

本博客记录一下遇到的各种损失,如想了解各种损失及其代码,也可查看mmdet项目的loss部分
交叉熵
适用于多分类任务,交叉熵属于分类损失中常见的一种损失,-ylogP取平均,概率P为1时,损失为0。在bert的mlm预训练任务中使用了ignore_index入参,可仅根据部分位置(15%mask处)计算损失。在实际计算时,标签转为one-hot,y=0的位置-ylogP为0,不参与损失计算,可参考如下链接中的红色示例交叉熵损失和二元交叉熵损失_飞机火车巴雷特的博客-CSDN博客_交叉熵损失
计算过程为:softmax——log——nllloss
softmax输出在0-1之间
log输出在负无穷到0之间,softmax和log可合并为F.log_softmax操作
nllloss取log输出中相应位置的值,求平均后取负,输出在0到正无穷之间
有多种实现方法,下例中所有loss=tensor(1.3077)
import torch
import torch.nn as nn
import torch.nn.functional as F
input = torch.randn(3,3)
print(input)
input = torch.tensor([[0.2,0.3,0.4],
[-0.02,-0.13,0.2],
[0.5,-0.3,0.73]])
target = torch.tensor([0,2,1])
target1 = torch.FloatTensor([[1,0,0],
[0,0,1],
[0,1,0]])
##############################################################
"""
softmax+只用正确类位置的概率
nn.Softmax-torch.log-nn.NLLLoss
=F.log_softmax-nn.NLLLoss
=nn.CrossEntropyLoss
=F.cross_entropy
"""
1、nllloss softmax-log-nllloss
softmax=nn.Softmax(dim=1) # 横向softmax
nllloss=nn.NLLLoss()
softmax_log = torch.log(softmax(input))
softmax_log2=F.log_softmax(input, dim=1)
"""
print(softmax_log)
tensor([[-1.2019, -1.1019, -1.0019],
[-1.1448, -1.2548, -0.9248],
[-0.9962, -1.7962, -0.7662]])
"""
loss1 = nllloss(softmax_log,target)
print(loss1)
loss2 = nllloss(softmax_log2,target)
print(loss2)
2、nllloss=取对应值求平均取负
loss3 = -(softmax_log[0][target[0]]+
softmax_log[1][target[1]]+
softmax_log[2][target[2]])/3
print(loss3)
3、直接调用CrossEntropyLoss、cross_entropy
crossEntropyLoss=nn.CrossEntropyLoss()
loss4=crossEntropyLoss(input, target)
print(loss4)
loss5=F.cross_entropy(input, target)
print(loss5)
二元交叉熵/二分类交叉熵
适用于二分类、多标签分类任务。交叉熵在softmax后只取正确位置的值计算loss。二元交叉熵认为类间独立,在sigmoid后取所有位置的值计算loss,-(ylogP+(1-y)log(1-P))取平均,当y为0或1时,相加的两项中必有一项为0。
"""
sigmoid+使用所有类别的概率
F.sigmoid- F.binary_cross_entropy
=F.binary_cross_entropy_with_logits
=nn.BCEWithLogitsLoss
=nn.BCELoss
"""
softmax=nn.Softmax(dim=1)
print('softmax=',softmax(input))
sigmoid = F.sigmoid(input)
print('sigmoid=',sigmoid)
softmax= tensor([[0.3006, 0.3322, 0.3672],
[0.3183, 0.2851, 0.3966],
[0.3693, 0.1659, 0.4648]])
sigmoid= tensor([[0.5498, 0.5744, 0.5987],
[0.4950, 0.4675, 0.5498],
[0.6225, 0.4256, 0.6748]])
loss6 = F.binary_cross_entropy(sigmoid, target1)
print(loss6)
loss7 = F.binary_cross_entropy_with_logits(input, target1)
print(loss7)
loss = nn.BCELoss(reduction='mean')
loss8 =loss(sigmoid, target1)
print(loss8)
loss =nn.BCEWithLogitsLoss()
loss9 =loss(input, target1)
print(loss9)
def binary_cross_entropyloss(prob, target, weight=None):
weight=torch.ones((3,3)) # 正样本权重
loss = -weight * (target * torch.log(prob) + (1 - target) * (torch.log(1 - prob)))
print('torch.numel(target)=',torch.numel(target)) # 元素个数9
loss = torch.sum(loss) / torch.numel(target) # 求平均
return loss
loss10=binary_cross_entropyloss(sigmoid, target1)
print(loss10)
平衡交叉熵Balanced Cross-Entropy——设置超参数
常用在语义分割任务中,处理正负样本不均衡问题,平衡正负样本(在二进制交叉熵中其实也可以设置一个参数设置正样本权重)。
