

目录
一、引语
最近想用YOLO训练一个行人检测的模型,找到了CUHK Occlusion Datase 这个数据集,但这个数据集想要用YOLO训练的话,涉及到Seq文件转JPEG和VBB文件转XML,花了一下午时间在网上查资料,整理了一下供大家参考,参考文章链接在文末。
二、准备工作
1.首先新建⼀个set00⽂件夹,将所有.seq⽂件都放进去;


3.在Annotations⽂件夹中同样新建⼀个set00⽂件夹,将所有.vbb⽂件放⼊,如下:

三、Seq文件转JPEG
-*- coding:utf-8 -*-
import os.path
import fnmatch
import shutil
def open_save(file, savepath):
# 读入一个seq文件,然后拆分成image存入savepath当中
f = open(file, 'rb')
# 将seq文件的内容转化成str类型
string = f.read().decode('latin-1')
# splitstring是图片的前缀,可以理解成seq是以splitstring为分隔的多个jpg合成的文件
splitstring = "\xFF\xD8\xFF\xE0\x00\x10\x4A\x46\x49\x46"
# split函数做一个测试,因此返回结果的第一个是在seq文件中是空,因此后面省略掉第一个
"""
>>> a = ".12121.3223.4343"
>>> a.split('.')
['', '12121', '3223', '4343']
"""
strlist = string.split(splitstring)
# print(strlist)
# print('######################################')
f.close()
count = 0
# delete the image folder path if it exists
if os.path.exists(savepath):
shutil.rmtree(savepath)
# create the image folder path
if not os.path.exists(savepath):
os.makedirs(savepath)
# 遍历每一个jpg文件内容,然后加上前缀合成图片
for img in strlist:
filename = str(count) + '.jpg'
filenamewithpath = os.path.join(savepath, filename)
if count > 0:
i = open(filenamewithpath, 'wb+')
i.write(splitstring.encode('latin-1'))
i.write(img.encode('latin-1'))
i.close()
count = count + 1
if __name__ == "__main__":
rootdir = "D:/BaiduNetdiskDownload/行人检测/46_CUHK Occlusion Dataset"
saveroot = "C:/Users/杨鑫兴/Desktop/VOCdevkit/JPEG"
for parent, dirnames, filenames in os.walk(rootdir):
for filename in filenames:
if fnmatch.fnmatch(filename, '*.seq'):
thefilename = os.path.join(parent, filename)
thesavepath = saveroot + '/' + parent.split('/')[-1] + '/' + filename.split('.')[0] + '/'
print("Filename=" + thefilename)
print("Savepath=" + thesavepath)
open_save(thefilename, thesavepath)
这里只需要修改两个路径

rootdir是你刚刚新建的set00和 Annotations所在的文件夹路径
saveroot是你存放转好的JPEG的位置(自己创建一个文件夹存放即可)
效果如图:
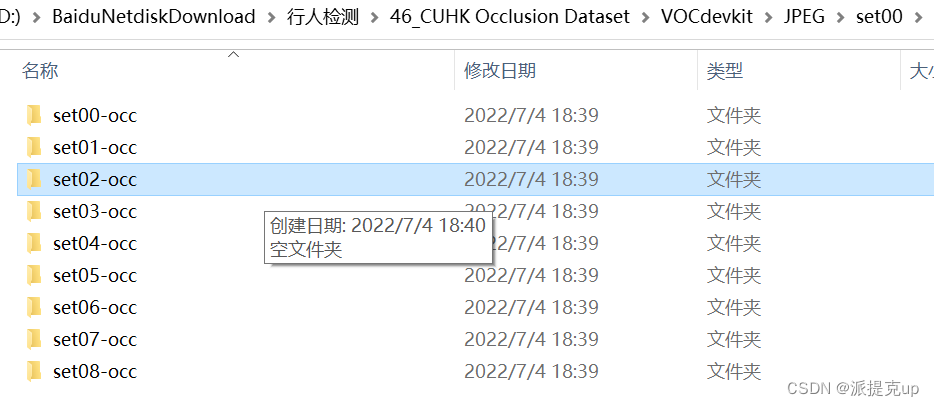
四、VBB转XML
-*- coding:utf-8 -*-
import os, glob
import cv2
from scipy.io import loadmat
from collections import defaultdict
import numpy as np
from lxml import etree,objectify
def vbb_anno2dict(vbb_file, cam_id):
# 通过os.path.basename获得路径的最后部分"文件名.扩展名"
# 通过os.path.splitext获得文件名
filename = os.path.splitext(os.path.basename(vbb_file))[0]
# 定义字典对象annos
annos = defaultdict(dict)
vbb = loadmat(vbb_file)
# object info in each frame: id, pos, occlusion, lock, posv
objLists = vbb['A'][0][0][1][0]
objLbl = [str(v[0]) for v in vbb['A'][0][0][4][0]] # 可查看所有类别
