

文章目录
- 数据清洗
* - Pandas
- 数据结构:Series
– - 数据结构:DateFrame
–
数据清洗
Pandas
Pandas是一个强大的分析结构化数据的工具集,使用基础是Numpy,用于数据挖掘和数据分析
数据结构:Series
是一种类似于一维数组的对象,是由一组数据以及一组与之相关的数据标签组成,仅由一组数据也可产生简单的Series.
创建Series
- 导入Pandas包
import numpy as np
import pandas as pd
- 通过数组创建一个Series
Series([data, index, dtype, name, copy, ...])


创建一个带索引的Series:
import numpy as np
import pandas as pd
np.random.seed(1234)
arr1=np.random.randint(1,20,5)
index=["a","b","c","d","e"]
ser1=pd.Series(arr1,index)
print(ser1)
输出结果:左边是索引,右边是值

- 通过字典创造Series:
通过字典创造Series:
import numpy as np
import pandas as pd
drict1={"a":1,"b":2,"c":3}
ser1=pd.Series(drict1)
print(ser1)
输出结果:字典中自带索引

常用属性
- 索引:Series变量名.index
- 值:Series变量名.values
- 名字:Series变量名.name
- 更改名字:Series变量名.rename(“新名字”,inplace=Ture)
Series特性
数组特性
可以进行 索引和切片操作,与Ndarray非常相似,是大部分Ndarray函数的有效参数
索引与切片
import numpy as np
import pandas as pd
np.random.seed(1234)
arr1=np.random.randint(1,20,5)
index=["a","b","c","d","e"]
ser1=pd.Series(arr1,index)
print(ser1)
ser1[1];
print(ser1[1])
print(ser1[1:4])
print(ser1[[1,2,3]])
print(ser1[ser1>2])

字典特性
同时像一个固定大小的dict,可以通过索引标签获得和设置值
通过索引标签进行取值和切片
import numpy as np
import pandas as pd
np.random.seed(1234)
arr1=np.random.randint(1,20,5)
index=["a","b","c","d","e"]
ser1=pd.Series(arr1,index)
print(ser1)
print(ser1["a"])
print(ser1["a":"c"])
print(ser1[["a","c","e"]])
