

一、定义
DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,它可以被看做一个共享相同索引的Series的字典。
DataFrame中的数据是以⼀个或多个⼆维块存放的(⽽不是列表、字典或别的⼀维数据结构)
二、创建


2.1 利用包含等长度列表或NumPy数组的字典
如果列索引顺序如果未指定,默认值为排列顺序
如果行索引未指定,默认为0到n-1
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']}
frame = pd.DataFrame(data)

指定列索引,则按照列索引顺序
指定行索引,则将行索引按顺序排列下去
columns = ['year','pop','state']
index = ['one','two','three','four','five','six']
frame2 = pd.DataFrame(data,columns = columns, index = index)

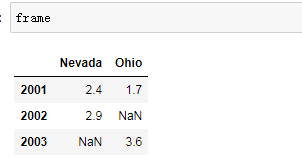
2.2 包含字典的嵌套字典。
未有的数值填入NaN
data_2 = {'Nevada':{2001:2.4, 2002:2.9},
'Ohio':{2001:1.5, 2001:1.7, 2003:3.6},
}
frame = pd.DataFrame(data_2)
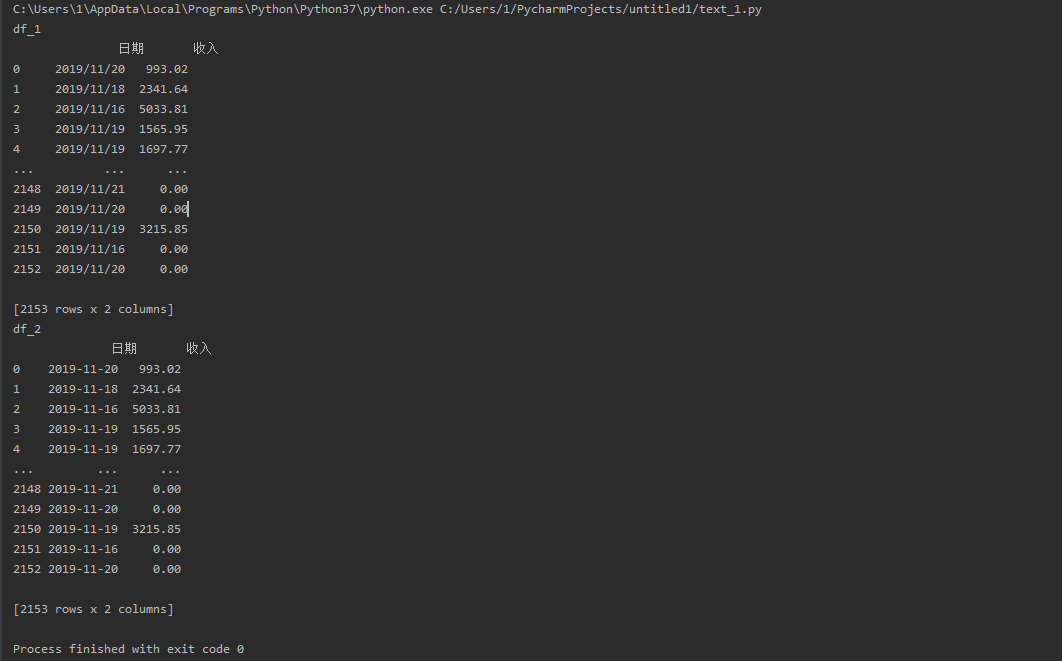
2.3 从Excel中读取