# person index
person_index_list = np.where(np.array(objLbl) == "person")[0] # 只选取类别为'person'的xml
for frame_id, obj in enumerate(objLists):
if len(obj) > 0:
frame_name = str(cam_id) + "_" + str(filename) + "_" + str(frame_id + 1) + ".jpg"
annos[frame_name] = defaultdict(list)
annos[frame_name]["id"] = frame_name
annos[frame_name]["label"] = "person"
for id, pos, occl in zip(obj['id'][0], obj['pos'][0], obj['occl'][0]):
id = int(id[0][0]) - 1 # for matlab start from 1 not 0
if not id in person_index_list: # only use bbox whose label is person
continue
pos = pos[0].tolist()
occl = int(occl[0][0])
annos[frame_name]["occlusion"].append(occl)
annos[frame_name]["bbox"].append(pos)
if not annos[frame_name]["bbox"]:
del annos[frame_name]
print(annos)
return annos
def seq2img(annos, seq_file, outdir, cam_id):
cap = cv2.VideoCapture(seq_file)
index = 1
# captured frame list
v_id = os.path.splitext(os.path.basename(seq_file))[0]
cap_frames_index = np.sort([int(os.path.splitext(id)[0].split("_")[2]) for id in annos.keys()])
while True:
ret, frame = cap.read()
print(ret)
if ret:
if not index in cap_frames_index:
index += 1
continue
if not os.path.exists(outdir):
os.makedirs(outdir)
outname = os.path.join(outdir, str(cam_id) + "_" + v_id + "_" + str(index) + ".jpg")
print("Current frame: ", v_id, str(index))
cv2.imwrite(outname, frame)
height, width, _ = frame.shape
else:
break
index += 1
img_size = (width, height)
return img_size
def instance2xml_base(anno, bbox_type='xyxy'):
"""bbox_type: xyxy (xmin, ymin, xmax, ymax); xywh (xmin, ymin, width, height)"""
assert bbox_type in ['xyxy', 'xywh']
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder('VOC2014_instance/person'),
E.filename(anno['id']),
E.source(
E.database('Caltech pedestrian'),
E.annotation('Caltech pedestrian'),
E.image('Caltech pedestrian'),
E.url('None')
),
E.size(
E.width(640),
E.height(480),
E.depth(3)
),
E.segmented(0),
)
for index, bbox in enumerate(anno['bbox']):
bbox = [float(x) for x in bbox]
if bbox_type == 'xyxy':
xmin, ymin, w, h = bbox
xmax = xmin + w
ymax = ymin + h
else:
xmin, ymin, xmax, ymax = bbox
E = objectify.ElementMaker(annotate=False)
anno_tree.append(
E.object(
E.name(anno['label']),
E.bndbox(
E.xmin(xmin),
E.ymin(ymin),
E.xmax(xmax),
E.ymax(ymax)
),
E.difficult(0),
E.occlusion(anno["occlusion"][index])
)
)
return anno_tree
def parse_anno_file(vbb_inputdir, vbb_outputdir):
# annotation sub-directories in hda annotation input directory
assert os.path.exists(vbb_inputdir)
sub_dirs = os.listdir(vbb_inputdir) # 对应set00,set01...