print(ser1.get("a","没有找到"))
print(ser1.get("k","没有找到"))
运行结果:

矢量化操作与标签对齐操作
import numpy as np
import pandas as pd
index=["a","b","c","d","e"]
ser1=pd.Series([1,2,3,4,5],index)
ser2=pd.Series([1,2,3,4,5],index)
print(ser1+ser2)
运行结果:对应索引上的值进行了相加且不用通过循环遍历每一个元素

数据结构:DateFrame
是Pandas中一个表格型的数据结构,包括一组有序的列,每列可以是不同的值类型,DateFrame即有行索引也有列索引,可以被看做是由Series组成的字典,即每一列都是一个Series.
创建DateFrame库
- 导入pandas:
import numpy as np
import pandas as pd
- 利用数组创建DataFrame:
pandas.DataFrame( data, index, columns, dtype, copy)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-scfAWy0i-1626953574415)(C:\Users\Kaiser\Desktop\学习笔记\图片存放\adas.png)] 其中index控制行标签,columns控制列表签
import numpy as np
import pandas as pd
arr1=np.random.randint(1,30,(3,7))
index=["a","b","c"]
column=["A","B","C","D","E","F","G"]
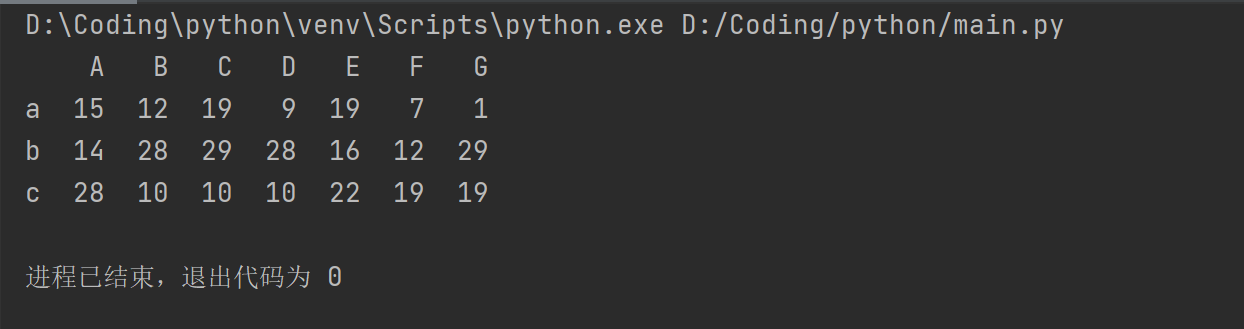
pad1=pd.DataFrame(arr1,index,column)
print(pad1)
运行结果:
3. 通过字典创建: 字典中的一行索引控制DateFrame的行索引,列索引控制DateFrame的列索引 注意:使用Series可以允许值为空的情况,不使用则不允许
import numpy as np
import pandas as pd
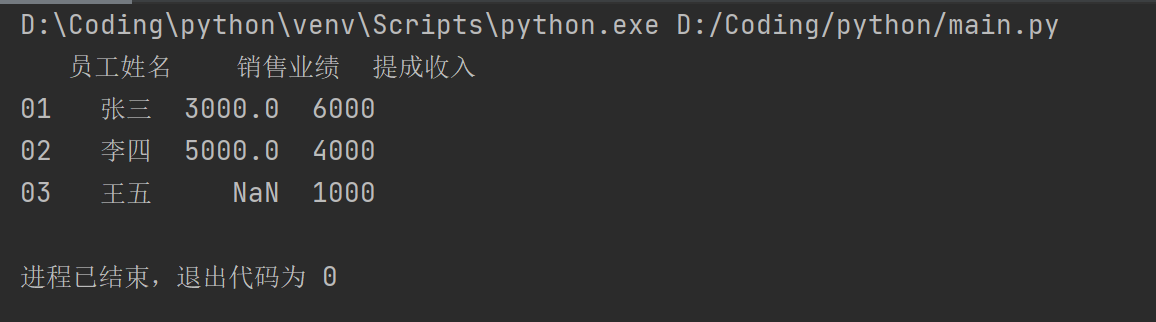
dirct1={"员工姓名":pd.Series(["张三","李四","王五"],index=["01","02","03"]),
"销售业绩":pd.Series([3000,5000],index=["01","02"]),
"提成收入":pd.Series([6000,4000,1000],index=["01","02","03"])
}
pad1=pd.DataFrame(dirct1)
print(pad1)
运行结果:
DataFrame的列操作
增加列
增加列的操作方式和字典类似
- 通过一个标量增加一整列
import numpy as np
import pandas as pd
