

系列文章持续更新中…
文章目录
- 前言
- 一、相关性分析
* - A.获取股票价格
– - B. 合并股票价格
- C.股票价格相关性分析
- 二、假设检验
- 三、方差分析
* - A.单因素方差分析
- B.双因素方差分析
- C.第三方模块快速通关方差分析
- 小结
前言
通过几篇学习笔记我们学习了Python数据分析必备的NumPy模块和pandas模块,这篇我们就来实战演练各种数据分析问题。
需要写的东西比较多,所以我们分为上下两篇来学习。
—————————————————————————————————
一、相关性分析
相关性分析的定义:
对多个可能具备相关关系的变量进行分析,得到衡量变量间的相关程度或密切程度。
A.获取股票价格
列表数据的含义:
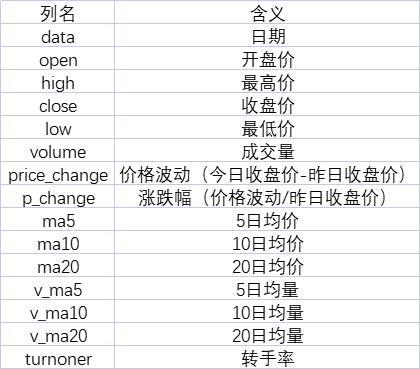

; a.获取日K线的股票价格
Tushare模块中的get_hist_data()函数可以获取日K线级别的股票价格。
eg:
import tushare as ts
import pandas as pd
pd.set_option(‘display.max_columns’,None)#强制显示所有列
data = ts.get_hist_data(‘000001′,start=’2022-01-01′,end=’2022-02-8’)#股票代码、起止实时间
print(data.head(10))#输出前10行数据运行结果:
open high close low volume price_change p_change
date
2022-02-08 16.30 16.97 16.83 16.26 1754695.38 0.44 2.69
2022-02-07 16.02 16.41 16.39 15.89 1515476.38 0.56 3.54
2022-01-28 16.39 16.45 15.83 15.82 1675563.62 -0.47 -2.88
2022-01-27 16.50 16.54 16.30 16.25 1024643.12 -0.35 -2.10
2022-01-26 16.95 17.10 16.65 16.54 984975.19 -0.20 -1.19
2022-01-25 17.08 17.08 16.85 16.81 1093284.00 -0.35 -2.04
2022-01-24 17.34 17.38 17.20 16.98 874770.88 -0.15 -0.86
2022-01-21 17.45 17.56 17.35 17.21 1481682.88 0.02 0.12
2022-01-20 16.47 17.46 17.33 16.42 3031194.00 0.83 5.03
2022-01-19 16.54 16.69 16.50 16.36 988391.81 -0.02 -0.12
ma5 ma10 ma20 v_ma5 v_ma10 v_ma20
date
2022-02-08 16.400 16.723 16.818 1391070.74 1442467.73 1396215.49
2022-02-07 16.404 16.692 16.809 1258788.46 1382295.63 1366943.69
2022-01-28 16.566 16.675 16.814 1130647.36 1345116.94 1378707.93
2022-01-27 16.870 16.725 16.863 1091871.21 1387870.08 1334762.93
2022-01-26 17.076 16.793 16.886 1493181.39 1376348.03 1356999.46
2022-01-25 17.046 16.828 16.912 1493864.71 1428066.86 1364082.65
2022-01-24 16.980 16.884 16.930 1505802.79 1476938.40 1345974.40
2022-01-21 16.784 16.883 16.936 1559586.51 1480438.71 1326648.42
2022-01-20 16.580 16.868 16.934 1683868.94 1444933.49 1305543.07
2022-01-19 16.510 16.847 16.937 1259514.66 1252602.62 1202829.76
turnover
date
2022-02-08 0.90
2022-02-07 0.78
2022-01-28 0.86
2022-01-27 0.53
2022-01-26 0.51
2022-01-25 0.56
2022-01-24 0.45
2022-01-21 0.76
2022-01-20 1.56
2022-01-19 0.51
b.获取每分钟的股票价格
Tushare模块中的get_hist_data()函数可以获取每分钟的股票价格。
eg:
import tushare as ts
import pandas as pd
pd.set_option(‘display.max_columns’,None)#强制显示所有列
data = ts.get_hist_data(‘000001′,ktype=’5’)#股票代码、,参数ktype表示获取数据类型
