

推荐系统是当今业界最具影响力的 ML 任务。从淘宝到抖音,科技公司都在不断尝试为他们的特定应用程序构建更好的推荐系统。而这项任务并没有变得更容易,因为我们每天都希望看到更多可供选择的项目。所以我们的模型不仅必须做出最优推荐,而且还必须高效地做出推荐。今天介绍的这个模型被称作:Light Graph Convolution Network 或 LightGCN¹。
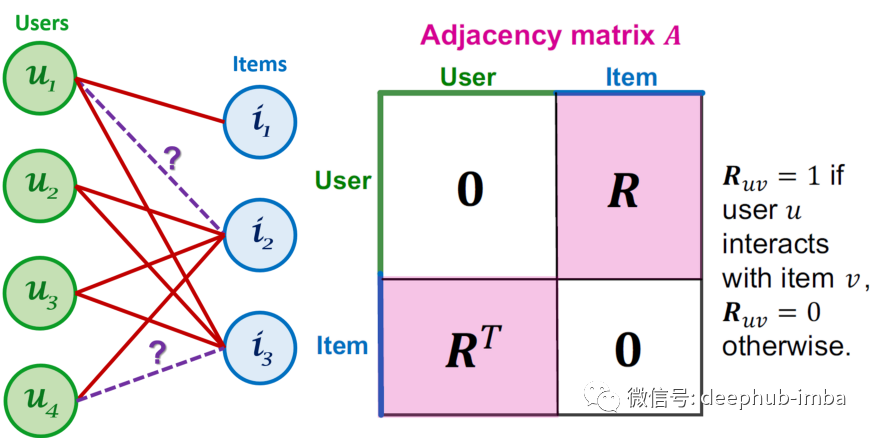

让我们将用户和项目想象成二分图中的节点,其中用户与已经选择的项目相连。所以寻找最佳推荐项目的问题就变成了链接预测问题。
; 示例数据集
作为一个实际示例,我们所说的用户是搜索音乐艺术家(”项目”)的音乐听众。原始数据集可在 ³ 获得。
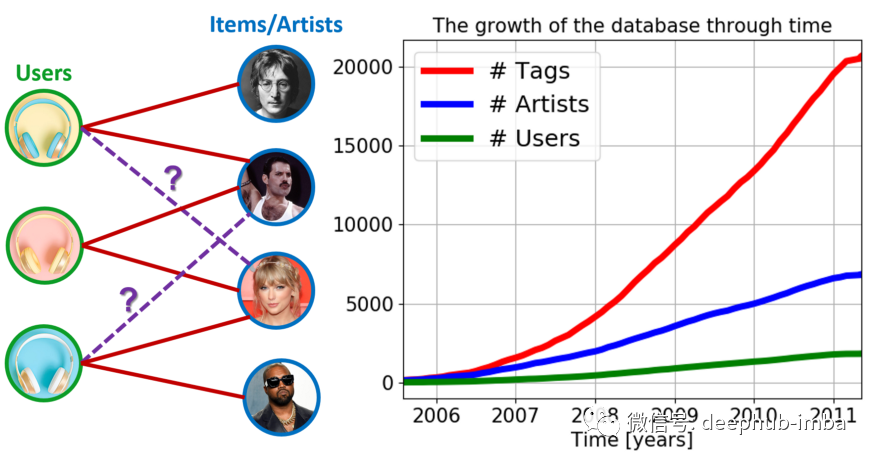
该数据集包含 1824 位用户、6854 位艺术家和 20,664 个标签。一个普通艺术家与大约 3 个用户相关联,而一个普通用户与大约 11 个艺术家相关联,因为在这个特定数据集中,艺术家的数量大大超过了用户。这个数据集的一个特点是可以看到每个新连接的创建时间,这对我们来说非常的重要,因为可以通过连接时间将数据分成训练集(最早时间)和测试集(最新时间)³。我们的目标是想要创建一个推荐系统模型来预测未来形成的新标签/连接。
基于嵌入的模型
LightGCN 是一个基于嵌入的模型,这意味着它试图为用户和项目找到最佳嵌入(向量)。除此以外,它还在寻找最优评分函数 f,这个函数为新的用户-项目进行评分,分数高的则会被推荐。
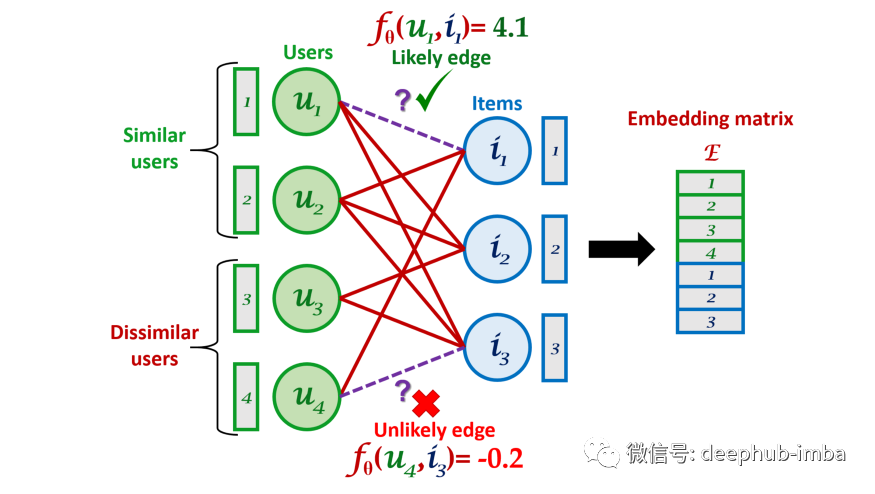
对于嵌入向量,具有相似偏好的用户的嵌入会相似,而偏好不同的用户的嵌入会更加不同。
在继续研究 lightGCN 之前,首先简单介绍一下的基于嵌入的模型,矩阵分解法在传统的推荐系统中已被应用多年,并且效果一直都很好,所以它将作为我们的基线模型:
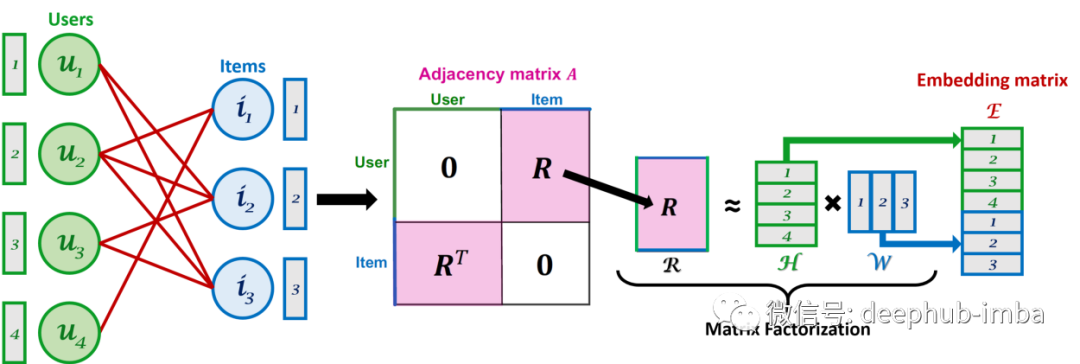
上图是矩阵分解(MF)过程与原始图以及嵌入矩阵²的关系。
这里我们将矩阵分解模型作为基线与 LightGCN 模型进行比较。这里的评分函数 f 只是两个嵌入和模型通过最小化矩阵 (R – HW) 的 Frobenious 范数来训练的标量积,其中矩阵 R 是用户-项目邻接矩阵,而矩阵 H 包含用户嵌入,W 包含项目嵌入²。评分函数 f 在 lightGCN 的情况下是一样的,但是为了直观地理解模型,首先要考虑 lightGCN 模型的性能优化目标是什么。
; 但是如何衡量性能呢?
一种流行的性能度量是从测试集中获取所有实际的新用户边并计算考虑模型的前 K 个预测(意味着具有最高分数 f(用户,项目))。这个分数是为每个用户计算的,然后对所有用户的分数进行平均以获得最终分数,称为 Recall @ K²。
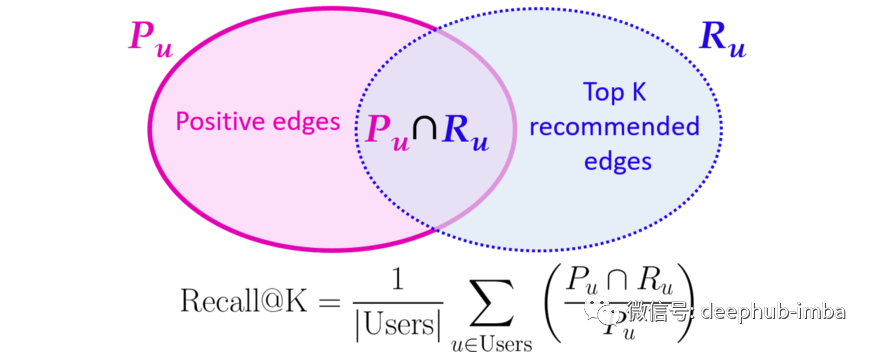
但是Recall@K度量是不可微的,这意味着需要设计一个可微的损失函,这样lightGCN模型的训练才能利用梯度找到最优值。
