

提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
多跳逻辑推理【目前,在知识图谱上进行多跳推理的一种流行方法是:先将查询转换为相应的计算图,计算图中每个节点表示一个实体集合,每条边表示一个逻辑运算,然后根据计算图遍历知识图谱以获得最终的答案实体集合。】是知识图谱(KG)表示学习领域的一个既定问题。 它包含一跳链路预测以及其他更复杂类型的逻辑查询。 现有算法仅在基于三元组的经典图上运行,而现代 KG 通常采用超关系建模范式。 在这个范例中,类型化的边可能有几个称为限定符的键值对,它们为事实提供细粒度的上下文。 在查询中,此细粒度的上下文会修改关系的含义,并且通常会减少答案集。 在现实世界的 KG 应用程序中经常观察到超关系查询,而现有的近似查询回答方法却不能使用限定词对。 在这项工作中,本文弥合了这一缺陷,并将多跳推理问题扩展到超关系 KG,从而可以解决这种新型复杂查询难题。 基于图神经网络和查询嵌入技术的最新进展,本文研究如何嵌入和回答超关系连接查询。 除此之外,本文提出了一种回答此类查询的方法,并在本文的实验中证明了增加限定词可以改进对各种查询模式的查询回答。
一、背景知识
知识图谱 (KGs) 上的查询嵌入 (QE) 旨在使用神经推理器,而不是传统的数据库和查询语言来回答逻辑查询。另一方面,QE 绕过了对数据库或查询引擎的需求,并通过计算查询表示和实体表示之间的相似度分数直接在潜在空间中执行推理。
然而,所有现有的 QE 模型仅适用于经典的基于三元组的 KG。 相比之下,越来越多的工业 KG 采用超关系建模范式,其中类型化的边可能具有额外的属性,以键值对的形式,称为限定符。 一些标准化工作体现了这种范式,即 RDF【RDF使用三元组来表示,是 W3C 的语义网络标准。由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。】和标签属性图 (LPG)【标签属性图(LPG)和资源描述框架(RDF)有一个共同点:都将数据视为图。它非常直观的反应了现实问题的结构,无论从业务分析还是数据建模,以及到查询,都能很直观的进行。】,分别使用它们的查询语言 SPARQL 和 GQL。 这种涉及限定符的超关系查询是高阶逻辑查询的实例,到目前为止,还没有尝试将神经推理器带入这个领域。
二、写作动机
本文并提出了一个神经框架,以扩展 QE 问题,以超关系KGs,使回答更复杂的查询。具体来说,本文关注使用连接量词(∧)和存在量词()的逻辑查询,其中函数符号用关系的限定符参数化。
本文对这个问题的贡献有四方面:
(1)由于高阶查询在实际规模上难以处理,展示了如何根据文献中充分探索的一阶逻辑 (FOL) 的子集来表达此类查询。
(2)在图神经网络 (GNN) 的最新进展的基础上提出了一种方法来回答潜在空间中的联合超关系查询。
(3)通过实证证明限定符显着提高了对各种查询模式的查询回答准确性来验证本文的方法。
(4)展示了本文的超关系查询回答模型对图形数据库中常用的两种具体化机制的鲁棒性,以在物理级别存储此类图形。
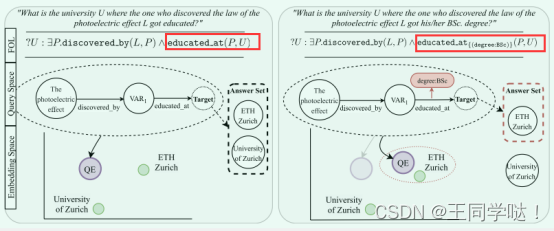
可以处理诸如这样的问题:比如说哪所大学是我获得光电效应学士学位的学校?
