

一、基本概念
1.1 定义
跳表(SkipList):增加了向前指针的链表叫做指针。跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上增加了多级索引,通过索引来实现快速查询。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
跳表=链表+多级索引结构
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是O(n)。
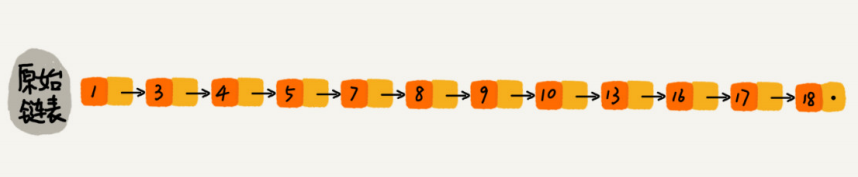

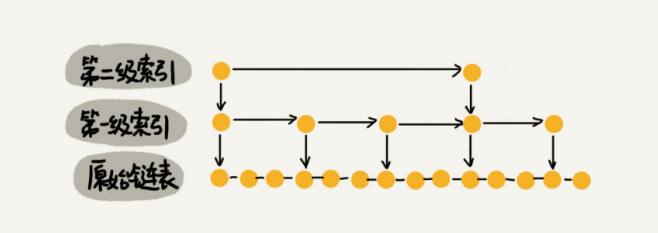
那怎么来提高查找效率呢?如果像图中那样,对链表建立一级”索引”,查找起来是不是就会更快一些呢?每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。图中的down表示down指针,指向下一级结点。
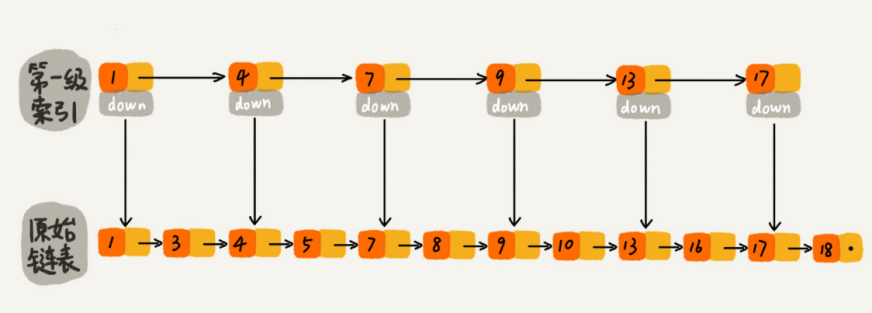
如果我们现在要查找某个结点,比如16。我们可以先在索引层遍历,当遍历到索引层中值为13的结点时,我们发现下一个结点是17,那要查找的结点16肯定就在这两个结点之间。然后我们通过索引层结点的down指针,下降到原始链表这一层,继续遍历。
这个时候,我们只需要再遍历2个结点,就可以找到值等于16的这个结点了。这样,原来如果要查找16,需要遍历10个结点,现在只需要遍历7个结点。
加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。
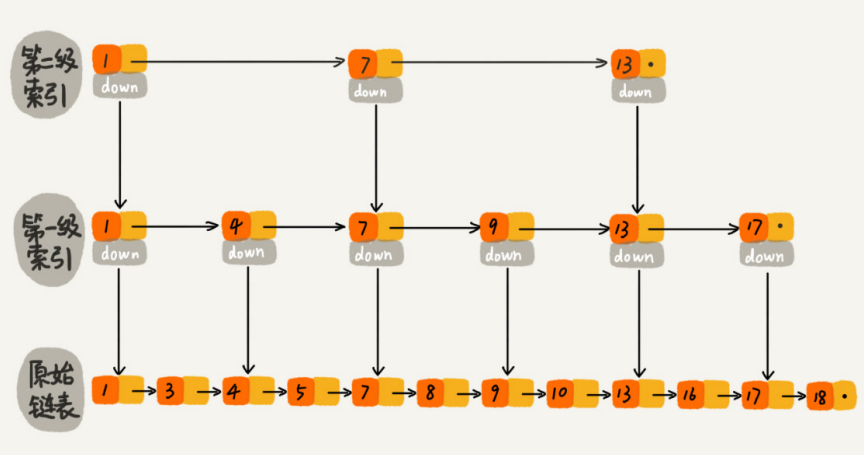
跟前面建立第一级索引的方式相似,我们在第一级索引的基础之上,每两个结点就抽出一个结点到第二级索引。现在我们再来查找16,只需要遍历6个结点了,需要遍历的结点数量又减少了。
1.2 时间复杂度
假设每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是n/2,第二级索引的结点个数大约就是n/4,第三级索引的结点个数大约就是n/8,依次类推,也就是说,第k级索引的结点个数是第k-1级索引的结点个数的1/2,那第
k级索引结点的个数就是n/(2k)。按照我们刚才讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是n/2,第二级索引的结点个数大约就是n/4,第三级索引的结点个数大约就是n/8,依次类推,也就是说,第k级索引的结点个数是第k-1级索引的结点个数的1/2,那第k级索引结点的个数就是n/(2k)。
假设索引有h级,最高级的索引有2个结点。通过上面的公式,我们可以得到n/(2h)=2,从而求得h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历m个结点,那在跳表中查询一个数据的时间复杂度就是O(m*logn)。那这个m的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历3个结点,也就是说m=3,为什么是3呢?
假设我们要查找的数据是x,在第k级索引中,我们遍历到y结点之后,发现x大于y,小于后面的结点z,所以我们通过y的down指针,从第k级索引下降到第k-1级索引。在第k-1级索引中,y和z之间只有3个结点(包含y和z),所以,我们在K-1级索引中最多只需要遍历3个结点,依次类推,每一级索引都最多只需要遍历3个结点。
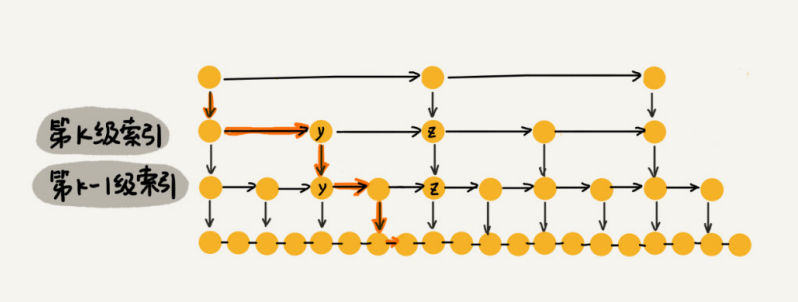
通过上面的分析,我们得到m=3,所以在跳表中查询任意数据的时间复杂度就是O(logn)。这个查找的时间复杂度跟二分查找是一样的。
1.3 空间复杂度
比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢?我们来分析一下跳表的空间复杂度。假设原始链表大小为n,那第一级索引大约有n/2个结点,第二级索引大约有n/4个结点,以此类推,每上升一级就减少一半,直到剩下2个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。

