

目录
前言
一个机器人问答系统的核心我认为包括两大部分,一部分对用户说的话进行理解和识别,转换成机器可识别的查询语句或者API,另一部分就是知识。简单而言就是解决识别问题和足够多的问题答案的梳理和存储。 当然,我说的非常的笼统和简单,一个智能机器人系统是包含非常多功能和子模块的,参考这篇知乎上的博文,写的非常的好。
如何将知识存储并且应用到合适场景正常返回?比如在闲聊型、任务型、问答型不同类型的问题中,如何准确的找到答案并返回,这是一个非常核心的工作。 实际上不同类型的问答,有不同的处理方案,比如对于任务型,常用的解决方案就是对话流配置,通过意图或者规则的匹配识进入不同流程,然后进行流程执行;比如问答型,简单的就是我们常见的FAQ,通过在数据库中维护不同的问题和答案对来处理;闲聊型,一般都有通用的闲聊库,这个不做重点。
ApacheJena Or Neo4j
如何将FAQ的回答做的更精准,更有目标性?知识图谱是一种比较常见的方式。 前面我调研了Neo4j图数据库,Neo4j作为当前最流程应用最广,也可以说是最强大的 图数据库,上手非常容易,上一篇博客我记录了Neo4j的安装以及一些基本命令,用起来确实非常的方便快捷,而且还支持分布式存储,高效的查询语言,强大的图形化展示效果,真是是非常好用。后来我又了解和看了看Apache Jena,发现Jena也有很大的优势,Jena针对构建语义网络和数据关系提供了一整套的解决方案,从存储、查询、API操作等等。结合产品需求的实际情况,最终决定选择使用Apache Jena。 那么如何抉择选哪个?他们之间又有那些区别,应用常见又有什么不同呢?
先看一下准官方的一个对比,参考这里。还有知乎上这个回答,也提到了两者的区别。
从我了解和理解的角度来说,我认为两者主要区别在于应用场景不同。
Neo4j侧重图数据的存储、查询和展示,他有自己的存储规则,数据结构不是RDF标准的W3C规范,查询语句也是自己的规范,但是封装的非常便捷易用。主要还是侧重存储和数据展示。而且从目前了解到的知识看,Neo4j在知识推理方面比较薄弱。
Apache Jean更侧重构建语音网络,侧重对数据之间的关联关系管理。 遵循W3C规范,支持RDF、RDFS、OWL。可以通过构建自己的推理规则进行查询。 TDB的单节点数据存储效率和查询效率也是非常惊人。如果硬拿Apache Jean和Neo4j比较的话,Jena的存储组件TDB的定位和Neo4j是有些相似的,主要是进行RDF存储,并提供查询API。
做对话系统的话,选择Apache Jena更合适些。
Jena的安装和简介
首先,向这份源码的作者表示感谢,作者提供了一整套的基于Apache Jean的知识图谱问答系统的demo,不光配套的有源码,还有好几篇的博文,可以说相当良心、相当有贡献精神,对此,给作者鞠个躬。 我个人也是从他的这些博文入手学习的。
Jena包括两个安装包
Apache Jena是专门用于语义网本体操作的开源Java框架,其提供RDF和SPARQL API,来查询、修改本体和进行本体推理,并且 提供了TDB和Fuseki来存储和管理三元组。
Jena总共支持三种内置存储模式,分别是RDB、SDB 和TDB。其中RDB现在几乎不用了,因为速度比较慢。而官方推荐的则是TDB,把RDF数据load到TDB中存储,之后的查询就是通过TDB查询,而且速度很快,操作简单,支持几十亿条记录,且支持几百个并行查询。所以在使用Jena的API时,要先导入相应的.nt、.rdf等数据,load到你的TDB中并在之后进行处理。
Apache Jena Fuseki是一个SPARQL服务器。它可以作为一个操作系统服务,作为一个Java网络应用程序(WAR文件),以及作为一个独立的服务器运行。它提供安全性(使用Apache Shiro),并有一个用户界面用于服务器的监控和管理(Apache Jena Fuseki is a SPARQL server. It can run as a operating system service, as a Java web application (WAR file), and as a standalone server. It provides security (using Apache Shiro) and has a user interface for server monitoring and administration. )
Fuseki是基于SPARQL 1.1版本的协议,以及SPARQL图存储协议,进行查询和修改操作。Fuseki底层存储基于TDB,具有SPARQL查询处理的Web用户界面,同时提供服务器监控和管理功能界面。对于其他RDF查询和存储系统来说,Fuseki可被用来提供协议引擎。
参考这篇博客了解基础知识,安装、启动、简单使用
注意:
jena对jdk是有版本要求的。我们一般情况下使用3.5或者3.6就可以了,对应jdk1.8。最新的4.4.0对jdk有更高的要求,要去jdk11。
本体建模,什么是本体?所谓本体实际上就是模式层,对应到Neo4j就是标签的概念。
- 开放域知识图谱的本体构建通常用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系。这也很好理解,开放的世界太过复杂,用自顶向下的方法无法考虑周全,且随着世界变化,对应的概念还在增长。
- 领域知识图谱多采用自顶向下的方法来构建本体。一方面,相对于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,我们要求其满足较高的精度。现在大家接触到的一些语音助手背后对接的知识图谱大多都是领域知识图谱,比如音乐知识图谱、体育知识图谱、烹饪知识图谱等等。正因为是这些领域知识图谱来满足用户的大多数需求,更需要保证其精度。
从MySql转换数据到RDF
环境准备:
本地mysql中新建一个kg_demo_movie的数据库,包含几张表如下:


总共是基础数据表、关系表这两类。
然后我们通过D2RQ先生成mapping文件,然后再生成对应的nt文件。
D2RQ(The D2RQ Platform – Accessing Relational Databases as Virtual RDF Graphs,0.8.1版本)可以将MySql中的关系型数据转换成RDF,基本步骤是:
(1)生成对应mapping文件,对应xxx.ttl文件
进入到D2RQ的安装目录,打开命令行,执行如下命令:
generate-mapping -u root -p root -o kg_demo_movie_mapping.ttl jdbc:mysql://localhost:3307/kg_demo_movie
执行成功后,会在当前目录生成对应的kg_demo_movie_mapping.ttl文件。
自动生成的ttl映射文件,需要做一些调整和修改,主要是需要映射到我们自己设计的模式层,也就是和各种本体映射上,说白了,就是修改下名称。
主要修改几个点:
新增自己定义的URI,和业务相关的URI地址,例如:
#新增这个URI,替换掉原来的 @prefix vocab: <vocab> .
