

可以关注博主获取代码,一般回应时长2-3小时,最迟一天内
目录
1 系统简介
我们生活中在访问一些网站和资源时,总需要在输入账号和密码之后,输入验证码进行识别。所以我们以此基点,我们想要基于机器学习做出一个识别验证码的模型来。这个模型对带有0-9数字,a-z英文小写字母,A-Z英文大写字母的混合验证码图片识别起来有很好的准确率。对该机器学习进行训练之后,我们能够对相似的验证集进行验证,验证的准确率能够达到一定的要求。
2 需求分析
设计需求:功能能够实现对带有0-9数字,a-z英文小写字母,A-Z英文大写字母的混合验证码图片进行识别。
性能:我们要求对模型配套生成的验证码图片上的识别准确率较高(70以上)又不至于到达过拟合的程度。
对软硬件平台的要求:
硬件: GPU-GTX 2060Ti
软件:python 3.7.9
IDE:pycharm
windows11
Cuda 10.0
Opencv
Tensorflow
windows10/11
其中,Opencv:图像处理 ; Tensorflow:深度学习运算库; NVIDIA CUDA 深层神经网络库(cuDNN)是一个 GPU 加速的深层神经网络原语库
3.基本原理
3.1生成图像
调用captcha自动生成验证码图片。其中验证码的大小为60*100,其中有4个字符,包含数字和大小写字母。
3.2图像处理
1.转换大小:图片的大小格式标准化处理。使用python对产生的验证码图片进行标准化处理,使图像的尺寸保持一致方便图像顺利进入机器学习的’黑箱子’,产生标准的向量。
2.转灰度图:将三通道的rgb验证码图片降维为灰度图。
3.二值化:将灰度图变为只有全黑和全白的图片。
4.降维:将图片矩阵变为一维向量。
3.3卷积神经网络
3.2.1卷积神经网络构成
与其他神经网络相同,CNN网络同样也包含输入层、隐藏层、输出层几大部分,卷积神经网络的主要运算过程如图所示。
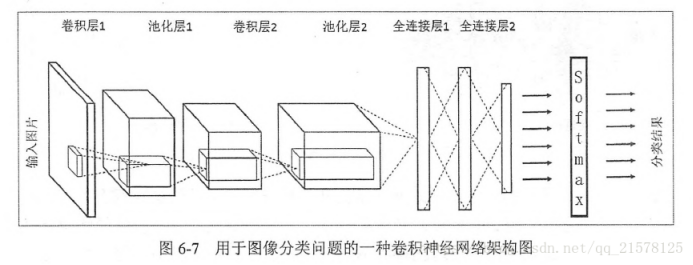

卷积层:卷积层由多个卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算主要为了提取图像的特征,随着卷积层的增加,多层网络可以提取更为复杂的图像特征。
线性整流:主要指的是激活函数运算使用线性整流的ReLu函数
池化层:在卷积之后图像的维度特征依然很多,将特征矩阵分割成几个单个区块,取其最大值或平均值,起到了降维的作用。
全连接层:把所有局部特征以及各通道的特征矩阵结合变为向量代表,计算最后每一类的得分。
3.2.2卷积神经网络的具体工作过程
(1)数据规则化
彩色图像的输入通常先要分解为RGB三个通道,其中每个值介于0~255之间。
(2)卷积运算(Convolution)
前面讲到,由于普通的神经网络对于输入与隐层采用全连接的方式进行特征提取,在处理图像时,稍微大一些的图将会导致计算量巨大而变得十分缓慢。卷积运算正是为了解决这一问题,每个隐含单元只能连接输入单元的一部分,我们可以理解为是一种特征的提取方法。
首先我们来明确几个基础概念:深度(depth)、步长(stride)、补零(zero-padding)、卷积核(convolution kernel)。
深度(depth):深度指的是图的深度与它控制输出单元的深度,也表示为连接同一块区域的神经元个数。
步幅(stride):用来描述卷积核移动的步长。
补零(zero-padding):通过对图片边缘补零来填充图片边缘,从而控制输出单元的空间大小。
卷积核(convolution kernel):在输出图像中每一个像素是输入图像中一个小区域中像素的加权平均的权值函数。卷积核可以有多个,卷积核参数可以通过误差反向传播来进行训练。
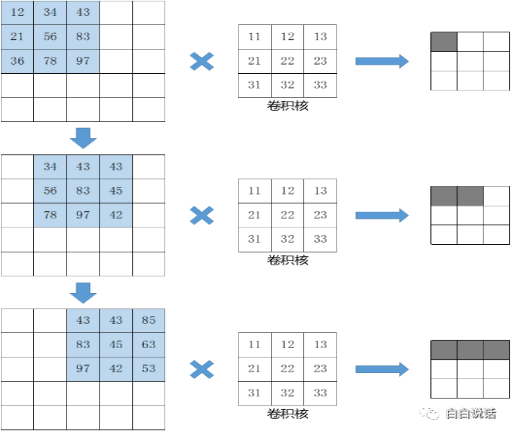
如图4-25为步长=1的卷积计算过程,卷积核依次向右移动进行卷积运算得到相应结果。
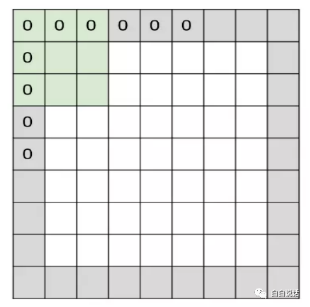
为图像计算可以对边缘进行补零,可见这个过程改变了图像的运算大小,如上图所示。
卷积运算的过程其实非常简单,过程如图4-27描述,可以概括为公式(4.3.6)。其中B代表卷积后的结果,K是卷积核,A为图像的输入矩阵。
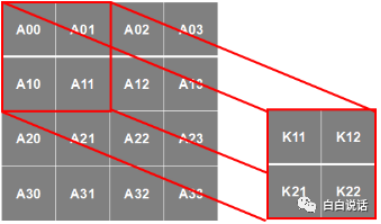
如上图所示,可见卷积核K为2*2的卷积核,详细运算过程如下。
全部图像卷积运算可以通过公式进行。
(3)激活
CNN卷积神经网络在卷积后需要经过激活过程,当前通常使用的激活函数是Relu函数。Relu函数的主要特点在之前的章节已经讲过。从函数的图像上来看,单侧抑制,相对宽阔的兴奋边界,具有稀疏激活性的特点。
(4)池化
池化的目的是提取特征,减少向下一个阶段传递的数据量。池化操作相对于对每个深度切片是独立,池化规模一般为像素的 2*2,与卷积运算相比,池化层运算一般有以下几种:
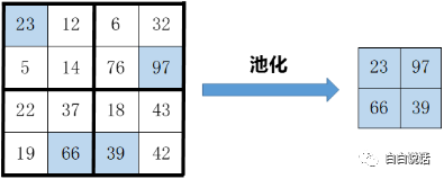
最大池化(Max Pooling):取4个点数值的最大值。这是最常用的池化算法。
均值池化(Mean Pooling):取4个点数值的均值。
高斯池化(Gauss Pooling):按照高斯模糊的方法。
如图4-28,描述了最大池化的计算方法。
(5)全连接
全连接层一般出现最后几步,在卷积神经网络中起到”分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的”分布式特征表示”映射到样本标记空间的作用。全连接过程是对矩阵的展开过程,也可以理解为输出矩阵与一个11的卷积核进行卷积运算,最后展开为一个1n的向量。
在卷积神经网络中,全连接层一般使用Softmax函数来进行分类。Softmax函数适用于数据分类,用于保证每个分类概率总和为1。
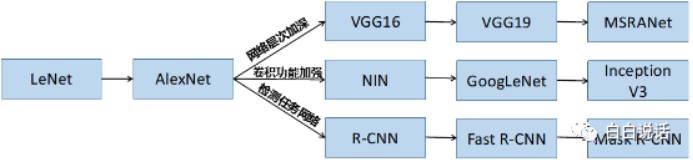
卷积神经网络的计算过程虽然讲解繁琐,但对于了解深刻理解神经网络算法非常有益。卷积神经网络经过近30年的发展拥有多条网络发展分支,并且持续高速发展之中。其中有网络层数加深的VGG16与VGG19等,有卷积模块增强的NIN网络等,从分类任务向目标检测任务过度的新型网络R-CNN等,下图展示了卷积神经网络的不同发展分支。
4 方案设计
因为卷积神经网络CNN对验证码等图像有着很好的效果,图片甚至不需要过多前端处理就可以获得很好的效果,所以我们采用CNN作为模型来识别验证码。
下面是我们为什么采用CNN 的原因:
1.能够将大数据量的图片有效的降维成小数据量(并不影响结果)
2.能够保留图片的特征,类似人类的视觉原理
3.原理较易理解,可以进行拓展和变换。
下面是我们以CNN为中心整个项目的大体框架以及实现的大体思路

自动生成验证码:我们准备使用现有的captcha自动生成。
对验证码进行分类:合理设置分类的比例,以便达到模型很好的效果 。
图像处理:基于常规的过程,经历大小标准化和图像RGB转为灰度图,变成单通道等过程,还有对灰度图的二值化处理,这个我们直接使用的OPENCV。
C NN 的模型训练及硬件考虑:调用现有的tensorflow库,利用现有的卷积层,激活函数,池化和损失函数等。我们小组使用RTX2060进行训练,其显存只有6GB,所以训练过程中每次训练的图片最终敲定为300张,刚好占据5.7GB显存。
模型测试:直接调用训练好的模型的chickpoint文件,通过tensorflow内部函数加载模型具体信息后进行识别。同时一次识别100张图片,统计其正确率和识别时间。对模型的预测能力和判断速度进行评估。
5 详细设计
1.验证码自动生成和分类
这个是直接进行库的调用,直接自己设置图片的合适和内容的参数,自动生成设置保存的文件夹。
验证码在生成之后进行类别的划分,分别存储到不同的文件夹下。
2.验证码图像处理
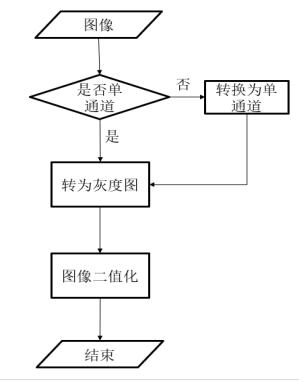
本节进行图像的预处理。在传统的图像处理和机器学习算法中,我们往往需要进行图像的预处理、分割、剪裁、滤波降噪、颜色分离和旋转等操作。使用这些方法往往对使用者的数学基础和编程能力有渐高的要求,而且普适性相对较低。我们采用卷积神经网络算法(CNN)不需要对图像进行太多的处理,只需要进行预处理(转为灰度图、图像二值化)过程,就可以实现大部分静态字符型验证码的识别,正确率也往往较高。
3.卷积神经网络模型训练


我们采用三层卷积和两层全连接,具体信息如下:
输入图片大小为60×100×1。
第一层卷积设置了32个滤波器,每个滤波器的大小为3×3×1,步长为1。输出60×160×32。
第一层池化,大小2×2,步长为2。输出30×80×32。
第二层卷积设置了64个滤波器,每个滤波器的大小为3×3×32,步长为1。输出30×80×64。
第二层池化,大小2×2,步长为2。输出15×40×64。
第三层卷积设置了128个滤波器,每个滤波器的大小为3×3×64,步长为1。输出15×40×64。
第三层池化,大小2×2,步长为2。输出8×20×64。
池化后的输出接全连接层。全连接层设置了1024个神经元。最后在接一个全连接层输出。
我们训练卷积核采用梯度下降法:

其中我们的学习率设置为0.0001,因为考虑到大的学习率会错过最优解的范围,考虑到 硬件训练速度较快所以我们选择较小的学习率用训练时间来换训练效果。
池化层采用 最大值池化的 方法,窗口大小为:[1, 2, 2, 1]。
激活函数为:
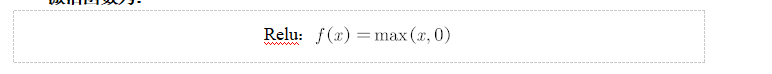
损失函数我们采用如下的库函数计算:

4.卷积神经网络测试和验证
