

1、行转列
源数据:
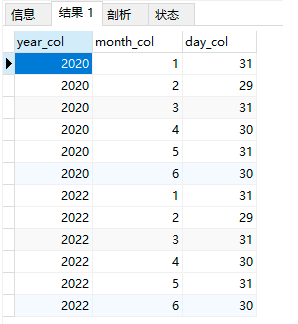

目标数据:
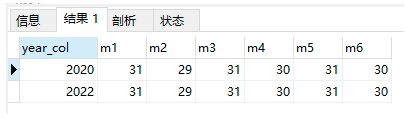
数据准备
-- 建表插入数据
drop table if exists time_temp;
create table if not exists time_temp(
year_col int not null comment '年份',
month_col int not null comment '月份',
day_col int not null comment '天数'
)engine = innodb default charset = utf8;
insert into time_temp values
(2020,1,31),
(2020,2,29),
(2020,3,31),
(2020,4,30),
(2020,5,31),
(2020,6,30);
insert into time_temp values
(2022,1,31),
(2022,2,29),
(2022,3,31),
(2022,4,30),
(2022,5,31),
(2022,6,30);
1.1 方式1 分组+子查询
-- 将数据根据年份分组,然后在进行子查询通过月份查出对应的天数;
select t.year_col,
(select t1.day_col from time_temp t1 where t1.month_col = 1 and t1.year_col = t.year_col) 'm1',
(select t1.day_col from time_temp t1 where t1.month_col = 2 and t1.year_col = t.year_col) 'm2',
(select t1.day_col from time_temp t1 where t1.month_col = 3 and t1.year_col = t.year_col) 'm3',
(select t1.day_col from time_temp t1 where t1.month_col = 4 and t1.year_col = t.year_col) 'm4',
(select t1.day_col from time_temp t1 where t1.month_col = 5 and t1.year_col = t.year_col) 'm5',
(select t1.day_col from time_temp t1 where t1.month_col = 6 and t1.year_col = t.year_col) 'm6'
from time_temp t
group by t.year_col;
1.2 方式2:分组+case when
-- 先根据年份分组,在根据case when .. then ... 条件判断 输入出指定列的信息
select t.year_col,
min(case when t.month_col = 1 then t.day_col end) 'm1',
min(case when t.month_col = 2 then t.day_col end) 'm2',
min(case when t.month_col = 3 then t.day_col end) 'm3',
min(case when t.month_col = 4 then t.day_col end) 'm4',
min(case when t.month_col = 5 then t.day_col end) 'm5',
min(case when t.month_col = 6 then t.day_col end) 'm6'
from time_temp t
group by t.year_col;
2、删除重复数据
思路:先查询出需要保留的数据,然后删除其他的数据;
-- ====================删除重复数据=========================
DROP TABLE IF EXISTS results_temp;
CREATE TABLE results_temp(
id int primary key auto_increment comment '主键',
stu_no int NOT NULL COMMENT '学号',
subj_no int NOT NULL COMMENT '课程编号',
exam_date datetime NOT NULL COMMENT '考试时间',
stu_result int NOT NULL COMMENT '考试成绩'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '成绩表临时' ROW_FORMAT = Dynamic;
-- 将另外一张表的数据插入到此表中(也可以用其他方式插数据,这里时为了方便) 插入两次,让数据重复
insert into results_temp (stu_no,subj_no,exam_date,stu_result)
select stu_no,subj_no,exam_date,stu_result
from results
where subj_no = 1;
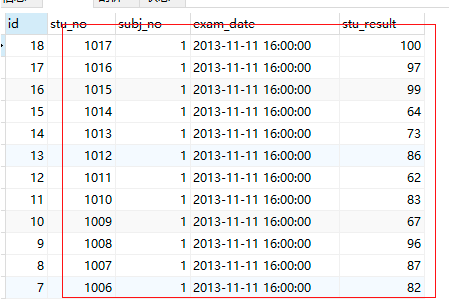
-- 查询数据,每个学生的同一门课程的成绩有两个,或者多个
select * from results_temp
order by stu_no desc;

解决方法:筛选出我们需要的数据,其他数据删除;
-- 剔除重复的学生成绩,只保留一份
-- 我们要保留的数据
select min(id) from results_temp
group by stu_no;
delete from results_temp
where id not in( -- 除了我们要保留的数据其他数据都删除
select * from(
select min(id) from results_temp -- 我们要保留的数据
group by stu_no