设计这个损失函数的最主要的目标是:未来正边的计分函数结果是一个较大的数字,而未来负边的计分函数结果是一个较小的数字²。所以结合这两个问题的一个比较好的方法是:希望用户u的给定未来正边和用户u的给定未来负边之间的差值是一个较大的数字:
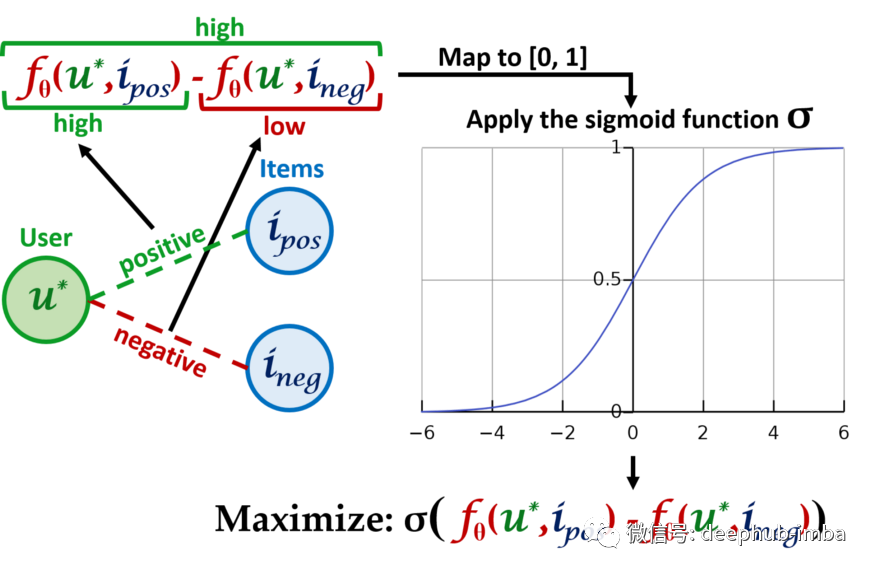
在使用 sigmoid 函数将两个分数的差异映射到区间 [0, 1]后,就能够将分数视为概率。因此对于一个给定用户u,可以将给定的所有正边和负边对的分数组合起来输入损失函数中。然后在所有用户中平均这些损失²以获得最终的损失,这称为贝叶斯个性化排名 (Bayesian Personalized Ranking BPR) 损失:

LightGCN
下面进入本文的正题,虽然矩阵分解方法仅捕获图的一阶边连接结构(仅来自给定节点的直接邻居的信息),但我们希望模型能够捕获更高阶的图结构。所以使用 LightGCN 来做这件事,它从用矩阵分解初始化的节点嵌入开始训练:
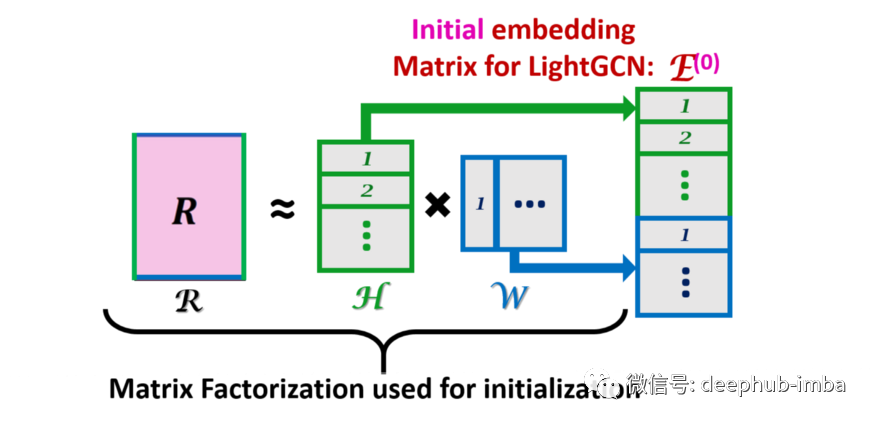
嵌入初始化后, LightGCN 使用 3 层来完成嵌入的训练,在每一层中,每个节点通过组合其邻居的嵌入来获得新的嵌入。这可以被认为是一种图卷积(参见下面与图像卷积的比较):
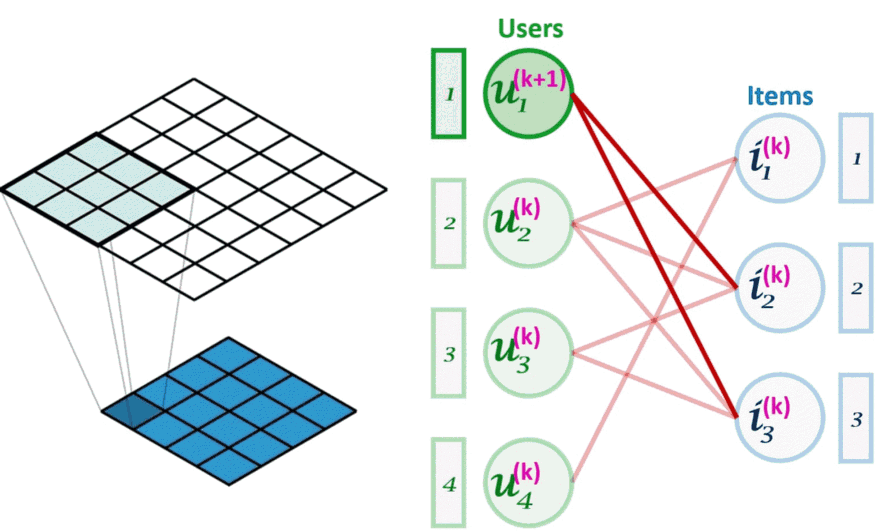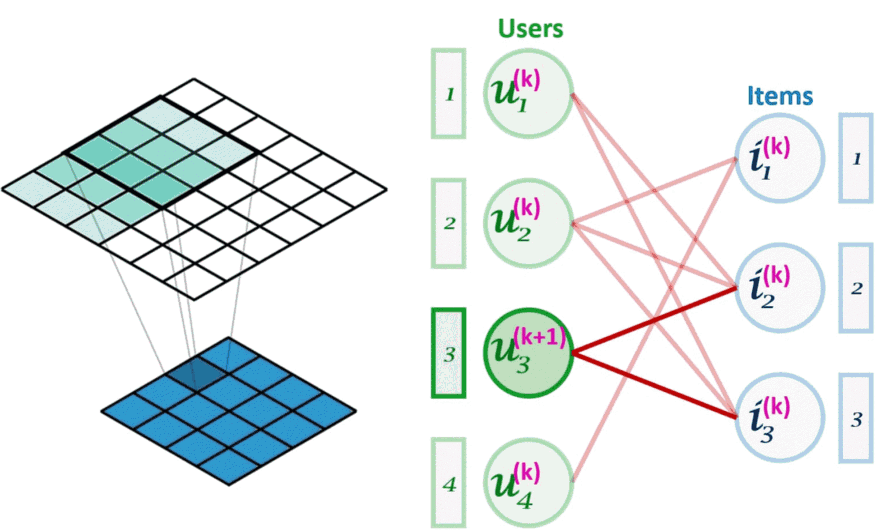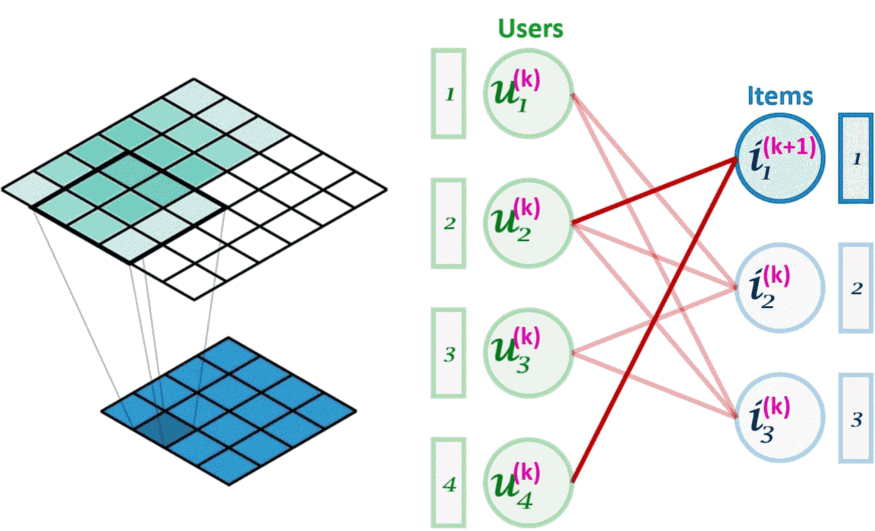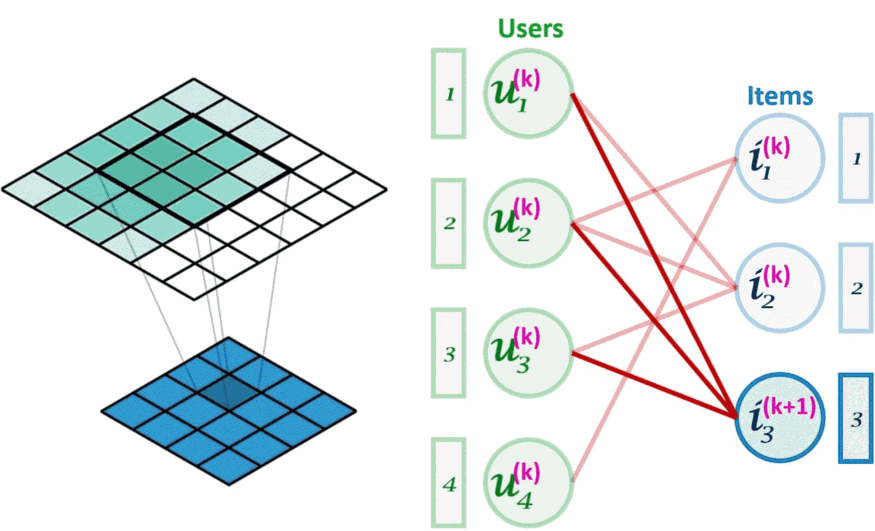
图像卷积(左)可以看作是图卷积(右)的一个特例。图卷积是一种节点置换不变的操作。
上图所示,与卷积层类似堆叠更多层意味着来自给定节点的信息能够获得离该节点更远的节点的信息,这样可以根据需要捕获更高阶的图结构。但是在每次迭代 k 中,嵌入究竟是如何组合成一个新的嵌入的呢?下面举两个例子:
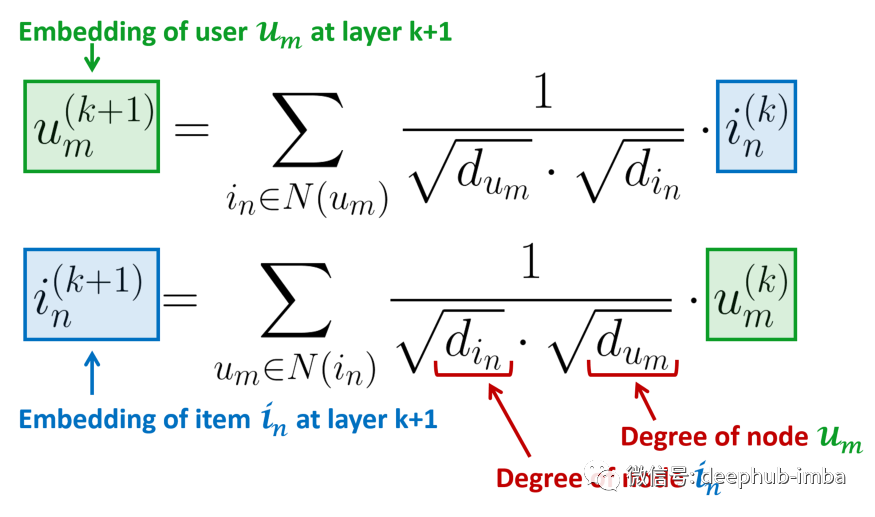
上图为相邻项目嵌入对用户嵌入下一层的影响,反之亦然¹。初始嵌入的影响随着每次迭代而减小,因为它能够到达远离原点的更多节点。这就是所说的正在扩散嵌入,这种特殊的扩散方式还可以通过构建扩散矩阵进行矢量化并加速该过程:
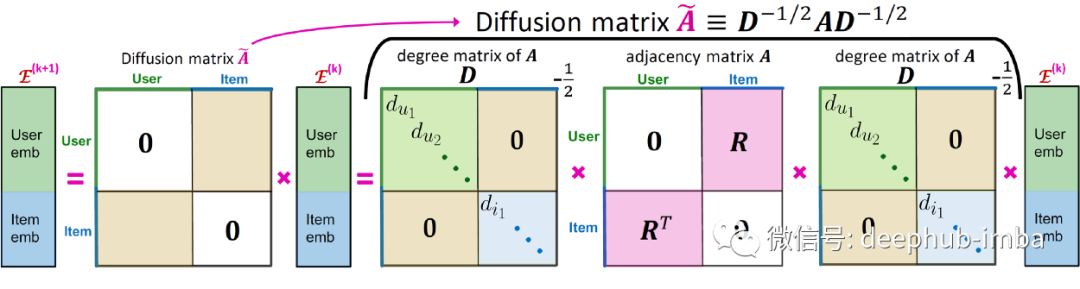
从度矩阵和邻接矩阵²构建扩散矩阵。
由于扩散矩阵是从度矩阵D和邻接矩阵A计算出来的,所以扩散矩阵只需要计算一次并且不包含可学习的参数。模型中唯一可学习的参数是在浅输入节点嵌入,将其与扩散矩阵 K 次相乘以得到 (K + 1) 个嵌入,然后对其进行平均以获得最终嵌入:
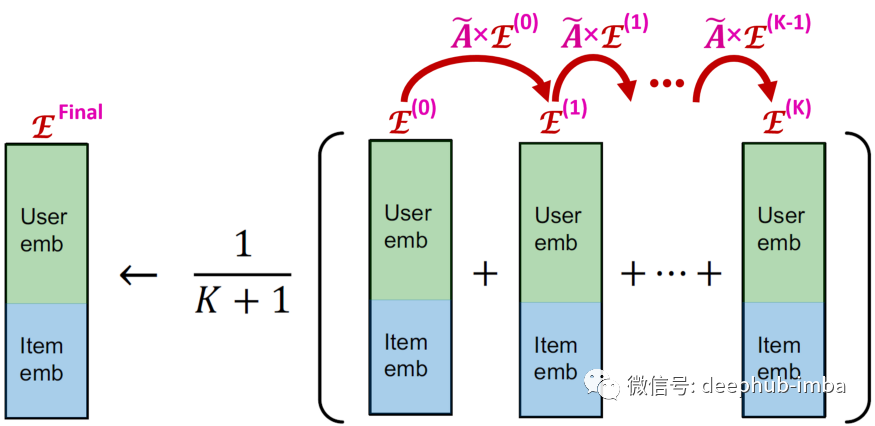
现在我们了解了模型如何向前传播输入嵌入,这样就可以使用 PyTorch Geometric 对模型进行编码,然后使用上面提到的BPR损失来优化项目和用户的嵌入。PyG (PyTorch Geometric) 是一个基于 PyTorch 构建的库,可帮助我们编写和训练图形神经网络 (GNN)。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch_scatter