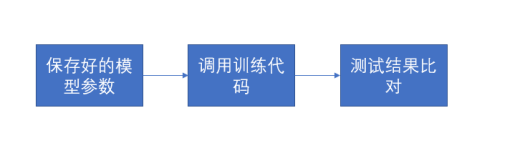
直接调用训练好的模型的chickpoint文件,通过tensorflow内部函数加载模型具体信息后进行识别。同时一次识别100张图片,统计其正确率和识别时间。对模型的预测能力和判断速度进行评估。
6 系统实现
开发环境
Pycharm
Cudnn
Python 3.7.9
Cuda 10.0
Opencv
RTX 2060
Tensorflow 1.15
代码源文件及其介绍
change_size.py
改变图片大小
gen_sample_by_captcha.py
获得样本验证码
t_batch.py
验证神经网络
train_model.py
训练神经网络
verify_and_split_data.py
样本验证码分为训练集和测试集
captcha_config.json
获取样本验证码的配置文件
sample_config.json
相关训练参数配置文件
network.py
CNN神经网络模块
代码之间的调用关系如下图所示:
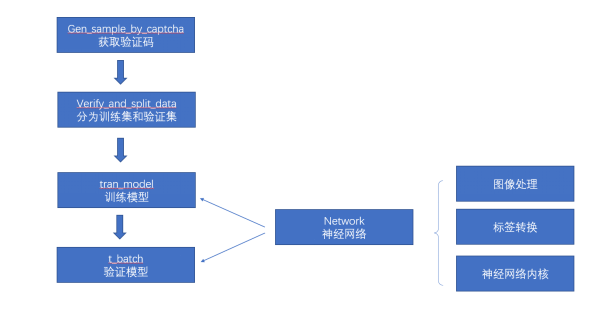
代码之间的结构关系,主要就是利用现有的这个库进行撰写。
7 测试及评估结果
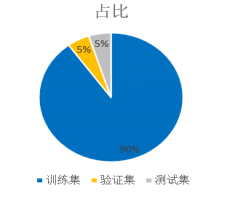
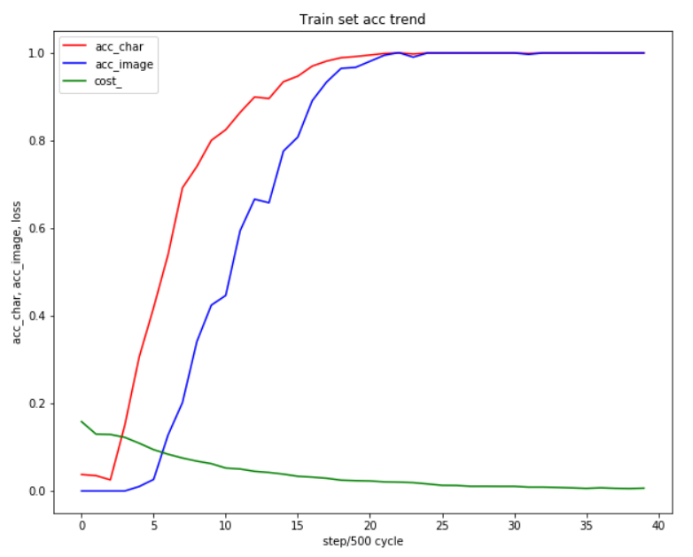
最开始我们小组对小写字母的方案进行训练,发现50000张训练集已经足够训练到较好的效果。但是当加入大写字母之后,相同训练集的情况下正确率只有50左右,所以我们又增加了50000张训练集进行训练,才得到与小写模型相同的效果。从中可以看出特征越复杂的预测对于训练集的数量要求就越高。
我们在测试集中,分为了两种方式含有大写字母和不含大写字母,分别批量测试了100张图片,在包含大写字母的情况下,正确率为70/100;在不包含大写字母的情况下,正确率为73/100。总体来看,测试效果不错,准确率较高。

部分图像验证:

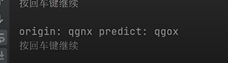
第一组:qgnx


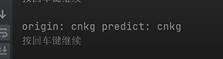
第二组:luwz

但是利用爬虫程序识别网络上的验证码效果不是很好,我们分析原因是:数据集需要重新寻找(从网络上收集各种各样的)。
8 总结
在这个课程设计当中,我们感觉我们遇到的最大的困难就是给我们的机器学习CNN模型代码配置环境还有参数的调整,在这个过程当中,我们一开始没有考虑到tensorflow这个包的更新设置,以前的函数在现在tensorflow2.0版本无法正常运行,我们就在网上查询资料,寻找解决方法。在参数调整方面,我们设置卷积核大小经过几次测试采取的比较好的效果。
一开始使用tensorflow-cpu速度太慢,我们就寻求加入GPU部分,提高模型训练的速度。为了适配和调用电脑的GPU,我们查资料下载学习CUDA和Cudnn来解决问题。
在深刻理解神经网络的原理上也花费了很大的功夫,在不同的神经网络模型之间进行对比,对比分析特征。
对于识别网络中的验证码,还有一定的提升空间,因为网络上的验证码各种各样,模型肯定要对网络上各式各样的验证码这个数据集进行重新训练,重新获得特征矩阵,才能取得比较好的效果
9.项目代码
1.train.py
import json
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import time
from PIL import Image
import random
import os
from cnnlib.network import CNN
class TrainError(Exception):
pass
class TrainModel(CNN):
def __init__(self, train_img_path, verify_img_path, char_set, model_save_dir, cycle_stop, acc_stop, cycle_save,
image_suffix, train_batch_size, test_batch_size, verify=False):
# 训练相关参数
self.cycle_stop = cycle_stop
self.acc_stop = acc_stop
self.cycle_save = cycle_save
self.train_batch_size = train_batch_size
self.test_batch_size = test_batch_size
self.image_suffix = image_suffix
char_set = [str(i) for i in char_set]