) rt
);
再次执行SQL重复数据删除成功
select * from results_temp
order by stu_no desc;
3、如果一张表,没有id自增主键,实现自定义一个序号
实现思路:通过定义一个变量,查询到一行数据就对变量 +1;
使用@关键字创建”用户变量”;
mysql中变量不用事前申明,在用的时候直接用”@变量名”。
第一种用法:set @num=1; 或set @num:=1;
第二种用法:select @num:=1; 也可以把字段的值赋值给变量 select @num:=字段名 from 表名 where ……
注意上面两种赋值符号,使用set时可以用 = 或 := ,但是使用select时必须用 :=
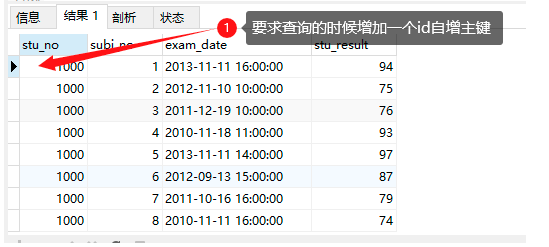
SQL实现
select @rownum:=@rownum + 1 'id',stu_no,stu_result -- @rownum:=@rownum + 1 每查询出一条数据就对变量 @rownum 加一
from results,
(select @rownum:= 0) rowss -- 声明:前面要使用 @rownum 要在这里(form后面)先声明并赋值为0 @rownum:= 0 ,前面才可以使用
where subj_no = 2
order by stu_no desc;
4、约束
4.1 主键约束 primary key
4.1.1 创建表和约束
-- 主键约束
create table employees_temp1(
emp_id int primary key,
emp_name varchar(50)
)engine = innodb charset = utf8;
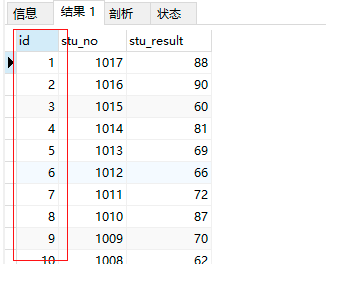
4.1.2 主键约束特点1:非空
insert into employees_temp1 values (null,'张三'); -- 添加一条数据,主键为空
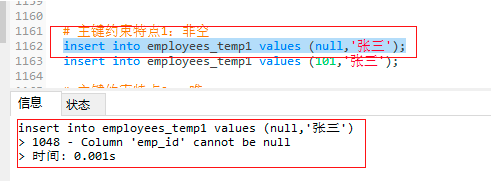
4.1.3 主键约束特点2: 唯一
insert into employees_temp1 values (101,'张三');
insert into employees_temp1 values (101,'张三'); -- 插入两个相同的数据
4.2 唯一约束 unique
4.2.1 创建表和唯一约束
-- 唯一约束,
create table employees_temp2(
emp_id int primary key,
emp_name varchar(50),
emp_tel char(11) unique -- 使用列级别声明
)engine = innodb charset = utf8;
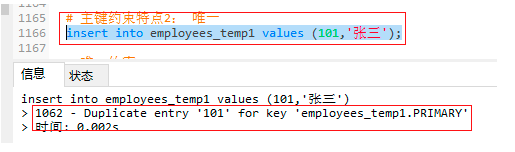
4.2.2 唯一约束特点1:没有非空约束非空
-- 唯一约束特点1:没有非空约束非空
insert into employees_temp2 values (101,'张三',null); -- 可以插入null值
insert into employees_temp2 values (102,'李四',null);
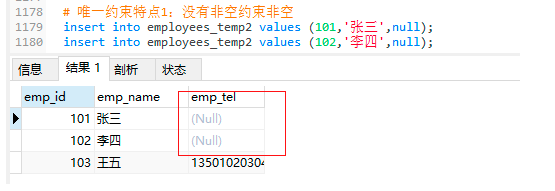
4.2.3 唯一约束特点2:可以保证值的唯一性
-- 唯一约束特点2:可以保证值的唯一性
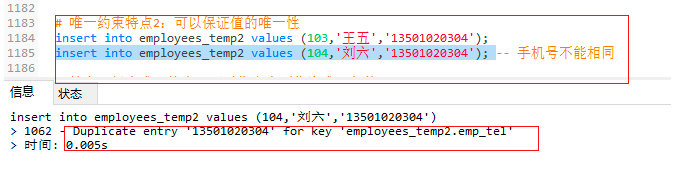
insert into employees_temp2 values (103,'王五','13501020304');
insert into employees_temp2 values (104,'刘六','13501020304'); -- 手机号不能相同
4.2.4 组合唯一约束
-- 补充:组合唯一约束,可以指定多列作为唯一条件
create table employees_temp3(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
-- 使用表级别声明,真实姓名和昵称的组合唯一
constraint uk_emp_name_nick unique(emp_name,emp_nick)
)engine = innodb charset = utf8;
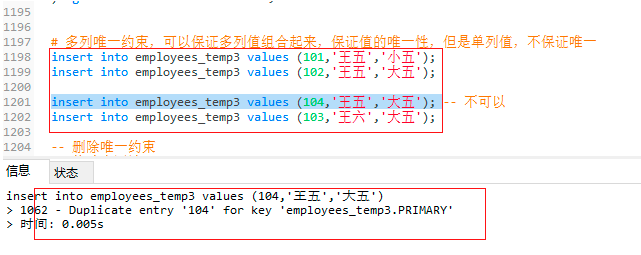
-- 多列唯一约束,可以保证多列值组合起来,保证值的唯一性,但是单列值,不保证唯一
insert into employees_temp3 values (101,'王五','小五');
insert into employees_temp3 values (102,'王五','大五');
insert into employees_temp3 values (104,'王五','大五'); -- 不可以
insert into employees_temp3 values (103,'王六','大五');
4.2.5 删除唯一约束
-- 修改表语法
-- alter table 表名 drop 约束名
alter table employees_temp3 drop index uk_emp_name_nick;
-- drop 语法
-- drop index 约束名 on 表名
drop index uk_emp_name_nick on employees_tem
4.3 外键约束 delete时的级联删除和级联置空
4.3.1 级联删除 on delete cascade
-- 级联删除
-- 创建部门表
drop table if exists departments_temp1;
create table departments_temp1(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
-- 插入部门数据
insert into departments_temp1 values(100,'研发部'),(200,'市场部')
