

一、词频统计
A. 分步骤实现
准备文件
- 下载小说或长篇新闻稿
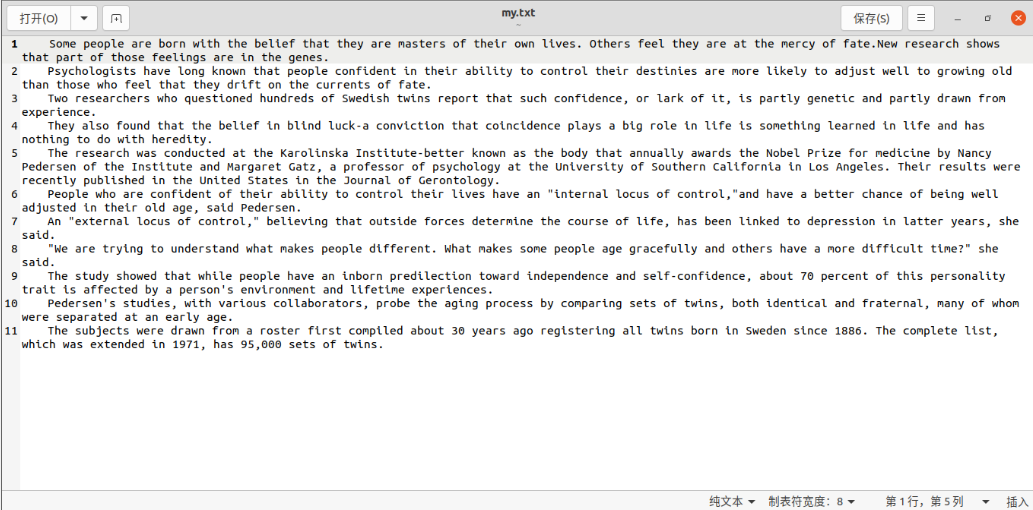

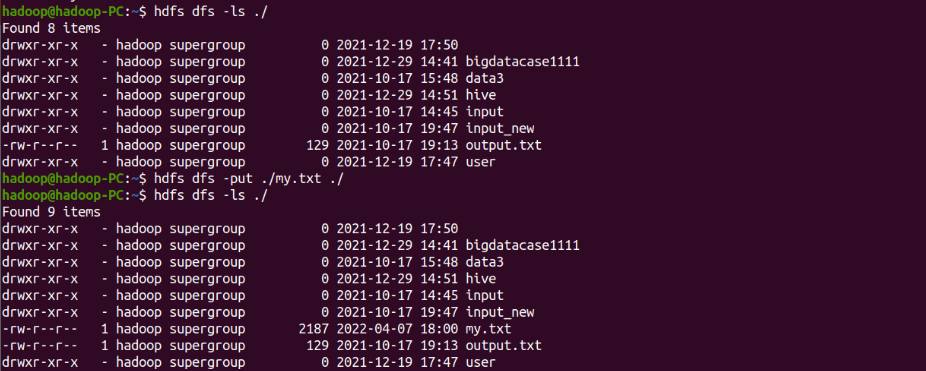
- 上传到hdfs上
读文件创建RDD
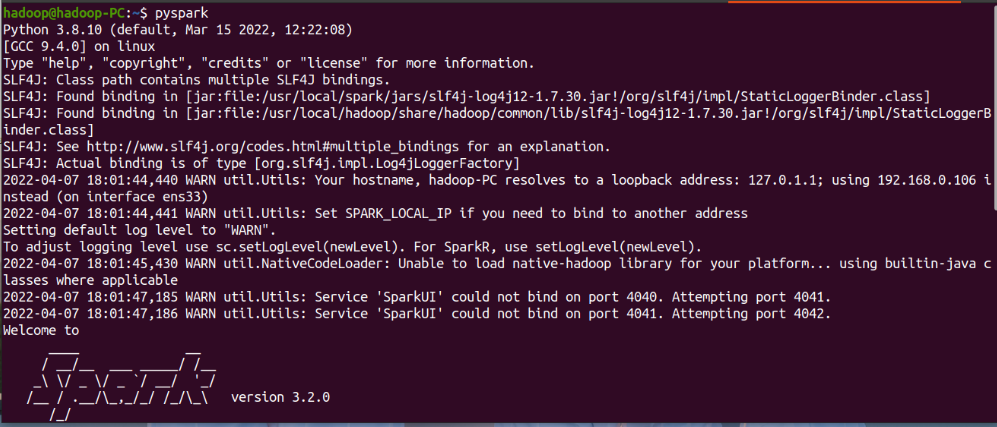
>>> lines = sc.textFile("hdfs://localhost:9000/user/hadoop/my.txt")
>>> lines