# 打乱文件顺序+校验图片格式
self.train_img_path = train_img_path
self.train_images_list = os.listdir(train_img_path)
# 校验格式
if verify:
self.confirm_image_suffix()
# 打乱文件顺序
random.seed(time.time())
random.shuffle(self.train_images_list)
# 验证集文件
self.verify_img_path = verify_img_path
self.verify_images_list = os.listdir(verify_img_path)
# 获得图片宽高和字符长度基本信息
label, captcha_array = self.gen_captcha_text_image(train_img_path, self.train_images_list[0])
captcha_shape = captcha_array.shape
captcha_shape_len = len(captcha_shape)
if captcha_shape_len == 3:
image_height, image_width, channel = captcha_shape
self.channel = channel
elif captcha_shape_len == 2:
image_height, image_width = captcha_shape
else:
raise TrainError("图片转换为矩阵时出错,请检查图片格式")
# 初始化变量
super(TrainModel, self).__init__(image_height, image_width, len(label), char_set, model_save_dir)
# 相关信息打印
print("-->图片尺寸: {} X {}".format(image_height, image_width))
print("-->验证码长度: {}".format(self.max_captcha))
print("-->验证码共{}类 {}".format(self.char_set_len, char_set))
print("-->使用测试集为 {}".format(train_img_path))
print("-->使验证集为 {}".format(verify_img_path))
# test model input and output
print(">>> Start model test")
batch_x, batch_y = self.get_batch(0, size=100)
print(">>> input batch images shape: {}".format(batch_x.shape))
print(">>> input batch labels shape: {}".format(batch_y.shape))
@staticmethod
def gen_captcha_text_image(img_path, img_name):
"""
返回一个验证码的array形式和对应的字符串标签
:return:tuple (str, numpy.array)
"""
# 标签
label = img_name.split("_")[0]
# 文件
img_file = os.path.join(img_path, img_name)
captcha_image = Image.open(img_file)
captcha_array = np.array(captcha_image) # 向量化
return label, captcha_array
def get_batch(self, n, size=300):
batch_x = np.zeros([size, self.image_height * self.image_width]) # 初始化
batch_y = np.zeros([size, self.max_captcha * self.char_set_len]) # 初始化
max_batch = int(len(self.train_images_list) / size)
# print(max_batch)
if max_batch - 1 < 0:
raise TrainError("训练集图片数量需要大于每批次训练的图片数量")
if n > max_batch - 1:
n = n % max_batch
s = n * size
e = (n + 1) * size
this_batch = self.train_images_list[s:e]
