

数据立方体(Data Cube)是一种多维模型的表现。当然,这并不是指这个数据只有三维,数据立方体可以被看成是具有多维度的数据。
我们以一个例子来理解数据立方体 cube。


上图是数据立方体的一个示例。每个方块表示着对应维度的销售额数据。
数据立方体是一种多维数据模型,下面介绍一下多维模型的相关概念:
- 多维数据模型:为了满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实和维的数据库模型,其基本的应用是为了实现OLAP(Online Analytical Processing)
- 立方体:它是由维度构建出来的多维空间,包含了所要分析的基础数据,所有的聚合数据操作都在它上面进行
- 维度:观察数据的一种角度,比如在上图中季度、省份、产品类别都可以被看作一个维度,直观上来看维度是一个立方体的轴,比如三个维度可以构成一个立方体的空间
- 维度成员:构成维度的基本单位,比如对于省份维度,包含浙江上海江苏三个维度成员
- 层次:维度的层次结构,它存在两种:自然层次和用户自定义层次。比如对于时间维,可以分为年、月、日三个层次,也可以分为年、季度、月三个层次。一个维可以有多个层次,它是单位数据聚集的一种路径
- 级别:级别组成层次,比如年、月、日分别是时间维的三个级别
- 度量:一个数值函数,可以对数据立方体空间中的每个点求值;度量值自然就是度量的结果
- 事实表:存放度量值的表,同时存放了维表的外键,所有分析所用得数据最终都来自事实表
- 维表:对于维度的描述,每个维度对应一个或多个维表,一个维度对应一个表的是星型模式,对应多个表的是雪花模式
; 多维数据模型的模式
多维数据模型的模式主要有星形模式、雪花模式和事实星座模式。
星形模式
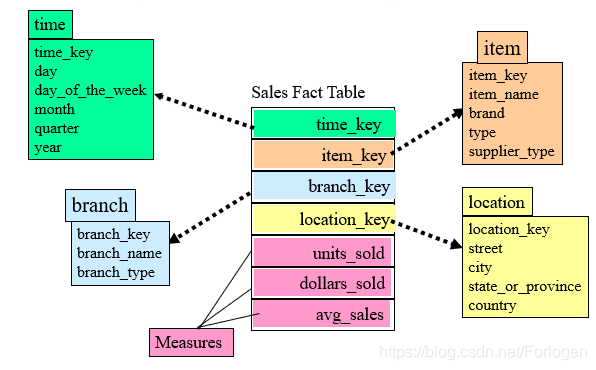
它是最常见的模式,它包括一个大的中心表(事实表),包含了大批数据但是不冗余;一组小的附属表(维表),每维一个。如下所示,从item、time、branch、location四个维度去观察数据,中心表是Sales Fact Table,包含了四个维表的标识符(由系统产生)和三个度量。
; 雪花模式
它是星模式的变种,将其中某些表规范化,把数据进一步的分解到附加的表中,形状类似雪花。如下所示,item这个维表被规范化,生成了新的item表和supplier表;同样location也被规范化为location和city两个新的表。

