

BERT类预训练模型整理
- 1.BERT的相关内容
* - 1.1 BERT的预训练技术
– - 1.2 BERT模型的局限性
- 2. RoBERTa的相关内容
* - 2.1 RoBERTa的预训练技术
– - 3.ERNIE
* - 3.1 ERNIE的预训练技术
– - 4. SpanBERT的相关内容
* - 4.1 SpanBERT的预训练技术
– - 5. ALBERT的相关内容
* - 5.1 ALBERT中主要有三个改进方向。
– - 6. MacBERT的相关内容
* - 6.1 研究背景
- 6.2 MacBERT的预训练技术
– - 6.3 MLM的替换策略实验对比
在本帖中,小阿奇将从中文预训练模型的角度去回顾最近自然语言处理领域中代表性的预训练语言模型的技术,自己也进行一个详细的整理
1.BERT的相关内容
BERT(来自transformer的双向编码器表示)(Devlin等人,2019年)在自然语言处理研究中被证明是成功的。 BERT通过所有Transformer层左右上下文共同调节,来预训练深度双向表示。 BERT主要包括两个预训练任务:mask语言模型(MLM)和下一句预测(NSP)。
1.1 BERT的预训练技术
1.1.1 掩码机制
给定一个句子,会 随机 Mask 15%的词,然后让 BERT 来预测这些 Mask 的词。在输入侧引入[Mask]标记,会导致预训练阶段和 Fine-tuning 阶段不一致的问题,因此在论文中为了缓解这一问题,采取了如下措施:
如果某个 Token 在被选中的 15%个 Token 里,则按照下面的方式随机的执行:
80%的概率替换成[MASK],比如 my dog is hairy → my dog is [MASK]
10%的概率替换成随机的一个词,比如 my dog is hairy → my dog is apple
10%的概率替换成它本身,比如 my dog is hairy → my dog is hairy
1.1.2 NSP( Next Sentence Prediction)
预测下一句(NSP)模型通过添加 Next Sentence Prediction的预训练方法来捕捉两个句子的联系,如有A和B两个句子,B有50%的可能性是A的下一句,训练模型是为了预测B是不是A的下一句,使模型增强对上下文联系的能力。
1.2 BERT模型的局限性
1.MASK掉的字词是独立的个体,未考虑词与词之间的连贯性与整体性;对于中文预训练模型,由于中文段落词语之间具有整体连贯性,比如哈尔滨,如果单单MASK掉哈【MASK】滨,远不如三个字一起MASK掉【MASK】【MASK】【MASK】的效果好,所以BERT的单个token mask会对段落的整体性和连贯性带来一定影响;
2.MASK机制会影响预训练和微调之间的协调性,因为预训练时会出现特殊的[MASK],但是它在下游的 fine-tune 中不会出现,这就出现了预训练阶段和 fine-tune 阶段不一致的问题。
- RoBERTa的相关内容
RoBERTa (A Robustly Optimized BERT approach)模型是BERT 的改进版
2.1 RoBERTa的预训练技术
RoBERTa在BERT的基础上主要在 MLM掩码方式和 NSP下一句预测两大预训练任务上进行了改进,主要为以下几点:
2.1.1动态掩码(Dynamic Masking)
BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成 新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
2.1.2取消NSP预训练任务
数据生成方式和任务改进:取消下一个句子预测,并且数据连续从一个文档中获得。
RoBERTa通过实验发现,去掉NSP任务将会提升down-stream任务的指标,如下图所示
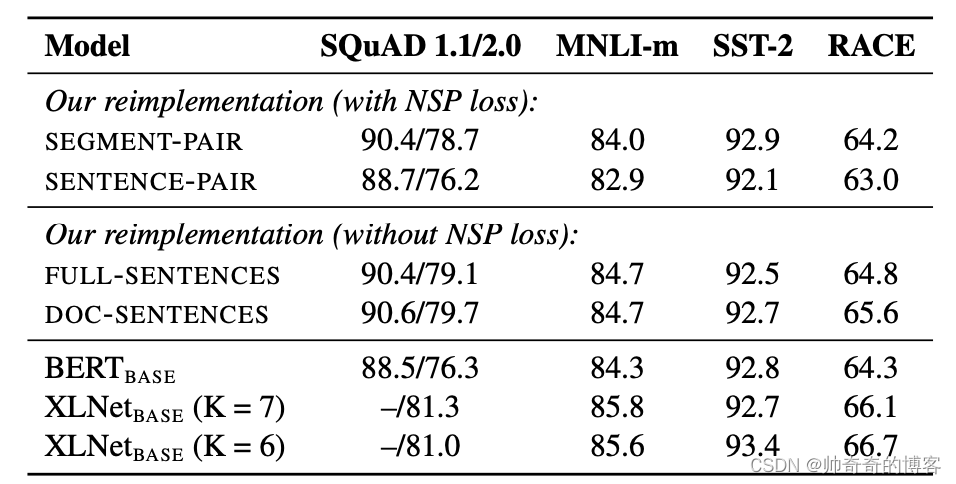

