

最近,报了一个俱乐部,第一节课的作业是对数据进行处理,查看异常值以及重复值,并研究气象参数与pm2.5的关系。
一.数据内容及任务
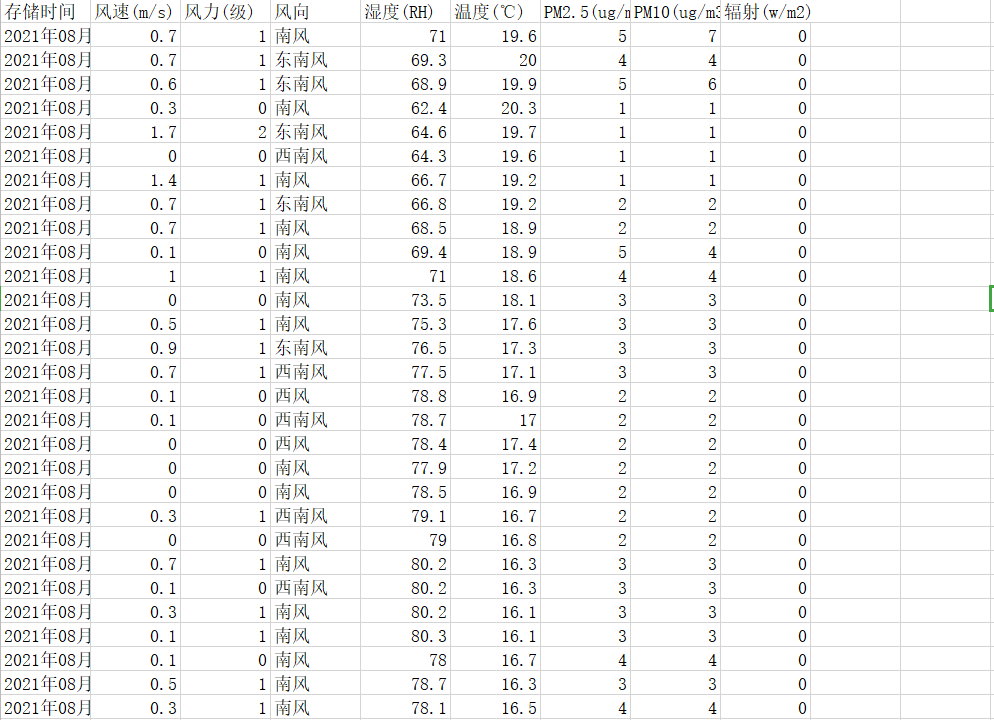
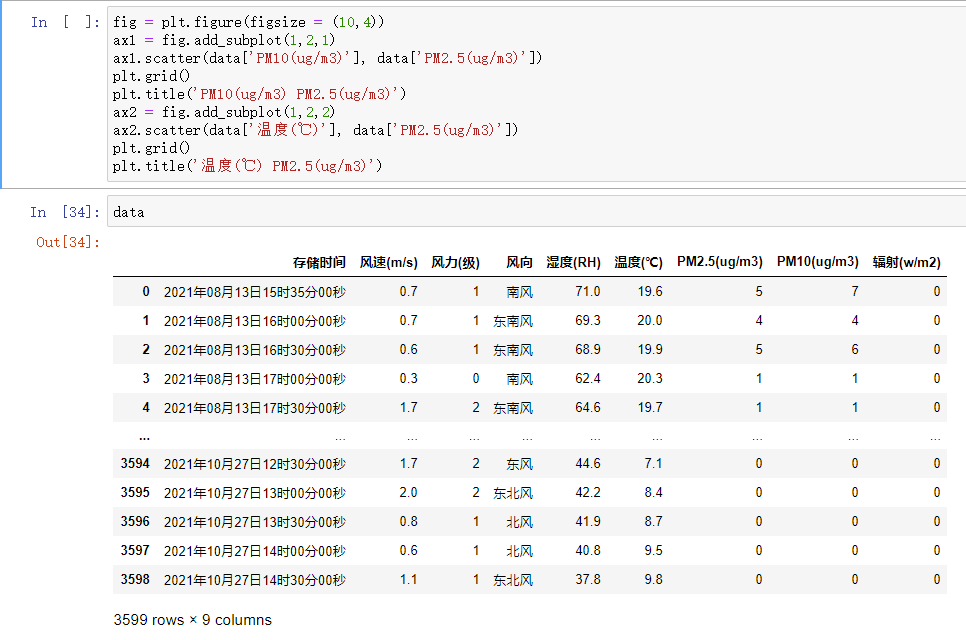
本次待处理的数据比较简单,首先看一下具体的数据内容:
分为以下几个维度:时间、风力、风向、湿度等,接下来我们对数据进行导入而后处理。