-- 创建员工表 和外键约束
drop table if exists employees_temp4;
create table employees_temp4(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
-- 使用表级声明,增加部门编号的外键约束,并指定级联删除
constraint fk_emp_dept_id foreign key (dept_id)
references departments_temp1(dept_id)
on delete cascade
)engine = innodb charset = utf8;
-- 插入员工数据
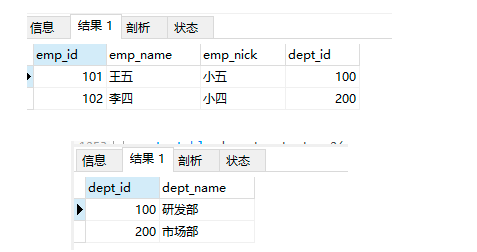
insert into employees_temp4 values (101,'王五','小五',100);
insert into employees_temp4 values (102,'李四','小四',200);
查询数据:
select * from employees_temp4;
select * from departments_temp1;
-- 当设置外键属性为级联删除时,删除部门表中的数据,自动将所有关联表中的外键数据,一并删除
delete from departments_temp1 where dept_id = 100;
-- 再次查询数据:
select * from employees_temp4;
select * from departments_temp1;
-- 部门删除后,该部门的数据也被删除了
4.3.2 级联删除置空 on delete set null
-- 级联置空
-- 创建部门表
drop table if exists departments_temp2;
create table departments_temp2(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
-- 插入部门数据
insert into departments_temp2 values(100,'研发部'),(200,'市场部')
-- 创建员工表和外键约束
drop table if exists employees_temp5;
create table employees_temp5(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
-- 使用表级声明,增加部门编号的外键约束,并指定级联删除
constraint fk_null_emp_dept_id foreign key (dept_id)
references departments_temp2(dept_id)
on delete set null
)engine = innodb charset = utf8;
-- 插入员工数据
insert into employees_temp5 values (101,'王五','小五',100);
insert into employees_temp5 values (102,'李四','小四',200)
查询数据:
select * from employees_temp5;
select * from departments_temp2;
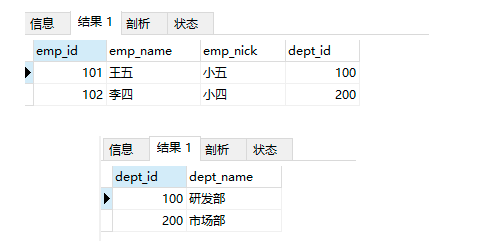
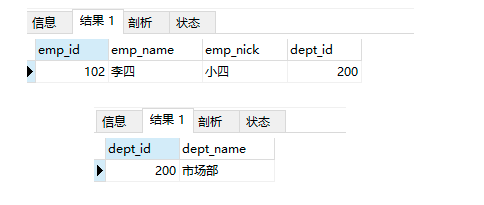
-- 当设置外键属性为级联置空时,删除部门表中的数据,自动将所有关联表中的外键数据,一并置空
delete from departments_temp2 where dept_id = 200;
select * from employees_temp5;
select * from departments_temp2;
-- 部门被删除后,该部门的数据被置空
4.4 外键约束 update时的级联更新和级联置空
4.4.1 级联更新 on update cascade
-- -- ================ update 的级联删除和级联置空==========
drop table if exists departments_temp1_2;
create table departments_temp1_2(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
insert into departments_temp1_2 values(100,'研发部'),(200,'市场部')
drop table if exists employees_temp4_2;
create table employees_temp4_2(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
# 使用表级声明,真实姓名和昵称是组合唯一
constraint uk_emp_name_nick unique(emp_name,emp_nick),
-- 使用表级声明,增加部门编号的外键约束,并指定级联更行修改
constraint fk_emp_dept_id_update foreign key (dept_id)
references departments_temp1_2(dept_id)
on update cascade -- 更新部门表中的数据,自动将所有关联表中的外键数据,一并更新
)engine = innodb charset = utf8;
insert into employees_temp4_2 values (101,'王五','小五',100);
insert into employees_temp4_2 values (102,'李四','小四',200);
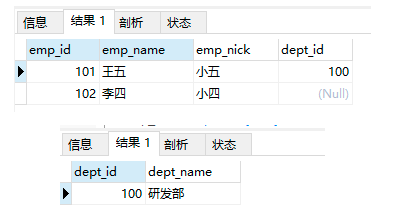
查询数据:
select * from employees_temp4_2;
select * from departments_temp1_2;
