



作者 | 高斯定理
欢迎关注知乎”高斯定理”和他的专栏专栏”边走边看”
整理 | NewBeeNLP
前段时间有读者留言『 怎么看最近的platoxl』,那么就 安! 排!

PLATO是百度Siqi Bao等人在2020年-2021年针对NLP对话领域提出的一系列预训练模型,具体包括PLATO,PLATO-2,PLATO-XL,前两篇分别发表在ACL2020和ACL-IJCNLP2021,PLATO-XL则是今年9月在arxiv上预印。
大规模预训练模型BERT、XLNet等在大量的广泛语料上训练,在下游任务上取得了突破性的进展,其证明了预训练—微调框架的有效性。
但是在对话系统上,由于对话语料不同于常规语料,缺少这样大规模的预训练模型。因此PLATO系列利用了大规模的对话语料,对对话系统进行训练,从PLATO到PLATO-XL,用的数据越来越多,模型大小也越来越大。之前开放PLATO的微信体验机器人,也着实让它又火了一遍。
那么本文就来梳理下PLATO家族,具体涉及到的文章链接如下:
- PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable[1]
- PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning[2]
- *PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation[3]
PLATO系列也在github上开源了,只不过用的是paddlepaddle
- https://github.com/sserdoubleh/Research/tree/master/NLP/Dialogue-PLATO