二.数据处理
包的导入
import pandas as pd
import missingno as msno
import matplotlib.pyplot as plt
文字规格
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #这两行需要手动设置
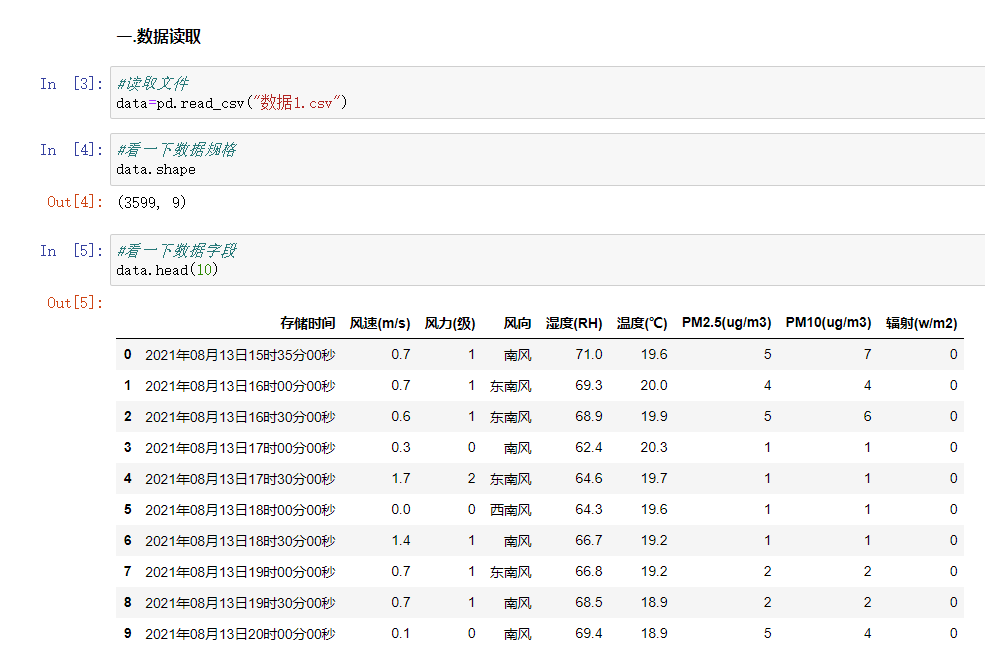
(一)数据读取
#读取文件
data=pd.read_csv("数据1.csv")
#看一下数据规格
data.shape
#看一下数据字段
data.head(10)
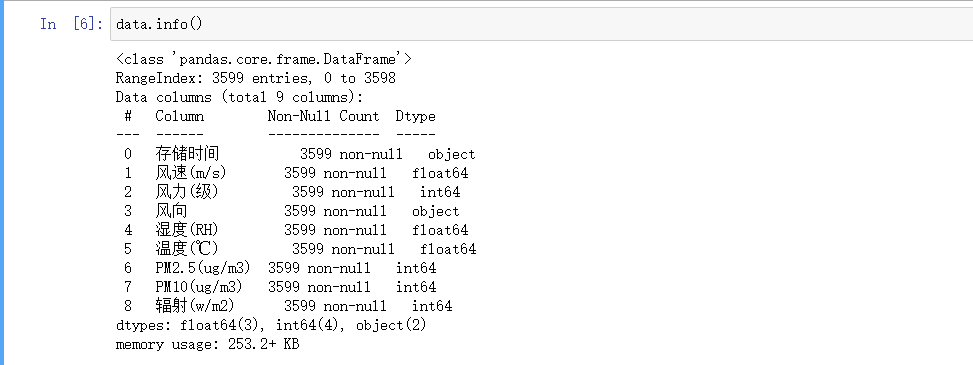
data.info()
(二)数据简单分析处理
1.缺失值
首先对缺失率进行可视化观察一下
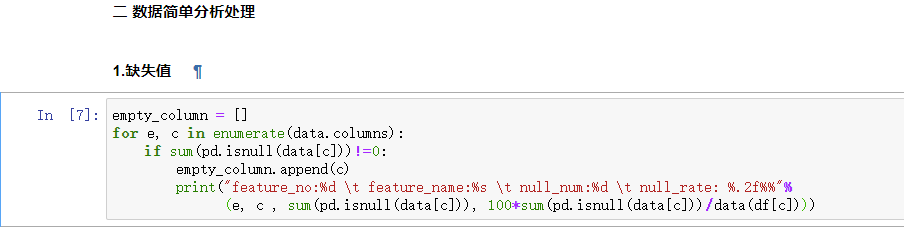
empty_column = []
for e, c in enumerate(data.columns):
if sum(pd.isnull(data[c]))!=0:
empty_column.append(c)
print("feature_no:%d \t feature_name:%s \t null_num:%d \t null_rate: %.2f%%"%
(e, c , sum(pd.isnull(data[c])), 100*sum(pd.isnull(data[c]))/data(df[c])))
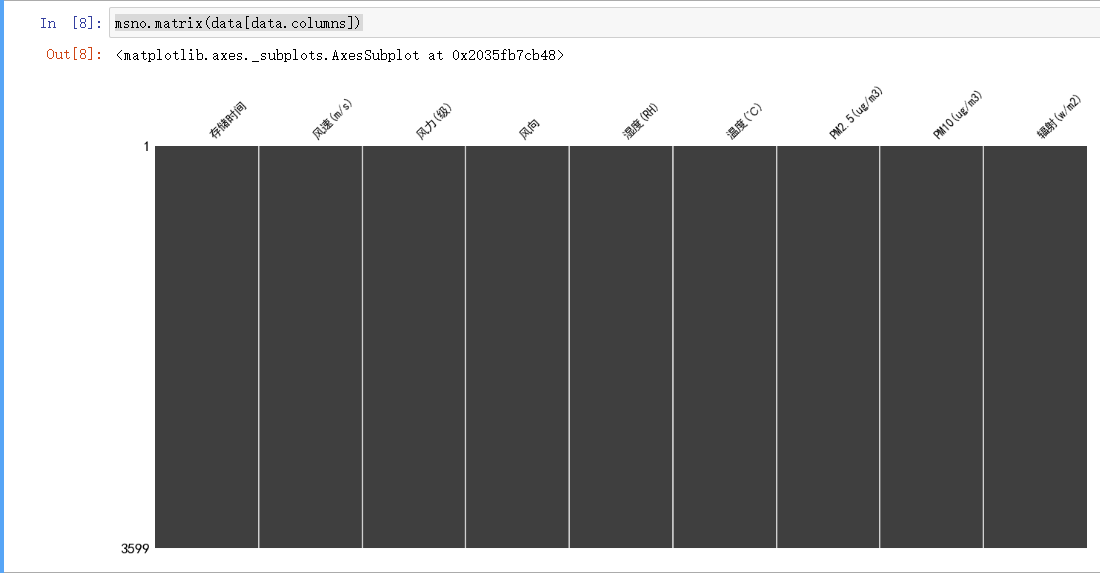
msno.matrix(data[data.columns])
看一下缺失率