那表达式可以写为:U: P.discovered_by (L,P)∧ educated at {(degree: BSc)}(P,U)。
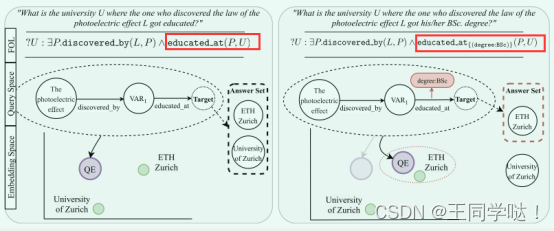

; 三、技术概述
1.查询嵌入:
图查询嵌入(GQEs):是一个基于嵌入的框架,可以有效地预测不完全知识图上的连接查询。GQEs背后的关键思想是,将图节点嵌入到一个低维空间中,并将逻辑操作符表示为在这个嵌入空间中学习到的几何操作(如平移、旋转)。经过训练后,本文可以使用该模型来预测哪些节点可能满足任何有效的连接查询。本文演示的效用在两个应用研究涉及网络与数以百万计的边缘:发现新的交互生物医学药物交互网络(例如,”预测药物可能治疗疾病与蛋白质X”)和预测社会互动网站Reddit(例如,”推荐帖子用户可能否决,但用户B可能赞成”)。
Query2Box:是一个基于嵌入(embedding-based)的框架,可用于推理任何使用∧ , ∨ , ∃ \wedge, \vee, \exists∧,∨,∃操作符的query,并且可用于任意大规模的不完全的KG中。作者的主要观点是:query可以被编码成box(例如hyper-rectangles),box内的一组点对应于query中的一组答案实体(answer entities)。
BetaE:是第一个可以在大型异构知识图谱上处理所有逻辑操作符号(包括存在、交、或、非,之前主要是无法处理逻辑”非”)的方法,它具有embedding类方法的隐含归纳关系的能力、并且可以建模实体语义的不确定性,极大的增强了真实世界知识图谱上多跳推理的可拓展性和处理能力。
MPQE:是假设变量和目标是查询图中的节点,并在其上应用R-GCN编码器。
BIQE :将查询DAG视为全连接图,应用了Transformer编码器,并允许在图中的不同位置回答具有多个目标的查询。
CQD : 表明可以在没有明确查询表示的情况下回答复杂查询。 相反,CQD 在一系列推理步骤中分解查询,并在对简单的 1 跳链路预测任务进行预训练的 KG 嵌入模型的潜在空间中执行波束搜索。这种方法的一个特别新颖之处在于,不需要对复杂查询进行端到端训练,并且可以按现状采用现有的任何训练的嵌入模型。
尽管如此,所有描述的方法都仅限于基于三重的KGs,而本文将QE问题扩展到超关系KGs的领域。由于本文的方法也基于查询图,因此本文采用并进一步研究了一些MPQE观察结果,以进行查询直径和泛化。
超关系嵌入:由于其新颖性,嵌入超关系KG是一个正在进行的研究领域。现有的少数几个模型中,大多数是仅限端到端解码器的CNN,仅限于1跳链路预测,即实体和关系的嵌入被堆叠并通过CNN对语句进行评分。在编码器方面,本文知道STARE【是一种基于消息传递的图形编码器-STARE,能够对超关系KGs进行建模。与现有方法不同,STARE可以与主要三元组一起编码任意数量的附加信息 (限定符),同时保持限定符和三元组的语义角色完好无损。】在超关系设置下工作。STARE扩展了CompGCN【一种新的图卷积框架——CompGCN,它将节点和关系共同嵌入到关系图中。CompGCN利用了来自知识图嵌入技术的各种实体—关系的组合操作,并根据关系的数量进行缩放。】的消息传递框架,通过组合限定符并将其表示与语句的主要关系聚合在一起。
本文研究了将超关系查询与它们的对应关系 (转换为仅三重形式) 进行比较。本文还采用STARE 作为基本的查询图编码器,并使用类似于GAT的注意聚合器进一步扩展它。
2.超关系知识图谱:
给定实体的有限集合和关系R的有限集合,令Q = 2(R × )。然后,本文定义一个超关系知识图为G = (,R,S),其中S ( × R × × Q) 是一组 (限定) 语句。
超关系KG 通过支持三元组来扩展传统 KG。在这项工作中,本文只使用超关系KG,因此使用 KG 来表示这个变体。限定词对集为主要三元组(h, r, t)的语义解释提供了附加信息。例如,考虑语句(AlbertEinstein,edued_at, ETHZurich, {(degree, BSc)})。在这里,限定词对(degree, BSc)给出了关于基本三元组(AlbertEinstein, educationed_at,ETHZurich) 的附加上下文。此语句可以等效地写成一阶逻辑 (FOL)。 具体来说,本文可以把它写成一个带有参数化函数符号的语句educationed_at{(degree:BSc)}(AlbertEinstein, ETHZurich)。在这种形式中,KG 是所有FOL 语句的合取。