from torch_geometric.nn.conv import MessagePassing
class LightGCNStack(torch.nn.Module):
def __init__(self, latent_dim, args):
super(LightGCNStack, self).__init__()
conv_model = LightGCN
self.convs = nn.ModuleList()
self.convs.append(conv_model(latent_dim))
assert (args.num_layers >= 1), 'Number of layers is not >=1'
for l in range(args.num_layers-1):
self.convs.append(conv_model(latent_dim))
self.latent_dim = latent_dim
self.num_layers = args.num_layers
self.dataset = None
self.embeddings_users = None
self.embeddings_artists = None
def reset_parameters(self):
self.embeddings.reset_parameters()
def init_data(self, dataset):
self.dataset = dataset
self.embeddings_users = torch.nn.Embedding(num_embeddings=dataset.num_users, embedding_dim=self.latent_dim).to('cuda')
self.embeddings_artists = torch.nn.Embedding(num_embeddings=dataset.num_artists, embedding_dim=self.latent_dim).to('cuda')
def forward(self):
x_users, x_artists, batch = self.embeddings_users.weight, self.embeddings_artists.weight, \
self.dataset.batch
final_embeddings_users = torch.zeros(size=x_users.size(), device='cuda')
final_embeddings_artists = torch.zeros(size=x_artists.size(), device='cuda')
final_embeddings_users = final_embeddings_users + x_users/(self.num_layers + 1)