# print("{}:{}".format(s, e))
for i, img_name in enumerate(this_batch):
label, image_array = self.gen_captcha_text_image(self.train_img_path, img_name)
image_array = self.convert2gray(image_array) # 灰度化图片
batch_x[i, :] = image_array.flatten() / 255 # flatten 转为一维
batch_y[i, :] = self.text2vec(label) # 生成 oneHot
return batch_x, batch_y
def get_verify_batch(self, size=100):
batch_x = np.zeros([size, self.image_height * self.image_width]) # 初始化
batch_y = np.zeros([size, self.max_captcha * self.char_set_len]) # 初始化
verify_images = []
for i in range(size):
verify_images.append(random.choice(self.verify_images_list))
for i, img_name in enumerate(verify_images):
label, image_array = self.gen_captcha_text_image(self.verify_img_path, img_name)
image_array = self.convert2gray(image_array) # 灰度化图片
batch_x[i, :] = image_array.flatten() / 255 # flatten 转为一维
batch_y[i, :] = self.text2vec(label) # 生成 oneHot
return batch_x, batch_y
def confirm_image_suffix(self):
# 在训练前校验所有文件格式
print("开始校验所有图片后缀")
for index, img_name in enumerate(self.train_images_list):
print("{} image pass".format(index), end='\r')
if not img_name.endswith(self.image_suffix):
raise TrainError('confirm images suffix:you request [.{}] file but get file [{}]'
.format(self.image_suffix, img_name))
print("所有图片格式校验通过")
def train_cnn(self):
y_predict = self.model()
print(">>> input batch predict shape: {}".format(y_predict.shape))
print(">>> End model test")
# 计算概率 损失
with tf.name_scope('cost'):
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=y_predict, labels=self.Y))
# 梯度下降
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(cost)
# 计算准确率
predict = tf.reshape(y_predict, [-1, self.max_captcha, self.char_set_len]) # 预测结果
max_idx_p = tf.argmax(predict, 2) # 预测结果
max_idx_l = tf.argmax(tf.reshape(self.Y, [-1, self.max_captcha, self.char_set_len]), 2) # 标签
# 计算准确率
correct_pred = tf.equal(max_idx_p, max_idx_l)
with tf.name_scope('char_acc'):
accuracy_char_count = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.name_scope('image_acc'):
accuracy_image_count = tf.reduce_mean(tf.reduce_min(tf.cast(correct_pred, tf.float32), axis=1))