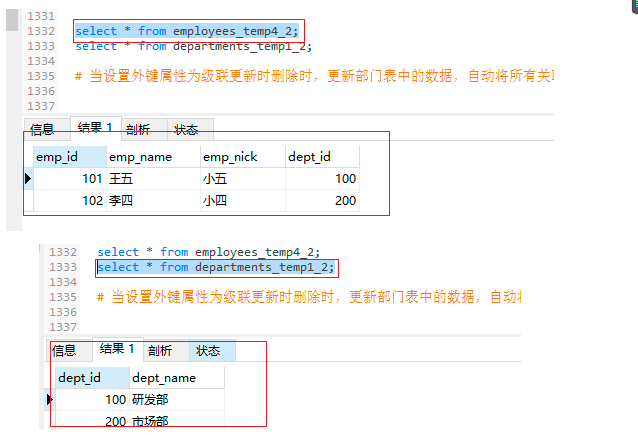
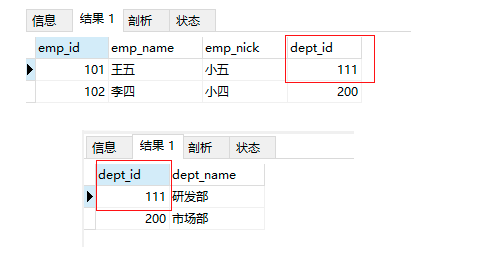
部门表数据更新:
-- 当设置外键属性为级联更新时删除时,更新部门表中的数据,自动将所有关联表中的外键数据,一并更新
update departments_temp1_2 set dept_id = 111 where dept_id = 100;
-- 再次查询数据
select * from employees_temp4_2;
select * from departments_temp1_2;
4.4.2 级联更新置空
-- ==================update 级联更新置空========================
drop table if exists departments_temp2_2;
create table departments_temp2_2(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
insert into departments_temp2_2 values(100,'研发部'),(200,'市场部')
drop table if exists employees_temp5_2;
create table employees_temp5_2(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
-- 使用表级声明,增加部门编号的外键约束,并指定级联更新置空
constraint fk_emp_dept_id_update2 foreign key (dept_id)
references departments_temp2_2(dept_id)
on update set null
)engine = innodb charset = utf8;
select * from employees_temp5_2;
select * from departments_temp2_2;
查询数据:
insert into employees_temp5_2 values (101,'王五','小五',100);
insert into employees_temp5_2 values (102,'李四','小四',200);

部门表数据更新
-- 当设置外键属性为级联置空时,更新部门表中的数据,自动将所有关联表中的外键数据,一并置空
update departments_temp2_2 set dept_id = 111 where dept_id = 100;
-- 再次查询数据
select * from employees_temp5_2;
select * from departments_temp2_2;

4.5 非空约束
-- 非空约束
drop table if exists employees_temp6;
create table employees_temp6(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int not null,
-- 使用表级声明,真实姓名和昵称是组合唯一
constraint uk_emp_name_nick unique(emp_name,emp_nick)
)engine = innodb charset = utf8;
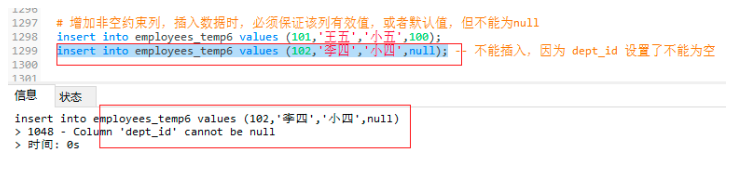
-- 增加非空约束列,插入数据时,必须保证该列有效值,或者默认值,但不能为null
insert into employees_temp6 values (101,'王五','小五',100);
insert into employees_temp6 values (102,'李四','小四',null); -- 不能插入,因为 dept_id 设置了不能为空
5、索引
5.1分类
- 主键索引(主键约束) primary key
- 唯一索引(唯一约束) unique
- 普通索引 index/key
- 全文索引fulltext (存储引擎必须时MyISAM)
5.2 作用
为了提高数据库的查询效率(SQL执行性能) , 底层索引算法是B+树(BTree);
5.3 建议
索引的创建和管理是数据库负责,开发人员无权干涉,原因:查询数据是否走索引,是数据库决定,底层算法觉得走索引查询效率高就走索引,如果觉得不走索引查询效率高,就不走索引,在写SQL语句时,尽量要避免索引失效(SQL调优);
5.4 注意
1.不是索引越多越好,数据库底层要管理索引,也需要耗费资源和性能(数据库性能会下降);
2.如果当前列数据重复率较高,比如性别,不建议使用索引;
3.如果当前列内容,经常改变,不建议使用索引,因为数据频繁修改要频繁的维护索引,性能会下降;
4.小数据量的表也不推荐索引,因为小表的查询效率本身就很快;
5.5 强调
一般索引都是加在where,order by 等子句经常设计的列字段,提高查询性能;
主键索引和唯一索引,查询列对应数据的效率高
[En]
Primary key index and unique index, high efficiency of querying data corresponding to column
5.6 建表时添加索引
-- 普通索引的创建1,建表时添加
drop table if exists employees_temp7;
create table employees_temp7(
emp_id int primary key,
emp_name varchar(50),
index index_emp_name (emp_name)
)engine = innodb charset = utf8;
5.7 建表后添加索引
-- 普通索引的创建2,建表后添加
drop table if exists employees_temp8;
create table employees_temp8(
emp_id int primary key,
emp_name varchar(50)