@prefix : <http: www.kgdemo.com#> .
#修改所有的d2rq:property vocab:xxx 和 d2rq:class vocab:xxx,去掉vocab,后面的名字根据模式层本体名称的设计修改即可
#d2rq:class vocab:movie;
d2rq:class :Movie;
#无用的信息删除掉,例如:xx__label信息,例如:id信息,这些不需存储
#关系表是关系,对应本体中的关系</http:></vocab>
(2)通过mapping文件生成RDF,生成xxx.nt ,.nt文件是N-TRIPLE数据序列化格式的RDF文件。(nt文件可以通过命令的方式转换成tdb的存储方式,放到jena中)
.\dump-rdf.bat -o kg_demo_movie.nt .\kg_demo_movie_mapping.ttl
kg_demo_movie_mapping.ttl是我们修改后的mapping文件。其支持导出的RDF格式有”TURTLE”, “RDF/XML”, “RDF/XML-ABBREV”, “N3”, 和”N-TRIPLE”。”N-TRIPLE”是默认的输出格式。
至此,我们已经完成从Mysql中的关系数据库的数据转换为N-TRIPLE类型的RDF数据了。下面我们尝试通过Apache Jean和Fuseki进行数据的查询以及各种API的使用。
RDF加载laod到Fuseki
Jean的存储系统是主要是TDB,TDB属于存储层面的技术,在单机情况下,能够提供非常高的RDF存储性能。 通过jean自带的工具,我们可以将.nt文件转换并加载到Jean的TDB中,以供查询和使用。
在指定目录下新建一个tdb目录,用于jean的存储目录,进入到jean的安装目录下,bat是windows环境下所需要用的工具,bin下是Linux环境下所需要用的工具,我们使用如下命令,将前面生成的RDF数据以TDB的方式加载进来。命令如下:
.\tdbloader.bat --loc="D:\jena\tdb" "D:\kg_demo_movie.nt"
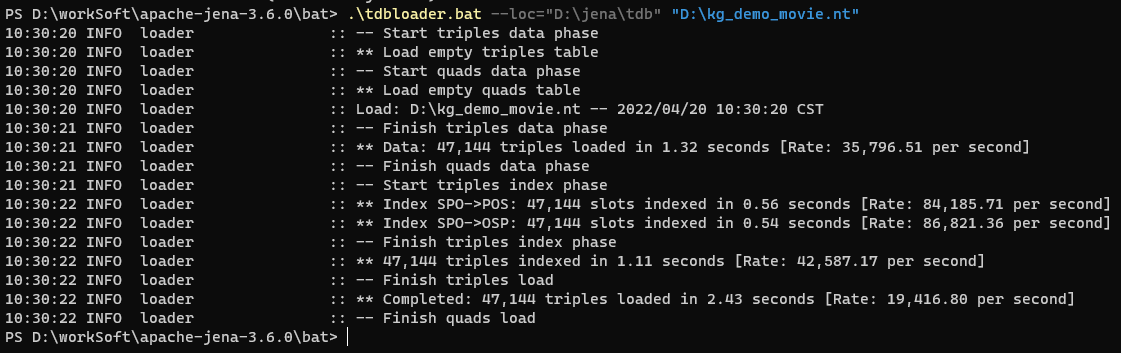
至此,我们就完成了将mysql中的关系型数据—>ttl映射文件—>nt序列化RDF数据—->TDB存储
Fuseki的使用
*例子中这块其实是比较繁琐的,涉及到一个本体构造的文件。 样例中本体的构造是通过protege工具创建的,参考这里,我理解这其实就是设计模式层。本体对应Neo4j中的标签。 说白了就是设计类别以及每个类之间的关系设计。通过protege工具设计好的本体文件格式是owl,比如:ontology.owl,内容如下:
@prefix : .
