

单图像超分辨率重建(Single Image Super-resolution Reconstruction,SISR)旨在从给定的低分辨率(LR)图像中,重建含有清晰细节特征的高分辨率(HR)图像,是计算机视觉中较为底层的任务。
方法分类
- 基于插值的超分辨率重建方法(如最近邻插值、双线性插值和双三次插值等)
- 基于重构的超分辨率重建方法(如凸集投影法和最大后验概率法等)
- 基于学习的超分辨率重建方法(稀疏表示法、基于卷积神经网络和基于生成对抗网络等)
最近邻插值法指插值点直接以与其 欧式距离最短的像素点的灰度值为自身插值后的灰度值。
- 优点:难度系数低且易实现。
- 缺点:放大的倍数高时,容易出现锯齿效应和图像灰度不连续问题。
双线性插值法主要从 垂直、水平两个方向对相邻的四个像素点进行线性插值实现图像插值问题。
- 优点:在图像灰度不连续问题上有所改进。
- 缺点:插值后的图像产生明显的细节退化,图像高频信息受到损坏。
双三次插值法是在双线性插值法的基础上提出的,将邻近区域内四个相邻像素点扩充到十六个相邻像素点,对其使用 三次插值多项式后进行加权平均计算完成图像插值重建。
- 优点:充分考虑了各像素点对目标插值点的影响,提高了重建质量。
- 缺点:计算复杂 ,运算量急剧增加。
边缘导向插值法主要是对RGB三色图像的 边缘信息进行约束、放大,以便解决人眼视觉特性对图像边缘信息的捕捉造成的影响。
梯度引导插值法是利用邻域内 一阶梯度、二阶梯度的信息调整 梯度分布和 像素分布,再结合 边缘导向插值法和 双线性插值法实现图像重建。
小波变换插值法充分利用 小波变换所具有的 局部细化特点,将图像特征信息分解到 不同尺度上独立研究与分析后,将提取的特征信息叠加融合后再用 小波逆变换提高图像分辨率。
- 优点:提高了运算速度和图像精度。
- 缺点:只适合于整体平移和空间不变的模型,很难解决图像噪音问题。
非均匀内插法对抽象出的非均匀分布的 LR图像特征信息进行 拟合或者插值得到分布均匀的HR图像特征信息来实现超分辨率图像重建。
- 优点:重建效率高。
- 缺点:需要先验信息,缺乏灵活性。
Irani 等人提出迭代反向投影法解决超分辨率图像重建算法对图像先验信息的 高依赖性问题,有效改善重建图像质量问题和对图像先验信息依赖问题,但也使得重建图像的唯一性不能得到保证。
凸集投影法利用HR图像的 正定性、有界性、光滑性等限制条件对重建图像的 边缘信息和 结构信息进行保留,但该算法运算复杂度高,收敛速度慢,且每次迭代对先验信息都存在较强的依赖性。
最大后验概率法(MAP)是指在已知LR图像序列信息和HR图像 后验概率达到最大的前提下,对HR图像进行图像特征信息估计,保证 图像解唯一性的同时 提高图像清晰度,但 图像边缘信息提取有待加强。
陈光盛等人将 POCS 和MAP 结合,在MAP 迭代优化过程中加入POCS 约束凸集中的先验条件,充分发挥出两者的优势, 利用POCS 弥补MAP 收敛稳定性和降噪能力弱的缺点,MAP 弥补POCS 边缘和细节保持差的缺点。