final_embeddings_artists = final_embeddings_artists + x_artists/(self.num_layers+1)
for i in range(self.num_layers):
x_users = self.convs[i]((x_artists, x_users), self.dataset.edge_index_a2u, size=(self.dataset.num_artists, self.dataset.num_users))
x_artists = self.convs[i]((x_users, x_artists), self.dataset.edge_index_u2a, size=(self.dataset.num_users, self.dataset.num_artists))
final_embeddings_users = final_embeddings_users + x_users/(self.num_layers+1)
final_embeddings_artists = final_embeddings_artists + x_artists/(self.num_layers + 1)
return final_embeddings_users, final_embeddings_artists
def decode(self, z1, z2, pos_edge_index, neg_edge_index): # only pos and neg edges
edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=-1) # concatenate pos and neg edges
logits = (z1[edge_index[0]] * z2[edge_index[1]]).sum(dim=-1) # dot product
return logits
def decode_all(self, z_users, z_artists):
prob_adj = z_users @ z_artists.t() # get adj NxN
#return (prob_adj > 0).nonzero(as_tuple=False).t() # get predicted edge_list
return prob_adj
def BPRLoss(self, prob_adj, real_adj, edge_index):
loss = 0
pos_scores = prob_adj[edge_index.cpu().numpy()]
for pos_score, node_index in zip(pos_scores, edge_index[0]):
neg_scores = prob_adj[node_index, real_adj[node_index] == 0]
loss = loss - torch.sum(torch.log(torch.sigmoid(pos_score.repeat(neg_scores.size()[0]) - neg_scores))) / \
