

四、Python数据挖掘(Pandas库)
目录:
- 四、Python数据挖掘(Pandas库)
*
–
+ - pd.DataFrame(data, index, columns, dtype=None, copy=False)
- pd.DataFrame(dict)
- pd.date_range(start=, end=, periods=, freq=, closed=None)
- new_ = pd.to_datetime(datetime_list)
–
+
*
– 2.DataFrame 的属性
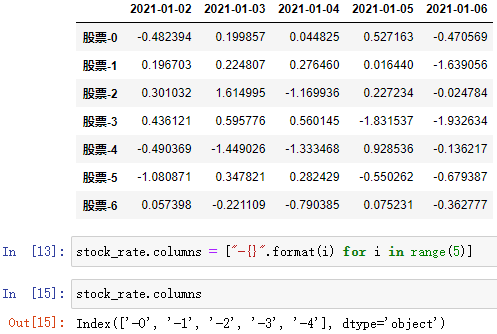
– 3.DataFrame 重设索引 - DataFrame数组.index[下标/start:stop]
- DataFrame数组.columns[下标/start:stop]
- new_ = DataFrame数组.reset_index(drop=False)
- new_ = DataFrame数组.set_index(keys, drop=True)
–
+
*
– 4.其他常用方法 - DataFrame数组.T
- DataFrame数组.head([num])
- DataFrame数组.tail([num])
- DataFrame数组.iloc[行下标/start:stop[, start:stop]]
–
+ - DataFrame数组.index.levels
–
+
*
– 2.Panel - pd.Panel(data, items, major_axis, minor_axis, copy=False, dtype=None)
–
+ - pd.Series(data, index)
–
+ - DataFrame数组[column][index]
- DataFrame数组[start:stop]
–
+
*
–
+ (2)按标签索引(先行后列) - DataFrame数组.loc[index][column] DataFrame数组.loc[index, column]
–
+
*
–
+ (3)按下标索引(先行后列) - DataFrame数组.iloc[行下标/start:stop[, start:stop]]
–
+
*
–
+ (4)扩展:属性访问法
– 2.数据的赋值 - 访问需要修改的值 = 值
–
+
*
– 3.排序
–
+ (1)对 DataFrame 进行排序 - DataFrame数组.sort_values(by=, ascending=True)
- DataFrame数组.sort_index()
–
+
*
–
+ (2)对 Series 进行排序 - Series数组.sort_values(ascending=True)
- Series数组.sort_index()
–
+
*
– 4.算术运算与逻辑运算
–
+ (1)算术运算 - 访问要进行运算的值 运算式
–
+
*
–
+ (2)逻辑运算 - 直接访问元素的逻辑表达式 ⇨ 返回值:布尔数组
- DataFrame/Series数组[布尔数组]
- DataFrame/Series数组[布尔数组] = 值
- DataFrame/Series数组.query(“列索引属性的逻辑表达式”)
- DataFrame/Series数组[列索引].isin(values)
–
+
*
–
+ (3)统计运算 - DataFrame/Series数组.describe()
–
+
*
–
+ (4)自定义运算 - DataFrame/Series数组.apply(func[, axis=0])
–
+
*
– 5.Pandas 绘图 - DataFrame/Series数组.plot(x=?, y=?, kind=?)
–
+ - pd.read_csv(filepath_or_buffer, usecols=[ ], names=[ ])
- DataFrame/Series数组.to_csv(…)
–
+
*
– 2.HDF5 文件的读写 - pd.read_hdf(…)
- DataFrame/Series数组.to_hdf(…)
–
+
*
– 3.JSON 文件的读写 - pd.read_json(…)
- DataFrame/Series数组.to_json(…)
一、Pandas 简介
- *Pandas是什么?
Pandas 以 Numpy 为基础,借力 Numpy 模块在计算方面性能高的优势;其次, Pandas 基于 Matplotlib,能够简便的画图; Pandas 还具有独特的数据结构
- *为什么使用 Pandas?