事实星座
允许多个事实表共享维表,可以看作是星形模式的汇集。如下所示,Sales和Shipping两个事实表共享了time、item、location三个维表。

总体来说,在数据仓库中多用事实星座模式,因为它能对多个相关的主题建模;而在数据集市流行用星形或雪花模式,因为它往往针对于某一个具体的主题。
; cube核心操作
我们回到cube。
在Hive中,也同样有cube函数,可以做cube的多个核心操作,以实现任意维度的组合统计查询。
说得通俗一点,cube就是根据需求对各个维度做group by,得到不同维度的度量数据。当我们对三个维度a, b, c使用cube函数cube(a, b, c)时,会对(a, b, c), (a, b), (a, c), (a), (b,c),(b),( c), ()依次进行group by操作,()指的是对全表进行group by操作。可以看得出来,我们可以直接建立一个cube,再根据具体需求找到我们想要的维度,以得到特定维度的度量数据。
当然,对cube进行操作,当然有一些讲究的。以下就是实际使用时常用的cube核心操作。
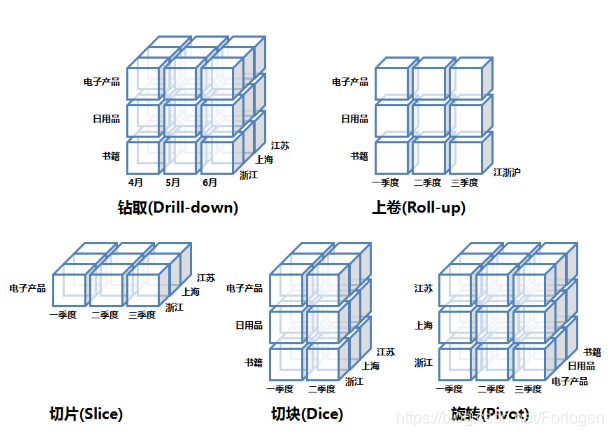
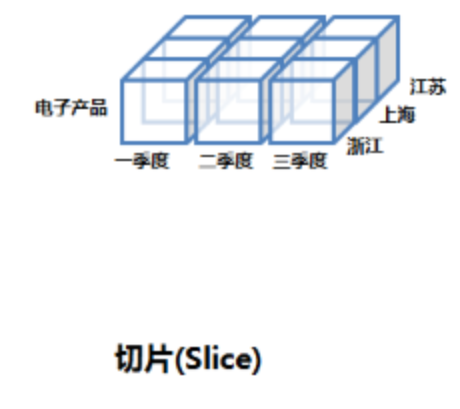
切片(Slice)
将某一个(或多个)维度上的值锁定,只观察当这个维度取这个值时的情形,相当于将一个立方体做
了一个切片。如下图所示,我们在产品类别维度锁定了电子产品,得到该维度下的切片。
; 切块(Dice)
将某一个(或多个)维度上的值固定在一个区间内,观察这个取值区间内 cube 的情形,相当于将一
个立方体做了一个切块。如下图所示,我们在产品类别维度固定在一二季度之间,得到该维度下的切块。

上卷(Roll up)
沿着某一个(或多个)维度进行聚合,观察聚合后其他维度上的汇总数据,相当于将一个立方体沿着
某个维度压缩(聚合)在一起。如下图所示,我们将省份进行聚合,把浙江江苏上海聚合成江浙沪的汇总数据。

; 下钻/钻取(Drill)
沿着某一个(或多个)维度在更细粒度层面上进行展开,观察展开后其他维度上的对应数据,相当于
将一个立方体沿着某个维度拉伸,拉伸的结果就是粒度变细,比如时间维度从季度拉伸到月。