缺失率
def missing_data(data):
total = data.isnull().sum().sort_values(ascending = True)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
return pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data(data[data.columns])
惊呆了老铁,这次的数据没有缺失(在这里我都怀疑老师是不是数据给错了)。
2.重复数据
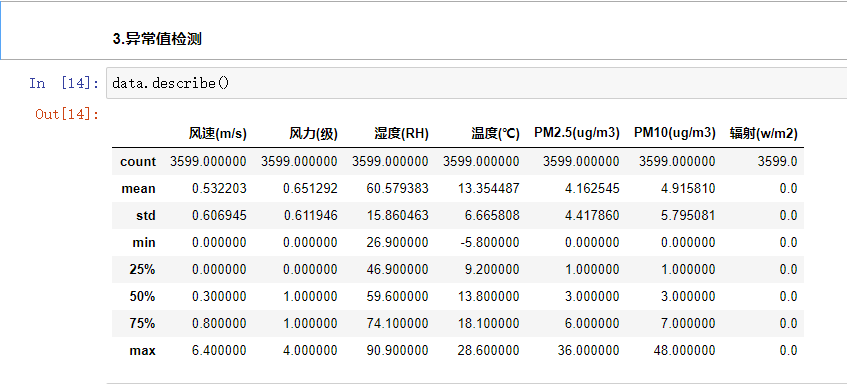
3.异常值检测