dirct1={"员工姓名":pd.Series(["张三","李四","王五"],index=["01","02","03"]),
"销售业绩":pd.Series([3000,5000],index=["01","02"]),
"提成收入":pd.Series([6000,4000,1000],index=["01","02","03"])
}
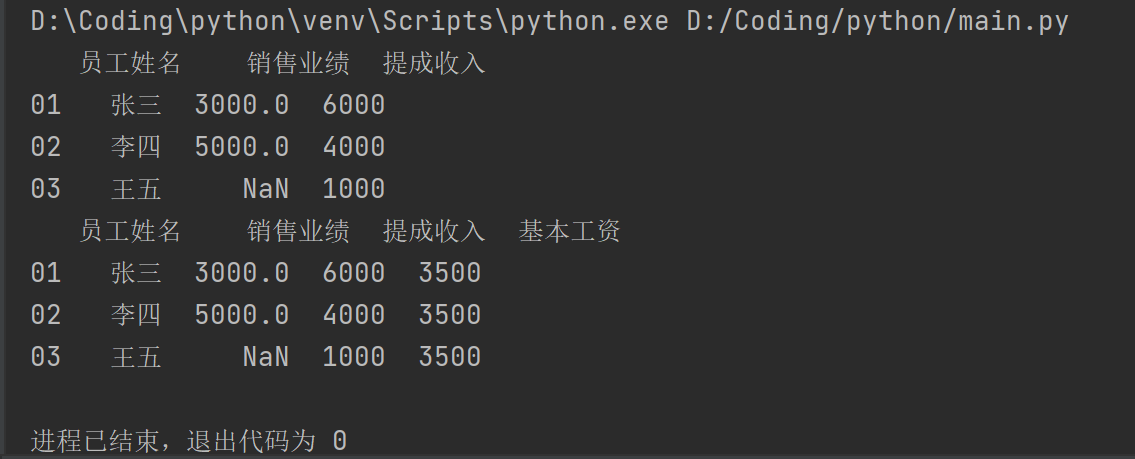
pad1=pd.DataFrame(dirct1)
print(pad1)
pad1["基本工资"]=3500
print(pad1)
运行结果:
2. 通过其他列的运算创造新的列
import numpy as np
import pandas as pd
dirct1={"员工姓名":pd.Series(["张三","李四","王五"],index=["01","02","03"]),
"销售业绩":pd.Series([3000,5000],index=["01","02"]),
"提成收入":pd.Series([6000,4000,1000],index=["01","02","03"])
}
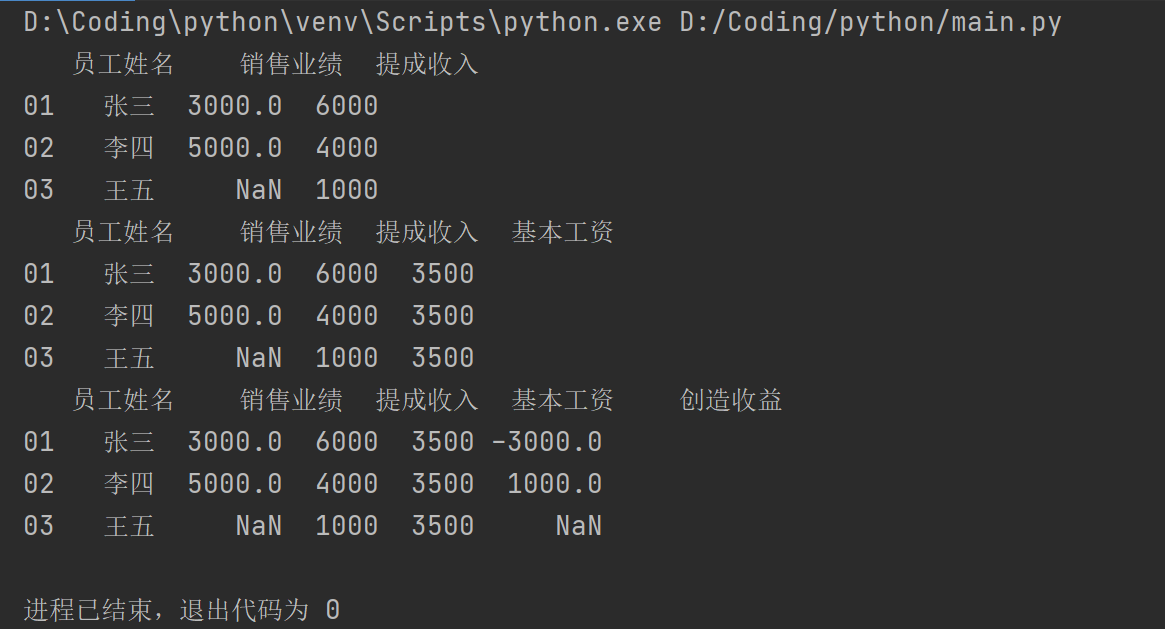
pad1=pd.DataFrame(dirct1)
print(pad1)
pad1["基本工资"]=3500
print(pad1)
pad1["创造收益"]=pad1["销售业绩"]-pad1["提成收入"]
print(pad1)
- 利用bool表达式创造列
pad1["是否达标"]=pad1["创造收益"]>=0
print(pad1)
- 利用Series与标签索引直接插入
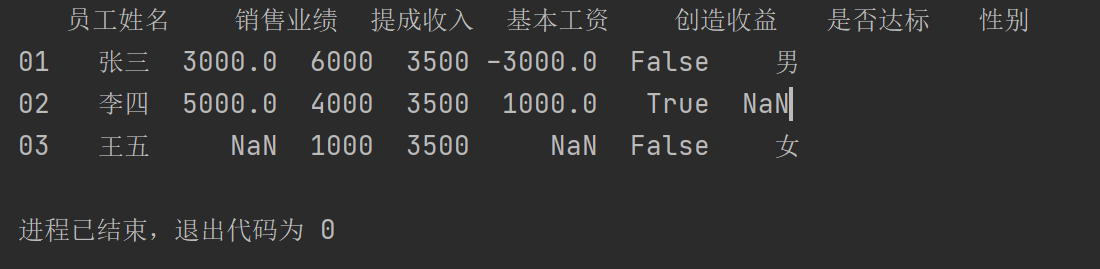
pad1["性别"]=pd.Series(["男","女"],index=["01","03"])
print(pad1)
运行结果:
3. 插入指定位置列
Dataframe.insert(loc, column, value, allow_duplicates=False)
Dataframe.insert(loc, column, value, allow_duplicates=False)
loc:int型,表示第几列;若在第一列插入数据,则 loc=0
column: 给插入的列取名,如 column=’新的一列’
value:数字,array,series等都可(可自己尝试)
allow_duplicates: 是否允许列名重复,选择Ture表示允许新的列名与已存在的列名重复。
pad1.insert(1,"年龄",pd.Series(["25","26","27"],index=["01","02","03"]))
print(pad1)

删除列
- Dataframe名.pop(“列名”)
- del Dateframe名[“列名”]
- Dataframe名.drop():既可以删列也可以删行,还可以实现多列的删除
Dataframe.drop([ ],axis=0,inplace=True)