3. 超关系查询:
设V是一组可变符号,TAR ∈ V表示查询目标的特殊变量。设+=+V. 然后,如果(+×R×+×Q)的任何子集Q的诱导图。
1)是一个有向无环图
2)具有一个拓扑序,其中所有实体(在本文中称为锚)出现在所有变量之前
3)TAR必须在拓扑序中最后。
从本文对KG,查询和单调性要求的定义中,本文可以得出,在查询的语句中添加更多的限定符只能减少查询的可能答案集。
四、模型概述:
本文的模型不是直接在KG上训练的,而是使用从中采样的一组查询 。因此,本文考虑一个查询并描述本文如何学习表示它。
本文使用一系列STARE层对查询图进行编码。【提出了一种基于消息传递的图形编码器STARE,它能够对这种超关系KG进行建模,与现有方法不同,STARE可以将任意数量的附加信息(限定符)与主三元组一起编码,同时保持限定符和三元组的语义角色不变。】
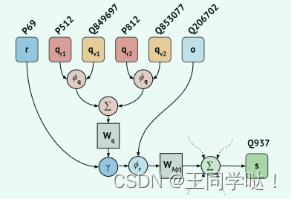
STARE 编码图中限定符对通过复合函数 φq,由 Wq 求和变换。 然后通过 γ 和 φr 将得到的向量分别与关系向量和对象向量合并。 最后,节点 Q937 聚合来自这个和其他超关系边缘的消息。除了计算每个方向上的这些消息聚合,本文还计算自循环更新,然后将更新后的实体表示作为两个方向和自循环的平均值,并对其应用额外的激活函数,最后,通过线性变换更新关系表示。
应用多个STARE层后,本文获得查询图中所有节点的丰富节点表示。最终的查询表示形式为,聚合查询图的所有节点表示形式,本文只选择唯一目标节点的最终表示形式,。给答案实体候选集评分,使用查询表示形式和实体表示形式的相似性,即Score (Q,e) = sim(,),使用简单的向量相似性函数,例如点积或余弦相似性。本文将所描述的模型指定为 STARQE模型。
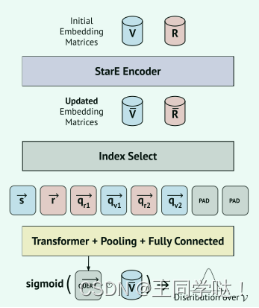
; 五、实验结果分析:
本文设计实验来解决以下研究问题:
RQ1)限定符是否有利于查询回答性能?
RQ2)超关系查询应答的泛化能力是什么?
RQ3)查询应答性能是否取决于超关系KG的物理表示,即物化?
1.数据集:本文基于WD50K 设计了一个新的超关系QE数据集,该数据集由wikidata语句组成,具有不同数量的限定符。
2.超关系查询回答:由于本文是第一个介绍超关系查询应答问题的人,所以在撰写本文时还没有现成的基线。因此,本文将该方法与几个强基线进行比较。
1)三重基线对比。 对于第一个基线,从查询图中的超关系语句中彻底删除所有限定符,只保留基本三元组 (h, r, t)。 这样就可以研究限定符的附加信息是否对正确回答查询有重要影响,或者裸三元组是否已经足够。例如,具有如图中的超关系查询,本文删除了 (degree:BSc) 限定词,最终就只有 ETHZurich 作为正确答案。 否则,在没有限定词的情况下有更多正确答案,会使得查询结果无法精确。
2)具体化。对于第二种设置,本文将超关系查询图通过具体化转换为普通三元组,在这里,本文研究STARQE是否能够对拓扑不同的查询产生相同的语义解释。注意,虽然STARQE的默认关系富集机制在概念上类似于单例属性物化 ,但其语义解释等效于标准RDF物化。
3)零层。作为一个额外的基线,本文考虑了一个类似于单词包的模型,该模型训练实体和关系嵌入,但在图聚合之前不使用任何消息传递步骤。
实验结果:

其中:anchor node———锚节点(实体节点)
qualifier pairs———限定词对
表1中显示的结果表明,STARQE模型通常能够处理不同复杂性的超关系查询。也就是说,复杂交集和投影查询的性能通常高于简单链路预测 (hr-1p) 的性能。特别是,具有交叉点 (− i) 的查询显示出出色的准确性。重要的是,MRR值相对接近Hits@10,这意味着更精确的度量 (如Hits@3和Hits@1) 保持良好的性能 (本文在补充材料中提供了详细的细分)。
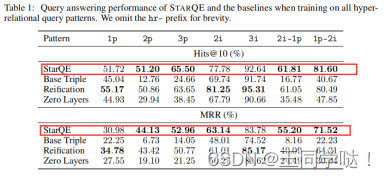
为了调查这种表现是否可以归因于限定符的影响,本文运行了一个基础三重基线。结果表明,限定符在投影 (− p) 查询中起着特别重要的作用,因为性能之间有足够大的差异,例如,在3p查询上超过40Hits@10(%)。本文假设这可以通过以下事实来解释: 限定符还可以有效地减少中间变量答案的大小,并且本文的限定符感知编码器可以捕获该大小。
本文观察到运行 Reification 基线的比较性能。 这表明本文的 QE 框架对于保留复杂查询的相同逻辑解释的底层图拓扑是健壮的。 本文相信这是在广泛的物理图实现上启用超关系查询回答的一个好迹象。