plt.subplot(1,2,1)
plt.boxplot(data["湿度(RH)"])
plt.title("湿度(RH)")
plt.subplot(1,2,2)
plt.boxplot(data["风速(m/s)"])
plt.title("风速(m/s)")
plt.show()
plt.subplot(1,3,1)
plt.boxplot(data["温度(℃)"])
plt.title("温度(℃)")
plt.subplot(1,3,2)
plt.boxplot(data["PM2.5(ug/m3)"])
plt.title("PM2.5(ug/m3)")
plt.subplot(1,3,3)
plt.boxplot(data["PM10(ug/m3)"])
plt.title("PM10(ug/m3)")
plt.show()
(三).数据分析


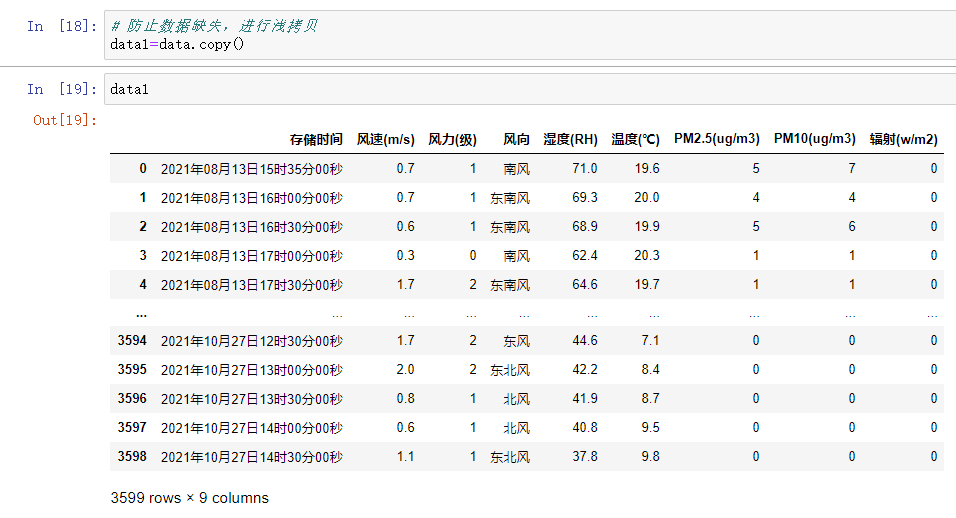



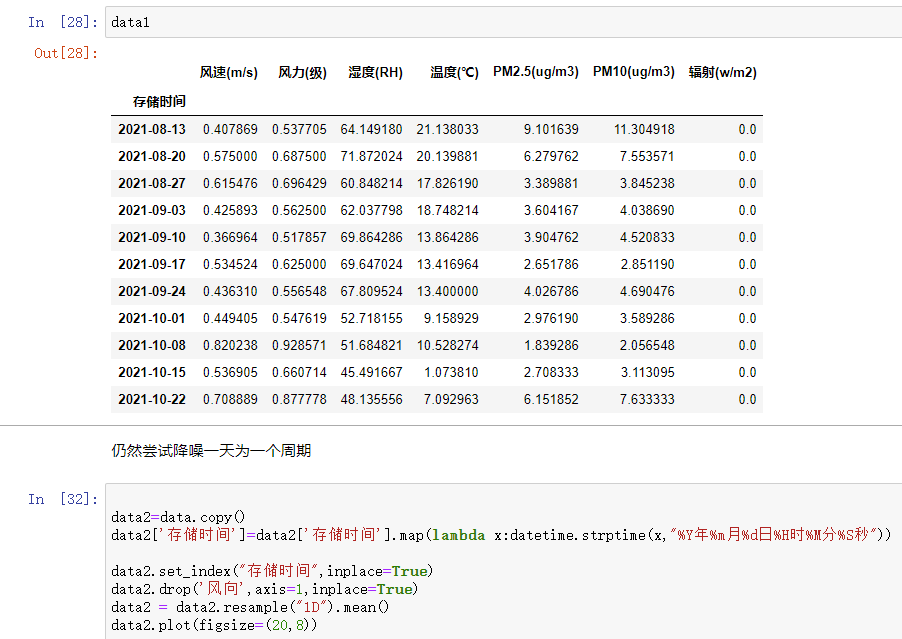
分析可得时间的颗粒度太细,我们需要对时间进行压缩来进一步对数据进行观察。