# 模型保存对象
saver = tf.train.Saver()
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
# 恢复模型
if os.path.exists(self.model_save_dir):
try:
saver.restore(sess, self.model_save_dir)
# 判断捕获model文件夹中没有模型文件的错误
except ValueError:
print("model文件夹为空,将创建新模型")
else:
pass
# 写入日志
tf.summary.FileWriter("logs/", sess.graph)
step = 1
for i in range(self.cycle_stop):
batch_x, batch_y = self.get_batch(i, size=self.train_batch_size)
# 梯度下降训练
_, cost_ = sess.run([optimizer, cost],
feed_dict={self.X: batch_x, self.Y: batch_y, self.keep_prob: 0.6})
if step % 10 == 0:
# 基于训练集的测试
batch_x_test, batch_y_test = self.get_batch(i, size=self.train_batch_size)
acc_char = sess.run(accuracy_char_count, feed_dict={self.X: batch_x_test, self.Y: batch_y_test, self.keep_prob: 1.})
acc_image = sess.run(accuracy_image_count, feed_dict={self.X: batch_x_test, self.Y: batch_y_test, self.keep_prob: 1.})
print("第{}次训练 >>> ".format(step))
print("[训练集] 字符准确率为 {:.5f} 图片准确率为 {:.5f} >>> loss {:.10f}".format(acc_char, acc_image, cost_))
# with open("loss_train.csv", "a+") as f:
# f.write("{},{},{},{}\n".format(step, acc_char, acc_image, cost_))
# 基于验证集的测试
batch_x_verify, batch_y_verify = self.get_verify_batch(size=self.test_batch_size)
acc_char = sess.run(accuracy_char_count, feed_dict={self.X: batch_x_verify, self.Y: batch_y_verify, self.keep_prob: 1.})
acc_image = sess.run(accuracy_image_count, feed_dict={self.X: batch_x_verify, self.Y: batch_y_verify, self.keep_prob: 1.})
print("[验证集] 字符准确率为 {:.5f} 图片准确率为 {:.5f} >>> loss {:.10f}".format(acc_char, acc_image, cost_))
# with open("loss_test.csv", "a+") as f:
# f.write("{}, {},{},{}\n".format(step, acc_char, acc_image, cost_))
# 准确率达到99%后保存并停止
if acc_image > self.acc_stop:
saver.save(sess, self.model_save_dir)
print("验证集准确率达到99%,保存模型成功")
break
# 每训练500轮就保存一次
if i % self.cycle_save == 0:
saver.save(sess, self.model_save_dir)
print("定时保存模型成功")
step += 1
saver.save(sess, self.model_save_dir)
def recognize_captcha(self):
label, captcha_array = self.gen_captcha_text_image(self.train_img_path, random.choice(self.train_images_list))