Pandas 具有便捷的数据处理能力,例如上一节 三、Python数据挖掘(Numpy库)中我们知道了,通过 Numpy 的 genfromtxt() 函数读取数据文件中的 字符串时,会出现 nan 的情况,但 Pandas 解决了这些问题,具有便捷的数据处理能力,读取文件方便,并且封装了 Matplotlib 和 Numpy 的画图和计算
二、Pandas 三大结构之——DataFrame
对于 Numpy 中的 ndarray,它只储存数据,但不包含数据的意义,而 DataFrame 的结构上,既有 行索引,又有 列索引的 二维数组
可以类比于 SQL 中的一张关系表:一般 DataFrame 中行索引是指不同的事物,而列索引是指事物的属性( 重要)
Pandas 一般会和 Numpy 配合着来使用
导入模块:
import pandas as pd
1.DataFrame 的创建
pd.DataFrame(data, index, columns, dtype=None, copy=False)
返回 二维数组data 的 DataFrame 结构
index 行索引语句,数组
columns 列索引语句,数组
注: 只返回新数组,不改变原数组
例:
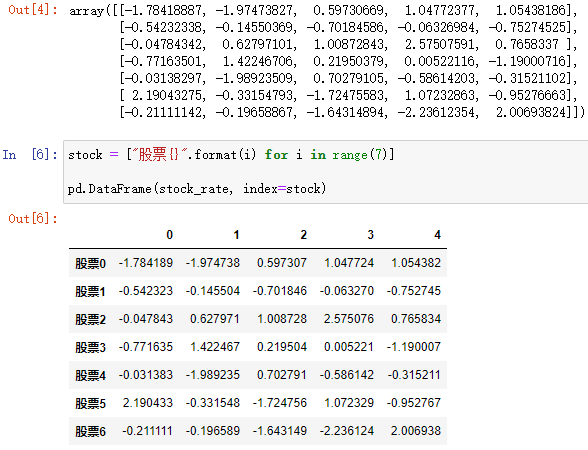

还可以通过传入字典来定义 DataFrame:
; pd.DataFrame(dict)
以字典的方式创建 DataFrame 数组
字典 key值 作为列索引
例:

Pandas 中的特殊索引——时间序列:
pd.date_range(start=, end=, periods=, freq=, closed=None)
生成一个固定间隔时间的时间序列,可以用作 DataFrame 的索引
start= 开始日期,格式为: “2021-01-01”(不含时间)或 “2021-01-01 00:00:00”(含时间)
end= 结束日期,格式和 start= 一致
periods= 生成的时间序列的个数
freq= 频率,即时间间隔
closed= 把原输出结果输出为开/闭区间:
“closed=left” 表示输出区间为 左闭右开
“closed=right” 表示输出区间为 左开右闭