基于样例学习法起源于Freeman等人根据 马尔可夫网络提出的单幅图像重建算法,主要是通过对原始HR图像 实施退化操作,建立训练 图像特征信息库来学习HR图像的先验信息,以此来恢复图像的 高频细节特征信息。
邻域嵌入法以图像块为单位对图像特征信息进行提取,构建 特征信息库对LR图像块和HR图像块进行 加权求和以实现HR图像重建。
- 优点:减弱了模型对样本的依赖性。
- 缺点:削弱了模型的灵活性。
稀疏表示法重点以 字典学习和 稀疏编码为核心来实现图像图像重建效率与重建质量的有效提升。用稀疏编码对图像块进行表示,再从样本图像中抓取HR图像块和LR图像块,形成 超完备字典,并根据字典得到样本图像的系数线性表示,最后根据稀疏系数重建HR图像。
- SRCNN SRCNN 先对图片进行 下采样预处理,得到LR图像,利用 双三次插值放大到目标分辨率,再用卷积核大小分别为9×9、1×1、5×5 的三个卷积层,分别完成特征提取、拟合LR-HR 图像对之间的非线性映射以及将网络模型的输出结果进行重建,得到最后的HR图像。
- FSRCNN 与SRCNN 相比,FSRCNN 主要有三点改进:
- 直接用LR 图像作为输入, 降低特征维度;
- 使用比SRCNN 更小的滤波器,网络结构加深;
- 采用后端上采样超分框架,在网络最后加入 反卷积层来将图像放大至目标分辨率。
在Goodfellow等人提出生成对抗网络(GAN)之后,出现了许多基于GAN 的超分辨率图像重建算法,其在 图像重建效果、网络运算量、运算速度等方面都有很好的结果。
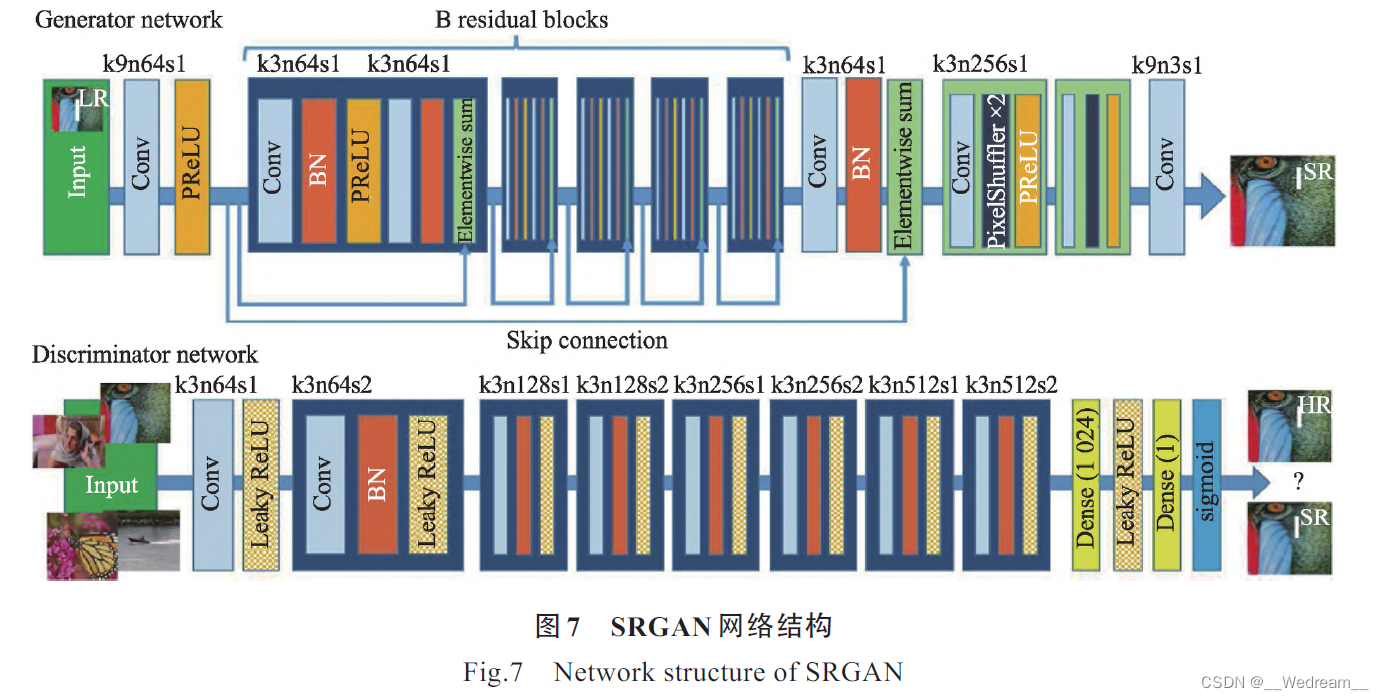

* ESRGAN Wang 等人提出增强型的ESRGAN(enhanced super-resolution generative adversarial network)算法来 提高网络泛化能力,用 残差缩放加快深层网络的训练速度和缩减网络运算参数量,使得重建HR 图像具有 更加丰富的纹理特征,且 色彩亮度也更贴近原始HR 图像。
在图像超分领域早期,利用深度学习算法学习LR 图像到HR 图像所有块之间的映射时,没有考虑到 块与块之间的相关性。2017 年Qingxing Cao 等人受人类感知过程的启发,从整体图像开始, 对不同区域的相关关系进行建模,并按照各个区域的关联线索进行融合,探索具有 注意力转移机制的区域序列,结合深度学习强大的学习能力,提出了基于深度强化学习的注意感知人脸超分。
2020 年Fuzhi Yang 等人最早将Transformer 引入图像超分领域,提出了基于Transformer 网络结构的TTSR 超分算法。为了 充分利用参考图像的纹理信息,FuzhiYang 等人在TTSR 中提出了 特征融合机制,利用上采样方式实现 不同层级间的特征互相融合。大量的实验表明,TTSR 在客观和主观评价方面都取得了显著的进步。
常用数据集
用于深度学习的超分辨率图像重建的图像数据集所涉及的领域较多,涵盖人物、动植物、建筑、自然景观等,且许多开源的数据集在图像外部条件(分辨率大小、张数、格式等)和内部条件(内容、风格、纹理等)上存在着 较大差异,具体情况如下表所示。