for sub_dir in sub_dirs:
print("Parsing annotations of camera: ", sub_dir)
cam_id = sub_dir
# 获取某一个子set下面的所有vbb文件
vbb_files = glob.glob(os.path.join(vbb_inputdir, sub_dir, "*.vbb"))
for vbb_file in vbb_files:
# 返回一个vbb文件中所有的帧的标注结果
annos = vbb_anno2dict(vbb_file, cam_id)
if annos:
# 组成xml文件的存储文件夹,形如"/Users/chenguanghao/Desktop/Caltech/xmlresult/"
vbb_outdir = vbb_outputdir
# 如果不存在
if not os.path.exists(vbb_outdir):
os.makedirs(vbb_outdir)
for filename, anno in sorted(annos.items(), key=lambda x: x[0]):
if "bbox" in anno:
anno_tree = instance2xml_base(anno)
outfile = os.path.join(vbb_outdir, os.path.splitext(filename)[0] + ".xml")
print("Generating annotation xml file of picture: ", filename)
# 生成最终的xml文件,对应一张图片
etree.ElementTree(anno_tree).write(outfile, pretty_print=True)
def visualize_bbox(xml_file, img_file):
import cv2
tree = etree.parse(xml_file)
# load image
image = cv2.imread(img_file)
origin = cv2.imread(img_file)
# 获取一张图片的所有bbox
for bbox in tree.xpath('//bndbox'):