blanced和focal可理解为一种思想,用在各种损失的优化上。如在-(ylogP+(1-y)log(1-P))基础上增加一个beta系数,修改为 -(BylogP+(1-B)(1-y)log(1-P))
pytorch中实现Balanced Cross-Entropy_fpan98的博客-CSDN博客
下例中将1-y/w*h作为beta,实际中也可自己设置一个超参数
input = torch.tensor([[0.2,0.3,0.4],
[-0.02,-0.13,0.2],
[0.5,-0.3,0.73]])
target2 = torch.FloatTensor([[1,0,0],
[1,1,1],
[0,1,1]])
def balanced_loss(input, target):
input = input.view(input.shape[0], -1)
target = target.view(target.shape[0], -1)
loss = 0.0
for i in range(input.shape[0]):
# 本例中beta分别为tensor(0.6667)、tensor(0.)、tensor(0.3333)
beta = 1-torch.sum(target[i])/target.shape[1] # 样本中非1的概率
print('beta=',beta)
x = torch.max(torch.log(input[i]), torch.tensor([-100.0]))
y = torch.max(torch.log(1-input[i]), torch.tensor([-100.0]))
l = -(beta*target[i] * x + (1-beta)*(1 - target[i]) * y)
print('l=',l)
loss += torch.sum(l)
return loss
loss11=balanced_loss(sigmoid, target2)
平衡交叉熵Balanced Cross-Entropy——设置正负样本比例进行在线难样本挖掘
本例中将参与损失计算的负样本限制为正样本数量的3倍,选取较难的负样本
另一篇博文中也提到了在线难样本挖掘及其代码基于【基于(基于pytorch的resnet)的fpn】的psenet_北落师门XY的博客-CSDN博客
class BalanceCrossEntropyLoss(nn.Module):
'''
Balanced cross entropy loss.
Shape:
- Input: :math:(N, 1, H, W)
- GT: :math:(N, 1, H, W), same shape as the input
- Mask: :math:(N, H, W), same spatial shape as the input
- Output: scalar.
Examples::
>>> m = nn.Sigmoid()
>>> loss = nn.BCELoss()
>>> input = torch.randn(3, requires_grad=True)
>>> target = torch.empty(3).random_(2)
>>> output = loss(m(input), target)
>>> output.backward()
'''
def __init__(self, negative_ratio=3.0, eps=1e-6):
super(BalanceCrossEntropyLoss, self).__init__()
self.negative_ratio = negative_ratio
self.eps = eps
def forward(self,
pred: torch.Tensor,
gt: torch.Tensor,
mask: torch.Tensor,
return_origin=False):
'''
Args:
pred: shape :math:(N, 1, H, W), the prediction of network
gt: shape :math:(N, 1, H, W), the target
mask: shape :math:(N, H, W), the mask indicates positive regions
'''
positive = (gt * mask).byte()
negative = ((1 - gt) * mask).byte()
positive_count = int(positive.float().sum())
negative_count = min(int(negative.float().sum()),
int(positive_count * self.negative_ratio))
loss = nn.functional.binary_cross_entropy(
pred, gt, reduction='none')[:, 0, :, :]
positive_loss = loss * positive.float()
negative_loss = loss * negative.float()
negative_loss, _ = torch.topk(negative_loss.view(-1), negative_count)
balance_loss = (positive_loss.sum() + negative_loss.sum()) /\
(positive_count + negative_count + self.eps)
if return_origin:
return balance_loss, loss
return balance_loss
Focal Loss
处理难易样本问题,根据模型输出概率P调节比重,多了一个超参数gamma
-(B((1-P)gamma)ylogP+(1-B)(Pgamma)(1-y)log(1-P))
class BCEFocalLosswithLogits(nn.Module):
def __init__(self, gamma=0.2, alpha=0.6, reduction='mean'):
super(BCEFocalLosswithLogits, self).__init__()
self.gamma = gamma
self.alpha = alpha
self.reduction = reduction
def forward(self, logits, target):
# logits: [N, H, W], target: [N, H, W]
logits = F.sigmoid(logits)