benchmark 数据集是同一领域内的对比标准,本节主要列举了该领域的 benchmark测试数据集,即Set5、Set14、BSD100、Urban100 以及DIV2K 数据集。除此之外,Flickr2K 也是超分领域主流的训练数据集,以及后续提出的具有LR-HR 图像对的真实数据集City100、RealSR、DRealSR。
图像质量评估
图像质量评价(image quality assessment,IQA)的方式主要分为 人眼视觉系统感知方面的主观评价和 实验数值计算方面的客观评价。
主观评价是指观察者通过眼睛观察重建的HR 图像,主要依据观察者在 色彩、清晰度、噪音、质感等方面对图像的综合评价。
- 意见平均分MOS MOS 的中文名称是 平均意见评分,是一种常用的主观图像质量评估的方法,通过邀请 接受过训练的普通人以及 未接受过训练的普通人来对重建的图像进行评分,并且两者人数 大致均衡。通过给重建图像打分,再对最后的得分 进行平均,在 视觉感知方面远远优于其它评价指标,可以准确测量图像感知质量。
客观评估是对超分重建结果的定量评价,直接定量地反映图像质量,从数据上可以直接得出结果的好坏。
- PSNR PSNR 的中文名称是 峰值信噪比,是图像进行有损变换时最常用的度量指标之一,也是目前超分领域使用最广泛的客观评价指标。PSNR由图像的 最大像素值和 均方误差MSE来定义的,如以下公式所示:
P S N R = 10 l g ( M A X I 2 M S E ) PSNR = 10 lg(\frac{MAX_I^2}{MSE})PSNR =10 l g (MSE M A X I 2 )
其中,M S E MSE MSE为均方误差,M A X I MAX_I M A X I 指表示图像点颜色的最大数值,图像的最大像素值由 二进制位数决定,如8位二进制表示的图像的 最大像素值就是255。
- SSIM SSIM 的中文名称是 结构相似性,也是目前图像超分领域被广泛使用的性能指标之一。SSIM从人类视觉系统中获得灵感,将图像的组成分为 亮度、对比度以及结构三个部分,并用 均值作为亮度的估计,标准差作为对比度估计,协方差作为结构相似程度估计,数学表达式如下:
S S I M ( x , y ) = [ l ( x , y ) ] α [ c ( x , y ) ] β [ s ( x , y ) ] γ SSIM(x,y)=[l(x,y)]^ \alpha [c(x,y)]^ \beta [s(x,y)]^ \gamma SS I M (x ,y )=[l (x ,y )]α[c (x ,y )]β[s (x ,y )]γ
其中:
l ( x , y ) = 2 μ x μ y + c 1 μ x 2 + μ y 2 + c 1 l(x,y)= \frac{2 \mu_x \mu_y+c_1}{\mu_x^2+\mu_y^2+c_1}l (x ,y )=μx 2 +μy 2 +c 1 2 μx μy +c 1
