

一直兜兜转转,看yolov5看了好长一段时间。感觉迷迷糊糊的一直摸不着边际,直到今天终于可以又进一步。现在是使用yolov5里面训练自己的数据(只说我当前的操作,不说原理,因为我现在也不会)😂
使用环境:Win10(GPU) + Anacoda3+ pycharm
下载包:GitHub – ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
直接到这个下面将整个包下载下来。
1,安装Anaconda+pycharm
Anaconda和Pycharm的安装和配置 – 做你的太阳乀 – 博客园
2,配置环境
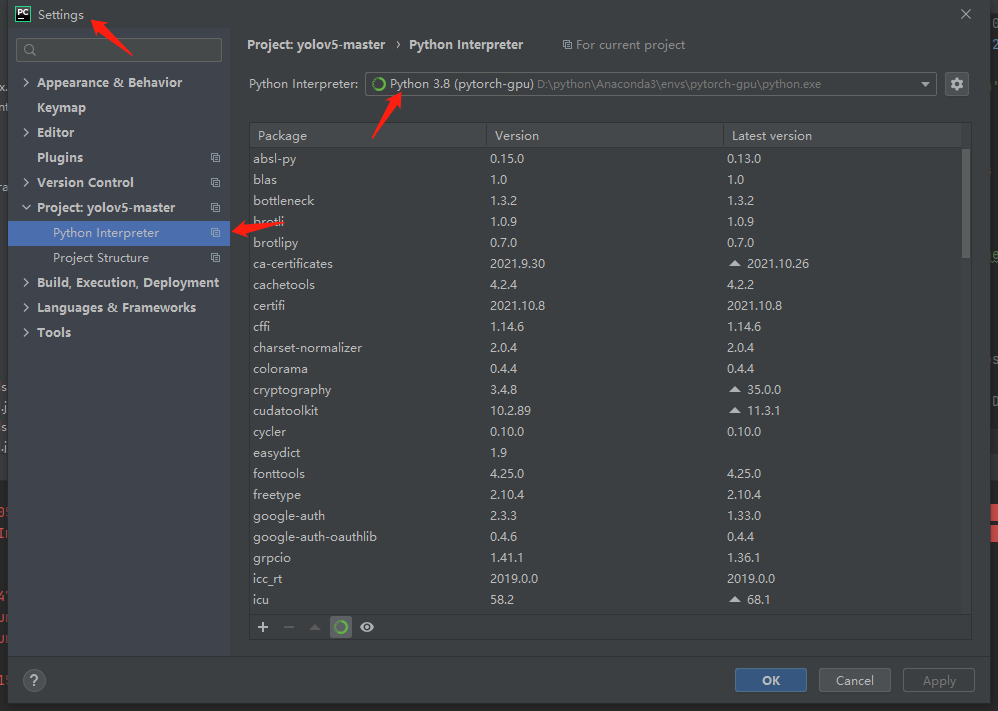

然后点击右上角的设置符号,点击”add”创建一个新的环境。我修改的环境名称为pytorch-gpu
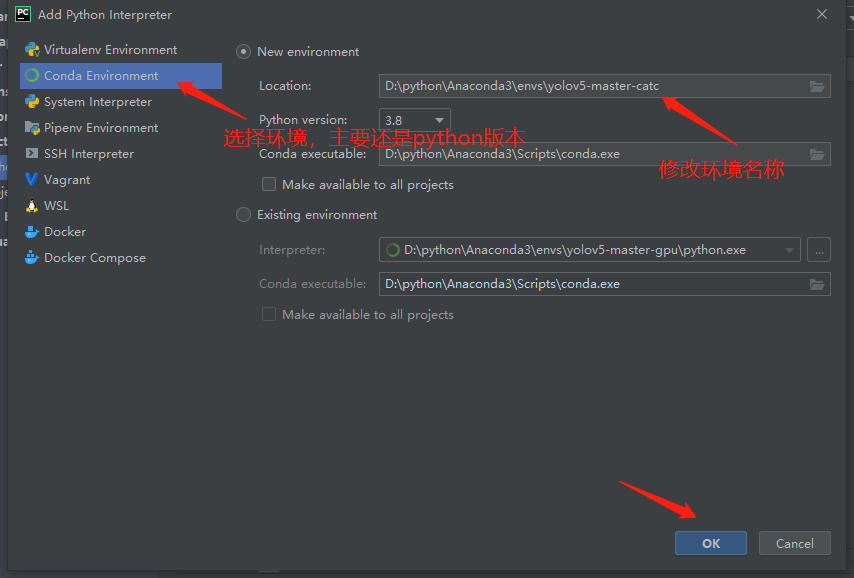
点击ok,确定了当前的运行环境。
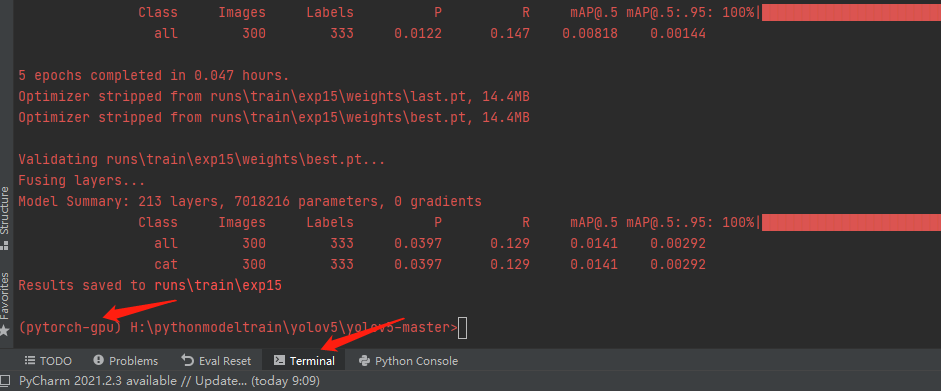
点击”Terminal”可以直接进入当前的环境。然后即可在上面安装GPU相关的依赖包
win10下conda安装pytorch-gpu版本(超详细),完美解决镜像源下载慢问题!_皮皮鲁与鲁西西�的博客-CSDN博客