freq 频率含义D一天W一周W-SUN一周,以星期天为起始,等同于”W”W-MON一周,以星期一为起始W-TUE一周,以星期二为起始W-WED一周,以星期三为起始W-THU一周,以星期四为起始W-FRI一周,以星期五为起始W-SAT一周,以星期六为起始M一个月,以月结束为界,如:”2018-11-30″, “2018-12-31″MS一个月,以月起始为界,如:”2021-01-01”, “2021-02-01″S一秒T/min一分钟H一个小时A/Y一年,以年结束为界,如:”2020-12-31”
更详细的内容,可参考下述文章:
- 【pandas】 之 pandas.date_range 函数
- 此外,还可以指定数值,如: 5D 表示5天; 3H 表示三个小时
例:
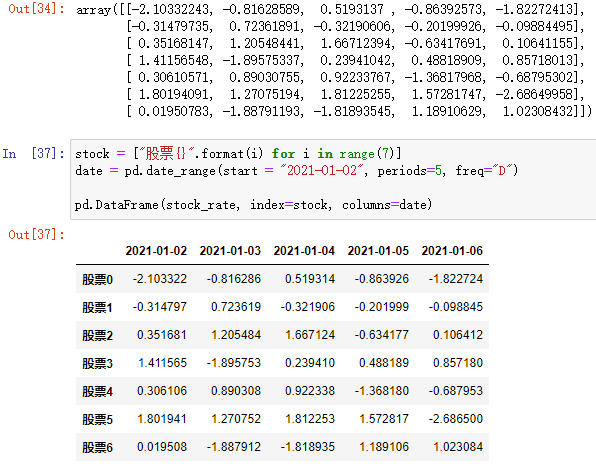
专门处理时间序列的函数:
; new_ = pd.to_datetime(datetime_list)
专门处理时间序列的函数,传入一个时间序列的列表,返回一个新的对象
datetime_list 时间序列列表
新对象的属性含义month时间序列列表的
月份
列表year时间序列列表的
年份
列表weekday时间序列列表的
星期
列表day时间序列列表的
日份
列表
例:
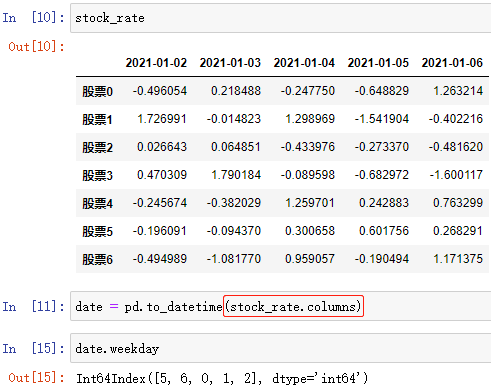
可以直接根据日期返回星期
2.DataFrame 的属性
属性含义shape形状index行索引columns列索引values表格内容-值
例:
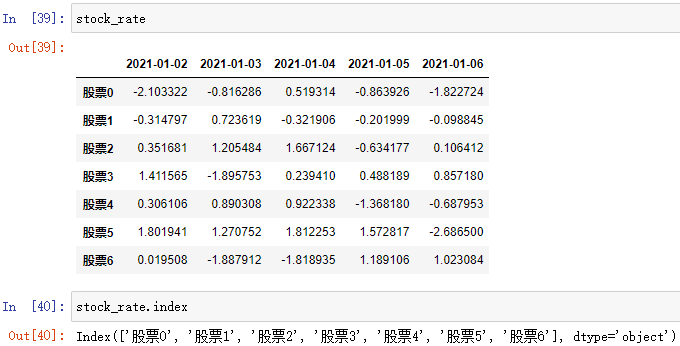
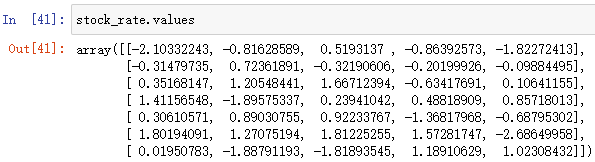

; 3.DataFrame 重设索引
由于这些属性都是由数组构成,因此也可以进行一些访问操作
访问行索引:
DataFrame数组.index[下标/start:stop]
访问 行索引,缺省时访问所有 行索引
注:DataFrame 规定,不能直接通过 DataFrame数组.index[下标] = 值 单独修改某一行索引,只能整体修改
例:
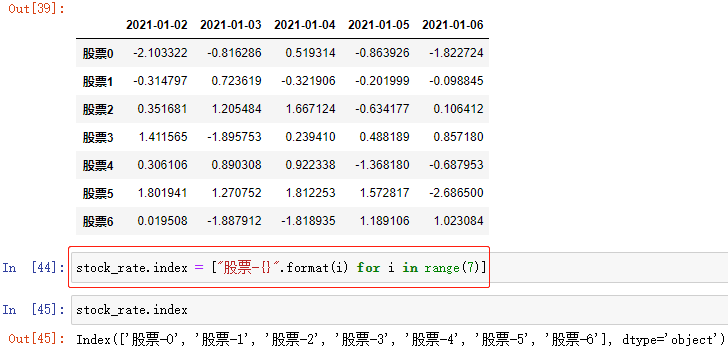
访问列索引:
; DataFrame数组.columns[下标/start:stop]
访问 列索引,缺省时访问所有 列索引
注:DataFrame 规定,不能直接通过 DataFrame数组.columns[下标] = 值 单独修改某一列索引,只能整体修改
例:
重设行索引:
new_ = DataFrame数组.reset_index(drop=False)