注意使用pd.excel是要安装xlrd包。
import pandas as pd
import xlrd
path_file_1 = r'E:\splider\pk\text.csv'
path_file_2 = r'E:\splider\pk\text.xlsx'
df_1 = pd.read_csv(path_file_1, encoding='gbk', header=0)
df_2 = pd.read_excel(path_file_2)
print('df_1\n', df_1)
print('df_2\n', df_2)
2.3 从数据库中读取
三、索引
3.1 轴
axis=0 就是axis=index
axis=1 就是axis=columns
谈谈我的理解。
3.1.1 创建角度看
DataFrame既有行索引也有列索引,它可以被看做一个共享相同索引的Series的字典。
为什么axis=0为axis=index?
1.DataFrame和Series都有index索引。而Series没有columns索引。
2.从下面创建的例子来看,外层逗号第一次分隔元素。冒号第二次分隔元素。
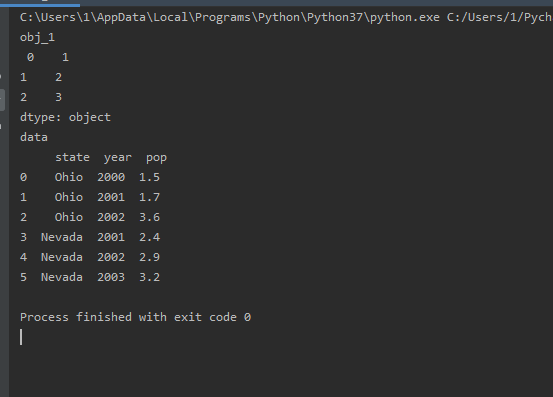
import pandas as pd
创建Series
obj_1 = pd.Series(['1',
'2',
'3'])
创建DataFrame
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']}
frame = pd.DataFrame(data)
3.1.1 展示角度看
DataFrame与Series一致的为index。为axis=0
DataFrame与Series不一致的为columns。为axis=1
3.2 改变索引顺序,重新索引。
column中可以调整列索引的顺序。
如果想调整行索引的顺序,需要分两步走。第一步建索引,第二步调整索引。
在调整索引时,可以增加索引,也可以减少索引。增加索引如果没有没有对应的值,则会填入NaN。
索引对象是 不可变的;索引对象是可以 重复的。重复的索引取值相同
import pandas as pd
data = {'state':['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year':[2000, 2001, 2002, 2001, 2002, 2003],
'pop':['1.5', '1.7', '3.6', '2.4', '2.9', '3.2']}
columns=['state', 'pop', 'year','month']
index = ['one', 'two', 'three', 'four', 'five', 'sxi'] # 只能是6个元素,不能多也不能少
frame = pd.DataFrame(data, columns=columns, index=index)
print('frame\n', frame)
columns = ['state', 'state', 'pop', 'year', 'month', 'day']
index = ['three', 'three', 'four', 'two', 'five', 'sxi', 'seven'] # 可以是任意个元素
frame_1 = pd.DataFrame(frame, index=index,columns=columns)
frame_2 = frame_1.reindex(index=index, columns=columns) #如果不指定index或者columns默认为index
frame_3 = frame_1 == frame_2 #对比frame_1与frame_2;结果为除了NaN值为False,其余为True
print('frame_1\n', frame_1)
print('frame_2\n', frame_2)
print(frame_3)

3.3 重设行索引
一般是选择某一列作为行索引,可以为重复,可以为None值。
有两种方法:
一种是设置成dataframe格式时,设置好行索引,可以为nan值。
一种是利用set_index设置成行索引。
import pandas as pd
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,None],
'year2':[2001,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']
}
df = pd.DataFrame(data)
print('原始df\n',df)
df = pd.DataFrame(data, index=data['year'])
print('设置index的df\n',df)
print(df)
df.set_index(df['year2'], inplace=True)
print('重设ndex的df\n',df)

