

文章目录
*
–
+ 1. 数据准备
+ 2. 配置数据集
+
* 2.1 配置数据集以提高性能
* 2.2 标准化数据
+ 3. 搭建模型
+ 4. 数据增强
+ 5. 数据预测
1. 数据准备
首先导入我们需要的包:
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import pathlib
然后从网上下载数据集,本文用大约 有3,700 张鲜花照片的数据集。数据集包含五个子目录,每个子目录代表一种鲜花。

dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
在这里,我们用 pathlib.Path()函数实现路径转换。
print("未使用pathlib.Path()函数路径转换前:data_dir: {},类型为:{}".format(data_dir, type(data_dir)))
data_dir = pathlib.Path(data_dir)
print("使用pathlib.Path()函数路径转换后:data_dir: {},类型为:{}".format(data_dir, type(data_dir)))

我们来简单看一下数据:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
data_dir.glob('*/*.jpg')这个路径涵盖 flower_photos文件夹下所有图片。上述代码可以看出这个数据集的图片总数为3670。
改变一下路径,查看一个各个子目录 data_dir.glob('sunflowers/*.jpg')涵盖的图片数量:
image_count = len(list(data_dir.glob('sunflowers/*.jpg')))
print(image_count)
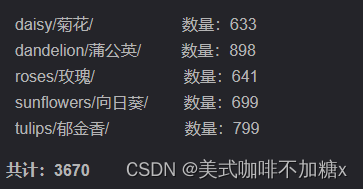
同理可得,各种花卉数据集图片的数量为:
简单展示玫瑰的照片:
roses = list(data_dir.glob('roses/*'))
img0 = PIL.Image.open(str(roses[0]))
plt.imshow(img0)
plt.show()
我们使用使用
tf.keras.utils.image_dataset_from_directory将图片数据集加载存入内存,该函数的参数可参考以下文章理解:http://www.136.la/jingpin/show-164419.html
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
print(train_ds)
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
print(val_ds)
我们可以在这些数据集的 class_names 属性中找到类名。这些对应于按字母顺序排列的目录名称。
class_names = train_ds.class_names
我们可视化一部分数据看一下,在 image_batch 和 labels_batch 张量上调用 .numpy() 可以将它们转换为 numpy.ndarray。
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()