DataFrame 将生成新的数字顺序的行索引
drop= 决定是否删除原索引,如果 drop=False,则不删除原索引,会把原行索引加到第一列中
注: 只返回新数组 new_ ,不改变原数组
例:

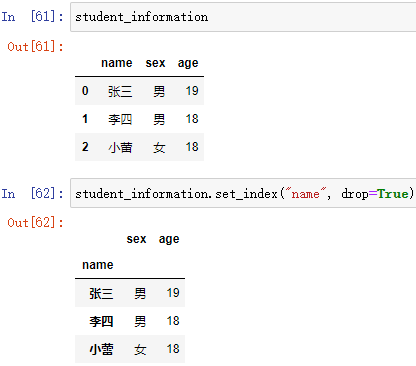
以某列值设置为新的索引:
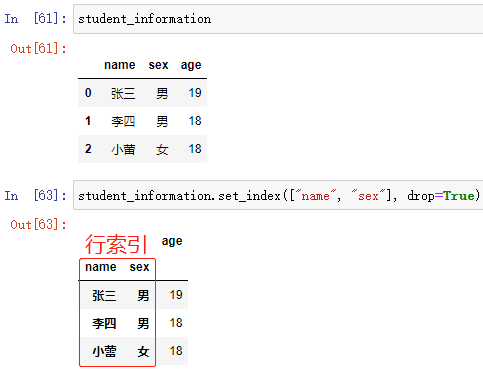
; new_ = DataFrame数组.set_index(keys, drop=True)
以某列的值设置为新的索引,key为某列的索引
keys 索引,可以设置 多个索引
drop 决定是否删除作为索引引用后的该列:
drop=Fales 当设置了某列的值为新的索引后,保留这一列
drop=True 当设置了某列的值为新的索引后,不保留这一列,即 列数-1
注: 只返回新数组 new_ ,不改变原数组
- 以某一列的值作为新的索引,可以类比于 SQL 的 主码,规定 主码为 索引
- 当设置多列作为索引时,可以类比于 SQL 的 主码,主码可以由 *多个属性组成
例:把 “name” 作为新的行索引
例:设置多个行索引
4.其他常用方法
DataFrame数组.T
同样可以实现行和列的转置
DataFrame数组.head([num])
返回 DataFrame 数组 前 num 行的内容
num 可以指定行数,默认为5行
DataFrame数组.tail([num])
返回 DataFrame 数组 后 num 行的内容
num 可以指定行数,默认为5行
- 后面两个方法一般用于结构的查看
访问某一行整行、某一整列或部分数据:
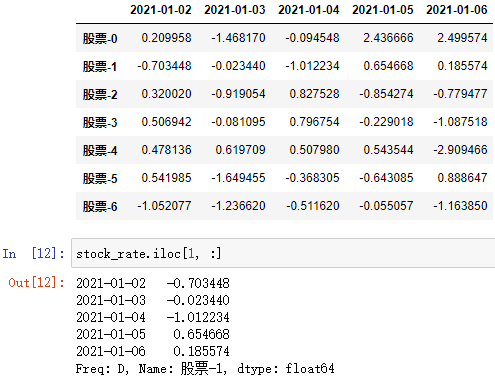
DataFrame数组.iloc[行下标/start:stop[, start:stop]]
用于访问 DataFrrame 中所选的数据
行下标/start:stop 可以是指 行下标 所索引的行,也可以是某些行 [start:stop)
[start:stop) 列的范围,缺省时为 所有列,这个 不能是下标,但是可以通过如:[0:1] 的方式来单独访问某一列
后面会作更详细的介绍
例:
; 三、Pandas 三大结构之——Panel
MultiIndex 与 Panel:
1.MultiIndex
MultiIndex 就是多层或分层索引对象,简单来说,在 DataFrame 具有 多列行索引时, MultiIndex 就是多列行索引对象