neg_scores.size()[0]
return loss / edge_index.size()[1]
def topN(self, user_id, n):
z_users, z_artists = self.forward()
scores = torch.squeeze(z_users[user_id] @ z_artists.t())
return torch.topk(scores, k=n)
class LightGCN(MessagePassing):
def __init__(self, latent_dim, **kwargs):
super(LightGCN, self).__init__(node_dim=0, **kwargs)
self.latent_dim = latent_dim
def forward(self, x, edge_index, size=None):
return self.propagate(edge_index=edge_index, x=(x[0], x[1]), size=size)
def message(self, x_j):
return x_j
def aggregate(self, inputs, index, dim_size=None):
return torch_scatter.scatter(src=inputs, index=index, dim=0, dim_size=dim_size, reduce='mean')
使用 LightGCN 进行预测
PyTorch Geometric 还提供了训练的函数可以帮助我们简化训练过程。在完成训练后,嵌入表示现在已经可以表示用户可能会喜欢相似的项目并具有相似的偏好。所以可以通过模型返回的最终嵌入来计算新的项目分数来预测每个用户对尚未看到的项目的偏好。对于每个用户推荐 K 个得分最高的项目(对用户来说是新的)。就像矩阵分解一样,评分函数 f 只是嵌入的标量积,通过矩阵乘法有效计算:
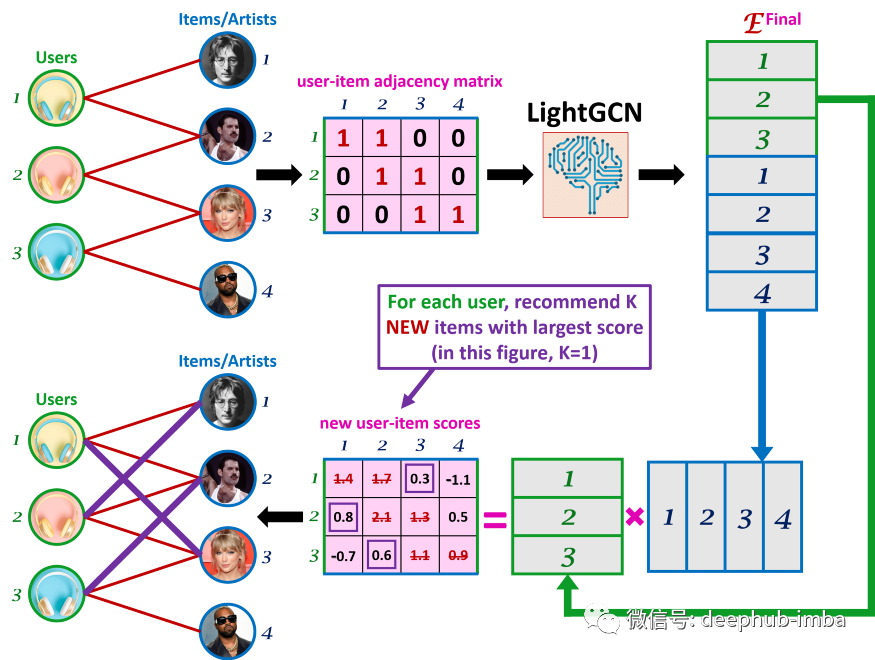
测试集还包含新用户,这些新用户未出现在训练集中。所以在这种情况下,我们只是推荐项目在训练集中存在的所有组合用户中都很受欢迎前 K 个项目。
from functools import partial
import get_pyg_data
from model import LightGCNStack
import torch
from src.data_preprocessing import TrainTestGenerator
from src.evaluator import Evaluator
from train_test import train, test
from torch_geometric.utils import train_test_split_edges
import time
import pandas as pd
class objectview(object):
def __init__(self, *args, **kwargs):
d = dict(*args, **kwargs)