drop([]),默认情况下删除某一行;如果要删除某列,需要axis=1; 参数inplace 默认情况下为False,表示保持原来的数据不变,True 则表示在原来的数据上改变 删除多列:
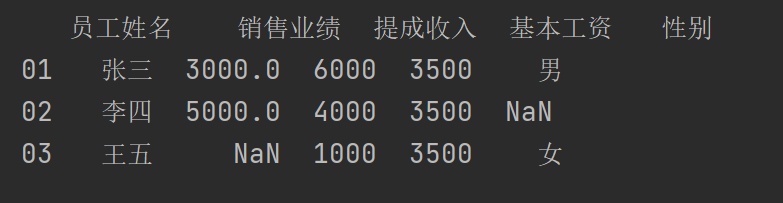
pad1.drop(columns=["创造收益","是否达标"],inplace=True)
print(pad1)
删除行:
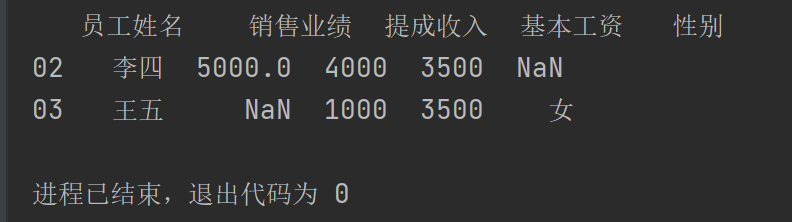
pad1.drop(index=["01"])
print(pad1.drop(index=["01"]))
运行结果:
DataFrame的索引和选择
基于标签
DataFrame名.loc[行索引信息,列索引信息]
如果之索引行信息,所有列信息都保留,索引语法中的列索引信息可以忽略
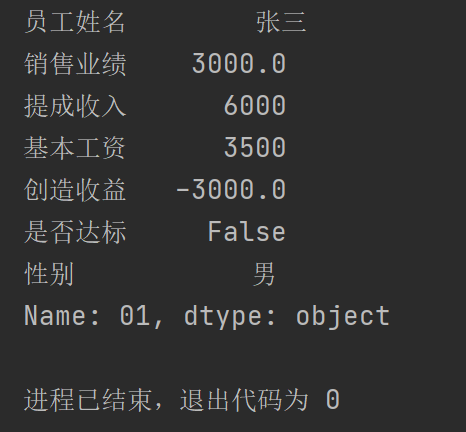
print(pad1.loc["01"])
运行结果:
如果只索引列信息,所有行信息都保留,索引语法中的行索引信息不可以被省略,写冒号加逗号表示所有行信息被保留
基于标签的切片:[start,end]即末尾的位置是可以切到的
print(pad1.loc["01":"02","员工姓名":"提成收入"])

通过loc基于标签的索引添加一行:
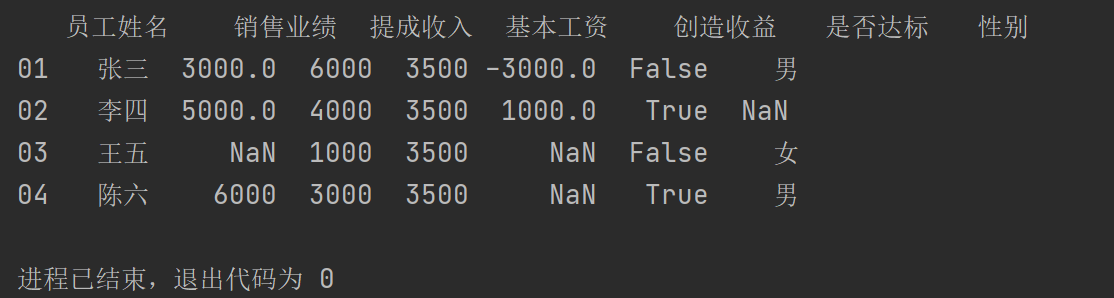
pad1.loc["04"]=["陈六","6000","3000","3500",np.nan,True,"男"]
print(pad1)
输出结果:
利用打包成一个列表选择性的选取列信息
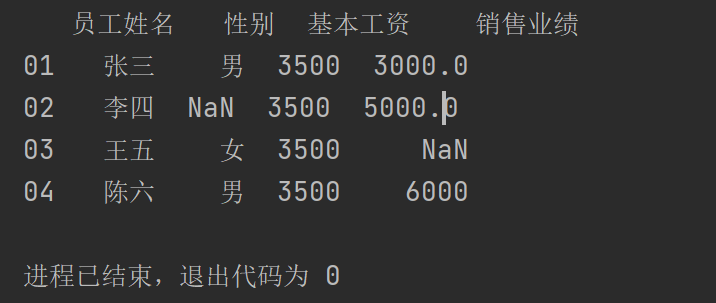
注意行信息需要用:来取,这是不可少的
pad1.loc[:,["员工姓名","性别","基本工资","销售业绩"]]
print(pad1.loc[:,["员工姓名","性别","基本工资","销售业绩"]])
基于位置
DataFrame名.iloc[行索引,列索引]
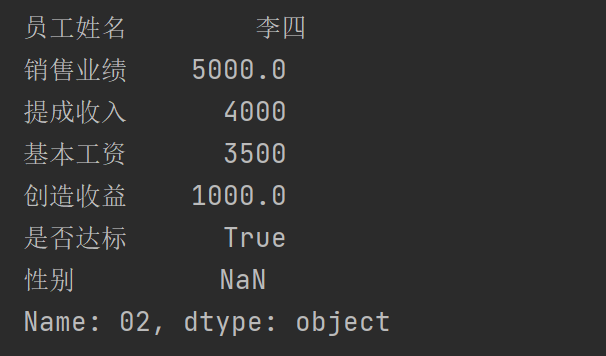
如果之索引行信息,所有列信息都保留,索引语法中的列索引信息可以忽略
print(pad1.iloc[1])
运行结果:
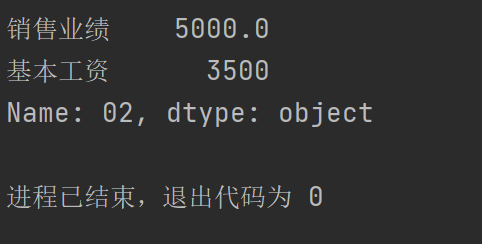
如果只索引列信息,所有行信息都保留,索引语法中的行索引信息不可以被省略,写冒号加逗号表示所有行信息被保留
写行的时候可以不写列,但是写列的时候必须写行
print(pad1.iloc[1,[1,3]])
运行结果:
基于位置的切片:[start,end)即终止值是切不到的
print(pad1.iloc[1:3,0:4])

基于bool表达式的切片:
print(pad1[(pad1.销售业绩>=2000)&(pad1.基本工资>=3500)])
使用逻辑连接词的时候用&表示且,|表示或,逻辑连接词左右两边由()连接
运行结果:

DataFrame常用操作
建表:
import numpy as np
import pandas as pd
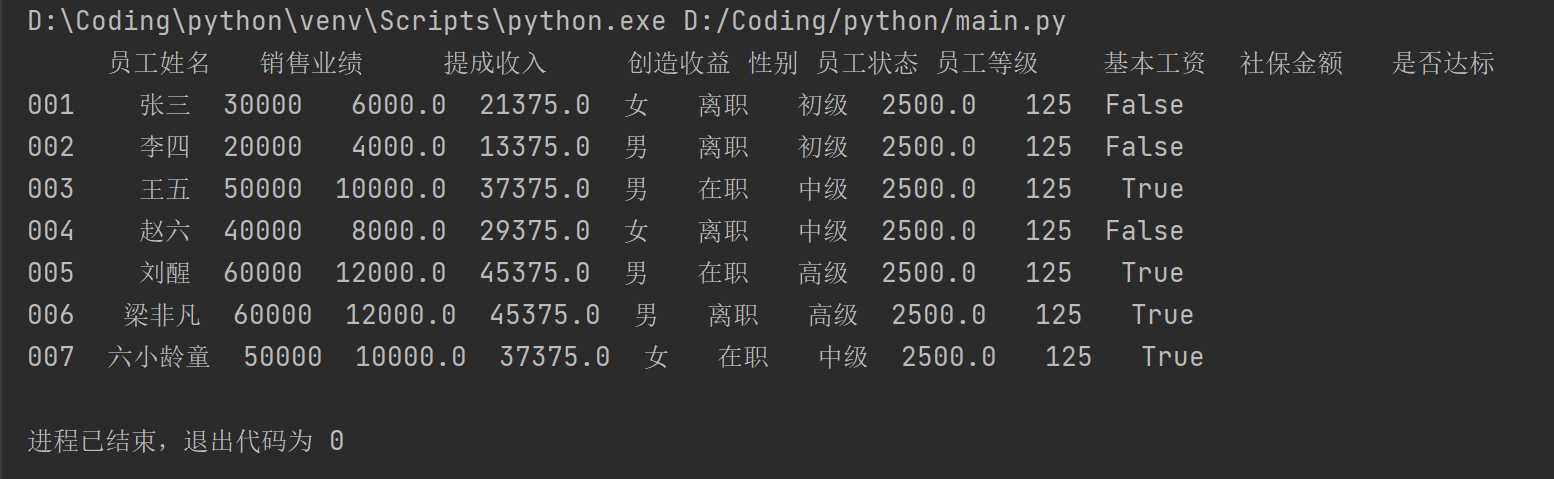
dirct1={"员工姓名":pd.Series(["张三","李四","王五","赵六","刘醒","梁非凡","六小龄童"],index=["001","002","003","004","005","006","007"]),
"销售业绩":pd.Series([30000,20000,50000,40000,60000,60000,50000],index=["001","002","003","004","005","006","007"],dtype=int),
"提成收入":pd.Series([6000,4000,10000,8000,12000,12000,10000],index=["001","002","003","004","005","006","007"],dtype=float),
"创造收益":pd.Series([21375,13375,37375,29375,45375,45375,37375,],index=["001","002","003","004","005","006","007"],dtype=float),
"性别":pd.Series(["女","男","男","女","男","男","女"],index=["001","002","003","004","005","006","007"]),
"员工状态":pd.Series(["离职","离职","在职","离职","在职","离职","在职"],index=["001","002","003","004","005","006","007"]),
"员工等级":pd.Series(["初级","初级","中级","中级","高级","高级","中级"],index=["001","002","003","004","005","006","007"])
}
pad1=pd.DataFrame(dirct1)
pad1["基本工资"]=2500.0
pad1["社保金额"]=125
pad1["是否达标"]=pad1["创造收益"]>=30000
print(pad1)
运行结果:
数据查看和描述
查看数据的形状
DataFrame名.shape()
查看数据框的前几行:默认前5行
DataFrame名.head(n)
查看数据框后几行:默认后5行
DataFrame名.tail(n)
查看行索引:
DataFrame名.index
查看列索引:
DataFrame名.columns
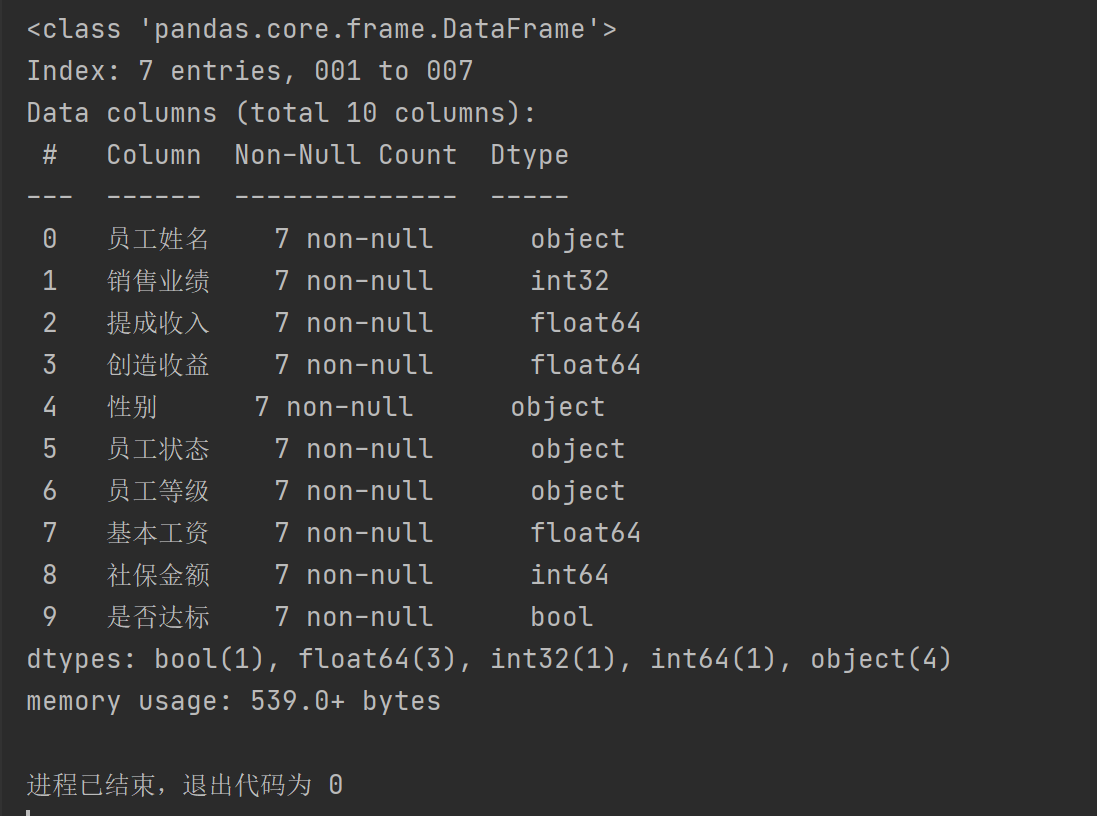
查看数据详细信息
DataFrame名.info()
pad1.info()
简单分析描述统计与排序
描述统计
DataFrame名.describe()
pad1.describe()
运行结果:
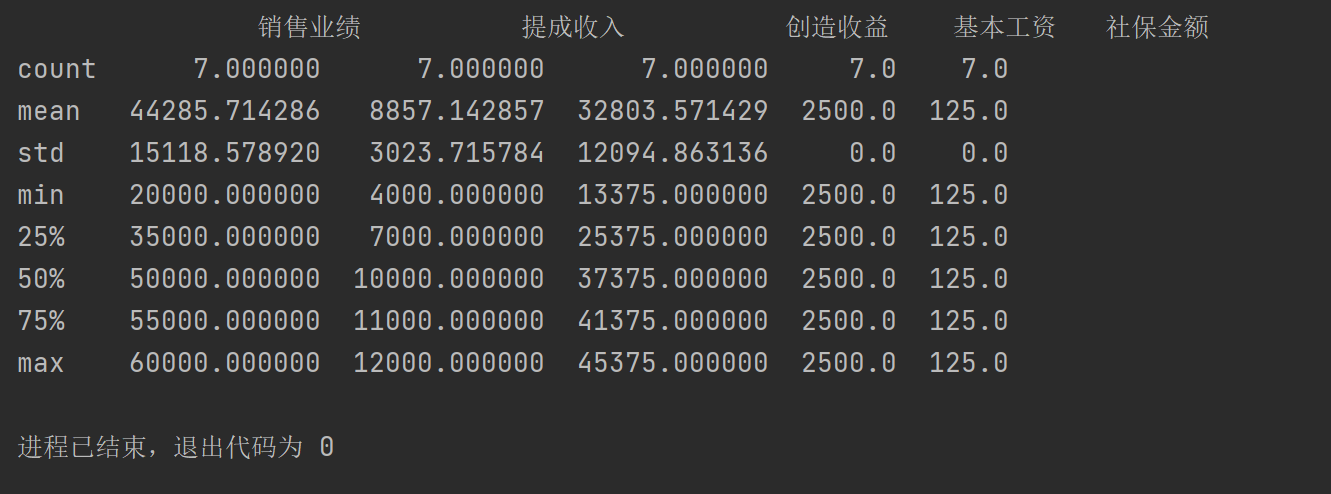
mean:均值;std:标准差;min:最小值;25%:四分之一位数;50%:中位数
