heatmap(corrs)
- 例如,对于这堆数据
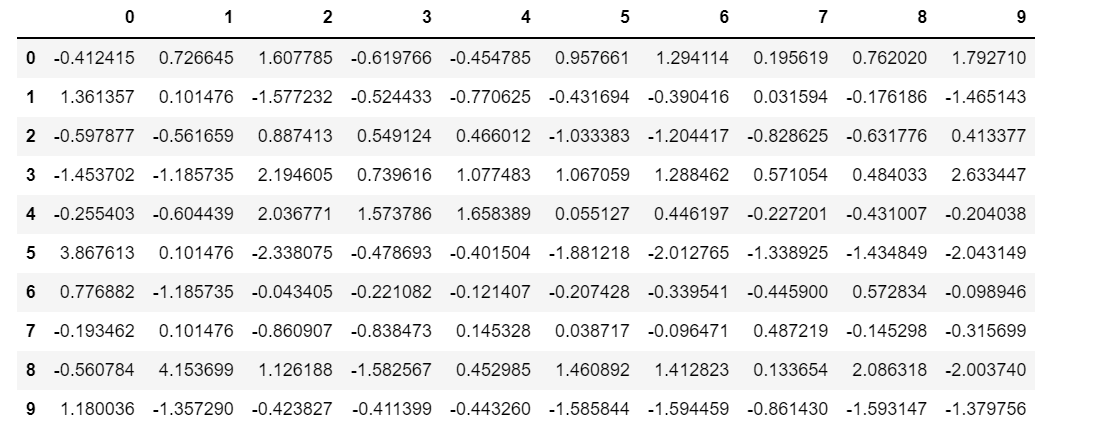
- 可以求得的相关性矩阵的可视化如下图:
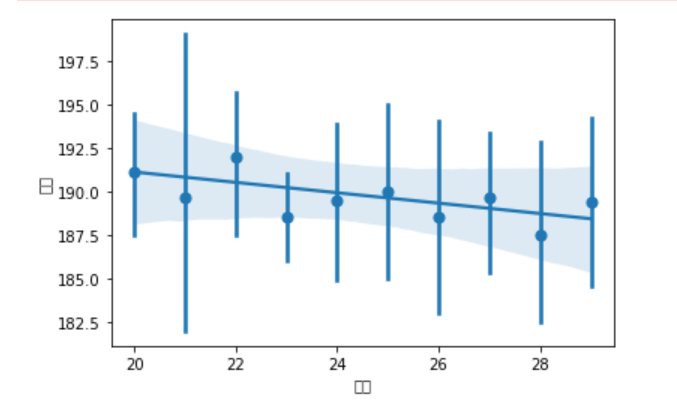
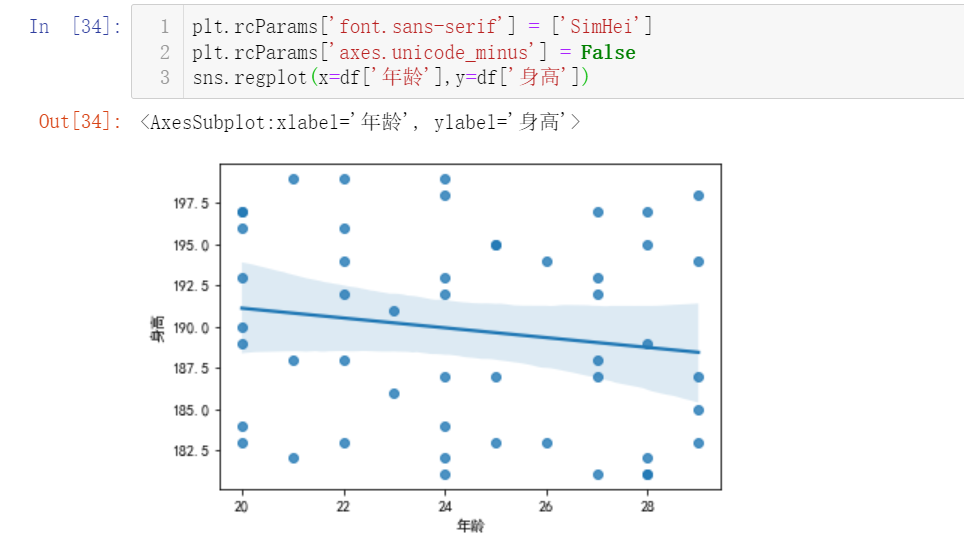
通过 sns.regplot() 可视化两组数据是否存在相关关系
- 更多参数设置和使用可以参考:
https://www.cnblogs.com/cgmcoding/p/13293395.html
sns.regplot(x=df['身高'],y=df['年龄'],x_estimator=np.mean)
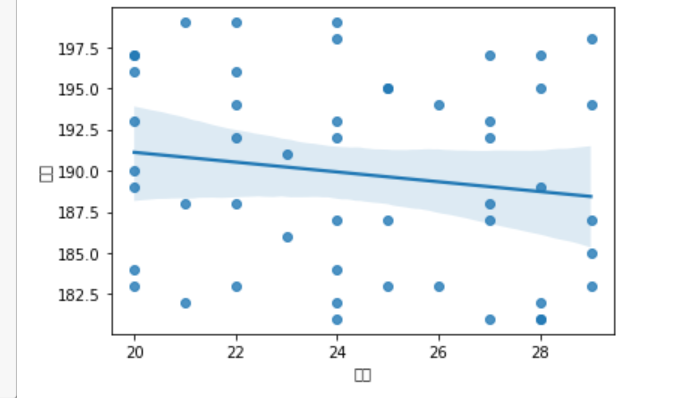
sns.regplot(x=df['身高'],y=df['年龄'])
plt 作图的中文显示问题
- 从上面的两个图上可以发现,纵坐标由于包含中文字符,所以显示不出来
- 加上这两行代码就能够显示出图中的中文字符了
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
Original: https://blog.csdn.net/qq_42902997/article/details/123588106
Author: 暖仔会飞
Title: 数据分析常用技巧之:读取 xls 后缀文件、数据相关性可视化、异常值替换和删除、求各列数据之间的相关性、数据分箱、数据排序、数据标准化和归一化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/674950/
转载文章受原作者版权保护。转载请注明原作者出处!