self.__dict__ = d
Wrapper for evaluation
class LightGCN_recommender:
def __init__(self, args):
self.args = objectview(args)
self.model = LightGCNStack(latent_dim=64, args=self.args).to('cuda')
self.a_rev_dict = None
self.u_rev_dict = None
self.a_dict = None
self.u_dict = None
def fit(self, data: pd.DataFrame):
# Default rankings when userID is not in training set
self.default_recommendation = data["artistID"].value_counts().index.tolist()
# LightGCN
data, self.u_rev_dict, self.a_rev_dict, self.u_dict, self.a_dict = get_pyg_data.load_data(data)
data = data.to("cuda")
self.model.init_data(data)
self.optimizer = torch.optim.Adam(params=self.model.parameters(), lr=0.001)
best_val_perf = test_perf = 0
for epoch in range(1, self.args.epochs+1):
start = time.time()
train_loss = train(self.model, data, self.optimizer)
val_perf, tmp_test_perf = test(self.model, (data, data))
if val_perf > best_val_perf:
best_val_perf = val_perf
test_perf = tmp_test_perf
log = 'Epoch: {:03d}, Loss: {:.4f}, Val: {:.4f}, Test: {:.4f}, Elapsed time: {:.2f}'
print(log.format(epoch, train_loss, best_val_perf, test_perf, time.time()-start))
def recommend(self, user_id, n):
try:
recommendations = self.model.topN(self.u_dict[str(user_id)], n=n)
except KeyError:
recommendations = self.default_recommendation
else:
recommendations = recommendations.indices.cpu().tolist()