75%:四分之三位数;max:最大值
按索引和值排序
按索引排序:默认升序
DataFrame名.sort_index()
DataFrame名.sort_index(ascending=False)
按值排序:默认升序排序
DataFrame名.sort(["列索引1,"列索引2","列索引3"....])
DataFrame名.sort(["列索引1,"列索引2","列索引3"....],ascending=[True,Flase,True...])
缺失值处理
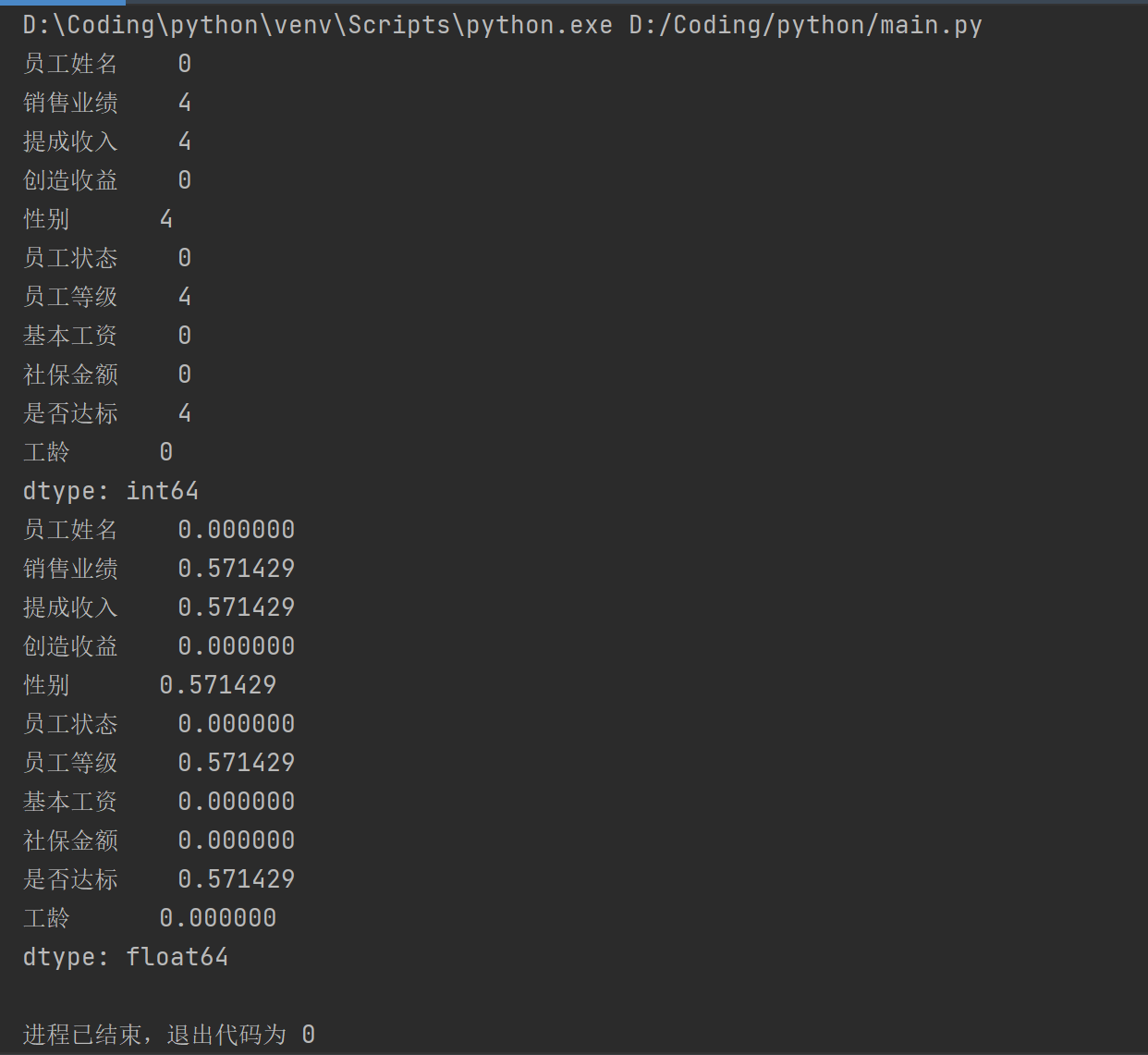
人为制造缺失值:
pad1.iloc[[0,1,3,5],[1,2,4,6,9]]=np.nan
缺失值查看
DataFrame名.isnull()
查看缺失值数量:
DataFrame名.isnull().sum()
查看缺失值比例:
DataFrame名.isnull().mean()
对某一列索引进行分类:
DataFrame名.列索引.value_counts()
填补或替换缺失值
填补缺失值
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
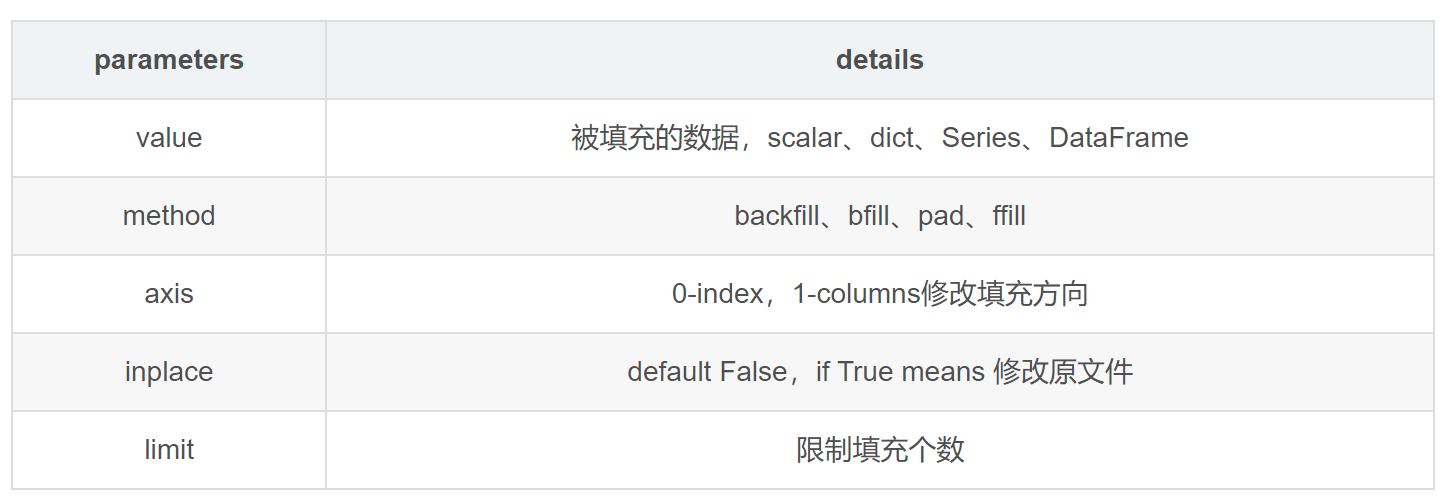
填充可以使用均值,指定数值等填充
backfill:从前往后填;bfill:从后往前填;
替换缺失值
DataFrame名.replace(a,b,method)
删除缺失值
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
数据合并
1.通过pd.concat():更擅长上下拼接
参数 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
objs 需要连接的对象,eg [df1, df2]
axis axis = 0, 表示在水平方向(row)进行连接 axis = 1, 表示在垂直方向(column)进行连接
join outer, 表示index全部需要; inner,表示只取index重合的部分
join_axes 传入需要保留的index
ignore_index 忽略需要连接的frame本身的index。当原本的index没有特别意义的时候可以使用
keys 可以给每个需要连接的df一个label
按行拼接:直接作为参数传进去就行
df_1=pad1.iloc[:4]
df_2=pad1.iloc[4:]
print(df_1)
print(df_2)
pd.concat([df_1,df_2])
print(pd.concat([df_1,df_2]))
按列进行拼接:设置anix=1,但是无法去除重复列
df_1 = pad1.iloc[:, :7]
df_2 = pad1.iloc[:, [0, 3,4,5,6]]
print(df_1)
print(df_2)
pd.concat([df_1, df_2],axis=1)
print(pd.concat([df_1, df_2],axis=1))