- *https://github.com/PaddlePaddle/Knover/tree/develop/projects/PLATO-2
PS:我始终没找到为什么这个模型叫PLATO,因为它说话像哲学家?
PLATO家族概览
想了一下,先把三个模型的概览给放在这儿,让大家看起来更方便一些:M=10^6, B=10^9
模型语言模型大小语料量PLATO英文132M8.3MPLATO-2英文1.6B684MPLATO-2中文1.6B1.2BPLATO-XL英文11B811MPLATO-XL中文11B1.2B
一、PLATO
三个动机与对应方案:
对话文本和广义文本的不同
一方面用BERT进行初始化;另一方面,没啥好说的,利用了大量Reddit和Twitter的数据,来做对话的文本,进行第二次的训练
对话文本理解的模式
对方的文本是完全可见的(可以用双向模型建模),要回答的文本时单向生成的(用单向模型建模)。因此采用了Unified Language Model的形式,具体如下图中的Seq-to-Seq LM:
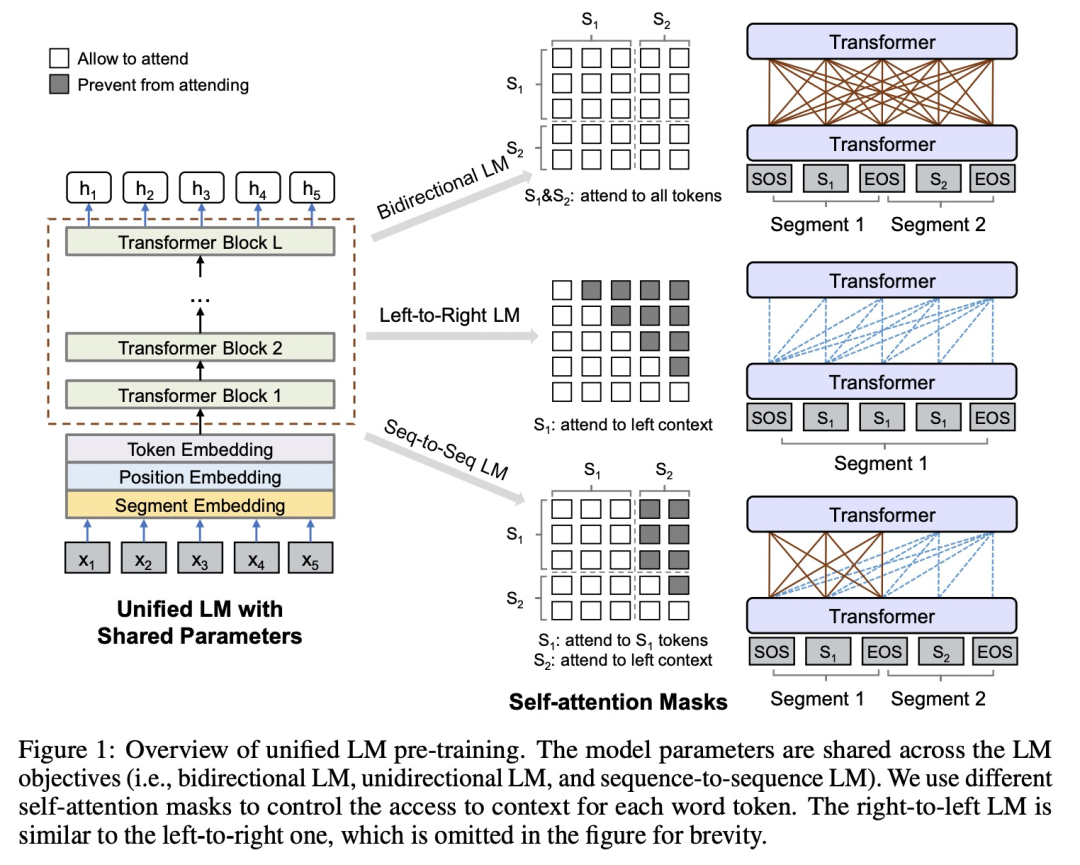
即seg1能看见seg1的所有,不能看见seg2;seg2能看见seg1的所有,能单向看见自己的历史。这样做就能完全利用对方的文本,并单向生成自己的文本。
PS:有兴趣的小伙伴可以参考unified LM原文
- Unified Language Model Pre-training for Natural Language Understanding and Generation[4]