coord = []
for corner in bbox.getchildren():
coord.append(int(float(corner.text)))
print(coord)
cv2.rectangle(image, (coord[0], coord[1]), (coord[2], coord[3]), (0, 0, 255), 2)
# visualize image
cv2.imshow("test", image)
cv2.imshow('origin', origin)
cv2.waitKey(0)
def main():
vbb_inputdir = r"C:\Users\杨鑫兴\Desktop\Annotations"
vbb_outputdir = r"C:\Users\杨鑫兴\Desktop\VOCdevkit\Annotations"
parse_anno_file(vbb_inputdir, vbb_outputdir)
"""
下面这段是测试代码
"""
"""
xml_file = "/Users/chenguanghao/Desktop/Caltech/xmlresult/set07/bbox/set07_V000_4.xml"
img_file = "/Users/chenguanghao/Desktop/Caltech/JPEG/set07/V000/4.jpg"
visualize_bbox(xml_file, img_file)
"""
if __name__ == "__main__":
main()
这里只需要改两个路径

vbb_inputdir是你开始时解压label压缩包时创建的Annotations文件夹路径
vbb_outputdir是存放转好的XML数据文件夹的路径(自己创建一个即可)
效果如图:
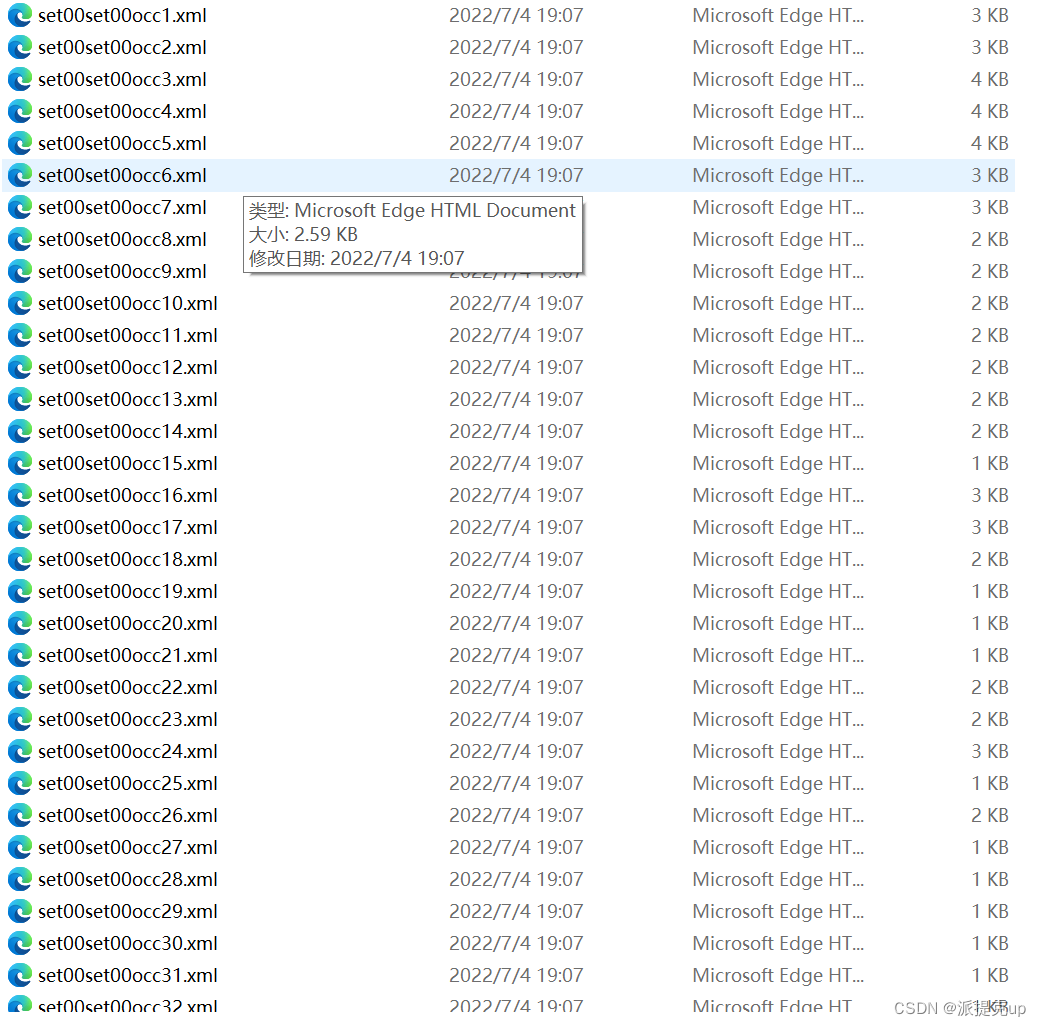
五、把刚刚照片与xml一一对应
import ntpath
import os
import glob
import shutil
imgpathin=r'C:\Users\杨鑫兴\Desktop\VOCdevkit\JPEG'
imgout=r'C:\Users\杨鑫兴\Desktop\VOCdevkit\JPEGlmages'