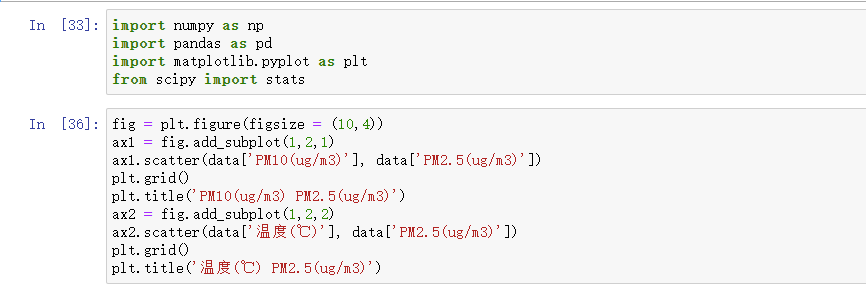


Pearson相关系数
相关系数的绝对值越大,相关性越强:相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数绝对值 :
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
采用Pearson相关系数检验相关性时,应先检验数据是否服从正态分布:

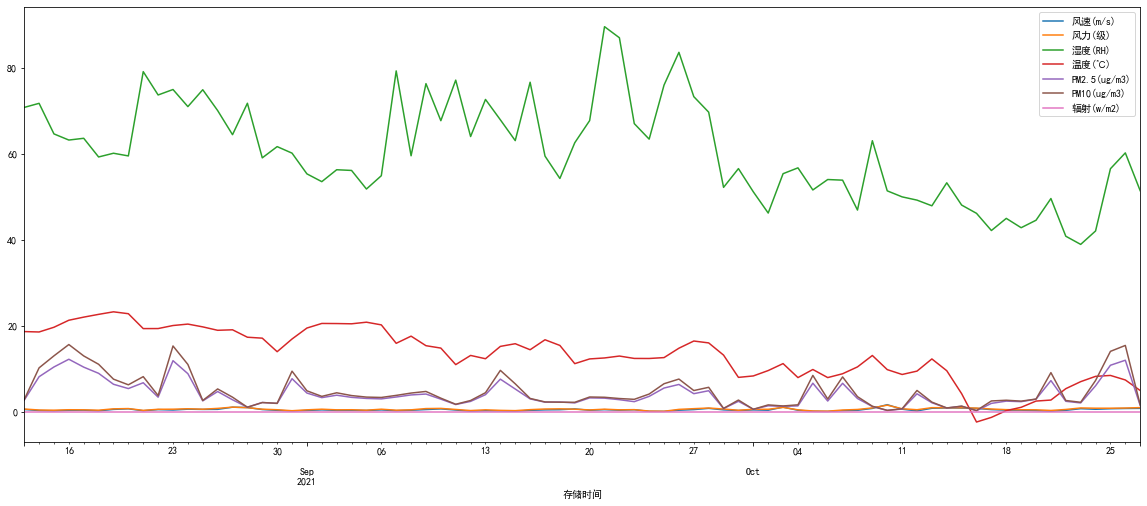
(四)可视分析


后面会把数据分享给大家
本文章仅供交流,如有转载,请标明来处 谢谢
Original: https://blog.csdn.net/weixin_45284767/article/details/122723400
Author: 江白AS
Title: 气象数据的简单数据分析处理——基于Notebook
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/639992/
转载文章受原作者版权保护。转载请注明原作者出处!