3.4 常用索引操作。

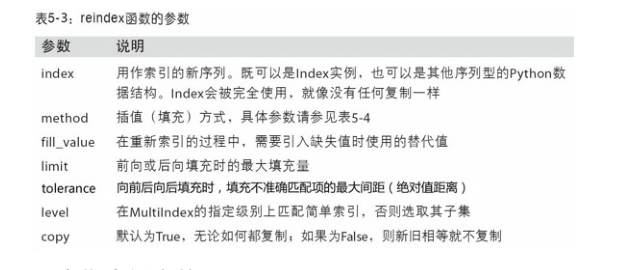
3.5 重新索引
见3.1
3.6 选取与过滤

3.6.1 使用标签与索引选取行与列
import pandas as pd
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': ['1.5', '1.7', '3.6', '2.4', '2.9', '3.2']}
columns = ['state', 'pop', 'year']
index = ['one', 'two', 'three', 'four', 'five', 'sxi'] # 只能是6个元素,不能多也不能少
frame = pd.DataFrame(data, columns=columns, index=index)
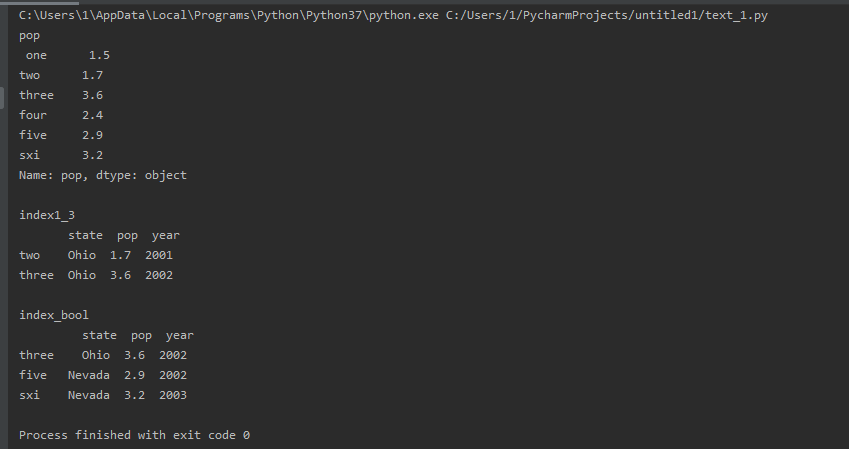
pop = frame['pop'] # 此处与Series不同,pop是在DataFrame的columns上的,而Series则是在index上的。
pop_year = frame['pop':'year'] # 报错,和Series不同
index1_3 = frame[1:3] # 选取行数,根据索引位置
index_bool = frame[frame['year'] > 2001] # 根据bool选取
print('pop\n', pop)
print('\nindex1_3\n', index1_3)
print('\nindex_bool\n', index_bool)
3.6.2 使用loc与iloc选取
import pandas as pd
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': ['1.5', '1.7', '3.6', '2.4', '2.9', '3.2']}
columns = ['state', 'pop', 'year']
index = ['one', 'two', 'three', 'four', 'five', 'sxi'] # 只能是6个元素,不能多也不能少
frame = pd.DataFrame(data, columns=columns, index=index)
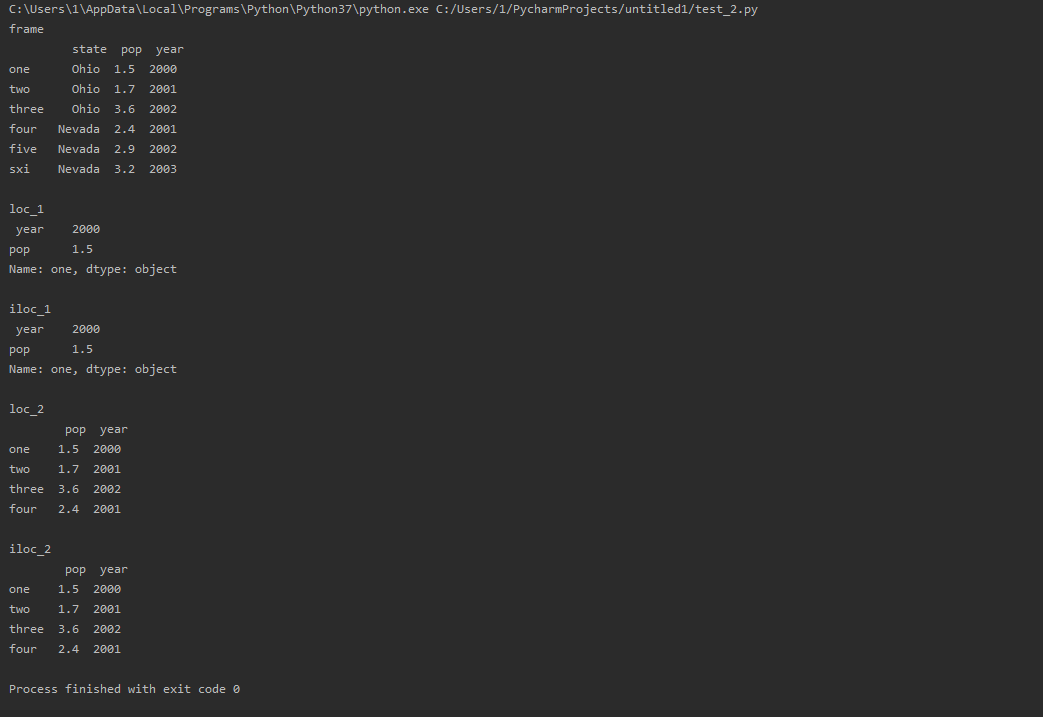
loc_1 = frame.loc['one', ['year', 'pop']] # 指定索引及其顺序
iloc_1 = frame.iloc[0, [2, 1]] # 指定索引及其顺序
loc_2 = frame.loc[:'four', 'pop':'year'] # 使用切片指定索引
iloc_2 = frame.iloc[:4, 1:3] # 使用切片指定索引
print('frame\n', frame)
print('\nloc_1\n', loc_1)
print('\niloc_1\n', iloc_1)
print('\nloc_2\n', loc_2)
print('\niloc_2\n', iloc_2)
3.6.3 整数索引。
与Series一致,如果索引中存在整数,最好使用标签索引。
3.6.4 二次选取。
当用3.5.1和3.5.2进行选取后。选取出来的如果为Series和DataFrame;则仍可以按照Series与DataFrame的选取规则进行选取。
import pandas as pd
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': ['1.5', '1.7', '3.6', '2.4', '2.9', '3.2']}
columns = ['state', 'pop', 'year']
index = ['one', 'two', 'three', 'four', 'five', 'sxi'] # 只能是6个元素,不能多也不能少
frame = pd.DataFrame(data, columns=columns, index=index)
year = frame.loc['one', ['year', 'pop']]['year']
print('year\n', year)