一对多映射
对话本来就没有标准的回答,需要个性化。如果不进行个性化的后果是,回答没有任何信息量,让人没有交谈的兴趣。这个我的理解是不个性化,网络学到的就是一种平均的表达,他把不同人都会表达的意思表达了,但是十分无聊。
一对多映射也是作者本文的重点。作者首先指明对话中的三要素:对话内容(dialogue context)、回应(response)和隐变量。其中隐变量建模成一个K维的类别向量。这三要素之间是什么关系呢,下面这张图做了说明:
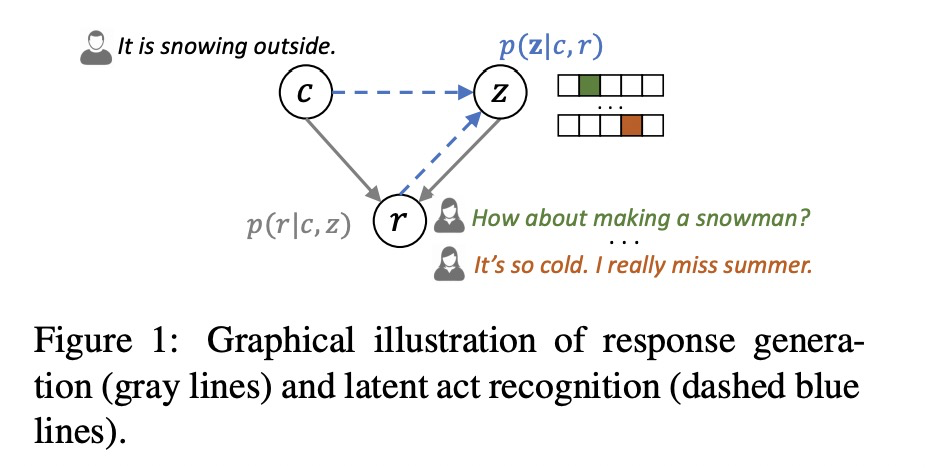
对话内容和回应能够反映隐变量,对话内容和隐变量能够决定生成的回应。这就像讲相声,郭德纲先说了一段,要是你听到后一段的内容,根据风格就能猜出这搭档是谁,要是你知道搭档是谁,那也能做好心理准备接下来的内容是什么风格。所以啊,这又是一个鸡生蛋蛋生鸡的故事。针对这种问题,其实也没什么好的解决方案,作者采用的方法就是在一个batch上跑3遍(OMG!),如下图
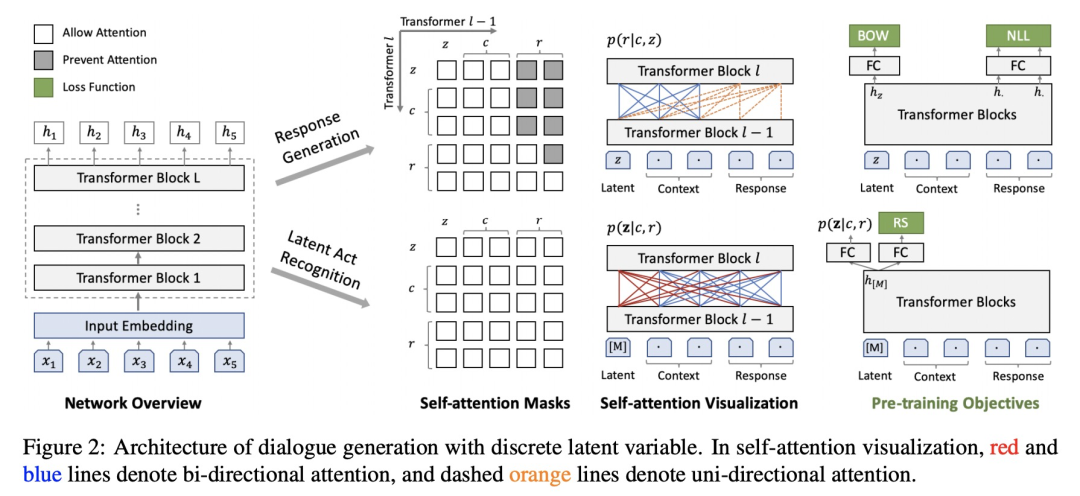
第一遍用正确的回答生成隐变量的概率(图片右下角);
第二遍随机采样一个非本对话内容的回答,和第一遍的比较去训练一个回答比较器(RS)(图片右下角),让其发现第一遍的回答优于第二遍,损失函数为基于交叉熵的损失;
第三遍再用隐变量的概率采样得到隐变量让后生成回答,与原回答比较计算基于自回归的损失函数NLL和非自回归损失函数BOW。
<
作者在8张V100上训练了3.5M步(一般实验室还支撑的起)。
在推断时,对每一个隐表达进行推断,然后用回答比较器判断哪一个回答最优。
模型输入