print(data.head(10))#输出前10行数据运行结果:
open high close low volume price_change
date
2022-02-08 15:00:00 16.85 16.85 16.83 16.82 13038.70 -0.02
2022-02-08 14:55:00 16.84 16.85 16.85 16.83 25472.80 0.01
2022-02-08 14:50:00 16.85 16.85 16.85 16.83 24344.30 0.00
2022-02-08 14:45:00 16.84 16.85 16.85 16.83 22600.00 0.01
2022-02-08 14:40:00 16.83 16.84 16.84 16.82 19424.80 0.01
2022-02-08 14:35:00 16.83 16.84 16.83 16.81 14400.30 0.00
2022-02-08 14:30:00 16.80 16.83 16.83 16.78 11253.90 0.03
2022-02-08 14:25:00 16.78 16.82 16.80 16.76 18803.40 0.02
2022-02-08 14:20:00 16.78 16.79 16.79 16.77 7604.48 0.01
2022-02-08 14:15:00 16.75 16.78 16.78 16.75 9000.16 0.03
p_change ma5 ma10 ma20 v_ma5 v_ma10
date
2022-02-08 15:00:00 -0.12 16.844 16.825 16.7780 20976.10 16594.3
2022-02-08 14:55:00 0.06 16.844 16.817 16.7730 21248.40 16206.6
2022-02-08 14:50:00 0.00 16.840 16.804 16.7665 18404.70 14575.6
2022-02-08 14:45:00 0.06 16.830 16.791 16.7585 17296.50 12996.0
2022-02-08 14:40:00 0.06 16.818 16.779 16.7485 14297.40 11828.6
2022-02-08 14:35:00 0.00 16.806 16.771 16.7430 12212.40 11657.8
2022-02-08 14:30:00 0.18 16.790 16.764 16.7380 11164.80 11610.3
2022-02-08 14:25:00 0.12 16.768 16.750 16.7350 10746.60 12020.8
2022-02-08 14:20:00 0.06 16.752 16.739 16.7355 8695.46 11758.2
2022-02-08 14:15:00 0.18 16.740 16.734 16.7395 9359.78 12418.5
v_ma20 turnover
date
2022-02-08 15:00:00 14808.2 0.01
2022-02-08 14:55:00 14540.9 0.01
2022-02-08 14:50:00 14087.3 0.01
2022-02-08 14:45:00 13623.2 0.01
2022-02-08 14:40:00 13734.9 0.01
2022-02-08 14:35:00 13357.0 0.01
2022-02-08 14:30:00 14343.8 0.01
2022-02-08 14:25:00 14930.2 0.01
2022-02-08 14:20:00 14922.2 0.00
2022-02-08 14:15:00 15639.8 0.01
B. 合并股票价格
eg:
import tushare as ts#导入模块
import pandas as pd#导入模块
data = ts.get_hist_data(‘0010001′,start=’2020-12-01’,end= ‘2022-02-10’)
data.to_excel(‘000001.xlsx’)#获取定期数据并保存到Excel文档
data1 = ts.get_hist_data(‘000002′,start=’2020-12-01’,end= ‘2022-02-10’)
data.to_excel(‘000002.xlsx’)#获取定期数据并保存到Excel文档
stock = pd.read_excel(‘000001.xlsx’)
stock = stock[[‘date’,’close’]]#选取000001.xlsx中date和close数据
stock = stock.rename(columns= {‘close’: ‘price_000001’})#重命名为price_000001
stock1 = pd.read_excel(‘000002.xlsx’)
stock1 = stock1[[‘date’,’close’]]#选取000002.xlsx中date和close数据