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9, "origin:" + label, ha='center', va='center', transform=ax.transAxes)
plt.imshow(captcha_array)
# 预测图片
image = self.convert2gray(captcha_array)
image = image.flatten() / 255
y_predict = self.model()
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, self.model_save_dir)
predict = tf.argmax(tf.reshape(y_predict, [-1, self.max_captcha, self.char_set_len]), 2)
text_list = sess.run(predict, feed_dict={self.X: [image], self.keep_prob: 1.})
predict_text = text_list[0].tolist()
print("正确: {} 预测: {}".format(label, predict_text))
# 显示图片和预测结果
p_text = ""
for p in predict_text:
p_text += str(self.char_set[p])
print(p_text)
plt.text(20, 1, 'predict:{}'.format(p_text))
plt.show()
def main():
with open("conf/sample_config.json", "r") as f:
sample_conf = json.load(f)
train_image_dir = sample_conf["train_image_dir"]
verify_image_dir = sample_conf["test_image_dir"]
model_save_dir = sample_conf["model_save_dir"]
cycle_stop = sample_conf["cycle_stop"]
acc_stop = sample_conf["acc_stop"]
cycle_save = sample_conf["cycle_save"]
enable_gpu = sample_conf["enable_gpu"]
image_suffix = sample_conf['image_suffix']
use_labels_json_file = sample_conf['use_labels_json_file']
train_batch_size = sample_conf['train_batch_size']
test_batch_size = sample_conf['test_batch_size']
if use_labels_json_file:
with open("tools/labels.json", "r") as f:
char_set = f.read().strip()
else:
char_set = sample_conf["char_set"]
if not enable_gpu:
# 设置以下环境变量可开启CPU识别
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
tm = TrainModel(train_image_dir, verify_image_dir, char_set, model_save_dir, cycle_stop, acc_stop, cycle_save,
image_suffix, train_batch_size, test_batch_size, verify=False)
tm.train_cnn() # 开始训练模型
# tm.recognize_captcha() # 识别图片示例
if __name__ == '__main__':
main()
2.其余代码私聊博主获取( 先关注 )
回复时长看文章开头
Original: https://blog.csdn.net/weixin_53284122/article/details/124073487
Author: 一个编程的菜鸡
Title: 机器学习-基于卷积神经网络验证码的识别(python实现)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/623109/
转载文章受原作者版权保护。转载请注明原作者出处!