额外提一嘴模型的输入包括
- Token embedding:BPE高维表达
- 位置编码:基于attention模型的常规操作了
- 角色embedding:response为用户A,进行用户A和B的轮流对话
- 轮数embedding:response序号为0,每进行一次交替-1
在我看来角色embedding和轮数embedding有点像,作者也在不断调整,PLATO-XL输入就发生了相应的变化。
实验结果
作者分别在三个下游数据集上进行了finetune并测试。这三个数据集分别为
- Persona-Chat:个性化对话,额外包括用户的信息
- Daily Dialog:人类日常对话
- DSTC7-AVSD:视频问答,作者只用了文本模态
实验结果如下图所示
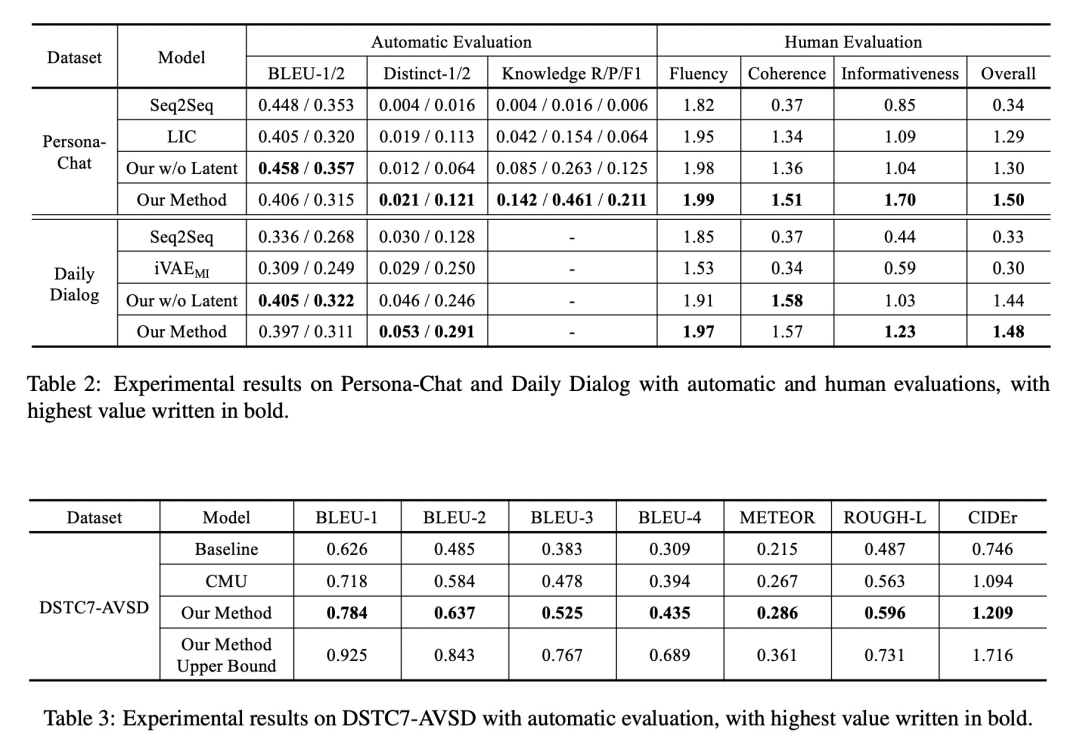
提一个我观察到的比较有趣的现象。不使用隐变量(Our w/o Latent)其实在BLEU上表现更好(也就是与”正确”回答更像),但是多样性也差很多(Distinct-1/2)。这样看来,用隐变量的方法达到了目标,回答更加有个性了,但是也牺牲了BLUE的性能。
二、PLATO-2
动机与方案
PLATO-2相比于PLATO主要想解决的问题是在更大规模的预料上(684M vs. 8M)训练更大规模的网络(作者分别整了1.6B、314M、93M vs 132M的模型)。
值得注意的是PLATO中作者是用BERT进行模型初始化的,而这篇文章没有提及,我默认他是从头开始训练(看了一下代码,应该确实没有)。没有采用BERT进行初始化+更大的模型增大了模型训练的难度。因此作者采用了课程学习的思路( Curriculum Learning),先不采用隐变量,进行one-to-one的粗训练,然后再接上隐变量进行精细化训练,第二阶段的训练方法基本和PLATO一致。