注:优先使用标签索引。
四、算术运算与自动对齐
4.1 直接相加减
⾃动的数据对⻬操作在不重叠的索引处引⼊了NA值。
缺失值会在算术运算过程中传播。
对于DataFrame,对⻬操作会同时发⽣在⾏和列上
对于有数据库经验的⽤户,这就像在索引标签上进⾏⾃动外连接。
⾃动的数据对⻬操作在不重叠的索引处引⼊了NA值。缺失值会在算术运算过程中传播。
对于DataFrame,对⻬操作会同时发⽣在⾏和列上。
如果DataFrame对象 加减乘除,没有共⽤的列或⾏标签,结果都会是空。
import pandas as pd
import numpy as np
df_1 = pd.DataFrame(np.arange(1, 13, 1).reshape(3, 4), index=list('qsl'), columns=list('qian'))
df_2 = pd.DataFrame(np.arange(1, 13, 1).reshape(4,3), index=list('qian'), columns=list('qsl'))
print('+\n', df_1+df_2)
print('\n/\n', df_1/df_2)

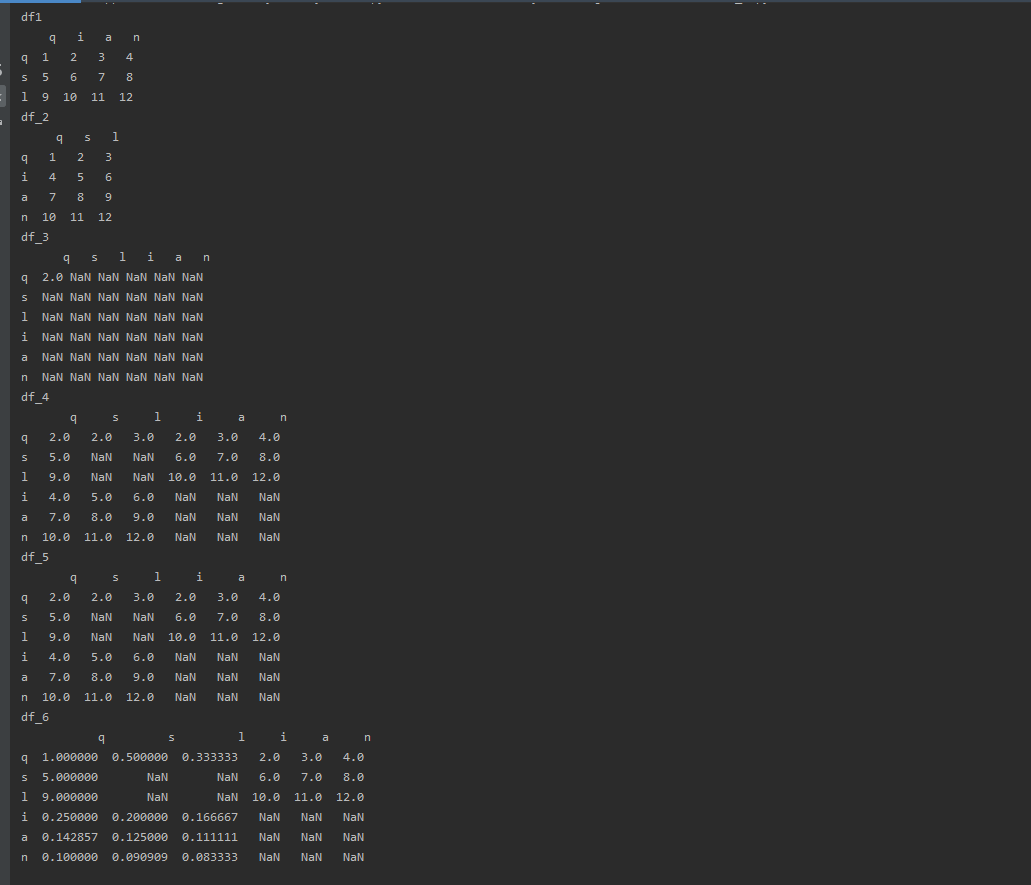
4.2 在算术算法中填充值。
在对不同索引的对象进⾏算术运算时,你可能希望当⼀个对象中某个轴标签在另⼀个对象中找不到时填充⼀个特殊值。
可以注意到当两边的行索引和列索引都没有值时,依然会被填入空。
如果其中一个有,而另一个没有。则会被填入 fill_value。
import pandas as pd
import numpy as np
index = list('qslian')
columns = list('qslian')
df_1 = pd.DataFrame(np.arange(1, 13, 1).reshape(3, 4), index=list('qsl'), columns=list('qian'))
df_2 = pd.DataFrame(np.arange(1, 13, 1).reshape(4,3), index=list('qian'), columns=list('qsl'))
df_3 = df_1 + df_2
df_4 = df_1.add(df_2, fill_value=0)
df_5 = df_1.radd(df_2, fill_value=0)
df_6 = df_1.div(df_2, fill_value=1)
df_3 = df_3.reindex(index=index, columns=columns)
df_4 = df_4.reindex(index=index, columns=columns)
df_5 = df_5.reindex(index=index, columns=columns)
df_6 = df_6.reindex(index=index, columns=columns)
print('df1\n', df_1)
print('df_2\n', df_2)