stock1 = stock1.rename(columns= {‘close’: ‘price_000002′})#重命名为price_000002
data_merge = pd.merge(stock,stock1,on=’date’,how=’inner’)#将更改列名后的数据合并写入到一个Excel中
data_merge.to_excel(‘合并.xlsx’,index=False)运行结果:(截图展示部分数据)
; C.股票价格相关性分析
这里我们先引入皮尔逊相关系数的概念。
皮尔逊相关系数:是一个用来反映两个随机变量之间的线性相关性程度的统计指标。eg:
import pandas as pd
from scipy.stats import pearsonr#导入模块
data = pd.read_excel(r’F:\合并.xlsx’)
corr = pearsonr(data[‘price_000001’],data[‘price_000002’])
print(‘相关系数r为’+str(corr[0])+’,显著性水平P值为’+str(corr[1]))运行结果:
相关系数r为0.9999999999999999,显著性水平P值为0.0

二、假设检验
实际工作中常用的有t检验、z检验和F检验。
这里我们演示一下t检验,导入SciPy模块,再调用双样本t检验的ttest_ind()函数检验A和B是否有显著性差异。
示例文档:
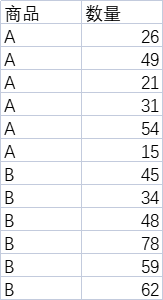
eg:
import pandas as pd
from scipy.stats import ttest_ind
data = pd.read_excel(r’F:\样本数据.xlsx’)
x = data[data[‘商品’] == ‘A’][‘数量’]#赋值变量x和y
y = data[data[‘商品’] == ‘B’][‘数量’]
print(ttest_ind(x,y))运行结果:
Ttest_indResult(statistic=-2.423080146952377, pvalue=0.03587218675038365)
pvalue是显著性水平P值,根据实际情况的确定置信度,若P值>1-置信度则有显著性差异。
; 三、方差分析
这里会用到一些统计学知识,如果想学习更多相关知识可以自行百度。
传送门:百度词条——方差分析
方差分析的基本步骤:
1)提出假设
2)计算均值
3)计算误差平方和
4)计算统计量
5)做出统计决策
A.单因素方差分析
H0:不同商品的销量没有显著差异。
H1:不同商品的销量有显著差异。
h0:不同月份的销量没有显著差异。
h1:不同月份的销量有显著差异。
代码:
import pandas as pd
def ONE_WAY_ANOVA(data):
col_mean = data.mean()
print(‘各水平的样本均值为’)
for index, value in col_mean.items():
print(index, str(value))#计算各水平的样本均值
data_mean = col_mean.mean()#计算所有样本的总均值
print(‘所有样本的总均值为’ + str(data_mean))
a = data.shape#计算样本数
n = data.shape[0]
m = data.shape[1]
nm = data.shape[0] * data.shape[1]
print(‘数据的行列数为’ + str(a))
print(‘试验次数为’ + str(n))
print(‘因素水平个数为’ + str(m))
print(‘总样本数为’ + str(nm))
SST = ((data – data_mean) 2).sum().sum()#计算总误差平方和、组间误差平方和和组内误差平方和
SSA = ((col_mean – data_mean) 2 * n).sum()
SSE = ((data – col_mean) ** 2).sum().sum()
print(‘总误差平方和SST为’ + str(SST))
print(‘组间误差平方和SSA为’ + str(SSA))
print(‘组内误差平方和SSE为’ + str(SSE))
MSA = SSA / (m – 1) #计算统计量
MSE = SSE / (nm – m)
F = MSA / MSE
print(‘组间均方MSA为’ + str(MSA))
print(‘组内均方MSE为’ + str(MSE))
print(‘统计量F值为’ + str(F))
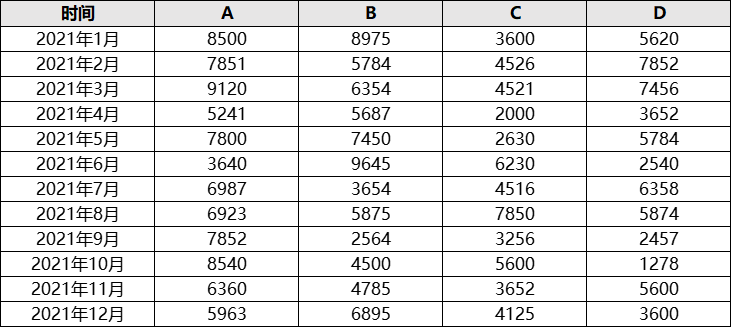
data_city = pd.read_excel(r’F:\销量统计.xlsx’, index_col=’时间’)
print(data_city.head())
ONE_WAY_ANOVA(data_city)
data_month = data_city.T
print(data_month.head())
ONE_WAY_ANOVA(data_month)运行结果:
A B C D
时间
2021年1月 8500 8975 3600 5620
2021年2月 7851 5784 4526 7852
2021年3月 9120 6354 4521 7456
2021年4月 5241 5687 2000 3652