例:
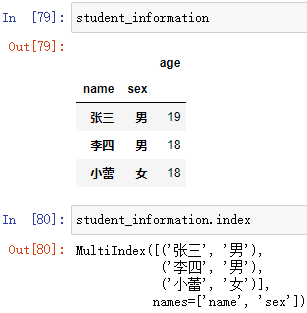
- 索引的名字分别是 name 和 *sex
例:通过 index.索引的名字 可以访问指定索引
; DataFrame数组.index.levels
显示行索引的内容

2.Panel
Panel 是用于存储三维数组的结构,其大致结构类似于 DataFrame
通常会把 Pnael 当作 DataFrame(数据帧) 的容器
pd.Panel(data, items, major_axis, minor_axis, copy=False, dtype=None)
返回 三维数组data 的 Panel 结构
data 三维数组
items – axis 0 每个项目对应于内部包含的数据帧(DataFrame)
major_axis – axis 1 它是每个数据帧(DataFrame)的 行索引
minor_axis – axis 2 它是每个数据帧(DataFrame)的 列
注: 只返回新数组 new_ ,不改变原数组
- Panel 了解即可, Panel 从版本0.20.0开始弃用:推荐的用于表示3D数据的方法是 DataFrame 上的 MultiIndex 方法
四、Pandas 三大结构之——Series
Series 可以是 DataFrame 中的某一行,视为 一维数组
它包含 索引index (0, 1, 2, 3…) 和 值value 属性,这里的 index 指的是 Series的列索引——即一维数组的索引,而不是 DataFrame 的行索引
可以把 DataFrame 理解为 Series 的容器
; 1.Series 的属性
属性含义index索引values值
2.Series 的创建
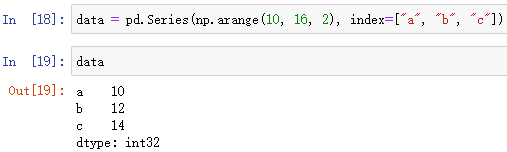
pd.Series(data, index)
返回 一维数组data 的 Series 结构
data 一维数组
index 索引语句,数组
例:
直接创建:
通过 DataFrame 创建:
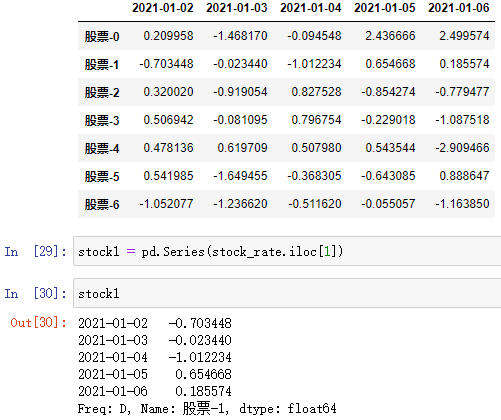
- 会沿用原 DataFrame 的列索引作为 Series 的索引
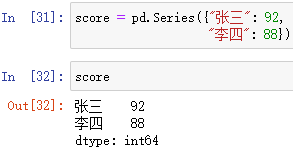
通过字典创建:
; 五、基本数据操作
1.数据的索引/访问