alpha = self.alpha
gamma = self.gamma
loss = - alpha * (1 - logits) ** gamma * target * torch.log(logits) - \
(1 - alpha) * logits ** gamma * (1 - target) * torch.log(1 - logits)
if self.reduction == 'mean':
loss = loss.mean()
elif self.reduction == 'sum':
loss = loss.sum()
return loss
L=BCEFocalLosswithLogits()
loss12= L(sigmoid, target2)
基于样本次数的加权
统计不同类别数量,得到该类别出现的概率p,根据1/log(a+p)得到各类别的权重,其中a为超参数用于平滑
处理样本不均衡问题的方法,样本权重的处理方法及代码_洲洲_starry的博客-CSDN博客_样本权重设置
DICE LOSS
适用于正负样本不均衡情况,常用于语义分割这种前后景像素数差异大的情况计算方式为
1-2abs(yp)/(abs(y)+abs(p)) 在实际计算中,y肯定大于等于0,p通过sigmoid后也大于等于0,代码中没有出现abs的函数
也可以参考pse那篇博文中将在线难样本挖掘(控制正负样本比例1:3)和dice loss结合的代码
def dice_loss(input, target):
input = input.contiguous().view(input.size()[0], -1)
target = target.contiguous().view(target.size()[0], -1).float()
a = torch.sum(input * target, 1)
b = torch.sum(input * input, 1) + 0.001
c = torch.sum(target * target, 1) + 0.001
d = (2 * a) / (b + c)
return 1-d
L1 loss
回归损失,不考虑方向,计算为方式为 abs(y-p)的平均值,可以理解为以y-p=0为轴对称的直线。
from torch.nn import L1Loss
loss = L1Loss()
loss13 = loss(input, target1)
print(loss13)
tmp = abs(input- target1)
loss14 = torch.sum(tmp)/torch.numel(tmp)
print(loss14)
L2 loss(均方误差)
差的平方求均值
SmoothL1Loss
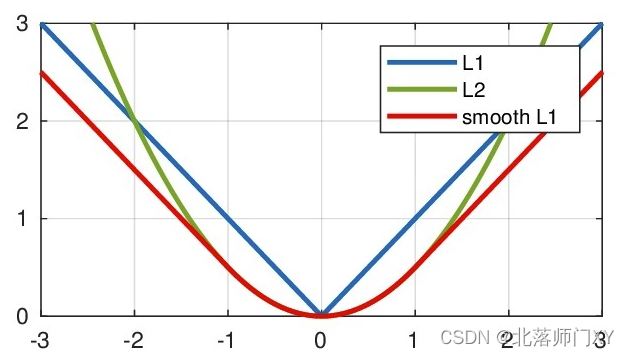

是一种综合了L1loss和L2loss的组合模式,一个平滑的分段函数,分段点是(beta,0.5*beta),小于分段点是L2曲线,大于分段点是L1直线。注意为了将2段组合起来,且拼接处可导,和真正的L1,L2稍有不同。默认参数beta为1.0,reduction为’mean’,
from torch.nn as nn
import torch
loss_fn = nn.SmoothL1Loss()
a=[1,2,3]
b=[3,1,9]
loss = loss_fn(torch.tensor(a,dtype=torch.float32), torch.tensor(b,dtype=torch.float32))
print(loss) #tensor(2.5000)
上例的计算过程为:[2,1,6]–>[1.5,0.5,5.5]—>7.5/3=2.5
回归损失函数1:L1 loss, L2 loss以及Smooth L1 Loss的对比 – Brook_icv – 博客园
loss出现nan
表现为训练一开始损失是正常减小的,后来零星出现Nan,到后来就都是Nan了。这其实就是出现了梯度爆炸现象。在各类模型、各类损失中都有可能出现这个现象。如下述博主遇到的情况:
用yolov3 VOC训练自己的数据时出现的问题及解决方法_小蜗zdh的博客-CSDN博客
ta采取的是修改学习率调整策略从而调小学习率
pytorch MultiheadAttention 出现NaN_qq_37650969的博客-CSDN博客_attention nan
ta遇到了在attention中整行被mask的情况
原因包含:
1)loss计算中除以nan
2)loss计算中log0,如二进制交叉熵计算loss = -(yln(p)+(1-y)ln(1-p))
3)softmax的输入全是负无穷,输出就是Nan
解决方法一般有:
1)交叉熵输入p加上一个很小的数限制一边范围
crossentropy(out+1e-8, target)
2)双边限制范围
q_logits = torch.clamp(q_logits, min=1e-7, max=1 – 1e-7) # 添加了截断区间
q_log_prob = torch.nn.functional.log_softmax(q_logits, dim=1)
3)调小学习率,减小震荡
4)评估损失函数是否适合任务
5)评估是否存在标注问题
我的一些nan处理经验:
1)将batch_size 调整为1,每一个batch打印一次loss,寻找loss突变的那个输入,检查对应的图像标注有没有问题,有次是标注人员不小心把某张图某个分割的mask复制了一份
2)很多人提到调小学习率,在mmdet的训练中,开源代码的提供者有N个GPU进行并行训练,但我只有1个,如果使用源码默认的学习率就太大了,出现梯度爆炸。
Q:为什么公式中没有取均值,但代码中经常需要取均值
A:实际是一个batch的样本取了平均损失,而不是对单个样本计算平均,reduction可设置为
'none', 'mean', 'sum'
Q:各类别样本不平衡有哪些处理方法
A:重采样、基于样本数量加权、balanced 设置正负样本超参数、balanced 控制正负样本比例、dice loss
推荐阅读:
pytorch学习经验(五)手动实现交叉熵损失及Focal Loss – 简书
Original: https://blog.csdn.net/weixin_41819299/article/details/122586657
Author: 北落师门XY
Title: Loss损失函数
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/666023/
转载文章受原作者版权保护。转载请注明原作者出处!