2021年5月 7800 7450 2630 5784
各水平的样本均值为
A 7064.75
B 6014.0
C 4375.5
D 4839.25
所有样本的总均值为5573.375
数据的行列数为(12, 4)
试验次数为12
因素水平个数为4
总样本数为48
总误差平方和SST为202272915.25
组间误差平方和SSA为52706325.75
组内误差平方和SSE为149566589.5
组间均方MSA为17568775.25
组内均方MSE为3399240.6704545454
统计量F值为5.168441117660171
时间 2021年1月 2021年2月 2021年3月 2021年4月 … 2021年9月 2021年10月 2021年11月 2021年12月
A 8500 7851 9120 5241 … 7852 8540 6360 5963
B 8975 5784 6354 5687 … 2564 4500 4785 6895
C 3600 4526 4521 2000 … 3256 5600 3652 4125
D 5620 7852 7456 3652 … 2457 1278 5600 3600
[4 rows x 12 columns]
各水平的样本均值为
2021年1月 6673.75
2021年2月 6503.25
2021年3月 6862.75
2021年4月 4145.0
2021年5月 5916.0
2021年6月 5513.75
2021年7月 5378.75
2021年8月 6630.5
2021年9月 4032.25
2021年10月 4979.5
2021年11月 5099.25
2021年12月 5145.75
所有样本的总均值为5573.375
数据的行列数为(4, 12)
试验次数为4
因素水平个数为12
总样本数为48
总误差平方和SST为202272915.25
组间误差平方和SSA为40759945.25
组内误差平方和SSE为161512970.0
组间均方MSA为3705449.5681818184
组内均方MSE为4486471.388888889
统计量F值为0.8259162372814113
统计决策:
统计量F值≈5.168
SSA的自由度为m-1=4-1=3
SSE的自由度为n×m-m=48-4=44
假设此检验是在显著性水平a=0.05的基础上进行的
在F值检验临界值表中查得自由度为(3,44)时临界值为2.816
可得假设H1成立。
同理,可得假设h0成立。
B.双因素方差分析
示例文档:
对行因素提出假设:
H0:不同商品的销量没有显著差异。
H1:不同商品的销量有显著差异。
对列因素提出假设:
h0:不同月份的销量没有显著差异。
h1:不同月份的销量有显著差异。
代码:
import pandas as pd
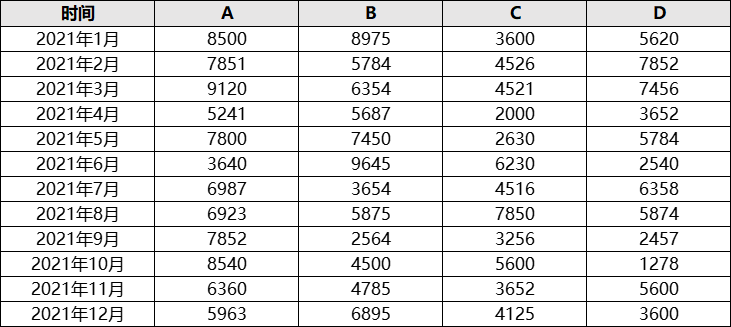
data = pd.read_excel(r’F:\销量统计.xlsx’, index_col=’时间’)
col_mean = data.mean()#计算均值
print(‘各商品的样本均值为’)
for index, value in col_mean.items():
print(index, str(value))
row_mean = data.T.mean()
print(‘各时间的样本均值为’)
for index, value in row_mean.items():
print(index, str(value))
data_mean = col_mean.mean()
print(‘所有样本的总均值为’ + str(data_mean))
n = data.shape[0]#计算样本数
m = data.shape[1]
SST = ((data – data_mean) 2).sum().sum()#计算误差平方和
SSR = ((row_mean – data_mean) 2 * m).sum()
SSC = ((col_mean – data_mean) ** 2 * n).sum()
SSE = SST – SSR – SSC
print(‘总误差平方和SST为’ + str(SST))
print(‘行因素的误差平方和SSR为’ + str(SSR))
print(‘列因素的误差平方和SSC为’ + str(SSC))
print(‘随机误差平方和SSE为’ + str(SSE))
MSR = SSR / (n – 1)#计算统计量
MSC = SSC / (m – 1)
MSE = SSE / ((n – 1) * (m – 1))
FR = MSR / MSE
FC = MSC / MSE
print(‘行因素的均方MSR为’ + str(MSR))
print(‘列因素的均方MSC为’ + str(MSC))
print(‘随机误差项的均方MSE为’ + str(MSE))
print(‘行因素的统计量FR值为’ + str(FR))
print(‘列因素的统计量FC值为’ + str(FC))运行结果:
各商品的样本均值为
A 7064.75
B 6014.0
C 4375.5
D 4839.25
各时间的样本均值为
2021年1月 6673.75
2021年2月 6503.25
2021年3月 6862.75
2021年4月 4145.0