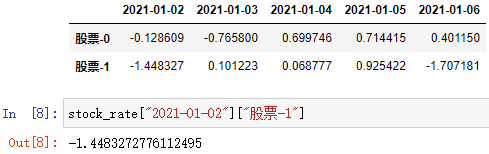
(1)直接索引(先列后行)
DataFrame数组[column][index]
通过 列和行 的索引访问 DataFrame 中的值
column 列索引,可以是一个数组
index 行索引,可以是一个数组,可以缺省
注:当 column 是一个数组时,index 不能指定任何值( 重要)
注:[ ][ ] 是先列后行,不是先行后列
DataFrame数组[start:stop]
读取下标在区间 [start, stop) 内的 行, 无法指定列
例:
索引到某一值:
访问整列数据:
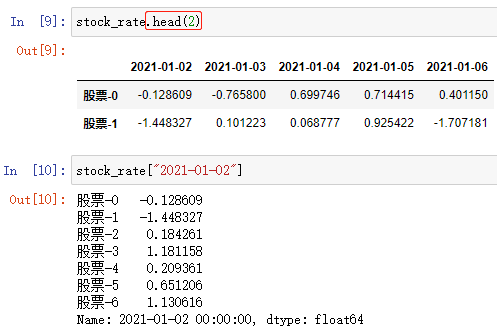
通过数组访问某些组合的数据:
- 注:上述情况中 column 是数组, index 不能指定任何值
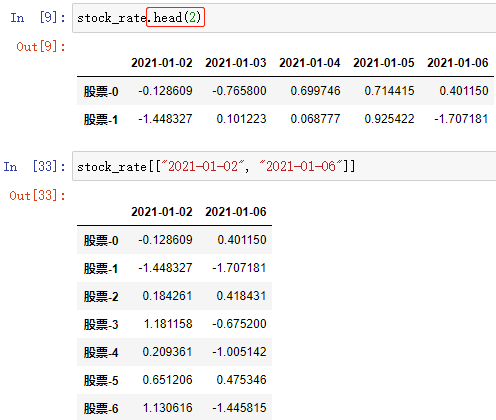
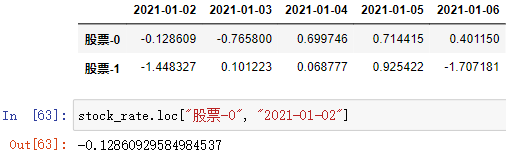
; (2)按标签索引(先行后列)
DataFrame数组.loc[index][column] DataFrame数组.loc[index, column]
通过 行和列 的索引访问 DataFrame 中的值,上述两种方法效果一样,都可以
index 行索引,可以是一个数组
column 列索引,可以是一个数组
loc() 不会受到 直接访问那样的限制
例:
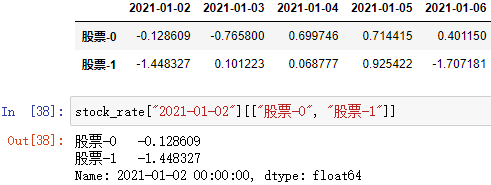
索引到某一值:
通过数组访问部分值:
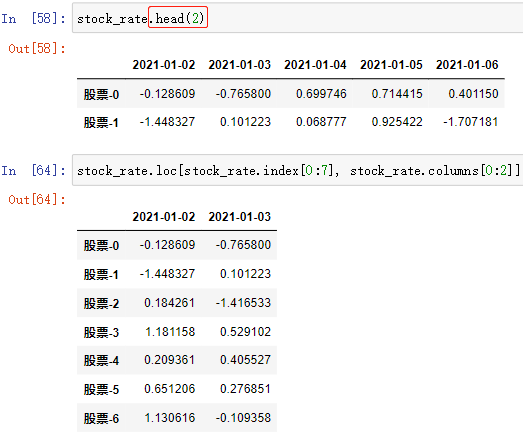
- 可以配合 DataFrame数组.index[ ] 和 DataFrame数组.columns[ ] 使用,不过没必要这样用,可以直接使用 *DataFrame数组.iloc[]
; (3)按下标索引(先行后列)
DataFrame数组.iloc[行下标/start:stop[, start:stop]]
用于访问 DataFrrame 中所选的数据
行下标/start:stop 可以是指 行下标 所索引的行,也可以是某些行 start:stop
start:stop 列的范围,缺省时为 所有列,这个 不能是下标
例:
通过 start:stop 访问部分值:
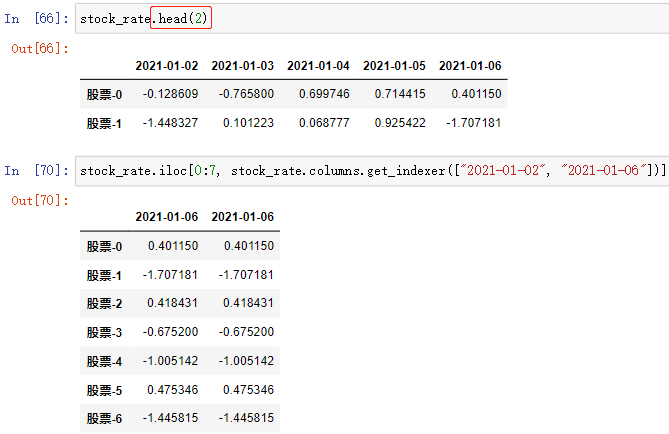
