

使用决策树算法的基本思路
划分数据集,使被划分的特征作为决策树的节点。通常采用二叉树(也可以采用非二叉树)作为最终形成的决策树形式,即将数据集按照某个特征进行划分成两个子数据集,并对这些子数据集递归地进行划分,直到无法划分为止。
划分数据集的伪代码:
检测数据集中的每个子项是否属于同一分类
If true then return 类标签
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
递归执行此过程并将返回结果增加到分支节点中
return 分支节点
信息增益和信息熵
信息增益
在划分数据集之前之后信息发生的变化称为信息增益。
信息熵
集合信息的度量方式称为香农熵或简称为熵。
- 概率和频率
这里我们采用频率来计算概率。假设一个随机变量 (X) 可取 (N) 个不同的值(x_1, x_2, …, x_N),其中值 (x_i)出现的次数记为(|x_i|),则 (x_i) 出现的概率可表示为$$p(x_i)=\frac{|x_i|}{\sum_{i=1}^N{|x_i|}}$$ - 信息量
上面我们计算出了随机变量 (X) 取 (x_i) 时的概率 (p(x_i)),则此时的信息量定义为 $$I(x_i) = -\log_2{p(x_i)}$$ - 信息熵
信息熵定义为随机变量 (X) 所包含的所有信息量的数学期望,即 $$H(X) = -\sum_{i=1}^Np(x_i)\log_2{p(x_i)}$$ 它表示这个随机变量所包含信息的随机程度。熵值越大,则数据的随机程度越高,反之随机程度越低,数据趋向于集中于某一个值。
一个例子
给定一个数据集 (D),其中包含两个标签类别(y_1, y_2),根据统计它们的出现概率分别为(\frac{2}{5})和(\frac{3}{5}),则 (D) 的信息熵 $$\begin{align }H(D) & = -(\frac{2}{5}\log_2\frac{2}{5} + \frac{3}{5}\log_2\frac{3}{5}) \ & \approx 0.971 \end{align}$$
如何构建一棵决策树
给定数据集
[X = \begin{pmatrix} x_{11} & x_{12} & … & x_{1M} \ x_{21} & x_{22} & … & x_{2M} \ . & . & & . \ . & . & & . \ . & . & & . \ x_{N1} & x_{N2} & … & x_{NM} \end{pmatrix}]
以及标签集
[Y = \begin{pmatrix} y_1 & y_2 & … & y_N \end{pmatrix}^T ]
首先我们计算原数据集的熵 (H_{base}),然后针对每一个特征 (\vec{X_1}, \vec{X_2}, …, \vec{X_M}),对数据集做划分。
之后分别计算划分后数据集的熵 (H_i),并计算它们和 (H_{base}) 的差值(即信息增益) (G_i = H_{base} – H_i)
最后找出最大的差值 (\max{G_i}),将产生该差值的特征 (x_i) 作为此次划分的最佳特征,并将其作为决策树的一个节点。
对剩余的数据集,重复上述步骤,将整个数据集划分完毕,并将划分特征作为决策树的节点,构造决策树。
又是一个例子
[D = \begin{pmatrix} 1 & 1 \ 1 & 1 \ 1 & 0 \ 0 & 1 \ 0 & 1 \end{pmatrix}, Y = \begin{pmatrix} 1 \ 1 \ 0 \ 0 \ 0 \end{pmatrix}]
首先按照第一列进行划分。可以看到数据集中只包含0和1两个数,因此如果我们按照第一列进行划分,则数据集可以分为
[D_1 = \begin{pmatrix} 1 \ 1 \ 0 \end{pmatrix}, D_2 = \begin{pmatrix} 1 \ 1 \end{pmatrix}]
其对应的标注集划分为
[Y_1 = \begin{pmatrix} 1 \ 1 \ 0 \end{pmatrix}, Y_2 = \begin{pmatrix} 0 \ 0 \end{pmatrix}]
分别计算 (D_1) 和 (D_2)的信息熵,可以得到
[H(D_1) \approx 0.918, H(D_2) = 0 ]
由于原数据集被划分成了两个,所以用它们对应的标注在原数据集中的比例作为权重计算它们熵的和。
[H_1=0.6\times0.918 + 0.4 \times 0 = 0.5508 ]
信息增益$$G_1 = H_{base} – H_1 = 0.971 – 0.5508 = 0.4202$$
同样的,我们按第二列进行划分
[D’_1 = \begin{pmatrix} 1 \ 1 \ 0 \ 0 \end{pmatrix}, D’_2 = \begin{pmatrix} 1 \end{pmatrix}]
对应的标注集划分为
[Y’_1 = \begin{pmatrix} 1 \ 1 \ 0 \ 0 \end{pmatrix}, Y’_2 = \begin{pmatrix} 0 \end{pmatrix}]
则它们的信息熵
[H(D’_1) = 1, H(D’_2)=0 ]
[H_2 = 0.8 * 1 + 0.2 * 0 = 0.8 ]
[G_2 = H_{base} – H_2 = 0.971 – 0.8 = 0.171 ]
由于 (G_1 > G_2),因此我们认为第一列的特征更可以用于划分。
因此我们先以第一列特征作为树根,构造一棵二叉决策树
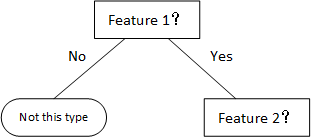

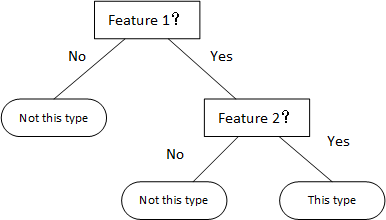
同理我们可以对剩下的部分进行划分,由于过程很简单,我们不再赘述过程。因此得到最后的决策树
Original: https://www.cnblogs.com/ryuasuka/p/7382607.html
Author: 飞鸟_Asuka
Title: 机器学习学习笔记之二:决策树
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/610468/
转载文章受原作者版权保护。转载请注明原作者出处!