设置表来源通过keys参数
print(pd.concat([df_1, df_2],axis=1,keys=["001","002"]))
2.通过pd.merge():更擅长左右拼接
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
eft: 拼接的左侧DataFrame对象
right: 拼接的右侧DataFrame对象
on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组, 即依据那个字段进行拼接,在数据库中类似于连接的作用
left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
right_index: 与left_index功能相似。
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,’B’,’C’];right[”A,’C’,’D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。’outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
suffixes: 用于重叠列的字符串后缀元组。 默认为(’x’,’ y’)。
copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在”左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在”右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
自动找相同列进行左右连接:
print(pd.merge(df_1,df_2))
指定相同列进行左右连接:
print(pd.merge(df_1,df_2,on="员工姓名"))
指定左表列名和右表列名进行连接:
print(pd.merge(df_1,df_2,left_on="员工姓名",right_on="员工姓名"))
分组运算
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
by : 接收映射、函数、标签或标签列表;用于确定聚合的组
axis : 接收 0/1;用于表示沿行(0)或列(1)分割。
level : 接收int、级别名称或序列,默认为None;如果轴是一个多索引(层次化),则按一个或多个特定级别分组
as_index : 接收布尔值,默认Ture;Ture则返回以组标签为索引的对象,False则不以组标签为索引
在进行分组操作:
gp1=pad1.groupby("性别")
查看分组数:
print(len(gp1))
查看具体的情况:
print(gp1.size())
多列标签进行分组并消除某一列的索引:
gp2=pad1.groupby(["性别","是否达标"],as_index=[False,True])
print(gp2.size())