recommendations = list(map(lambda x: self.a_rev_dict[x], recommendations))
return recommendations
def evaluate(args):
data_dir = "../data/"
data_generator = TrainTestGenerator(data_dir)
evaluator = Evaluator(partial(LightGCN_recommender, args), data_generator)
evaluator.evaluate()
evaluator.save_results('../results/lightgcn.csv', '../results/lightgcn_time.csv')
print('Recall:')
print(evaluator.get_recalls())
print('MRR:')
print(evaluator.get_mrr())
if __name__=='__main__':
# best_val_perf = test_perf = 0
# data = get_pyg_data.load_data()
#data = train_test_split_edges(data)
args = {'model_type': 'LightGCN', 'num_layers': 3, 'batch_size': 32, 'hidden_dim': 32,
'dropout': 0, 'epochs': 1000, 'opt': 'adam', 'opt_scheduler': 'none', 'opt_restart': 0, 'weight_decay': 5e-3,
'lr': 0.1, 'lambda_reg': 1e-4}
evaluate(args)
结果对比
该模型在三年的三个测试集上运行:2008 年、2009 年和 2010 年。对于给定的测试集,训练数据由前几年建立的所有连接组成,例如,在2010年的测试集上测试的模型,是在之前所有年份(包括2008年和2009年)的训练集上进行训练的。但是在2008年的测试集上测试的模型,只对2007年及更早的数据进行了训练。
模型产生预测后使用前面介绍的 Recall @ K 对其进行评估。下面的第一个表格显示了以矩阵分解作为基线的结果,而下面的第二个表格显示了使用 LightGCN 获得的结果:
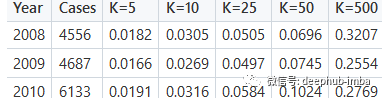
通过矩阵分解得到Recall@K分数
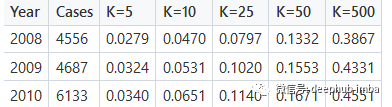
LightGCN的Recall@K分数
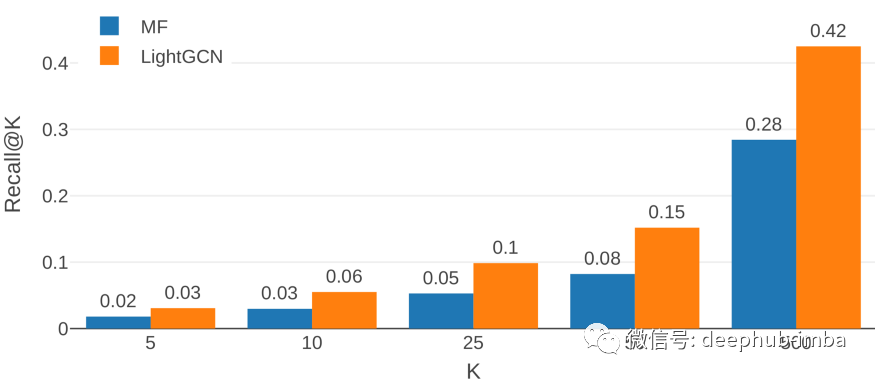
正如预期的那样召回率@K 随着 K 的增加而增加,并且该模型似乎在 2010 年的测试集上表现最好,可能是因为在这种情况下训练集的数据量是最大的。上面表都清楚地表明 LightGCN 在 Recall @ K 方面优于矩阵分解基线模型。下面的图显示了三年内平均的 Recall@K 值。