分词
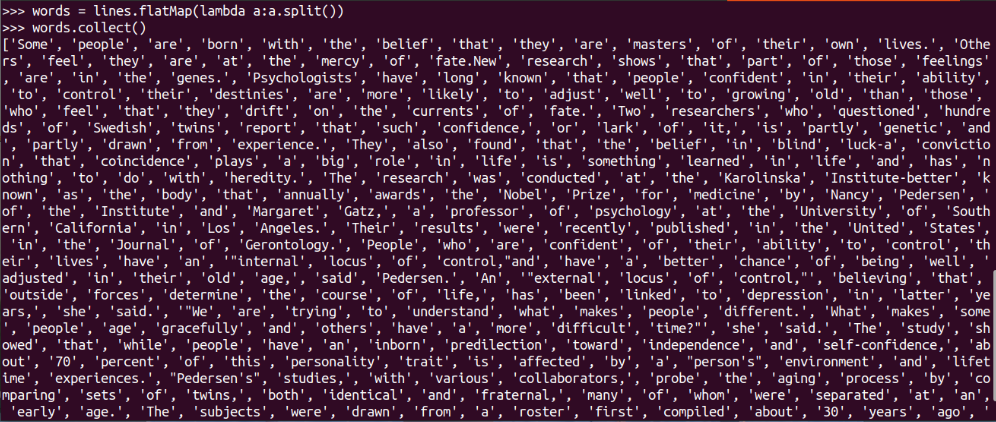
words = lines.flatMap(lambda a:a.split())
预处理
排除大小写lower(),map()
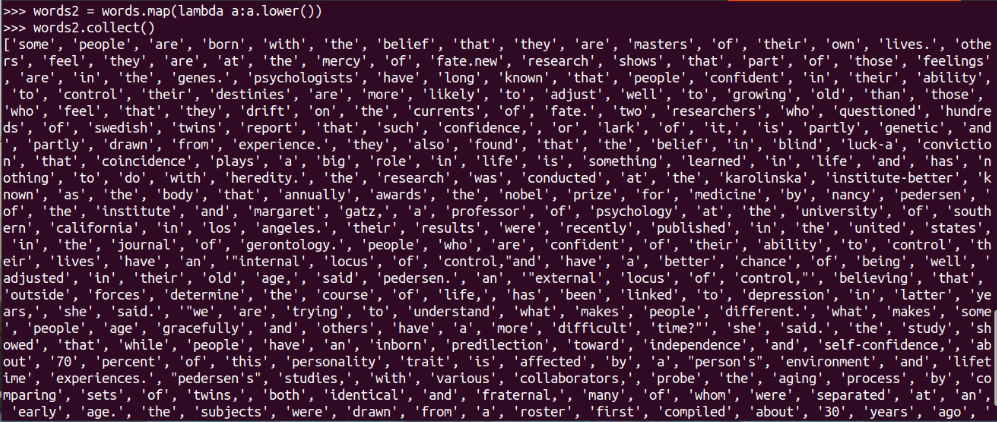
words2 = words.map(lambda a:a.lower())
words2.collect()
标点符号re.split(pattern,str),flatMap()
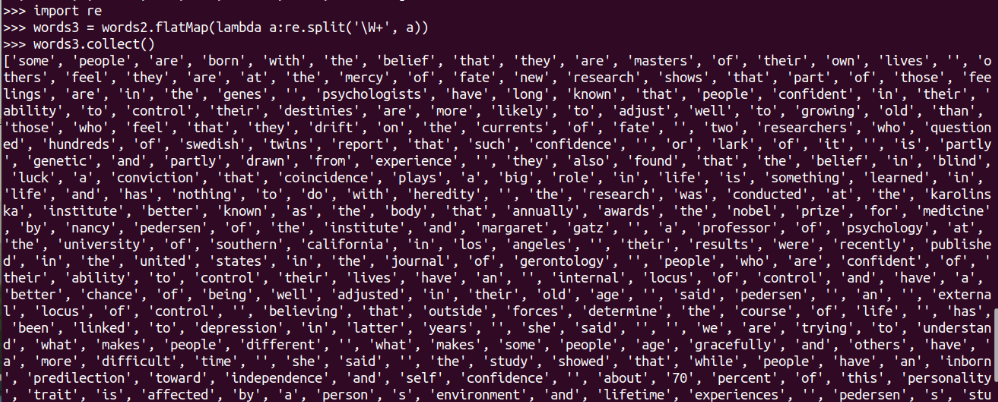
import re
words3 = words2.flatMap(lambda a:re.split('\W+', a))
words3.collect()
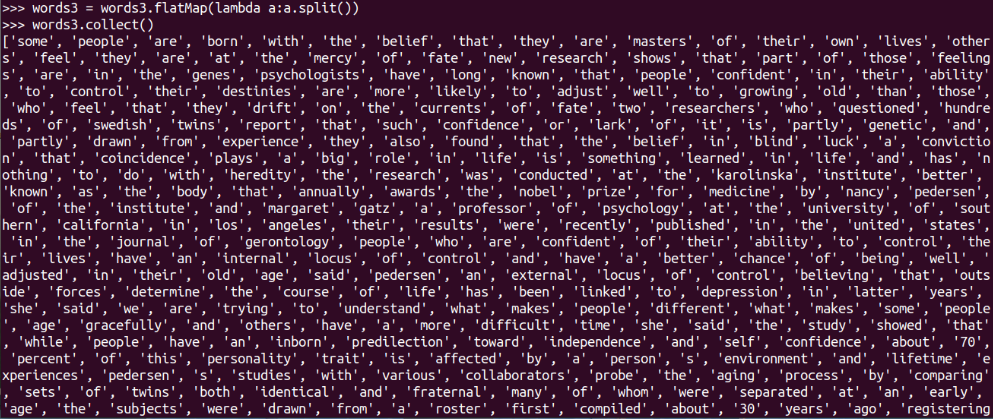
words3 = words3.flatMap(lambda a:a.split())
words3.collect()
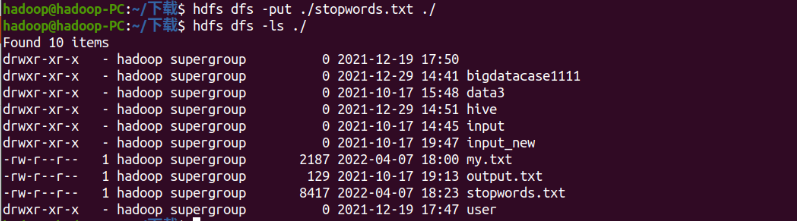
停用词,可网盘下载stopwords.txt,filter()
stopword = sc.textFile('stopwords.txt').flatMap(lambda a:a.split()).collect()
stopword
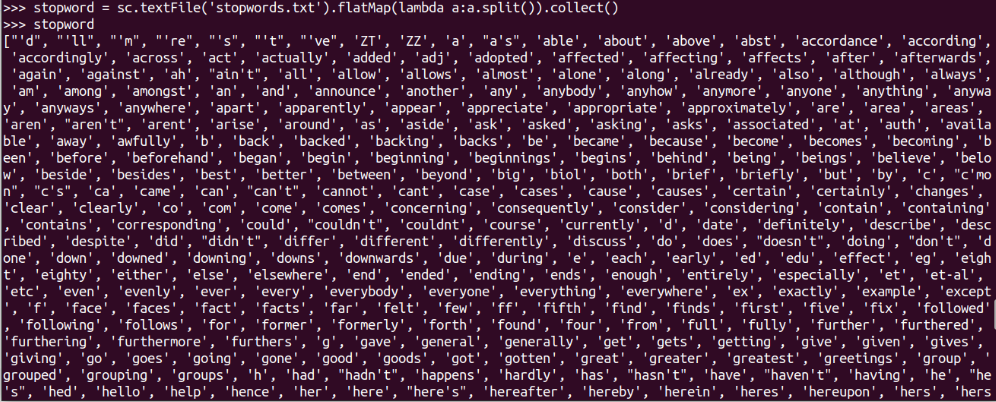