for subdir in os.listdir(imgpathin):
print(subdir)
file_path=os.path.join(imgpathin,subdir)
for subdir1 in os.listdir(file_path):
print(subdir1)
file_path1=os.path.join(file_path,subdir1)
for jpg_file in os.listdir(file_path1):
src=os.path.join(file_path1,jpg_file)
new_name=str(subdir+"_"+subdir1+"_"+jpg_file)
dst=os.path.join(imgout,new_name)
os.rename(src,dst)
同样这里也需要修改两个路径

imgpathin是你刚刚存放JPEG文件夹的路径
imgout是存放修改后图片文件夹的路径(创建一个即可)
效果如下:
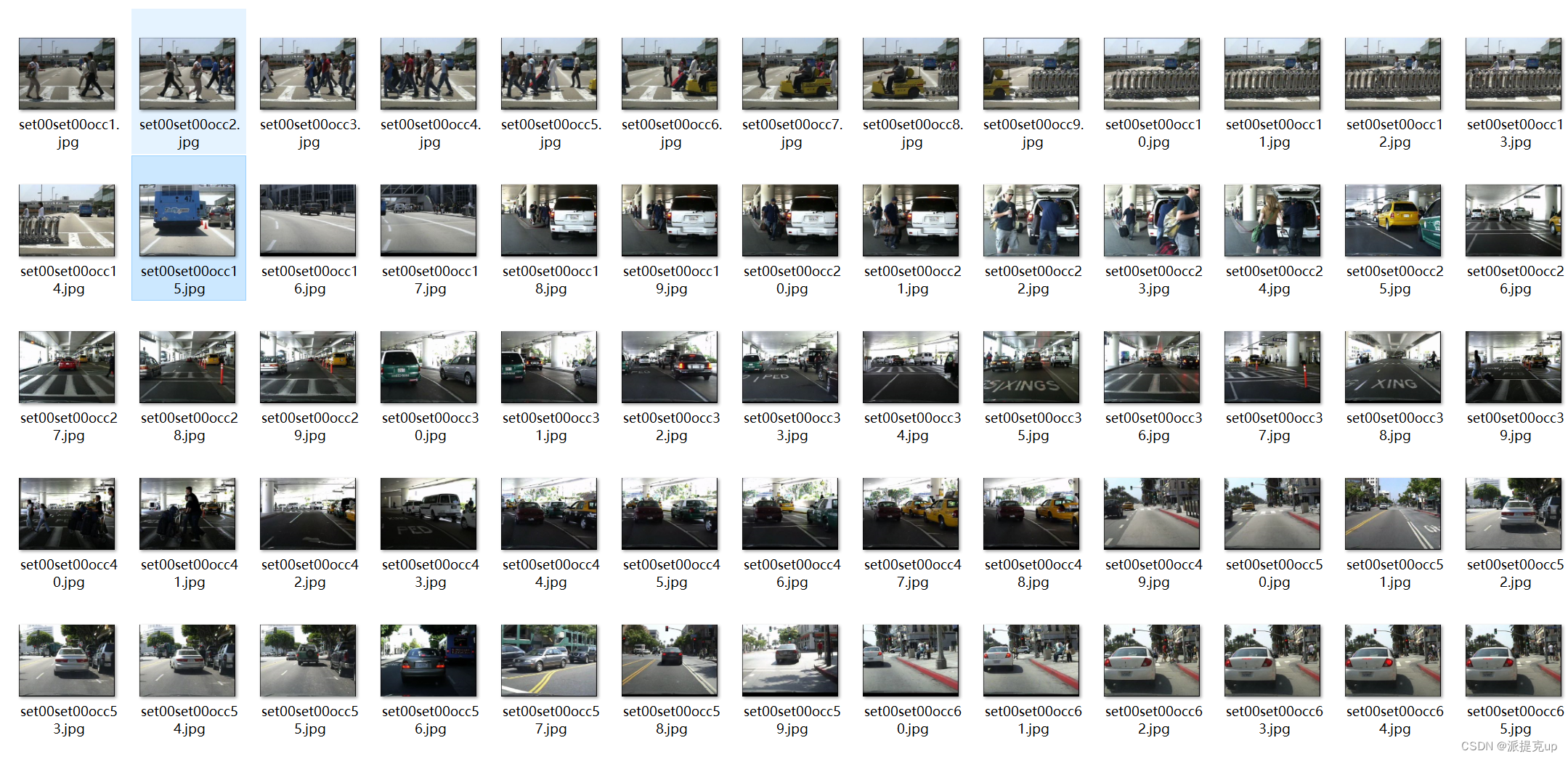
六、VOC数据集制作
七、结语
这篇文章我没有什么技术上的创新,我做的只是把自己花时间查的资料整合了一下,希望可以帮到大家,至于数据集,我查资料的时候发现作者把网盘链接删了,不知道什么原因,需要的私信或者留言我,最后感谢这些参考博客的作者👇
VOC数据集具体格式_北漠苍狼1746430162的博客-CSDN博客
CUHKOcclusionDataset数据集转换为yolo格式,并划分测试集和训练集 – 百度文库 (baidu.com)
(写的比较详细,大家可以看一下,对我帮助很大,唯一的缺点就是代码没有办法复制(百度文库嘛))
Original: https://blog.csdn.net/weixin_55504804/article/details/125608701
Author: 派提克up
Title: CUHK Occlusion Dataset(行人检测数据集)转换为YOLO+VOC数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/680361/
转载文章受原作者版权保护。转载请注明原作者出处!