对某一列进行多种聚合方式:
gp3=gp2["销售业绩"].agg([np.mean,np.std])
print(gp3)
以字典的方式对多列进行多种方式的聚合:
print(gp2.agg({"提成收入":np.mean,"销售业绩":np.std}))
对每一列都进行聚合:
gp2.mean()
对聚合出的每一列进行改名:
gp3=gp2.agg({"提成收入":np.mean,"销售业绩":np.std})
gp3.rename(columns={"mean":"平均销售额","std":"标准差"})
print(gp3.rename(columns={"mean":"平均销售额","std":"标准差"}))
数据透视表
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
index:相当于sql里的group by后面的列,用于分组的列,相当于行索引
values:相当于sql里的聚合函数操作的列,放在聚合函数里的列
columns:相当于列索引,就是更细化地展示一些内容
aggfunc:相当于sql里的聚合函数,如果不指明,默认求平均.可以接受列表,即对values作不同的聚合,也可以接受字典,即对不同的values作不同的操作,也可以将字典里的值改为列表形式的,即对某列作几种不同的操作.切记, 对于aggfunc,操作的是values后面的值,而不是columns后面的值
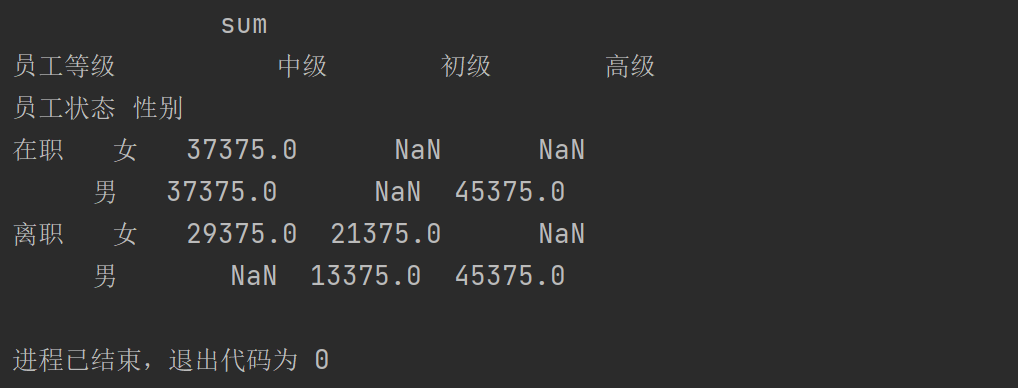
print(pd.pivot_table(pad1,values="创造收益",index=["员工状态","性别"],columns="员工等级",aggfunc=[np.sum,np.std]))
运行结果:
数据的读入和导出
1.读取csv和txt文件使用:
pd.read_csv()
sep参数设置分隔符
index_col参数设置索引列
如果要读取的文件和py文件在同一目录下则不需要写绝对路径,如果不在的话需要写绝对路径
2.读取excel文件:
pd.read_excel()
sheet_name决定读那个sheet的表,默认为0
如果要读取的文件和py文件在同一目录下则不需要写绝对路径,如果不在的话需要写绝对路径
3.导出csv或txt文件:
DataFrame.to_csv("绝对路径\文件名.csv或txt",encoding="设置编码")
编码一般设置为utf-8_sig
4.导出excel文件:
DataFrame.to_csv("绝对路径\文件名.xlsx",sheet_name="设置sheet的名字")
Original: https://blog.csdn.net/weixin_45924251/article/details/119005988
Author: 凯撒袁六兽
Title: 数据清洗-Pandas和DateFrame
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/679989/
转载文章受原作者版权保护。转载请注明原作者出处!