)engine = innodb charset = utf8;
-- 使用修改表语法,添加索引
alter table employees_temp8 add index index_emp_name_new(emp_name);
5.8 查看表的索引
-- 查看表的索引语法
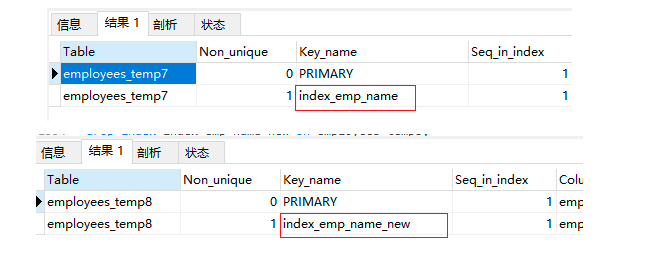
show index from employees_temp7;
show index from employees_temp8;
5.9 删除索引
-- 删除索引1
alter table employees_temp7 drop index index_emp_name;
show index from employees_temp7;

-- 删除索引2
drop index index_emp_name_new on employees_temp8;
show index from employees_temp8;

5.10 分析执行语句的执行性能
-- 分析执行语句的执行性能
-- 查看SQL语句的执行计划,通过分析执行计划结果,优化SQL语句,提示查询性能
-- 使用 explain select 语句,可以看SQL是全表查询还是走了索引等
-- 先把索引添加回来
alter table employees_temp8 add index index_emp_name_new(emp_name);
explain select * from employees_temp8;

5.10 全文索引
-- 全文索引
-- 快速进行全表数据的定位,是使用与MyISAM存储引擎表,而且只适用于char,varchar,text等数据类型
drop table if exists employees_temp9;
create table employees_temp9(
emp_id int primary key,
emp_name varchar(50),
fulltext findex_emp_name(emp_name)
)engine = myisam charset = utf8;
6、存储过程
6.1 带入参存储过程
-- 作用:可以进行程序编写,实现整个业务逻辑单元的多条SQL语句的批量执行;比如:插入表10W数据
-- 带入参的存储过程
-- delimiter // 将MySQL结束符号更改为 // ,其他符号也可以
delimiter //
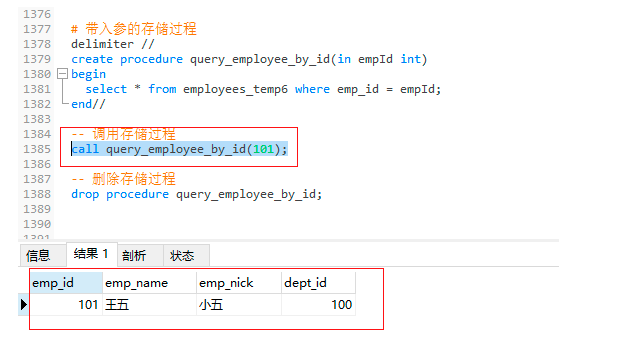
create procedure query_employee_by_id(in empId int)
begin
select * from employees_temp6 where emp_id = empId;
end//
-- 调用存储过程
call query_employee_by_id(101);
-- 删除存储过程
drop procedure query_employee_by_id;
6.2 带出参存储过程
-- 带出参的存储过程
delimiter //
create procedure query_employee_by_count(out empNum int)
begin
select count(1) into empNum from employees_temp6;
end//
-- 调用
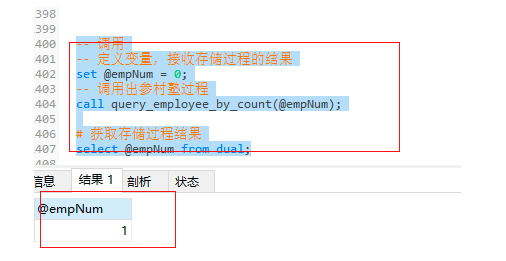
-- 定义变量,接收存储过程的结果
set @empNum = 0;
-- 调用出参村塾过程
call query_employee_by_count(@empNum);
-- 获取存储过程结果
select @empNum from dual;
6.3 自定义存储过程
-- 自定义存储过程,实现出入一个数值,并计算该值内的所有奇数之和,并输出结果
delimiter //
create procedure sum_odd(in num int)
begin
declare i int; -- 先定义,后赋值
declare sums int;
set i = 0;
set sums = 0;
-- declare i int default 0; -- 定义后直接赋默认值
-- declare sums int default 0;
while i
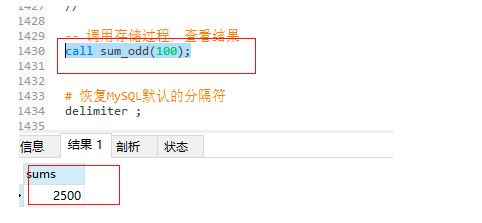
7、触发器
7.1 触发器语法
- 创建类似于存储过程
- 语法:create trigger trigger_name trigger_time trigger_event on tab_name for each row trigger_stmt
- trigger_name:触发器名
- trigger_time 触发时机 befor,after
- trigger_event 触发事件, 取值:insert,update,delete
- tab_name: 触发器作用的表名,即在那张表上建立触发器,如果对该表操作,触发器会自动生效
- trigger_stmt: 触发事件的执行程序主体,可以是一条SQL,也可以是使用begin…end 包含的duoSQL语句
7.2 触发器分类 (6种)
before 和 after 与 insert,update,delete的组合:
- before insert, before update, before delete
- *after insert, after update, after delete
7.3 简单案例
-- 简单案例,当对指定表删除数据时,自动将该条删除的数据备份
drop table if exists employees_temp10;
create table employees_temp10(
emp_id int primary key,
emp_name varchar(50),
emp_time datetime
)engine = innodb charset = utf8;
insert into employees_temp10 values (101,'王五',now());