words4 = words3.filter(lambda a:a not in stopword)
words4.collect()
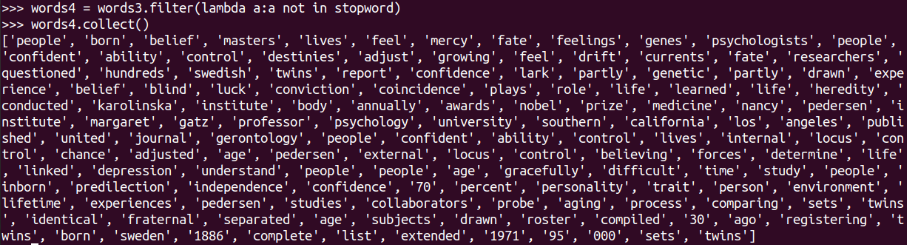
除去长度小于2的词 filter()
words5 = words4.filter(lambda a:len(a)>2)
words5.collect()
统计词频
// 将各个单词统计结果转换成键值对
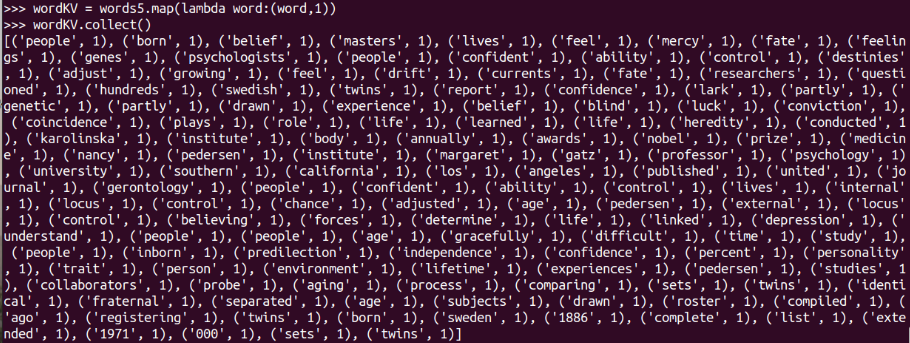
wordKV = words5.map(lambda word:(word,1))
wordKV.collect()
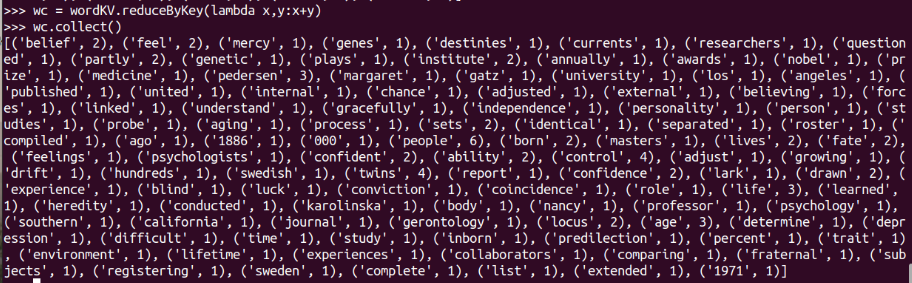
// 再将value进行累加,把相同Key的value进行累加
wc = wordKV.reduceByKey(lambda x,y:x+y)
wc.collect()
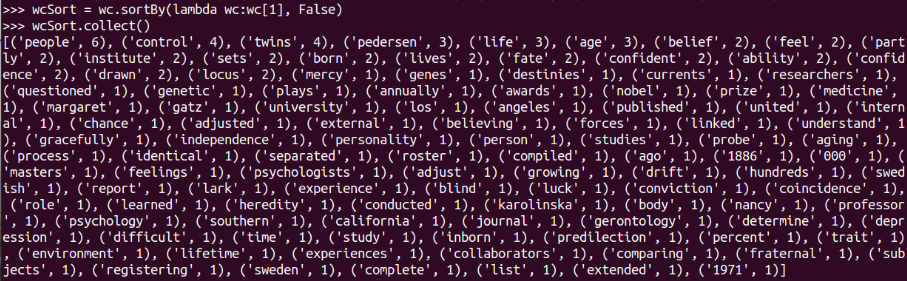
按词频排序
wcSort = wc.sortBy(lambda wc:wc[1], False)
wcSort.collect()
输出到文件
wcSort.saveAsTextFile("file:///home/hadoop/output/RDD5")
wcSort.saveAsTextFile("RDD5")