print('df_3\n', df_3)
print('df_4\n', df_4)
print('df_5\n', df_5)
print('df_6\n', df_6)
五、操作
5.1 drop操作。
和Series操作一致,不同点在与要加上轴axis。默认axis=0
import pandas as pd
import numpy as np
index = list('qslian')
columns = list('qslian')
df_1 = pd.DataFrame(np.arange(1, 13, 1).reshape(3, 4), index=list('qsl'), columns=list('qian'))
df_2 = pd.DataFrame(np.arange(1, 13, 1).reshape(4,3), index=list('qian'), columns=list('qsl'))
df_3 = df_1 + df_2
df_4 = df_1.add(df_2, fill_value=0)
df_5 = df_1.radd(df_2, fill_value=0)
df_6 = df_1.div(df_2, fill_value=1)
df_3 = df_3.reindex(index=index, columns=columns)
df_4 = df_4.reindex(index=index, columns=columns)
df_5 = df_5.reindex(index=index, columns=columns)
df_6 = df_6.reindex(index=index, columns=columns)
print('df1\n', df_1)
print('\nldf_2\n', df_2)
print('\nldf_3\n', df_3)
print('\nldf_4\n', df_4)
print('\nldf_5\n', df_5)
print('\nldf_6\n', df_6)
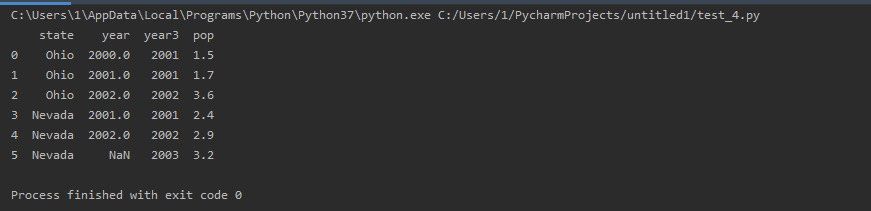
5.2 重命名列索引
import pandas as pd
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,None],
'year2':[2001,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']
}
df = pd.DataFrame(data)
df.rename(columns={'year2':'year3'}, inplace=True)
print(df)
5.3 广播
当我们从DataFrame减去Series,每⼀⾏都会执⾏这个操作。这就叫做⼴播
import pandas as pd
import numpy as np
df_1 = np.arange(12).reshape(3, 4)
Series = df_1[0]
df_2 = df_1 - Series
print(df_2)