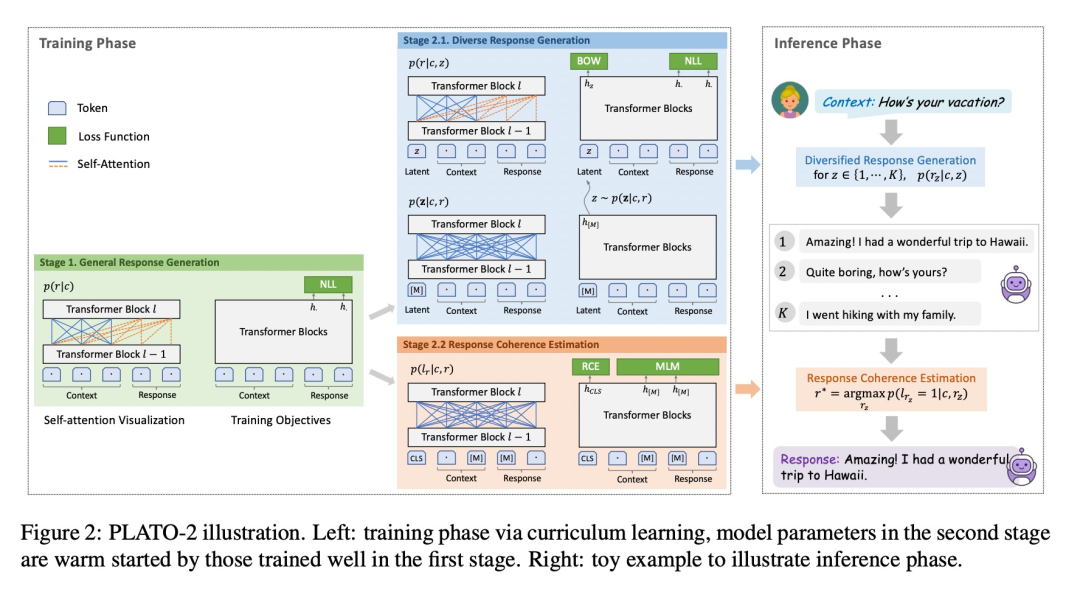
实验结果
主要的实验结果在下面两张表格中
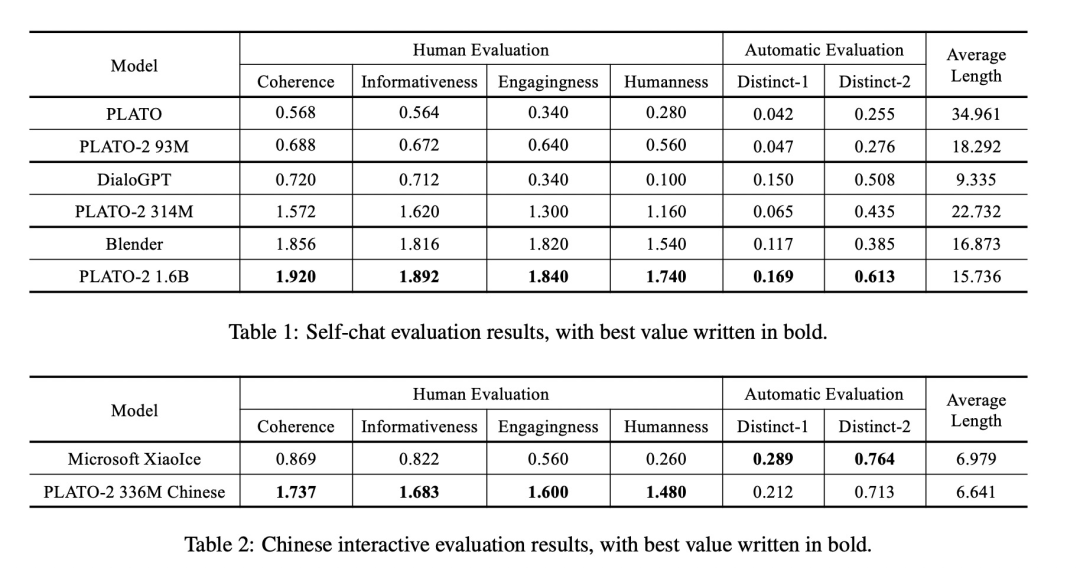
这里作者采用了人工打分(Human Evaluation)和自动多样性打分(Distinct-1/2)。表格1的self-chat是自己和自己对话,结果主要有三件事:
- 模型越大,效果越好
- 相同大小的PLATO,因为课程学习也会越好
- 相同大小的模型,因为PLATO-2采用了隐变量会更好
表格2中自动多样性打分劣于小冰的原因作者解释为:小冰可以进行检索得到更多丰富的内容。
作者参加了DSTC9这个比赛(2021年),在三个赛道上都取得了第一名的成绩。
实验分析
作者在这里额外对回答选择模块(response selection)进行了对比实验,结果如下图
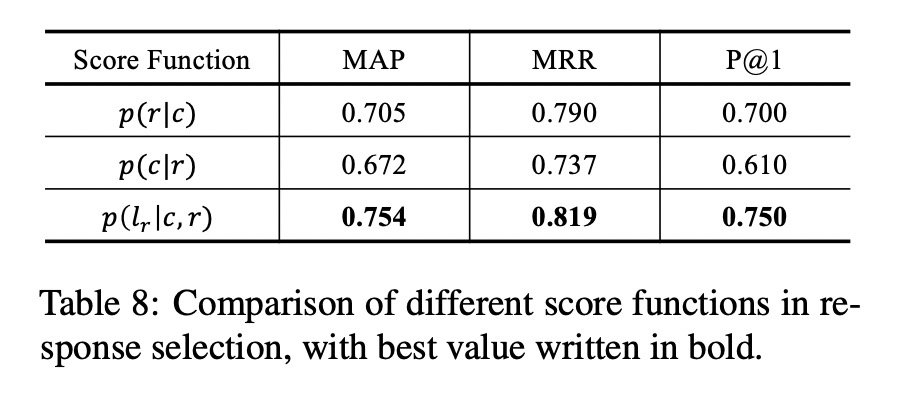
表格中三行的结果分别是前向、后向和选择打分相比于人工打分的不同准确率,可以看到选择打分的优势十分明显。
三、PLATO-XL
动机与方案
PLATO-XL相比于PLATO-2,数据更多(811M vs. 684M),模型更大(11B vs. 1.6B)。作者在这篇文章里返璞归真,抛弃了之前的隐变量和课程学习的方法,直接训练。只不过在训练时加入了 Multi-Party Aware Pre-training。