—真实句子过短,不如拼接成句子段
—无NSP任务,略好过有NSP
— 不跨文档好过跨文档
; 2.1.3 大批次(Larger Batch Size)
RoBERTa通过增加训练过程中Batch Size的大小,发现提高down-stream的指标
同时 RoBERTa也在数据大小以及训练参数training step 进行调整
3.ERNIE
ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方面,它采用了Transformer的Encoder部分作为模型主干进行训练
3.1 ERNIE的预训练技术
3.1.1 Knowledge Masking Task
ERNIE 模型通过建模海量数据中的实体概念等先验语义知识,学习真实世界的语义关系。具体来说,ERNIE 模型通过对 词、实体等语义单元的掩码,使得模型学习完整概念的语义表示。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。比如:
Learned by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
Learned by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城
在 BERT 模型中,通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
3.1.2 多个异源语料
ERNIE还采用 多个异源语料帮助模型训练,例如对话数据,新闻数据,百科数据等等。通过这些改进以保证模型在字词、语句和语义方面更深入地学习到语言知识。
- SpanBERT的相关内容
SpanBERT对Bert的改进主要体现在:
对 mask方式的改进, 丢弃NSP任务和增加SBO(Span Boundary Objective)任务
4.1 SpanBERT的预训练技术
4.1.1Span mask方案
Bert是随机mask输入序列中的字,这样能很简单地推测出字之间的搭配,这样会让本来应该有强相关的一些连在一起的字词,在训练时是割裂开来的。难以建立词中各个字之间的关联信息。
SpanBERT的做法是根据几何分布,先随机选择一段(span)的长度,之后再根据均匀分布随机选择这一段的起始位置,最后按照长度遮盖。文中使用几何分布取 p=0.2,最大长度只能是 10,利用此方案获得平均采样长度分布。
这样做的目的是:前不久的 MASS 模型,表明可能并不需要想Bert-wmm或者ERNIE那样mask,随机遮盖可能效果也很好。具体如下图所示:

; 4.1.2 加入SBO 训练目标
Span Boundary Objective 是该论文加入的新训练目标,希望被遮盖 Span 边界的词向量,能学习到 Span 的内容。具体做法是,在训练时取 Span 前后边界的两个词,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。
这样做的目的是:增强了 BERT 的性能,为了让模型让模型在一些需要 Span 的下游任务取得更好表现,特别在一些与 Span 相关的任务,如抽取式问答。
4.1.3 去除NSP任务
XLNet 中发现NSP不是必要的,而且两句拼接在一起使单句子不能俘获长距离的语义关系,所以作者剔除了NSP任务
这样做的目的是:剔除没有必要的预训练任务,并且使模型获取更长距离的语义依赖信息。
- ALBERT的相关内容
对于预训练模型,提升模型的大小是能对下游任务的效果有一定提升,然而如果进一步提升模型规模,势必会导致显存或者内存出现OOM的问题,长时间的训练也可能导致模型出现退化的情况。为此谷歌的研究者设计了「一个精简的 BERT」(A Lite BERT,ALBERT),参数量远远少于传统的 BERT 架构。
ALBERT主要对BERT做了3点改进,缩小了整体的参数量,加快了训练速度,增加了模型效果。

ALBERT也是采用和BERT一样的Transformer的encoder结果,激活函数使用的也是GELU,在讲解下面的内容前,我们规定几个参数,词的embedding我们设置为E,encoder的层数我们设置为L,hidden size即encoder的输出值的维度我们设置为H,前馈神经网络的节点数设置为4H,attention的head个数设置为H/64。
; 5.1 ALBERT中主要有三个改进方向。
5.1.1 对Embedding因式分解(Factorized embedding parameterization)
在BERT中,词embedding与encoder输出的embedding维度是一样的都是768。但是ALBERT认为,词级别的embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本生的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让H>>E,所以ALBERT的词向量的维度是小于encoder输出值维度的。
在NLP任务中,通常词典都会很大,embedding matrix的大小是E×V,如果和BERT一样让H=E,那么embedding matrix的参数量会很大,并且反向传播的过程中,更新的内容也比较稀疏。
结合上述说的两个点,ALBERT采用了一种因式分解的方法来降低参数量。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,说白了就是先经过一个维度很低的embedding matrix,然后再经过一个高维度matrix把维度变到隐藏层的空间内
5.1.2 跨层的参数共享(Cross-layer parameter sharing)
在ALBERT还提出了一种参数共享的方法,Transformer中共享参数有多种方案,只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行参数共享。
以base为例,BERT的参数是108M,而ALBERT仅有12M,但是效果的确相比BERT降低了两个点。由于其速度快的原因,我们再以BERT xlarge为参照标准其参数是1280M,假设其训练速度是1,ALBERT的xxlarge版本的训练速度是其1.2倍,并且参数也才223M,评判标准的平均值也达到了最高的88.7