5.3 排序与排名
5.3.1 按索引和值排序。
import pandas as pd
data = {'state':[87,45,87,12,87,34],
'year':[2000, 2001, 2002, 2001, 2002, 2003],
'pop':[30,45,89,30,87,89]}
index = list('qiansh')
df_1 = pd.DataFrame(data,index=index)
df_2 = df_1.sort_index(ascending = False) # False为降序,默认为True,也就是升序,axis 默认为0,也就是按index。
df_3 = df_1.sort_index(axis = 1)
df_4 = df_1.sort_values(by=['state','pop'],axis=0,ascending=[False,True]) # 按值进行排序
df_5 = df_1.sort_values(by=['s','a'],axis=1,ascending=[True,False])
print('df_1\n',df_1)
print('\ndf_2\n',df_2)
print('\ndf_3\n',df_3)
print('\ndf_4\n',df_4)
print('\ndf_5\n',df_5)

排序中如果碰到空值,默认情况下一律放到最后。参见Series。
5.3.1 排名。
参见Series。
六 筛选数据
筛选数据可以看成索引的补充。
筛选数据不外乎两点:
1.删除不要的,使用drop
2 选择需要的,使用索引。
6.1 删除不要的
6.1.1 根据字段是否满足条件进行删除。
import pandas as pd
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,None],
'year2':[2001,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']
}
df = pd.DataFrame(data)
a = df[df['year'] == 2001].index.tolist()
df.drop(a, inplace=True) #删除df['year']==2001的值。
print('drop_a\n', df)
6.1.2 根据索引删除。
如果根据索引删除,最好能够提前重设行索引。
import pandas as pd
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,None],
'year2':[2001,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']
}
df = pd.DataFrame(data)
df.set_index(df['year2'], inplace=True)
df.drop(2002, inplace=True)
print(df)

6.2 选择需要的
import pandas as pd
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002,None],
'year2':[2001,2001,2002,2001,2002,2003],
'pop':['1.5','1.7','3.6','2.4','2.9','3.2']
}
df = pd.DataFrame(data)
df = df[df['year']>2000]
print(df)

Original: https://www.cnblogs.com/qianslup/p/11898665.html
Author: qsl_你猜
Title: DataFrame
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/559895/
转载文章受原作者版权保护。转载请注明原作者出处!