这几级索引的结点总和就是n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是O(n)。也就是说,如果将包含n个结点的单链表构造成跳表,我们需要额外再用接近n个结点的存储空间。那我们有没有办法降低索引占用的内存空间呢?
我们前面都是每两个结点抽一个结点到上级索引,如果我们每三个结点或五个结点,抽一个结点到上级索引,是不是就不用那么多索引结点了呢?我画了一个每三个结点抽一个的示意图,你可以看下。
从图中可以看出,第一级索引需要大约n/3个结点,第二级索引需要大约n/9个结点。每往上一级,索引结点个数都除以3。为了方便计算,我们假设最高一级的索引结点个数是1。我们把每级索引的结点个数都写下来,也是一个等比数列。

通过等比数列求和公式,总的索引结点大约就是n/3+n/9+n/27+…+9+3+1=n/2。尽管空间复杂度还是O(n),但比上面的每两个结点抽一个结点的索引构建方法,要减少了一半的索引结点存储空间。
二、插入和删除
实际上,跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是O(logn)。
2.1 插入
跳表插入的时间复杂度为:O(logn),支持高效的动态插入。
在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1)。但是为了保证原始链表中数据的有序性,我们需要先找到要插入的位置,这个查找的操作就会比较耗时。
对于纯粹的单链表,需要遍历每个结点,来找到插入的位置。但是对于跳表来说,查找的时间复杂度为O(logn),所以这里查找某个数据应该插入的位置的时间复杂度也是O(logn),如下图所示:

2.2 删除
跳表的删除操作时间复杂度为:O(logn),支持动态的删除。
在跳表中删除某个结点时,如果这个结点在索引中也有出现,我们除了要删除原始链表中的结点,还要删除索引中的。
因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点(双向链表除外)。因此跳表的删除操作时间复杂度即为O(logn)。
2.3 跳表索引动态更新
当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某2个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。

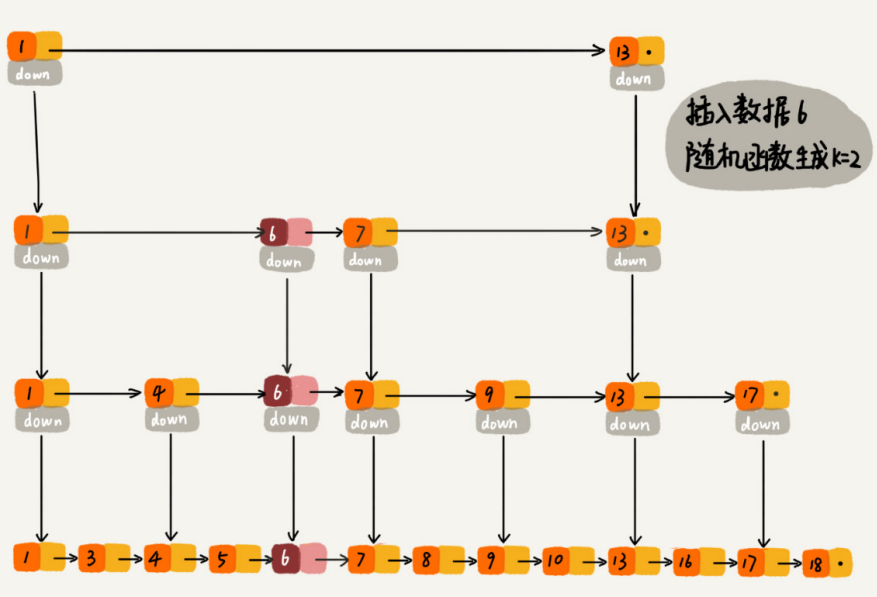
我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值K,那我们就将这个结点添加到第一级到第K级这K级索引中。
三、实现步骤分析
3.1 思路
先讨论插入,我们先看理想的跳跃表结构,L2层的元素个数是L1层元素个数的1/2,L3层的元素个数是L2层的元素个数的1/2,以此类推。从这里,我们可以想到,只要在插入时尽量保证上一层的元素个数是下一层元素的1/2,我们的跳跃表就能成为理想的跳跃表。那么怎么样才能在插入时保证上一层元素个数是下一层元素个数的1/2呢?很简单,抛硬币就能解决了!假设元素X要插入跳跃表,很显然,L1层肯定要插入X。那么L2层要不要插入X呢?我们希望上层元素个数是下层元素个数的1/2,所以我们有1/2的概率希望X插入L2层,那么抛一下硬币吧,正面就插入,反面就不插入。那么L3到底要不要插入X呢?相对于L2层,我们还是希望1/2的概率插入,那么继续抛硬币吧!以此类推,元素X插入第n层的概率是(1/2)的n次。这样,我们能在跳跃表中插入一个元素了。
在此还是以上图为例:跳跃表的初试状态如下图,表中没有一个元素:

如果我们要插入元素2,首先是在底部插入元素2,如下图:

然后我们抛硬币,结果是正面,那么我们要将2插入到L2层,如下图:

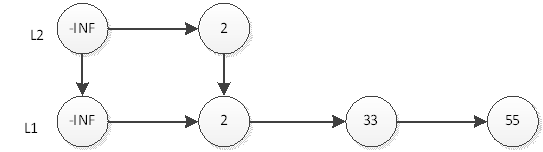
继续抛硬币,结果是反面,那么元素2的插入操作就停止了,插入后的表结构就是上图所示。接下来,我们插入元素33,跟元素2的插入一样,现在L1层插入33,如下图:

然后抛硬币,结果是反面,那么元素33的插入操作就结束了,插入后的表结构就是上图所示。接下来,我们插入元素55,首先在L1插入55,插入后如下图:
然后抛硬币,结果是正面,那么L2层需要插入55,如下图:
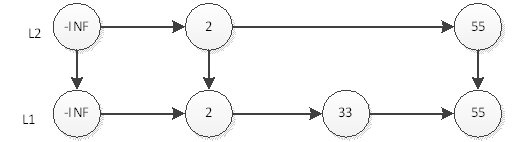
继续抛硬币,结果又是正面,那么L3层需要插入55,如下图:

以此类推,我们插入剩余的元素。当然因为规模小,结果很可能不是一个理想的跳跃表。但是如果元素个数n的规模很大,学过概率论的同学都知道,最终的表结构肯定非常接近于理想跳跃表。
3.2 代码实现(一)
采用随机数生成的方式来获取新元素插入的最高层数。我们先估摸一下n的规模,然后定义跳跃表的最大层数maxLevel,那么底层,也就是第0层,元素是一定要插入的,概率为1;最高层,也就是maxLevel层,元素插入的概率为1/2^maxLevel。
我们先随机生成一个范围为0~2maxLevel-1的一个整数r。那么元素r小于2(maxLevel-1)的概率为1/2,r小于2(maxLevel-2)的概率为1/4,……,r小于2的概率为1/2(maxLevel-1),r小于1的概率为1/2^maxLevel。
举例,假设maxLevel为4,那么r的范围为0~15,则r小于8的概率为1/2,r小于4的概率为1/4,r小于2的概率为1/8,r小于1的概率为1/16。1/16正好是maxLevel层插入元素的概率,1/8正好是maxLevel层插入的概率,以此类推。
通过这样的分析,我们可以先比较r和1,如果r
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* 实现跳跃表:能够对递增链表实现logN的查询时间
*/
public class SkipList {
// 约束整个跳表的最大层级。2^6(2的6次方)
private static final int MAX_LEVEL = 1 << 6;
// 跳跃表数据结构
private SkipNode top;
// 跳表默认层级数
private int level = 0;
// 用于产生随机数的Random对象
private Random random = new Random();
public SkipList() {
// 创建默认初始高度的跳跃表
this(4);
}
// 跳表的初始化
public SkipList(int level) {
this.level = level;
int i = level;
SkipNode temp = null;
SkipNode prev = null;
while (i-- != 0) {
/**
* 从下往上进行初始化。假设level为3,每个层级初始化一个值为null,分值为最小double的初始节点
* +---+
* | 3 |
* +---+
* +---+
* | 2 |
* +---+
* +---+
* | 1 |
* +---+
*/
temp = new SkipNode(null, Double.MIN_VALUE);
temp.down = prev;
prev = temp;
}
// 头节点
top = temp;
}
/**
* 产生节点的高度。使用抛硬币
*
* @return
*/
private int getRandomLevel() {
int lev = 1;
/**
* 核心:初始层级为1,那么此算法需要保证为2的概率为1/2,为3的概率为1/4,如此循环下去。。。
* 这样可以很好的保证第2层节点数量是第1层的两倍,第3层节点数量是第2层节点数量的两倍。
* 第n层节点数量是第n-1层节点数量的两倍。
* 因为如果每层节点数量过多,那么就跟单链表的查询一样了,影响性能。
*/
while (random.nextInt() % 2 == 0) {
lev++;
}
return lev > MAX_LEVEL ? MAX_LEVEL : lev;
}
/**
* 存放一个数据到跳表中
* @param score
* @param val
*/
public void put(double score, T val) {
// 若cur不为空,表示当前score值的节点存在
SkipNode t = top, cur = null;
/**
* path存的是每一层需要插入新节点的前驱节点的集合。
* 假设对于三层层级的跳表来说,需要插入分值为4的,那么path里的最终数据为[3,3,1]。
* 第一个3代表是第一层的3,第二个3代表是第二层的3,第三个1代表是第三层的1,
* 代表新节点将要插在这些节点的后面,也可以说这些节点是新节点的前驱节点。
* level3 1
* |
* level2 1---->3---->6
* | | |
* level1 1->2->3->5->6
*/
List> path = new ArrayList<>();
//当头节点不为空的时候,一直轮询
while (t != null) {
//若存在分值相同的,直接退出轮询。若分值相同,则会做覆盖处理
if (t.score == score) {
cur = t;
// 表示存在该值的点,表示需要更新该节点
break;
}
//如果右节点不存在,那么开始往下找,这一层也就结束,因此需要记录当前节点到path中
if (t.next == null) {
path.add(t);
//当down节点存在时,此次循环结束,继续往下找;否则退出轮询
if (t.down != null) {
t = t.down;
continue;
} else {
break;
}
}
//如果右节点的分数大于新节点分值,那么此层查找结束,继续查down节点,并记录当前层的当前节点
if (t.next.score > score) {
path.add(t);
if (t.down == null) {
break;
}
t = t.down;
} else
t = t.next;
}
/**
* 如果存在相同分值的,直接更改down这条竖线上所有数据就好。例如分值为3,那么改3这条竖线上所有的值就好
* level3 1
* |