可以使用的另一个指标是平均倒数排名 (mean reciprocal rank MRR)。该指标试图更好地说明模型对预测连接的确定程度。它通过考虑所有实际正确的新连接 Q 来做到这一点。对于每一个连接,它都会检查有多少不正确的预测连接(误报),以便获得该连接的排名(可能的最小排名是1,因为我们还计算了正确的连接本身)。这些排名的倒数进行平均以获得 MRR:
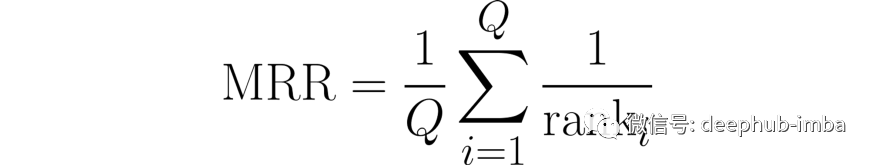
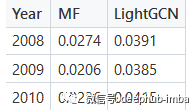
关于 MRR,我们可以再次清楚地看到 LightGCN 模型比矩阵分解模型表现更好,如下表所示:
但是与用于初始化其嵌入的矩阵分解模型相比,LightGCN 模型的训练时间要长得多。但是从名字中可以看出与其他图卷积神经网络相比,LightGCN 非常轻量级,这是因为 LightGCN 除了输入嵌入之外没有任何可学习的参数,这使得训练速度比用于推荐系统的其他基于 GCN 的模型快得多。
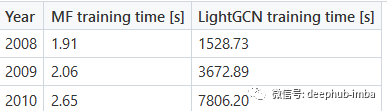
对于预测的时间,两个模型都需要几毫秒来生成预测,差距基本上可以忽略不计
引用
- Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 639–648, 2020. arXiv:2002.02126
- Visualizations taken from lecture given by Jure Leskovec, available at http://web.stanford.edu/class/cs224w/slides/13-recsys.pdf
-
Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2nd workshop on information heterogeneity and fusion in recommender systems (hetrec 2011). In Proceedings of the 5th ACM conference on Recommender systems, RecSys 2011, New York, NY, USA, 2011. ACM.
-
本文代码https://www.overfit.cn/post/4e217d5a562f40f9a5efc4a2b5300b09 (Authors: Ermin Omeragić, Tomaž Martičič, Jurij Nastran)
作者:jn2279
Original: https://blog.csdn.net/m0_46510245/article/details/123419110
Author: deephub
Title: 轻量级图卷积网络LightGCN介绍和构建推荐系统示例
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/699624/
转载文章受原作者版权保护。转载请注明原作者出处!