如果大家还有印象的话,在PLATO中,除了token embedding和positional embedding,作者还采用了role embedding(角色表达)和turn embedding(轮数表达)。
而Multi-Party Aware Pre-training中的Role embedding可不像PLATO中只有A和B,因为从Reddit上爬取的数据不可避免地会存在多个用户对同一个对话地回应。
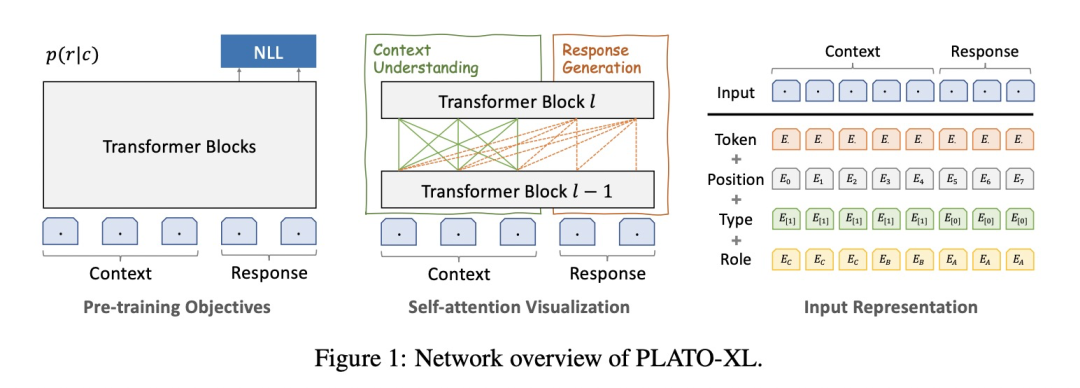
如上图右所示,Role embedding让response编码成角色A,从右到左地新角色依次为B、C、D。Type embedding则是对context和response进行了编码。
实验结果
结果上依然和之前的PLATO-2进行了对比,
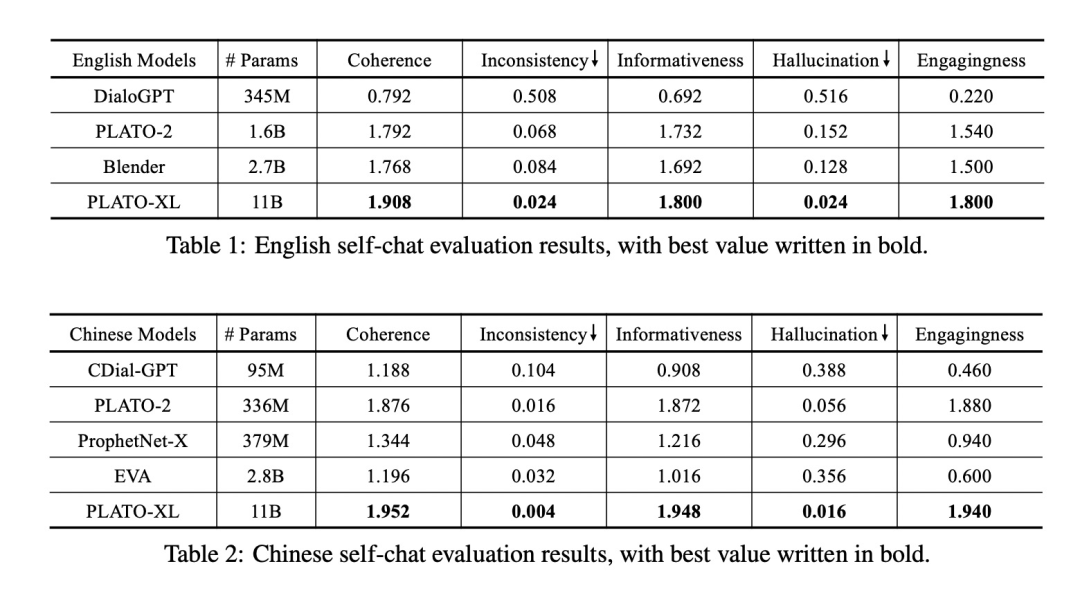
看来隐变量这些方法在大规模数据上也被超越了(笑。而且作者和商业引擎进行了对比,
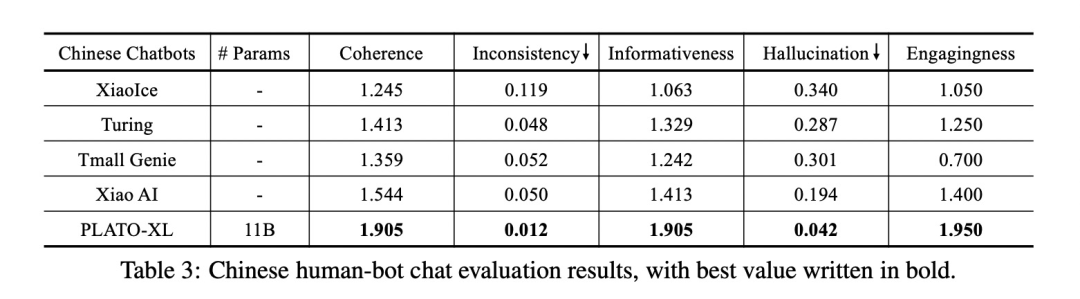
这个才是最强的地方。分数时0-2分,可以看到很多指标要么接近于2,要么就接近于0了。作者在一些下游任务上也finetune后测试,也是取得了SOTA的结果。
四、总结
三个模型各自的亮点:
- PLATO:采用unified language modeling,通过离散隐分布(Discrete Latent Variable),预测回答和隐行为(latent act)
- PLATO-2:利用课程学习,在大规模数据上训练
- PLATO-XL:返璞归真,在输入采用多角色embedding(Multi-Party Aware Pre-training)

码字不易,欢迎点赞、收藏与交流探讨~
本文参考资料
[1]
PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variabl: https://aclanthology.org/2020.acl-main.9.pdf
[2]
PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning: https://aclanthology.org/2021.findings-acl.222.pdf
[3]
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation: https://arxiv.org/pdf/2109.09519.pdf
[4]
Unified Language Model Pre-training for Natural Language Understanding and Generation: https://arxiv.org/pdf/1905.03197.pdf
- END–



Original: https://blog.csdn.net/Kaiyuan_sjtu/article/details/121219914
Author: kaiyuan_sjtu
Title: 一文看懂!百度对话系统PLATO家族
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531734/
转载文章受原作者版权保护。转载请注明原作者出处!