drop table if exists employees_temp10_his;
create table employees_temp10_his(
emp_id int primary key,
emp_name varchar(50),
emp_time datetime
)engine = innodb charset = utf8;
-- 自定义触发器
-- NEW 和 OLD 含义:代表触发器所在表中,当对数据操作时,触发触发器的那条数据
-- 对于insert触发事件:NEW 表示插入后的新数据
-- 对于update触发事件:NEW 表示修改后的数据,OLD表示被修改前的原数据
-- 对于delete出发时间:OLD 表示被删除前的数据
-- 语法:NEW/OLD.表中的列名
delimiter //
create trigger backup_employees_temp10_delete
after delete
on employees_temp10
for each row
begin
insert into employees_temp10_his(emp_id,emp_name,emp_time)
value (OLD.emp_id,OLD.emp_name,OLD.emp_time);
end
//
delimiter ;
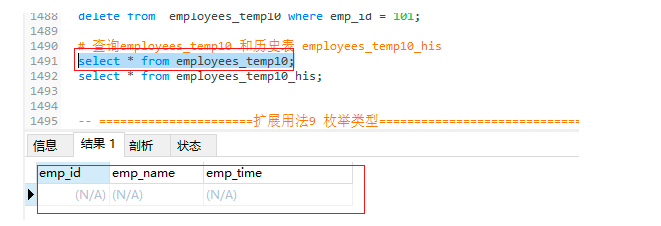
-- 删除employees_temp10 中的数据
delete from employees_temp10 where emp_id = 101;
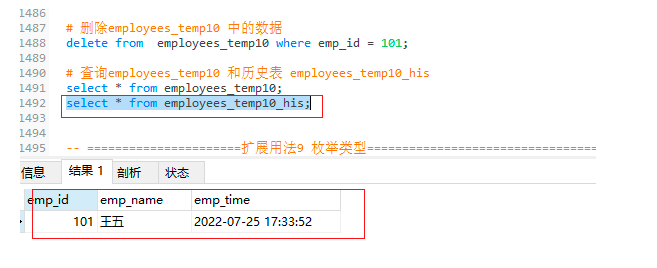
-- 查询employees_temp10 和历史表 employees_temp10_his
select * from employees_temp10;
select * from employees_temp10_his;
employees_temp10表:
employees_temp10_his表:
8、数据集合连接(union 和 union all)
-- 快速建表,直接将查询的数据建成一张表
-- crate table table_name (select_SQL)
create table employees_temp11(select * from employees where department_id in(50,60));
create table employees_temp12(select * from employees where department_id in(60,70));
-- 两张表有重复的数据 department_id = 60
8.1 union
-- union 连接:union前的那个SQL语句,不能是分号结尾
-- 查询结果连接,会自动去重,相同的数据只保留一份
-- 结果51条,50号部门45条,50号部门5条,70号部门1条,执行自动去重
select department_id,employee_id
from employees_temp11
union -- 查询的数据会去重
select department_id,employee_id
from employees_temp12;
8.2 union all
-- 结果56条,50号部门45条,50号部门5条,70号部门1条,执行连接,不会自动去重,相同的数据任然会保留
select department_id,employee_id
from employees_temp11
union all --查询到的数据不会去重
select department_id,employee_id
from employees_temp12;
8.3 union all
-- 连接两条SQL语句,查询结果列,上下列个数要统一,否则会报错,也可以写*(表结构统一)
select department_id,department_id,Last_name
from employees_temp11
union all
select department_id,department_id,hire_date
from employees_temp12;
-- 别名处理
-- 如果第一个SQL语句的结果集使用了别名处理,自动作用到连接的后面结果集,但要单独写在后面就没有效果
select department_id,department_id '部门编号',Last_name -- 有效果
from employees_temp11
union all
select department_id,department_id,hire_date
from employees_temp12;
select department_id,department_id,Last_name
from employees_temp11
union all
select department_id,department_id '部门编号',hire_date -- 无效果
from employees_temp12;
-- 连接查询,默认是按照查询结构第一列升序排序,也可以自定义
select employee_id,department_id '部门编号'
from employees_temp11
union all
select employee_id,department_id
from employees_temp12 order by employee_id desc;
9、视图-view
视图:view,是从表中抽离出(查询出),在逻辑上有相关性的数据集合,它是一个虚表。
数据:可以从一个或多个表中查询视图中的数据。视图的结构和数据依赖于基本表(原始表)。
[En]
Data: the data in the view can be queried from one or more tables. The structure and data of the view depend on the basic table (original table).