; 5.1.3 句间连贯(Inter-sentence coherence loss)
BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果,例如NLI自然语言推理任务。但是后续的研究发现该任务效果并不好,主要原因是因为其任务过于简单。NSP其实包含了两个子任务,主题预测与关系一致性预测,但是主题预测相比于关系一致性预测简单太多了,并且在MLM任务中其实也有类型的效果。
在ALBERT中,为了只保留一致性任务去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。SOP因为实在同一个文档中选的,其只关注句子的顺序并没有主题方面的影响。并且SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。
5.1.4 移除dropout
除了上面提到的三个主要优化点,ALBERT的作者还发现一个很有意思的点,ALBERT在训练了100w步之后,模型依旧没有过拟合,于是乎作者果断移除了dropout,没想到对下游任务的效果竟然有一定的提升。这也是业界第一次发现dropout对大规模的预训练模型会造成负面影响。
- MacBERT的相关内容
6.1 研究背景
作者认为大多数表现最好的模型都是基于BERT及其变体,表明预训练的语言模型已成为自然语言处理领域中的新基本组件;
训练transformer-based预训练模型比较困难;要让特征强大的BERT大型模型,带有3.3亿个参数的24层transformer收敛,需要高内存的计算设备,例如TPU,这非常昂贵;
大多数的语言模型是基于英语的,很少有工作致力于提升中文语言模型的提升;
6.2 MacBERT的预训练技术
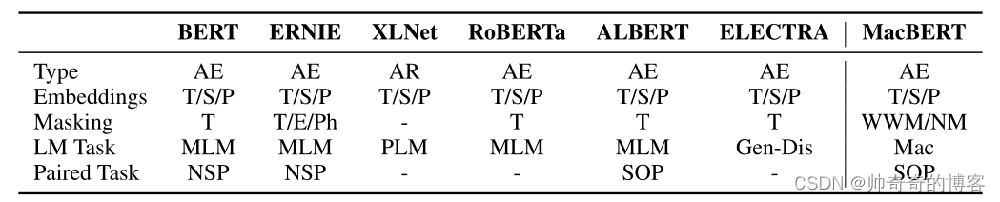
6.2.1 MLM:
使用Whole Word Masking、N-gram Masking:single token、2-gram、3-gram、4-gram分别对应比例为0.4、0.3、0.2、0.1;
由于finetuning时从未见过[MASK]token,因此使用相似的word进行替换。使用工具Synonyms toolkit 获得相似的词。如果被选中的N-gram存在相似的词,则随机选择相似的词进行替换,否则随机选择任意词替换;
对于一个输入文本,15%的词进行masking。其中80%的使用相似的词进行替换,10%使用完全随机替换,10%保持不变。
MacBERT的掩码方式如下图所示:

; 6.2.2 NSP:
采用ALBERT提出的SOP替换NSP,通过切换两个连续句子的原始顺序来创建负样本。作者在后面消融这些修改,以更好地证明每个组件的贡献。
回顾最近自然语言处理领域代表性的预训练语言模型的技术
6.3 MLM的替换策略实验对比
作者对了探究MLM掩码的最用和影响,做了以下实验:
遵循输入序列原始15%的mask比例,其中10%的mask token保持不变。 根据剩余的90%mask token,我们分为四类。
•MacBERT:将80%token替换为它们的相似词,并将10%token替换为随机词。
•随机替换:将90%token替换为随机词。
•部分 mask:原始的BERT实现,其中80%的token替换为[MASK] token,而10%的token替换为随机单词。
•所有mask:90%的token替换为[MASK] token。
在CMRC 2018和DRCD上不同的MLM任务的结果
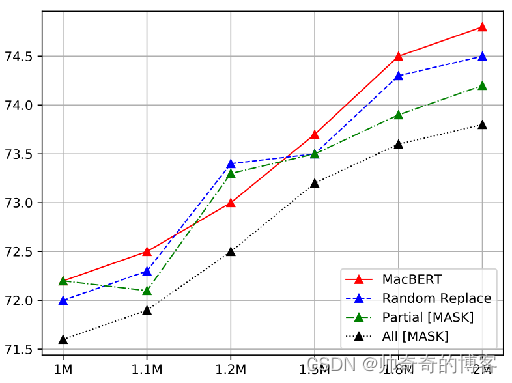
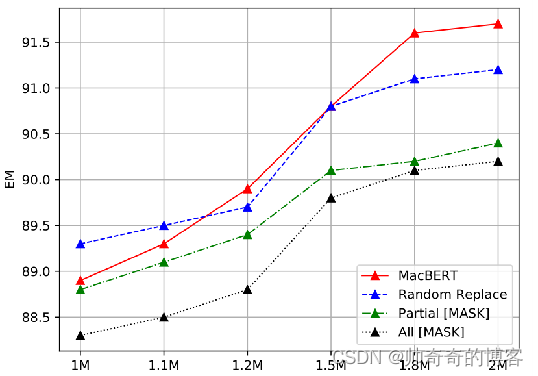
结果如图所示。预训练模型主要使用[MASK]进行masking(即部分mask和全部mask),从而导致性能较差,这表明预训练与微调是一个影响整体性能的实际问题。
Original: https://blog.csdn.net/Wwwwwww527/article/details/124739732
Author: 帅奇奇的博客
Title: 【BERT类预训练模型整理】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544547/
转载文章受原作者版权保护。转载请注明原作者出处!