4,开始注解数据集
LabelImg的使用_xiaoyifeishuang1的博客-CSDN博客
5,修改训练前的一些参数。
(1)我自己创建一个yaml文件
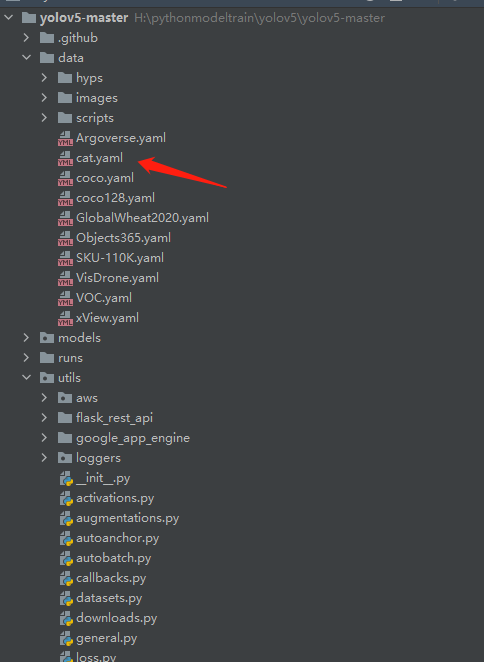
这个主要用来储存训练和测试数据的文件。我当前的如下
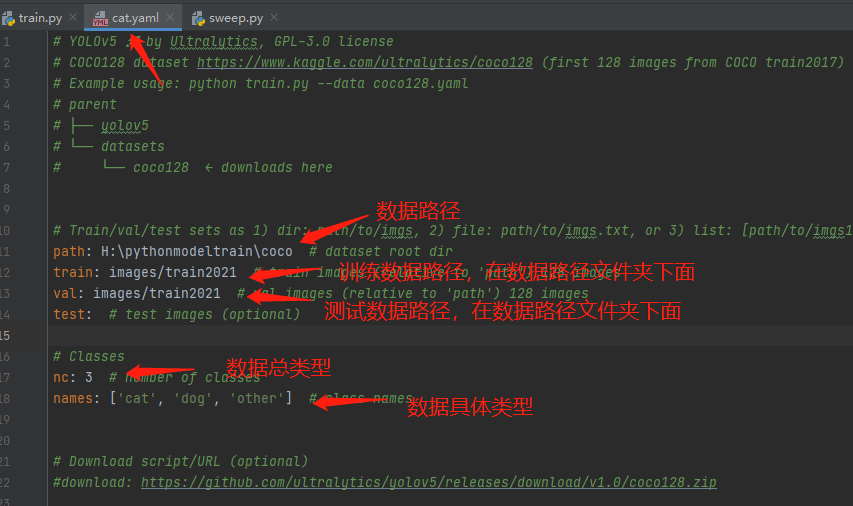
(2)设置你想训练的模型。我选择的是yolov5s,于是进去yolov5s.yaml里面将其改成我的种类
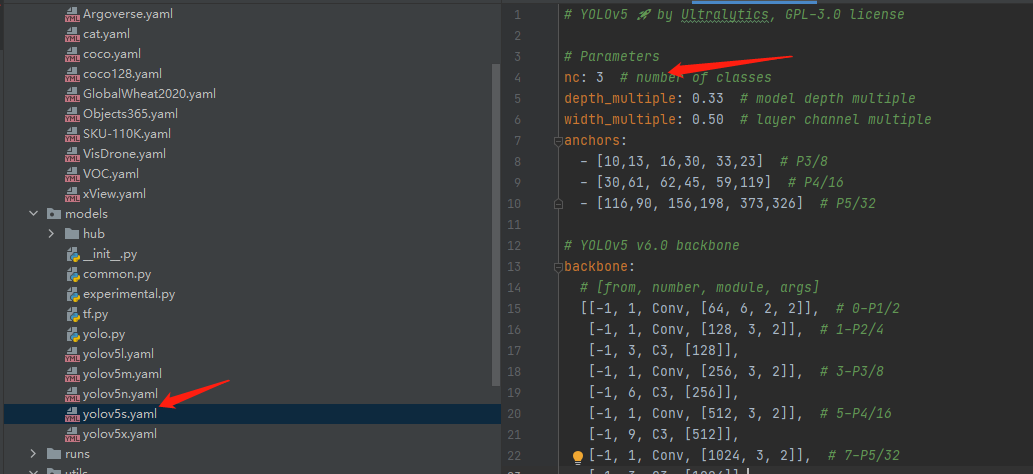
(3)开始训练
python train.py –img 640 –batch 16 –epochs 5 –data ./data/cat.yaml –cfg ./models/yolov5s.yaml –weights ”
这条马上报错了,错误信息是:RuntimeError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 4.00 GiB total capacity; 2.57 GiB already allocated; 36.61 MiB free; 2.71 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting
max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
这个我看了好久,最后发现是显卡性能不够。只需要将batch改小就好了
修改后为以下指令,
python train.py –img 640 –batch 4 –epochs 5 –data ./data/cat.yaml –cfg ./models/yolov5s.yaml –weights ”
这就跑起来了。
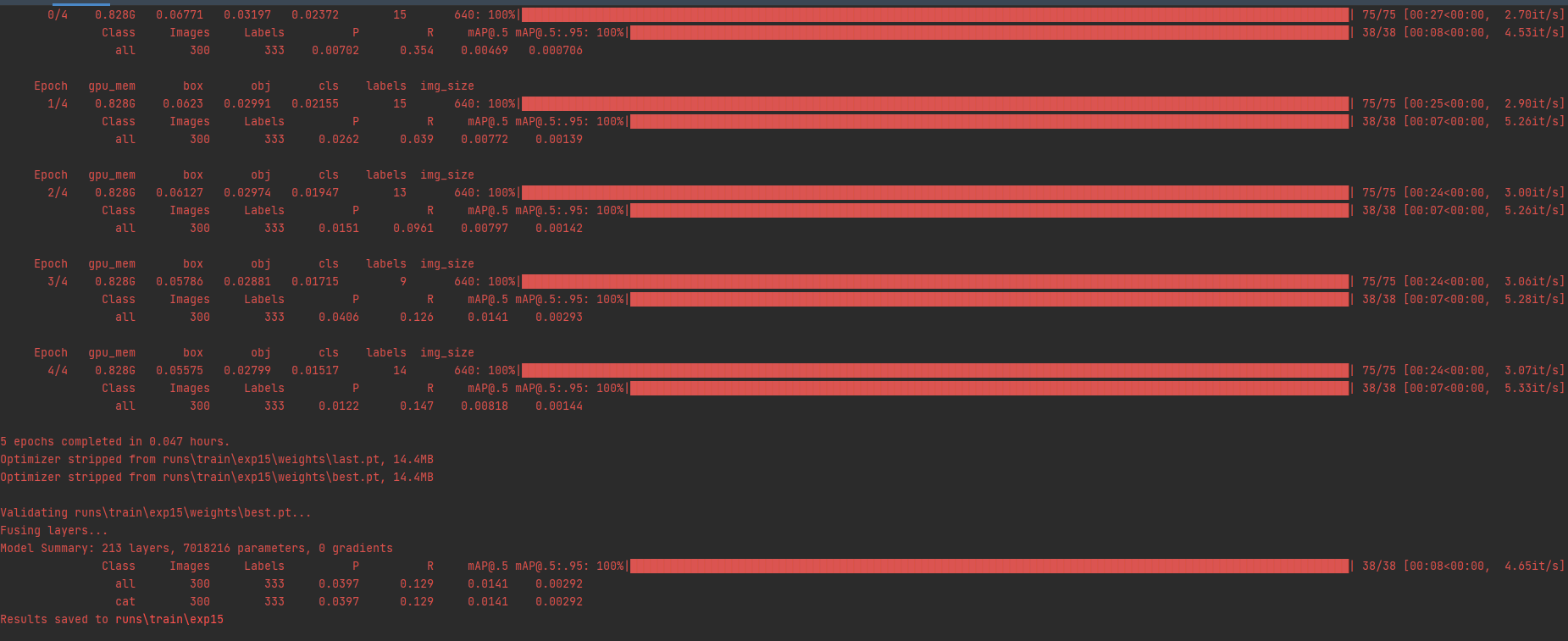
未报错得到的是这个。以上即为我训练的步骤和方法。
Original: https://blog.csdn.net/xiaoyifeishuang1/article/details/121266541
Author: tiwolf_li
Title: yolov5训练自己的数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/680371/
转载文章受原作者版权保护。转载请注明原作者出处!