通过该视图,可以直接查看基本表中的数据,可以直接进行操作、增加、删除、更改、查看。
[En]
Through the view, you can directly view the data in the basic table, and you can directly operate, add, delete, change and check.
理解:可以将视图理解为被存储起来的SQL语句,就是select语句;
特点:1.可以简化SQL语句,经常需要执行的复杂sql语句我们可以通过视图缓存,简化查询数据及操作;
特点:2.提高安全性,通过视图只能查询和修改你看到的数据,其他数据你看不到也改不了,比如工资,密码;
9.1创建视图
-- 创建视图
-- 普通视图和复杂视图
-- 创建视图语法:
-- create or replace [{undefined | merge | temptable}]
-- view view_name [coll_list]
-- as
-- select_SQL
-- 创建视图1:查询50号部门的数据
create or replace view employee_view1
as
select employee_id,last_name,salary,department_id
from employees
where department_id = 50;
9.2 查询视图
-- 查询视图
select * from employee_view1;
9.3 查看视图结构
-- 查看视图的内容结构
desc employee_view2;
9.4 视图特点
-- 视图中的数据,不是固定的,实际上还是查询的基础表的数据,所以基础表的数据发生改变,视图的数据也会改变
select * from employee_view1 where last_name = 'Fripp';
-- 修改基础表:employees,将Fripp的salary,从8200更改为9000
update employees set salary = 9000 where last_name = 'Fripp';
-- 视图中的数据,由于是源于基础表,跟基本表是有关系的,所以修改视图,就是修改源表
select * from employee_view1 where last_name = 'Fripp';
-- 修改视图 employee_view1 ,将Fripp的工资从9000更改为12000
update employees set salary = 12000 where last_name = 'Fripp';
-- 删除也是同理,删除视图中的数,源表中的数据也会删除
-- 删除最低工资的Olson删除
delete from employee_view1 where last_name = 'Olson';
select * from employees where last_name = 'Olson';
9.5 修改视图
-- 修改视图
-- crate or replace view view_name as select_sql
-- 如果不加or replace ,第一次创建视图是成功的,第二次会检查视图名是否存在,如果存在创建失败
-- 如果加上or replace,发现已经存在会替换
create or replace view employee_view1
as
select employee_id,last_name,salary,department_id,manager_id
from employees
where department_id = 50;
-- 查看视图
select * from employee_view1;
9.6 复杂视图
-- 查询员工表的所有部门的平均工资
create or replace view employee_view3
as
select d.department_id,d.department_name,avg(e.salary) 'salary_avg'
from employees e,departments d
where e.department_id = d.department_id
group by d.department_id;
-- 查询视图
select * from employee_view3;
复杂视图描述:如果该视图是复杂视图,则对该视图进行添加、删除和修改<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>Complex view description: if the view is a complex view, add, delete and modify this view</font>*</details>
-- 一般是无效的,因为复杂视图一般是有多表经过计算来的,所以数据库不知道该怎么操作
-- 比如:分组,group by,聚合函数,去重等
-- 举例:修改50号部门的平均工资
update employee_view3 set salary_avg = 6000 where department_id = 50; -- 不能修改
-- 删除视图,语法类似与删除表,删除视图定义,不会影响基本表
drop view employee_view3;
10、枚举类型
语法:enum(允许的值列表),比如:性别定义:gender enum(‘男’,’女’);
好处1:可以实现对该列值的限制,非指定值列表的其他值,是部允许插入的,增加数据的安全性;
好处2:相对于字符串类型纯属男或女,枚举可以节约存储空间,原因:使用整数进行管理,取值范围是2个字节,有65535个选项可以使用;
场景:该列中的值有大量重复数据,并且是预置和固定的,因此不容易更改。
[En]
Scenario: the values in the column have a lot of duplicate data and are preset and fixed, so they are not easy to change.