- 可以配合 DataFrame数组.columns.get_indexer(columns) 来使用,该方法的作用是通过 索引来获取索引所在位置的 列下标
- 可以配合 DataFrame数组.index.get_indexer(index) 来使用,该方法的作用是通过 索引来获取索引所在位置的 *行下标
通过行下标访问部分值:

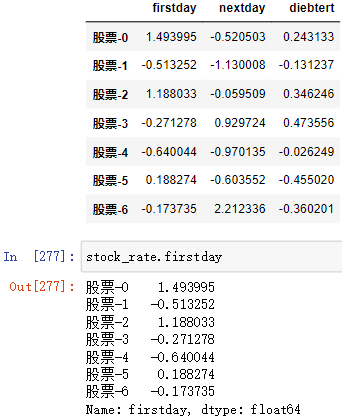
; (4)扩展:属性访问法
当 列索引是 以字母为开头时, 列索引就是该 DataFrame/Series数组 的属性,可以用访问属性的方法来访问列
例:
2.数据的赋值
可以进行整体赋值,也可以单独赋值:
访问需要修改的值 = 值
可以实现整体赋值或单独赋值
例:
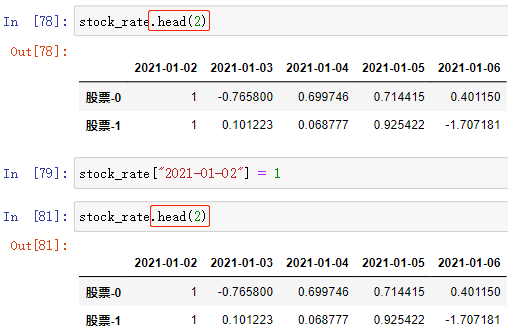
注:这个方法还可以为 DataFrame/Series数组 增加新的行或列
例:
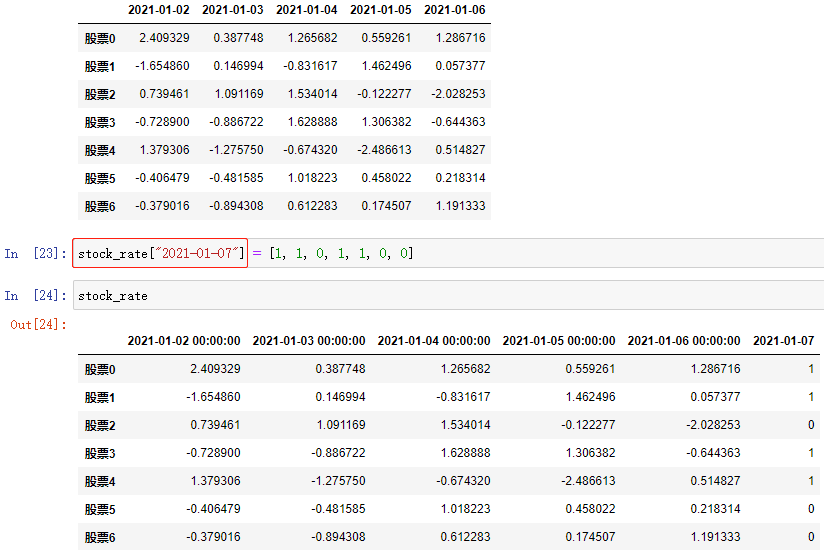
- 此时访问的索引是不存在的索引即可
; 3.排序
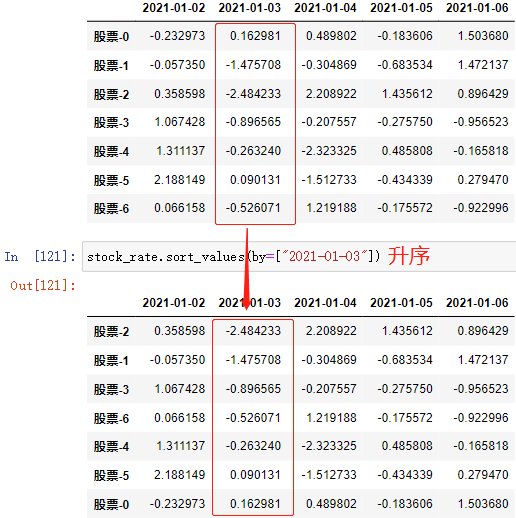
(1)对 DataFrame 进行排序
排序有两种形式,一种是根据 内容进行排序,一种是根据 行索引进行排序
DataFrame数组.sort_values(by=, ascending=True)
取单个列或多个列,根据这些列的内容进行排序
by 可以是某个列的索引,也可以是多个列的索引,以索引选取的列作为排序依据,如: by=[“Chinese”, “Math”],则优先根据 Chinese 索引进行排序,若 Chinese 索引值 有相等项时,再根据 Math 索引
ascending=False 降序排序
ascending=True 升序排序,默认
注: 只返回新数组,不改变原数组
DataFrame数组.sort_index()
根据 行索引进行排序
注: 只返回新数组,不改变原数组
例:
; (2)对 Series 进行排序
由于 Series 是一个一维数组,因此较简单
Series数组.sort_values(ascending=True)
根据 Series 数组内容进行排序
ascending=False 降序排序
ascending=True 升序排序,默认
注: 只返回新数组,不改变原数组
Series数组.sort_index()
根据 索引进行排序