2021年5月 5916.0
2021年6月 5513.75
2021年7月 5378.75
2021年8月 6630.5
2021年9月 4032.25
2021年10月 4979.5
2021年11月 5099.25
2021年12月 5145.75
所有样本的总均值为5573.375
总误差平方和SST为202272915.25
行因素的误差平方和SSR为40759945.25
列因素的误差平方和SSC为52706325.75
随机误差平方和SSE为108806644.25
行因素的均方MSR为3705449.5681818184
列因素的均方MSC为17568775.25
随机误差项的均方MSE为3297171.037878788
行因素的统计量FR值为1.1238269187775267
列因素的统计量FC值为5.328439152280905
统计决策:
行因素的统计量FR值为1.124
列因素的统计量FC值为5.328
SSR的自由度为m-1=12-1=11
SSC的自由度为m-1=4-1=3
SSE的自由度为(n-1)×(m-1)=33
假设此检验是在显著性水平a=0.05的基础上进行的
在F值检验临界值表中查得:
自由度为(11,33)时Fa1临界值为2.093
自由度为(3,33)时临界值Fa2为2.892
可得对行假设H1成立,对列h0成立。
; C.第三方模块快速通关方差分析
除了完全按照方差分析的基本步骤编写程序,还可以利用第三方模块快速通关方差分析。
下面以satatsmodels模块为例。
示例文档:
H0:不同商品的销量没有显著差异。
H1:不同商品的销量有显著差异。
h0:不同月份的销量没有显著差异。
h1:不同月份的销量有显著差异。
代码:
import pandas as pd
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
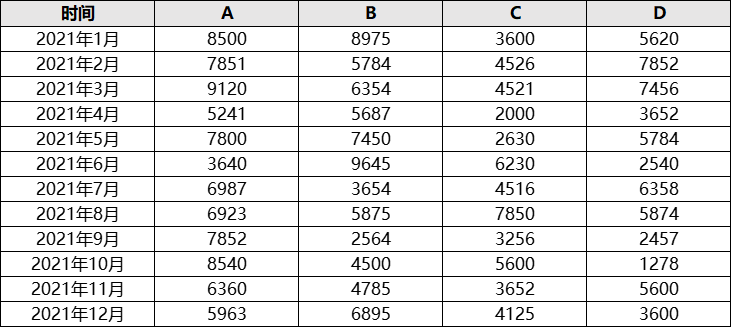
data = pd.read_excel(r’F:\销量统计.xlsx’, index_col=’时间’)#读取数据
df_city = data.melt(var_name=’商品’, value_name=’销量’)#商品因素的单因素方差分析
model_city = ols(‘销量~C(商品)’, df_city).fit()
anova_table = anova_lm(model_city)
print(anova_table)
df_month = data.T.melt(var_name=’时间’, value_name=’销量’)#时间因素的单因素方差分析
model_month = ols(‘销量~C(时间)’, df_month).fit()
anova_table = anova_lm(model_month)
print(anova_table)
df_twoway = data.stack().reset_index()#城市和月份因素的双因素方差分析
df_twoway.columns = [‘时间’, ‘商品’, ‘销量’]
model_twoway = ols(‘销量~C(时间) + C(商品)’, df_twoway).fit()
anova_table = anova_lm(model_twoway)
print(anova_table)运行结果:
df sum_sq mean_sq F PR(>F)
C(商品) 3.0 5.270633e+07 1.756878e+07 5.168441 0.003796
Residual 44.0 1.495666e+08 3.399241e+06 NaN NaN
df sum_sq mean_sq F PR(>F)
C(时间) 11.0 4.075995e+07 3.705450e+06 0.825916 0.615648
Residual 36.0 1.615130e+08 4.486471e+06 NaN NaN
df sum_sq mean_sq F PR(>F)
C(时间) 11.0 4.075995e+07 3.705450e+06 1.123827 0.374878
C(商品) 3.0 5.270633e+07 1.756878e+07 5.328439 0.004176
Residual 33.0 1.088066e+08 3.297171e+06 NaN NaN
决策:
时间因素的P值 0.374878>0.05
商品因素的P值 0.004176
小结
上篇我们进行了相关性分析、假设检验、方差分析,下篇我们来学习一下描述性统计分析和线性回归分析。
此系列文,仅记录鄙人python学习路程的一个片段,参考价值可能不大,写的不好请多多谅解,欢迎大佬们评论留言,指正鄙人的不足之处。(感激不尽!!!)
最后,
生活于生活之上,便知晓百花和万物沉默的思想。不管怎样,记得好好吃饭。
Original: https://blog.csdn.net/qq_46257360/article/details/122803503
Author: 槃星Panxing
Title: Python学习笔记(五.数据分析 ——上)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/599694/
转载文章受原作者版权保护。转载请注明原作者出处!