10.1 创建枚举
-- 实例用法
drop table if exists employees_temp13;
create table if not exists employees_temp13(
emp_id int primary key auto_increment comment '编号',
emp_name varchar(32) not null comment '姓名',
emp_sex enum('男','女') comment '性别'
)engine innodb charset = utf8 comment '员工临时表13';
10.2 插入枚举数据
10.2.1 使用列表值
-- 插入数据,使用列表值
insert into employees_temp13 values
(1,'张三','男');
10.2.2 使用索引
-- 插入数据,使用索引,从1开始编号
insert into employees_temp13 values
(2,'李四',2);
10.2.3 注意点
-- 不正常插入数据
insert into employees_temp13 values
(3,'王五',3); -- 不能插入数据
insert into employees_temp13 values
(4,'王五','未知'); -- 未知
insert into employees_temp13 values
(4,'王五',null); -- 允许插入null
10.3 枚举查询
-- 带条件查询
-- 使用索引查询
select * from employees_temp13 where emp_sex = 1;
-- 使用列表值查询
select * from employees_temp13 where emp_sex = '男';
-- 查询为null的
select * from employees_temp13 where emp_sex is null;
11、据备份和恢复
11.1 数据备份
作用1:备份就是为了防止原数据丢失,保证数据的安全。当数据库因为某些原因造成部分或者全部数据丢失后,备份文件可以找回丢失的数据。
作用2:方便数据迁移,当需要进行新的数据库环境搭建,复制数据时,备份文件可以快速实现数据迁移。
数据丢失场景:部分数据因人为错误被误删除,部分或全部数据库数据因硬件故障丢失,安全漏洞被入侵数据恶意破坏等。<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>Data loss scenario: some data is mistakenly deleted due to human error, some or all of the data in the database is lost due to hardware failure, and security vulnerabilities are maliciously destroyed by intrusive data, etc.</font>*</details>
无数据丢失场景:数据库或数据迁移、开发测试环境数据库建设、同一数据库的新环境建设等。<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>Non-data loss scenarios: database or data migration, development and test environment database construction, new environment construction of the same database, etc.</font>*</details>
方式1:前面介绍的Navicat或者SQLyog,导出脚本
方式2:MySQL提供了mysqldump命令,可以实现数据的备份。可以备份单个数据库、多个数据库和所有数据库。
语法:mysqldump -h主机ip –u用户名 –p密码 [option选项] 数据库名 [表名1 [表名2...]] > filename.sql
最后的文件名:可以直接是单个文件,也可以文件名前加上可以访问的绝对路径,如:d:/filename.sql 或则 /usr/tmp/filename.sql
选项指令说明:
--add-drop-table :导出sql脚本会加上 DROP TABLE IF EXISTS 语句,默认是打开的,可以用 --skip-add-drop-table 来取消
--add-locks :该选项会在INSERT 语句中捆绑一个LOCK TABLE 和UNLOCK TABLE 语句,好处:防止记录被再次导入时,其他用户对表进行的操作,默认是打开的
-t 或 --no-create-info : 忽略不写创建每个转储表的CREATE TABLE语句
-c 或 --complete-insert : 在每个INERT语句的列上加上字段名,在数据库导入另一个数据库已有表时非常有用
-d 或 --no-data :忽略,不创建每个表的插入数据语句
--where : 只转储给定的WHERE条件选择的记录
--opt 该选项是速记;等同于指定(--add-drop-table,--add-locks,--create-options,--disable-keys,--extended-insert,--lock-tables,--quick,--set-charset)
该选项默认开启,但可以用 --skip-opt 禁用。如果没有使用 --opt,mysqldump 就会把整个结果集装载到内存中,然后导出。如果数据非常大就会导致导出失败
-q 或 --quick : 不缓冲查询,直接导出到标准输出。默认为打开状态,使用--skip-quick取消该选项。
-- 备份数据库的语法不能在navicat中执行,跟mysql名是同级的,命令行执行
11.1.1 备份整个数据库
mysqldump -u root -p bbsdb > D:/sqlDumpTest/bbsdbTemp.sql
11.1.2 备份整个数据库,插入数据语句前 增加列名指定 -c
mysqldump -u root -p -c bbsdb > D:/sqlDumpTest/bbsdbTemp.sql
11.1.3 备份单张表
mysqldump -u root -p -c bbsdb bbs_detail > D:/sqlDumpTest/bbsdbTemp.sql
11.1.4 备份多张表
mysqldump -u root -p -c bbsdb bbs_detail bbs_sort > D:/sqlDumpTest/bbsdbTemp.sql
11.2.5 备份多个数据库
mysqldump -u root -p --databases [option] bbsdb [xxdb1 xxdb2] > D:/sqlDumpTest/bbsdbTemp.sql
11.2.6 备份所有数据库
mysqldump -u root -p --all-databases bbsdb [xxdb1 xxdb2] > D:/sqlDumpTest/bbsdbTemp.sql
11.2 数据恢复
数据恢复:在前提下,先备份数据文件
[En]
Data recovery: on the premise, back up the data files first
11.2.1 source命令
-- 方式1:使用source命令,是在MySQL的命令行中执行的,所以必须登录到MySQL数据库中,且要先创建好数据库,并切换到当前数据库中
-- source D:/sqlDumpTest/bbsdbTemp.sql
11.2.2 mysql指令
-- 方式 2:使用mysql指令,不需要登录
-- 语法:mysql -uroot -p db_name < D:/sqlDumpTest/bbsdbTemp.sql
11.2.3 多数据备份
--方式3:如果备份的是多数据库,备份的数据库文件中,包含创建和切换数据库语句,不需要先创建数据库,直接使用source命令
-- 语法:登录到mysql中,在命令行中执行
-- source D:/sqlDumpTest/bbsdbTemp.sql
Original: https://www.cnblogs.com/xiaoqigui/p/16524128.html
Author: 化羽羽
Title: MySQL扩展
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/505142/
转载文章受原作者版权保护。转载请注明原作者出处!