

过程基本参考自BERT实战——(5)生成任务-机器翻译,结合我个人的数据集在数据处理部分做了些调整,完整代码可见translate.ipynb
一、数据处理
我的数据集是这样的:


第一列是英文,第二列是对应的法文翻译,第三列是文本来源,所以说第三列是不需要的
1.首先是读取数据,把前两列存入数组中,并把前90%的数据作为训练集,后10%的数据作为验证集
f=open("fra.txt","r",encoding="utf-8").readlines()
en=[]
fre=[]
data=[]
for l in f:
line=l.strip().split("\t")
tmp={}
tmp["en"]=line[0]
tmp["fr"]=line[1]
data.append(tmp)
print(len(data))
print(data[0])
train_size=int(len(data)*0.9)
train_data=data[:train_size]
val_data=data[train_size:]
2.把数据存入到对应的文件中
f=open("train.txt","w")
for i in train_data:
f.write(str(i)+"\n")
f.close()
f=open("val.txt","w")
for i in val_data:
f.write(str(i)+"\n")
f.close()
3.加载分词器
from transformers import AutoTokenizer
model_checkpoint="Helsinki-NLP/opus-mt-en-ro"
tokenizer=AutoTokenizer.from_pretrained(model_checkpoint,use_fast=True)
4.定义预处理函数,把数据按源语言和目标语言分开,作为dataset中的input_ids和labels
from datasets import load_dataset
raw_datasets=load_dataset("text",data_files={"train":"train.txt","validation":"val.txt"})
max_input_length=64
max_target_length=64
source_lang="en"
target_lang="fr"
def preprocess_function(examples):
inputs=[eval(ex)[source_lang] for ex in examples["text"]]
targets=[eval(ex)[target_lang] for ex in examples["text"]]
model_inputs=tokenizer(inputs,max_length=max_input_length,truncation=True)
with tokenizer.as_target_tokenizer():
labels=tokenizer(targets,max_length=max_target_length,truncation=True)
model_inputs["labels"]=labels["input_ids"]
return model_inputs
tokenized_datasets=raw_datasets.map(preprocess_function,batched=True)
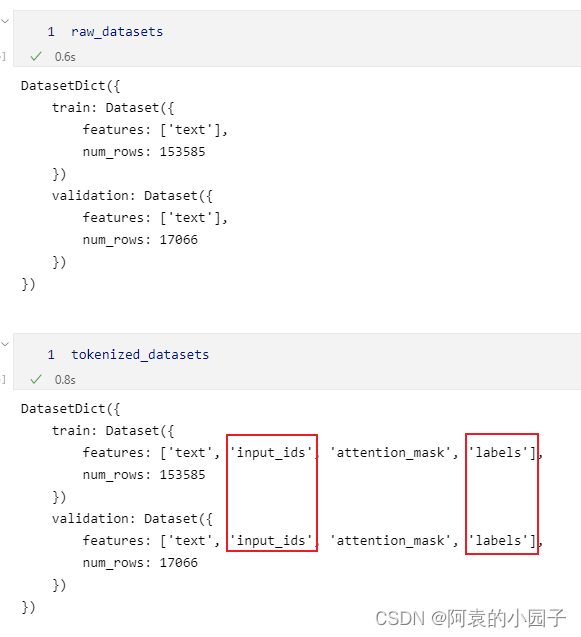
分别输出raw_datasets和tokenized_datasets的结构,可以看到后者多了三列内容,我们只需要关注input_ids和labels就行:
二、加载预训练模型,并设置参数
1.预训练模型和训练参数
from transformers import AutoModelForSeq2SeqLM
model=AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
from transformers import Seq2SeqTrainingArguments
batch_size=8
args=Seq2SeqTrainingArguments(
"test-translation",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=10,
predict_with_generate=True,
fp16=False,
)
2.载入数据收集器
from transformers import DataCollatorForSeq2Seq
data_collator=DataCollatorForSeq2Seq(tokenizer,model=model)
3.加载评估方法
import numpy as np
from datasets import load_metric
metric=load_metric("sacrebleu")
print("successfully import metric")
4.评估方法只能接收特定格式的数据,因此要把用postprocess_text方法把preds和labels处理成对应的格式
def postprocess_text(preds,labels):
preds=[pred.strip() for pred in preds]
labels=[[label.strip()] for label in labels]
return preds,labels
def compute_metrics(eval_preds):
preds,labels=eval_preds
if isinstance(preds,tuple):
preds=preds[0]
decoded_preds=tokenizer.batch_decode(preds,skip_special_tokens=True)
labels=np.where(labels!=-100,labels,tokenizer.pad_token_id)
decoded_labels=tokenizer.batch_decode(labels,skip_special_tokens=True)
print("type(decoded_preds)=",type(decoded_preds))
print("type(decoded_labels)=",type(decoded_labels))
decoded_preds,decoded_labels=postprocess_text(decoded_preds,decoded_labels)
result=metric.compute(predictions=decoded_preds,references=decoded_labels)
result={"bleu":result["score"]}
prediction_lens=[np.count_nonzero(pred!=tokenizer.pad_token_id) for pred in preds]
result["gen_len"]=np.mean(prediction_lens)
result={k:round(v,4) for k,v in result.items()}
print("result is as follow============================")
print(result)
return result
三、开始训练(微调模型)
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from transformers import Seq2SeqTrainer
trainer=Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
训练结果如下:
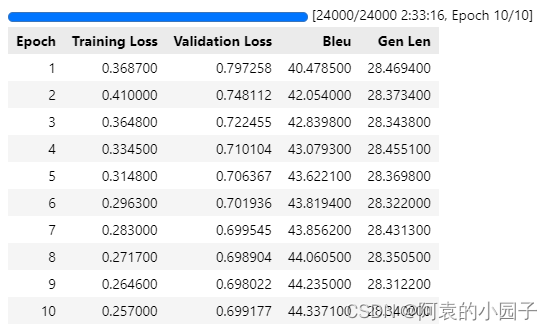
sacrebleu的评测结果是乘了100后的,所以可以看到评估出来的bleu是在44%左右。
这个实验是用A100跑的,但是跑了10个epoch竟然花了两个半小时。
Original: https://blog.csdn.net/yuanren201/article/details/124866061
Author: 阿袁的小园子
Title: 用Bert做英法机器翻译
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544455/
转载文章受原作者版权保护。转载请注明原作者出处!