下钻和上卷是两个相反的操作,取名上并不能很好地顾名思义,简单的解释两个操作就是:在某一个
(或多个)维度上是进行更细粒度放大观察还是最粗粒度的聚合观察。
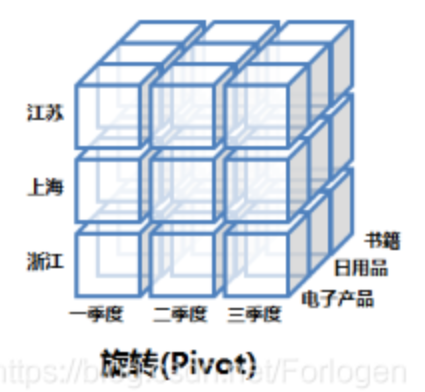
旋转(Pivot)
将维度的位置互换。在二维表格中就是行变列,列变行。如下图所示,我们将省份和产品类别两个维度进行了旋转。
; Hive的高阶聚合函数
with cube函数
使用with cube函数,会将你的group by中所有的列作组合进行group by操作,相当于做2^n次的group by,n表示group by的列数。
insert overwrite table ads_apl_trc_ovw
select
sum(pv_cnts) as pv_amt,
count(distinct guid) as uv_amt,
sum(se_cnts) as se_amt,
sum(ac_time)/sum(se_cnts) as time_avg_se,
sum(se_cnts)/count(distinct guid) as se_avg_u,
sum(pv_cnts)/count(distinct guid) as pv_avg_u,
sum(ac_time)/count(distinct guid) as time_avg_u,
count(if(se_cnts>=2,1,null)) as rbu_ratio,
province,
city,
district,
devicetype,
osname,
osversion,
release_ch,
promotion_ch
from dws_apl_trc_agu
where dt='2021-11-12'
group by province,city,district,devicetype,osname,osversion,release_ch,promotion_ch;
with cube
;
我们可以看到上面的例子,使用了with cube函数做了一个数据立方体。
我们将这段代码拆开来看,这一段就是度量。
sum(pv_cnts) as pv_amt,
count(distinct guid) as uv_amt,
sum(se_cnts) as se_amt,
sum(ac_time)/sum(se_cnts) as time_avg_se,
sum(se_cnts)/count(distinct guid) as se_avg_u,
sum(pv_cnts)/count(distinct guid) as pv_avg_u,
sum(ac_time)/count(distinct guid) as time_avg_u,
count(if(se_cnts>=2,1,null)) as rbu_ratio,
这个就是维度。
group by province,city,district,devicetype,osname,osversion,release_ch,promotion_ch;
注意,在with cube函数应用中,如果使用了distinct,则可能需要设置如下参数大于当前的组合值(2^n)。
set hive.new.job.grouping.set.cardinality=xxx
cube内的数据形式
使用了with cube的数据,实际上是做全覆盖的group by操作。但是实际数据是怎么存储的呢?数据看起来是什么样的?
我们使用一个例子助于理解。假设我们有三个维度a, b, c,下表是源数据。
abc111121121122211221222
接下来,用这三个维度做一个cube。
insert into cube_table
select * from
table_name
group by a, b, c
with cube;
其中会出现一个group by (a, c)的维度。我们用了with cube后,如果想看a, c维度的结果,就会得到这样的统计。
abccount1null131null212null122null21
在(a, c)每个group中,a和c都会有各自group的不同的值,而b的值为null,因为此时我们并不关心b到底是什么值,只关心a与c。这里表的意思是,(a, c)里面(1, 1), (1, 2), (2, 1), (2, 2)分为了四个组,得到了这四个组的统计数据。在这个结果中,我们要看的是a和c的维度统计,所以不需要知道b是什么值。
再例如,做(a, b)的group by就会有:
abccount11null112null321null122null2
当然,这只是其中两种组合,使用了with cube后,会将所有组合都做这样的group by,在每个group by中没有的维度就会置null。最后,我们将所有组合的数据存在一起,形成一张大数据表,需要特定维度时就使用where筛选即可。
那要查找对应数据的时候,就会相当方便。如通过以下sql操作cube,我们就能直接得到特定a, c维度的度量值,不需要繁琐的group by操作,因为cube已经做好了。这就是空间换时间的一个典型例子。
select * from
cube_table where a is not null and c is not null
and b is null;
使用这个方法,我们就可以直接做前面所说的各种cube操作:
- 切片操作,例如我们设置where限制其中一个维度为特定值,其他想要看到的维度设置not null,其他不需要注意到的维度为null,就可以得到切片数据。
- 切块操作,和切片相似,只是限制的维度由特定值变成范围值。
- 上卷操作,我们只关注想要的维度,设置为not null,其他不想看到的维度为null。例如,对于有省、市、区维度的数据,我们只看省(not null),不看市、区(null)。就是上卷。
- 下钻操作,设置想要的维度为not null, 其他不想看到的维度为null。例如,对于有省、市、区维度的数据,我们原本只看省,现在还要看市(not null)。这就是下钻。
grouping sets函数
grouping sets可以自由指定想要的维度组合。
例如下面的例子,我们不想让它所有维度都做组合,只想要(a, b), (a, c)的维度组合,就可以使用grouping sets。
insert into cube_table
select * from
table_name
group by a, b, c
grouping sets((a, b), (a, c))
下面两个操作是等价的。
select device_id,os_id,app_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id
grouping sets((device_id),(os_id),(device_id,os_id),())
SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg
group by device_id
UNION ALL
SELECT null,os_id,null,count(user_id) FROM test_xinyan_reg
group by os_id
UNION ALL
SELECT device_id,os_id,null,count(user_id) FROM
test_xinyan_reg
group by device_id,os_id
UNION ALL
SELECT null,null,null,count(user_id) FROM test_xinyan_reg
with rollup函数
有些维度在实际中组合并没有意义,比如国家和县的组合。因为这种维度一般都是存在着联级关系的。
例如:
国 省 市 区
国 省 市
国 省
国
此时,我们可以用with rollup。此时组合就会按照group by的顺序做组合,而不是全组合。
select * from
cube_table
group by country, province, city, district
with rollup;
上面的例子就做了(country, province, city, district), (country, province, city), (country, province), (country), ()五种组合,并不会全部组合。
参考:
https://blog.csdn.net/Forlogen/article/details/88634117
多易
Original: https://blog.csdn.net/weixin_41812379/article/details/121342195
Author: zkyCoder
Title: OLAP多维分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/698399/
转载文章受原作者版权保护。转载请注明原作者出处!