最后,本文发现消息传递层对于保持高精度至关重要,因为零层基线远远落后于启用GNN的模型。对此观察的一种解释可以是,在没有消息传递的情况下,变量节点不会接收任何更新,因此无法正确 “解析”。在某种程度上违反直觉,本文还观察到,关系嵌入是否包含在聚合中并没有很大的区别。1p,2i,3i查询上的相对高性能可以通过其非常特定的星形查询模式来解释,该模式基本上是1跳,在中心节点处有多个分支连接。
2.泛化能力:
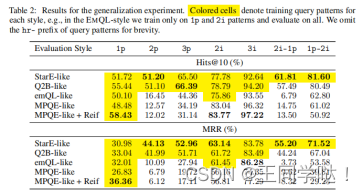
作为一个参考点,在对所有查询模式进行训练和评估时,本文将STARQE结果包括在非泛化设置中。通常,本文观察到,即使在最受限(1p)模式下进行训练时,所有设置在交叉点查询(-i)上也能很好地泛化。类似Q2B的机制在(2i-1p,2p-1i)上展示了吸引人的泛化能力,这表明没有必要在所有可用的查询类型上训练QE模型。然而,在对最具影响力的模式进行细粒度研究时,本文发现投影(-p)模式对于泛化非常重要,因为emQL和MPQE样式的准确性都大大落后,尤其是在MRR度量中,这表明更高的精度结果受到了最大的损害。
当只有一种训练模式时,MPQE 风格显然是最难的。 交集 (-i) 模式的较高结果可以通过答案集的小基数来解释,即,限定符使查询非常有选择性,可能的答案很少。 最后,根据 MRR 结果,物化(MPQE+ Reif)似乎阻碍了泛化能力和整体准确性。 这可以通过具体化复杂查询时产生的复杂图拓扑来解释,并且仅在 1p 上进行训练对于这种复杂的图是不够的。
; 六、 总结与展望
总结:在这项工作中,本文研究并解决了将多跳逻辑推理问题扩展到超关系KGs的问题,在查询回答的上下文中具有限定符的理论考虑,并讨论了它对查询回答的影响,例如答案集的基数。本文还提出了第一个基于图神经网络编码器的超关系QE模型STARQE,并引入了一个新的数据集WD50K QE进行实验验证,其中包含7种经过充分研究的查询模式的超关系变体,并分别平均分析了本文模型在每个模型上的性能。本文的结果表明,与仅三重图相比,限定符确实有助于获得更准确的答案。本文还演示了本文的方法对通常涉及具体化的图数据库中超关系图的特定具体实现的鲁棒性。最后,本文评估模型在各种设置下的泛化能力,发现它能够准确回答看不见的模式。
缺点:1. 第一个不足是本文不允许在图表中出现数字、文本和时间等文字值。 这意味着本文不能处理带有数字时间等查询。例如,询问出生于 1980 年的人的查询。
2.第二个不足是,本文假设了限定词的单调性。 在没有这个假设的情况下工作是一个有趣的未来方向。
3. 第三个不足是,本文可以包括其他几个逻辑运算符。 不仅否定(可以作为限定符包含),还有析取、基数约束等。另一个有趣的下一步是允许变量在查询的更多位置。 在这项工作中,本文只允许头部和尾部位置的变量。 尽管如此,人们也可以用限定符值甚至关系位置中的变量来制定更一般的图形查询。
展望:1. 此外,与以前的工作相比,当前的工作已经允许不同的查询形状,因为查询不限于 DAG(详见补充材料)。 但,本文的工作不允许所有形状。 具体来说,目前尚不清楚循环查询的行为方式。 此外,本文还注意到,与其他工作类似,具有多跳的查询更难。 这似乎与掌握序列中的远程依赖关系类似,需要在这个方向上进一步研究。
2.还要研究的另一个方面是诸如SPARQL之类的查询语言所具有的许多运算符和可能性。例如,查询包括路径、聚合、子查询、文字过滤器等。在可解释性方面还需要进一步的研究工作。系统目前确实会产生答案,但没有提供解释。一种潜在的解决方案是不仅寻找查询的目标,而且还为中间变量提供答案。
3. 最后一个有趣的研究方向是使用近似查询答案来创建查询计划。如果可以快速确定一组可能的正确答案,则可以使用此信息为精确的查询执行选择更优化的计划。
本论文的 GitHub 实现地址:https://github.com/DimitrisAlivas/StarQE.git
Original: https://blog.csdn.net/qq_43743850/article/details/124920767
Author: 王同学哒!
Title: 【Query Embedding on Hyper-relational Knowledge Graphs】 超关系知识图谱上的查询嵌入 论文结果复现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558343/
转载文章受原作者版权保护。转载请注明原作者出处!