2. 配置数据集
我们通过将这些数据集传递给模型来训练模型,我们也可以手动遍历数据集和检索一批图像。
2.1 配置数据集以提高性能
Dataset.cache()将图像在第一个epoch期间从磁盘上加载后保存在内存中。这将确保数据集在训练模型时不会成为瓶颈。如果数据集太大,无法装入内存,也可以使用此方法创建一个性能磁盘缓存。Dataset.prefetch()在训练过程中重叠数据预处理和模型执行。
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
2.2 标准化数据
对数据进行探索的时候,我们发现原始的像素值是 0-255, 为了模型训练更稳定以及更容易收敛,我们需要标准化数据集,一般来说就是把像素值缩放到 0-1,可以用下面的 layer 来实现:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
normalization_layer = tf.keras.layers.Rescaling(1./255)
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
print(np.min(first_image), np.max(first_image))
这里注意,我们在使用 tf.keras.utils.image_dataset_from_directory加载数据的时候使用 image_size参数重新定义了图片的大小。这个步骤也可以定义在模型中,通过使用 tf.keras.layers.Resizing。
3. 搭建模型
该模型由三个卷积块组成,每个卷积块(tf.keras.layers.Conv2D) 中有一个最大池层。有一个完全连接的层,上面有128个单元,由一个relu激活功能激活。这个模型还没有进行高精度的调整,目标是展示一种标准的方法。
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
用 model.summary()查看模型结构如下所示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 180, 180, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 90, 90, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 45, 45, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 22, 22, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 30976) 0
_________________________________________________________________
dense (Dense) (None, 128) 3965056
_________________________________________________________________
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
接下来,我们编译并训练上述的这个模型:
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
训练过程如下所示:
Epoch 1/10
92/92 [==============================] - 13s 132ms/step - loss: 1.3541 - accuracy: 0.4387 - val_loss: 1.0896 - val_accuracy: 0.5599
Epoch 2/10
92/92 [==============================] - 11s 124ms/step - loss: 0.9800 - accuracy: 0.6192 - val_loss: 0.9119 - val_accuracy: 0.6444
Epoch 3/10
92/92 [==============================] - 12s 127ms/step - loss: 0.8041 - accuracy: 0.6860 - val_loss: 0.8804 - val_accuracy: 0.6458
Epoch 4/10
92/92 [==============================] - 12s 127ms/step - loss: 0.5661 - accuracy: 0.7881 - val_loss: 0.8699 - val_accuracy: 0.6826
Epoch 5/10
92/92 [==============================] - 12s 128ms/step - loss: 0.3514 - accuracy: 0.8770 - val_loss: 0.9821 - val_accuracy: 0.6757
Epoch 6/10
92/92 [==============================] - 12s 127ms/step - loss: 0.1789 - accuracy: 0.9452 - val_loss: 1.1635 - val_accuracy: 0.6594
Epoch 7/10
92/92 [==============================] - 12s 127ms/step - loss: 0.0885 - accuracy: 0.9748 - val_loss: 1.3721 - val_accuracy: 0.6349
Epoch 8/10
92/92 [==============================] - 12s 127ms/step - loss: 0.0765 - accuracy: 0.9792 - val_loss: 1.4330 - val_accuracy: 0.6444
Epoch 9/10
92/92 [==============================] - 12s 128ms/step - loss: 0.0340 - accuracy: 0.9918 - val_loss: 1.6614 - val_accuracy: 0.6431
Epoch 10/10
92/92 [==============================] - 12s 128ms/step - loss: 0.0259 - accuracy: 0.9935 - val_loss: 1.7187 - val_accuracy: 0.6553
训练结果可视化及分析:
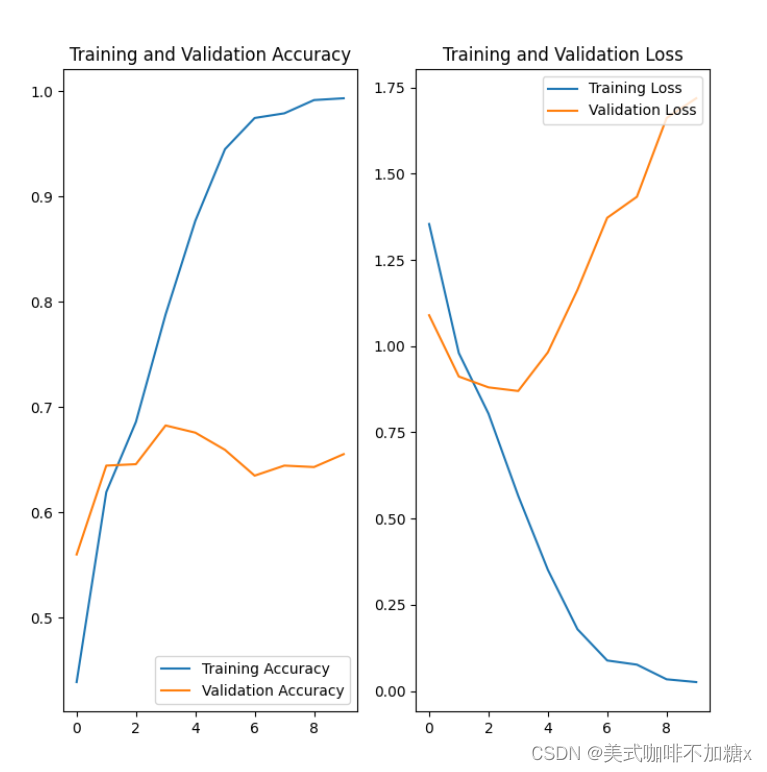
从图中可以看到,训练精度和验证精度相差很大,模型在验证集上仅实现了约60%的准确性。
让我们看看哪里出了问题,并尝试提高模型的整体性能。
在上面的图中,训练精度随时间线性增加,而验证精度在训练过程中停滞在60%左右。此外,训练和验证准确性之间的差异是明显的——这是过度拟合的迹象。
当训练样本数量很少时,模型有时会从训练样本的噪声或不需要的细节中学习,这在一定程度上会对模型在新样本上的性能产生负面影响。这种现象被称为 过拟合。这意味着模型在新的数据集中泛化时会有困难。
在训练过程中有多种方法可以对抗过拟合。 可以使用数据增强并将Dropout添加到我们的模型中。
4. 数据增强
数据增强主要用来防止过拟合,用于dataset较小的时候。
之前对神经网络有过了解的人都知道,虽然一个两层网络在理论上可以拟合所有的分布,但是并不容易学习得到。因此在实际中,我们通常会增加神经网络的深度和广度,从而让神经网络的学习能力增强,便于拟合训练数据的分布情况。在卷积神经网络中,有人实验得到,深度比广度更重要。
然而随着神经网络的加深,需要学习的参数也会随之增加,这样就会更容易导致过拟合,当数据集较小的时候,过多的参数会拟合数据集的所有特点,而非数据之间的共性。那什么是过拟合呢,之前的博客有提到,指的就是神经网络可以高度拟合训练数据的分布情况,但是对于测试数据来说准确率很低,缺乏泛化能力。
因此在这种情况下,为了防止过拟合现象,数据增强应运而生。当然除了数据增强,还有正则项/dropout等方式可以防止过拟合。那接下来讨论下常见的数据增强方法。
1)随机旋转:随机旋转一般情况下是对输入图像随机旋转[0,360)
2)随机裁剪:随机裁剪是对输入图像随机切割掉一部分
3)色彩抖动:色彩抖动指的是在颜色空间如RGB中,每个通道随机抖动一定的程度。在实际的使用中,该方法不常用,在很多场景下反而会使实验结果变差;
4)高斯噪声:是指在图像中随机加入少量的噪声。该方法对防止过拟合比较有效,这会让神经网络不能拟合输入图像的所有特征;
5)水平翻转;
6)竖直翻转;
随机裁剪/随机旋转/水平反转/竖直反转都是为了增加图像的多样性。并且在某些算法中,如faster RCNN中,自带了图像的翻转。
我们可以用以下方法来实现数据增强: tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, and tf.keras.layers.RandomZoom. 这些层可以像其他层一样包含在模型中。
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
当没有大型图像数据集时,通过对训练图像应用随机但逼真的变化来人为引入样本多样性,这有助于使模型暴露于训练数据的不同方面,同时减慢过度拟合的速度。
让我们通过对同一图像多次应用数据增强来可视化一些增强示例的外观:


我们在原来模型的基础上加上数据增强及Dropout方法:
model = Sequential([
data_augmentation,
layers.Rescaling(1. / 255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
这一次的训练我们将 epochs的值设为15。训练结果如下所示:
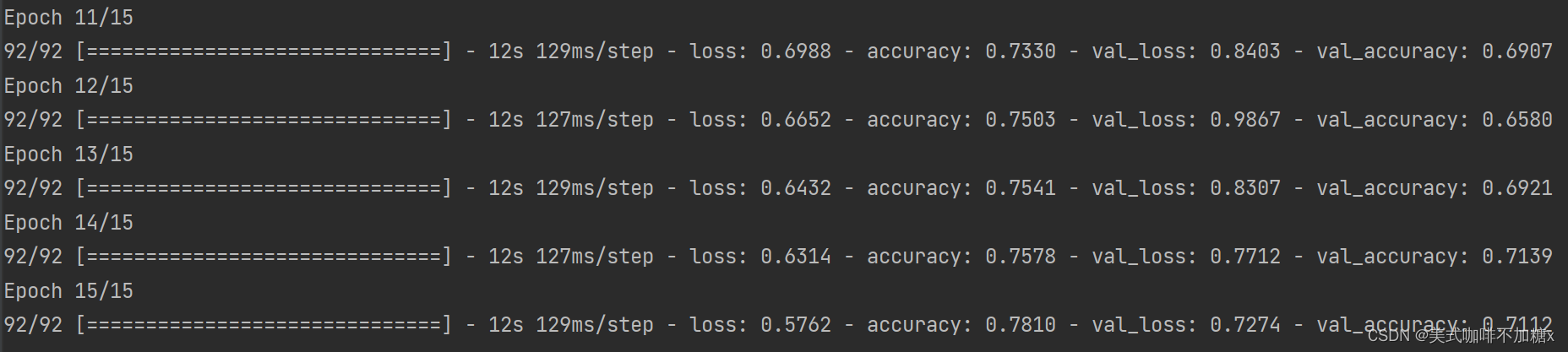
我们再一次可视化训练结果:
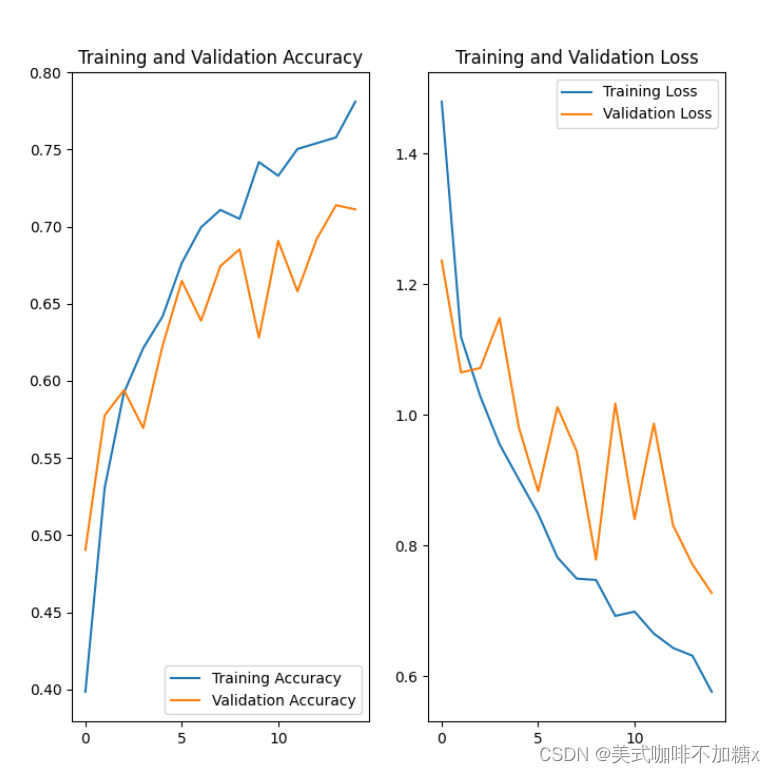
从上图我们可以看出,应用
数据增强和 tf.keras.layers.Dropout 后,过拟合明显缓和,训练和验证准确率更接近。
5. 数据预测
最后,让我们使用我们的模型对未包含在训练或验证集中的图像进行分类。

Original: https://blog.csdn.net/Serendipity_zyx/article/details/124740035
Author: 美式咖啡不加糖x
Title: 05-图像分类(含有3700张鲜花照片的数据集)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/662394/
转载文章受原作者版权保护。转载请注明原作者出处!