* level2 1---->3---->6
* | | |
* level1 1->2->3->5->6
*/
if (cur != null) {
while (cur != null) {
cur.val = val;
cur = cur.down;
}
} else {
// 当前表中不存在score值的节点,需要从下到上插入
int lev = getRandomLevel();
/**
* 当翻硬币的层级大于当前层级时,需要更新top这一列的节点数量,同时需要在path中增加这些新的首节点。
* 当小于当前层级时,直接在
*/
if (lev > level) {
/**
* 假如翻硬币的层级为4,那么对于如下跳表
* level3 1
* |
* level2 1---->3---->6
* | | |
* level1 1->2->3->5->6
* -----变成------
* level4 null
* |
* level3 1
* |
* level2 1---->3---->6
* | | |
* level1 1->2->3->5->6
* 新的top头节点为level4的null
*/
SkipNode temp = null;
// 前驱节点现在是top了
SkipNode prev = top;
while (level++ != lev) {
temp = new SkipNode(null, Double.MIN_VALUE);
// 加到path的首部
path.add(0, temp);
temp.down = prev;
prev = temp;
}
// 头节点
top = temp;
// level长度增加到新的长度
level = lev;
}
/**
* 从后向前遍历path中的每一个节点,在其后面增加一个新的节点
* 注:从第一层开始往上添加。path中的数据是从最高层级添加下来的,
* 因此需要从最后一位取,代表是第一层的新节点的前驱节点
*/
SkipNode downTemp = null, temp = null, prev = null;
//由于是从path中倒序取数,因此i>level-lev,
// 因为level-1到level-lev之间的举例为lev-1,就是翻硬币翻出来的层数
for (int i = level - 1; i >= level - lev; i--) {
temp = new SkipNode(val, score);
prev = path.get(i);
temp.next = prev.next;
prev.next = temp;
temp.down = downTemp;
downTemp = temp;
}
}
}
/**
* 查找跳跃表中的一个值
*
* @param score
* @return
*/
public T get(double score) {
SkipNode t = top;
while (t != null) {
if (t.score == score)
return t.val;
if (t.next == null) {
if (t.down != null) {
t = t.down;
continue;
} else
return null;
}
if (t.next.score > score) {
t = t.down;
} else
t = t.next;
}
return null;
}
/**
* 根据score的值来删除节点。
*
* @param score
*/
public void delete(double score) {
// 1,查找到节点列的第一个节点的前驱
SkipNode t = top;
while (t != null) {
if (t.next == null) {
t = t.down;
continue;
}
if (t.next.score == score) {// 在这里说明找到了该删除的节点
t.next = t.next.next;
t = t.down;// 删除当前节点后,还需要继续查找之后需要删除的节点
continue;
}
if (t.next.score > score)
t = t.down;
else
t = t.next;
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
SkipNode t = top, next = null;
while (t != null) {
next = t;
while (next != null) {
sb.append(next.score + " ");
next = next.next;
}
sb.append("\n");
t = t.down;
}
return sb.toString();
}
/**
* 跳跃表的节点的构成
*
* @param
*/
private static class SkipNode {
// 存储的数据
E val;
/**
* 跳跃表按照这个分数值进行从小到大排序。
* 注:通过引入分值,以分值大小进行排序,这样跳表中存储的数据可以是对象等复杂类型数据
*/
double score;
// next指针,down指针。一个指向右边元素,一个指向下层元素
SkipNode next, down;
SkipNode(E val, double score) {
this.val = val;
this.score = score;
}
}
public static void main(String[] args) {
SkipList list = new SkipList<>();
list.put(1.0, "1.0");
System.out.println(list);
list.put(2.0, "2.0");
System.out.println(list);
list.put(3.0, "3.0");
System.out.println(list);
list.put(4.0, "4.0");
System.out.println(list);
list.put(5.0, "5.0");
System.out.println(list);
list.delete(3.0);
System.out.println(list);
System.out.println("查找4.0" + list.get(4.0));
}
}
运行结果:

当然每次运行结果层数都可能会不一样,这也正是翻硬币的作用所在。
4.9E-324是double最小值,也就是我们初始化节点的默认value值。
3.3 代码实现(二)
// 跳表中存储的是正整数,并且存储的数据是不重复的
public class SkipList {
private static final int MAX_LEVEL = 16; // 结点的个数
private int levelCount = 1; // 索引的层级数
private Node head = new Node(); // 头结点
private Random random = new Random();
// 查找操作
public Node find(int value){
Node p = head;
for(int i = levelCount - 1; i >= 0; --i){
while(p.next[i] != null && p.next[i].data < value){
p = p.next[i];
}
}
if(p.next[0] != null && p.next[0].data == value){
return p.next[0]; // 找到,则返回原始链表中的结点
} else {
return null;
}
}
// 插入操作
public void insert(int value){
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level; // 通过随机函数改变索引层的结点布置
Node update[] = new Node[level];
for(int i = 0; i < level; ++i){
update[i] = head;
}
Node p = head;
for(int i = level - 1; i >= 0; --i){
while(p.next[i] != null && p.next[i].data < value){
p = p.next[i];
}
update[i] = p;
}
for(int i = 0; i < level; ++i){
newNode.next[i] = update[i].next[i];
update[i].next[i] = newNode;
}
if(levelCount < level){
levelCount = level;
}
}
// 删除操作
public void delete(int value){
Node[] update = new Node[levelCount];
Node p = head;
for(int i = levelCount - 1; i >= 0; --i){
while(p.next[i] != null && p.next[i].data < value){
p = p.next[i];
}
update[i] = p;
}
if(p.next[0] != null && p.next[0].data == value){
for(int i = levelCount - 1; i >= 0; --i){
if(update[i].next[i] != null && update[i].next[i].data == value){
update[i].next[i] = update[i].next[i].next[i];
}
}
}
}
// 随机函数
private int randomLevel(){
int level = 1;
for(int i = 1; i < MAX_LEVEL; ++i){
if(random.nextInt() % 2 == 1){
level++;
}
}
return level;
}
// Node内部类
public class Node{
private int data = -1;
private Node next[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
// 重写toString方法
@Override
public String toString(){
StringBuilder builder = new StringBuilder();
builder.append("{data:");
builder.append(data);
builder.append("; leves: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
// 显示跳表中的结点
public void display(){
Node p = head;
while(p.next[0] != null){
System.out.println(p.next[0] + " ");
p = p.next[0];
}
System.out.println();
}
}
参考文章
Original: https://www.cnblogs.com/ciel717/p/16369335.html
Author: 夏尔_717
Title: 【数据结构】跳表
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/598928/
转载文章受原作者版权保护。转载请注明原作者出处!