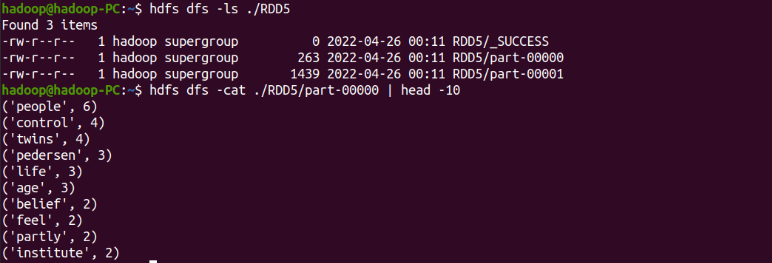
查看结果
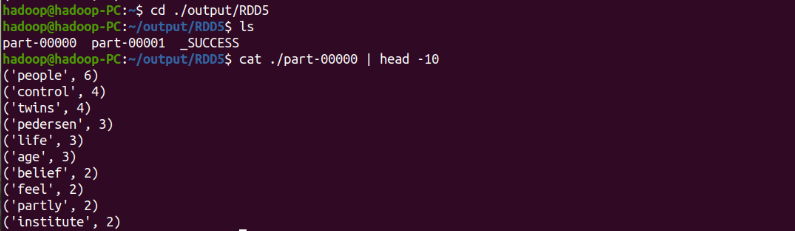
hdfs dfs -ls ./RDD5
hdfs dfs -cat ./RDD5/part-00000 | head -10
B. 一句话实现:文件入文件出
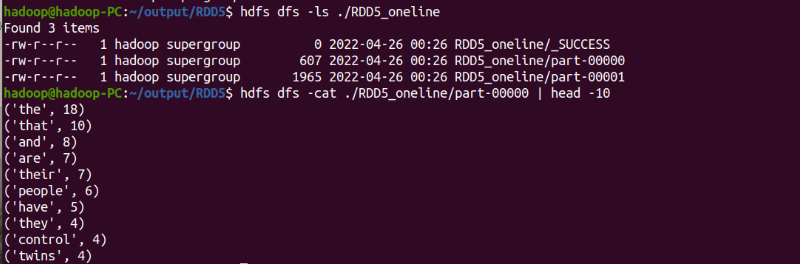
sc.textFile("file:///home/hadoop/my.txt").flatMap(lambda line: line.split(" ")).map(lambda word : word.lower()).flatMap(lambda word:re.split('\W+', word)).flatMap(lambda word:word.split(" ")).filter(lambda word:len(word)>2).map(lambda word : (word,1)).reduceByKey(lambda x,y : x+y) .sortBy(lambda wc:wc[1],False).saveAsTextFile("RDD5_oneline")