注: 只返回新数组,不改变原数组
4.算术运算与逻辑运算
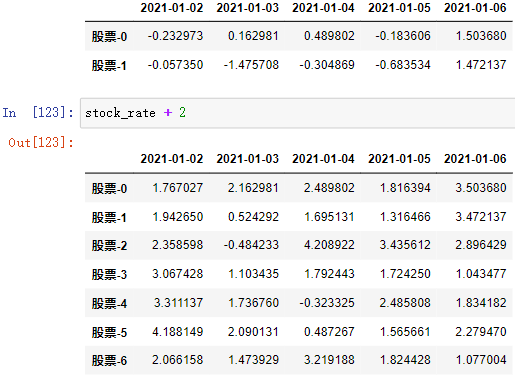
(1)算术运算
直接进行运算:
访问要进行运算的值 运算式
可以直接进行运算
例:
通过方法进行运算:
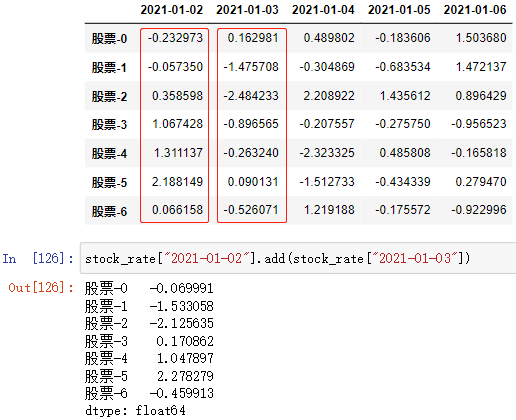
运算方法含义DataFrame/Series数组.add(other)加运算:DataFrame/Series数组元素 + otherDataFrame/Series数组.sub(other)减运算:DataFrame/Series数组元素 – otherDataFrame/Series数组.mul(other)乘运算:DataFrame/Series数组元素 * otherDataFrame/Series数组.div(other)除运算:DataFrame/Series数组元素 / otherDataFrame/Series数组.mod(other)除(取整)运算:DataFrame/Series数组元素 % otherDataFrame/Series数组.pow(other)幂运算:DataFrame/Series数组元素 ** other
数组与数组/自身之间运算(形状相同时):
例:
- 注:如果 other 是一个 数组的话,还有一个默认属性: …(other[, axis=1])
- 默认为 axis=1, DataFrame/Series数组 和 other 的对应位置进行运算,缺值的位置用 NaN 填充
- 若 axis=0,则 DataFrame/Series数组 会和 行列转置后的other进行运算
; (2)逻辑运算
直接访问元素的逻辑表达式 ⇨ 返回值:布尔数组
布尔逻辑表达式 ⇨ 返回值:布尔数组
进行基本的逻辑运算,该表达式记为”布尔数组”( 重要)
例:
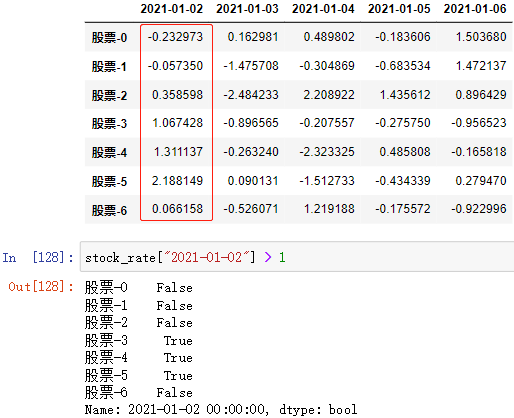
逻辑运算符:
逻辑运算符含义>大于
Original: https://blog.csdn.net/weixin_48261286/article/details/114156444
Author: ~宪宪
Title: 四、Python数据挖掘(Pandas库)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/676454/
转载文章受原作者版权保护。转载请注明原作者出处!