c ( x , y ) = 2 σ x y + c 2 σ x 2 + σ y 2 + c 2 c(x,y)= \frac{2 \sigma_{xy}+c_2}{\sigma_x^2+\sigma_y^2+c_2}c (x ,y )=σx 2 +σy 2 +c 2 2 σx y +c 2
s ( x , y ) = σ x y μ y + c 3 σ x σ y + c 3 s(x,y)= \frac{\sigma_{xy} \mu_y+c_3}{\sigma_x \sigma_y+c_3}s (x ,y )=σx σy +c 3 σx y μy +c 3
l ( x , y ) l(x,y)l (x ,y )表示图像的 亮度比较,c ( x , y ) c(x,y)c (x ,y )表示图像的 对比度比较,s ( x , y ) s(x,y)s (x ,y )表示图像的 结构比较,μ \mu μ代表均值,σ \sigma σ表示标准差,σ x y \sigma_{xy}σx y 表示协方差,c c c为常数,避免出现分母为0导致系统错误。
补充知识
在神经网络占据主导地位的情况下,部分传统的上采样方式因其可解释性以及容易实现,在深度学习的超分模型中经常见到,并且取得让人满意的效果。这里主要介绍 基于插值的传统上采样方法和 端到端可学习的上采样方法。
- 基于插值法的上采样方法 插值法的原理就是利用一定的 数学策略,从相关点中计算出待扩展点的像素值,这在数学上很容易实现,所以在超分重建领域最早采用插值法进行。但是因为插值函数本身的连续性,导致了重建图像 较为平滑而模糊。图像纹理处常常是 各种突变,这与函数的连续性互为矛盾,这正是基于插值的方法的 局限性以及 本质问题所在。
- 端到端可学习的上采样方法 为了解决基于插值法的上采样方法存在的问题,研究者们提出了端到端可学习的上采样方法: 转置卷积和 亚像素卷积。
- 转置卷积又称为 逆卷积,即卷积过程的逆过程。转置卷积通过 卷积学习来增大图像分辨率,实现了端到端的放大,避免了人工设计带来的干扰,并且可以与卷积神经网络 保持很好的兼容,所以被广泛应用在图像超分辨率重建领域中。
- 亚像素卷积具体过程就是利用 卷积计算对图像进行 特征提取,再 对不同通道间的特征图进行重组,从而得到更高分辨率的特征图。由于 每个像素的扩展都是通过卷积完成,相应的参数都是需要学习产生, 解决了插值方法中的存在人工痕迹问题,更好地拟合了像素之间的关系。
参考文献
[1]杨才东,李承阳,李忠博,谢永强,孙方伟,齐锦.深度学习的图像超分辨率重建技术综述[J].计算机科学与探索,2022,16(09):1990-2010.
[2]钟梦圆,姜麟.超分辨率图像重建算法综述[J].计算机科学与探索,2022,16(05):972-990.
最后感谢小伙伴们的学习噢~
Original: https://blog.csdn.net/weixin_43800577/article/details/126918676
Author: Wedream
Title: 单图像超分辨率重建总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/646063/
转载文章受原作者版权保护。转载请注明原作者出处!