C. 和作业2的”二、Python编程练习:英文文本的词频统计 “进行比较,理解并用自己话表达Spark编程的特点
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
二、求Top值
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户
丢弃不合规范的行:
items = sc.textFile('payment.txt').map(lambda line:line.split(','))
items.collect()

items.map(lambda item:len(item)).collect()
items.count()
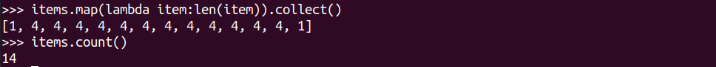
items.filter(lambda item:len(item)==4).collect()

// 丢弃空行、少数据项、缺失数据
items.filter(lambda item:len([i for i in item if len(i)>0])==4).collect()
items.filter(lambda item:len([i for i in item if len(i)>0])==4).count()

按支付金额排序
// 有效记录
recs = items.filter(lambda item:len([i for i in item if len(i)>0])==4)
recs

// 记录按支付金额排序
recs.sortBy(lambda rec:int(rec[2]),False).collect()

取出Top3
top3=recs.sortBy(lambda rec:int(rec[2]),False).take(3)
top3

Original: https://www.cnblogs.com/DingyLand/p/homework_05_.html
Author: stu(dying)
Title: 5.RDD操作综合实例
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/565087/
转载文章受原作者版权保护。转载请注明原作者出处!