@prefix owl: .
@prefix rdf: .
@prefix xml: .
@prefix xsd: .
@prefix rdfs: .
@base .
rdf:type owl:Ontology .
#################################################################
Object Properties
#################################################################
### http://www.kgdemo.com#hasActedIn
:hasActedIn rdf:type owl:ObjectProperty ;
owl:inverseOf :hasActor ;
rdfs:domain :Person ;
rdfs:range :Movie .
### http://www.kgdemo.com#hasActor
:hasActor rdf:type owl:ObjectProperty ;
rdfs:domain :Movie ;
rdfs:range :Person .
### http://www.kgdemo.com#hasGenre
:hasGenre rdf:type owl:ObjectProperty ;
rdfs:domain :Movie ;
rdfs:range :Genre .
#################################################################
Data properties
#################################################################
### http://www.kgdemo.com#genreName
:genreName rdf:type owl:DatatypeProperty ;
rdfs:domain :Genre ;
rdfs:range xsd:string .
### http://www.kgdemo.com#movieIntroduction
:movieIntroduction rdf:type owl:DatatypeProperty ;
rdfs:domain :Movie ;
rdfs:range xsd:string .
### http://www.kgdemo.com#movieRating
:movieRating rdf:type owl:DatatypeProperty ;
rdfs:domain :Movie ;
rdfs:range xsd:float .
### http://www.kgdemo.com#movieReleaseDate
:movieReleaseDate rdf:type owl:DatatypeProperty ;
rdfs:domain :Movie ;
rdfs:range xsd:string .
### http://www.kgdemo.com#movieTitle
:movieTitle rdf:type owl:DatatypeProperty ;
rdfs:domain :Movie ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personAppellation
:personAppellation rdf:type owl:DatatypeProperty ;
rdfs:domain :Person ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personBiography
:personBiography rdf:type owl:DatatypeProperty ;
rdfs:domain :Person ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personBirthDay
:personBirthDay rdf:type owl:DatatypeProperty ;
rdfs:domain :Person ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personBirthPlace
:personBirthPlace rdf:type owl:DatatypeProperty ;
rdfs:domain :Person ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personDeathDay
:personDeathDay rdf:type owl:DatatypeProperty ;
rdfs:domain :Person ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personEnglishName
:personEnglishName rdf:type owl:DatatypeProperty ;
rdfs:subPropertyOf :personAppellation ;
rdfs:domain :Person ;
rdfs:range xsd:string .
### http://www.kgdemo.com#personName
:personName rdf:type owl:DatatypeProperty ;
rdfs:subPropertyOf :personAppellation ;
rdfs:domain :Person ;
rdfs:range xsd:string .
#################################################################
Classes
#################################################################
### http://www.kgdemo.com#Comedian
:Comedian rdf:type owl:Class ;
rdfs:subClassOf :Person .
### http://www.kgdemo.com#Genre
:Genre rdf:type owl:Class .
### http://www.kgdemo.com#Movie
:Movie rdf:type owl:Class .
### http://www.kgdemo.com#Person
:Person rdf:type owl:Class .
### Generated by the OWL API (version 4.2.8.20170104-2310) https://github.com/owlcs/owlapi
仔细查看这个owl文件,实际上是有迹可循的。 我们自己实际上也是可以设计,很多都是通用的东西。比如最开始的@preix的规范,分别有 owl/rdf/xml/xsd/rdfs这些,还有一些自定义的,比如@base,URI是直接跟在@prefix后面的。还有很多关键字,比如 inverseOf/domain/range等等,如果我们需要自己手写本体文件,就需要参考和了解下owl的规范。
1、把本体文件放到fuseki的/run/databases/目录下,并且修改文件后缀为.ttl,例如:ontology.ttl
2、在fuseki的/run/configuration/目录下,创建一个fuseki_conf.ttl的文件,文件内容如下:
@prefix : <http: base #> .
@prefix tdb: <http: 2008 jena.hpl.hp.com tdb#> .
@prefix rdf: <http: 1999 www.w3.org 02 22-rdf-syntax-ns#> .
@prefix ja: <http: 11 2005 jena.hpl.hp.com assembler#> .
@prefix rdfs: <http: 2000 www.w3.org 01 rdf-schema#> .
@prefix fuseki: <http: jena.apache.org fuseki#> .
:service1 a fuseki:Service ;
fuseki:dataset <#dataset> ;
fuseki:name "kg_demo_movie" ;
fuseki:serviceQuery "query" , "sparql" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:serviceReadWriteGraphStore "data" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" .
<#dataset> rdf:type ja:RDFDataset ;
ja:defaultGraph <#model_inf> ;
.
<#model_inf> a ja:InfModel ;
ja:baseModel <#tdbgraph> ;
#本体文件的路径
ja:content [ja:externalContent <file:d: worksoft apache-jena-fuseki-3.6.0 run databases ontology.ttl> ] ;
#启用OWL推理机
#ja:reasoner [ja:reasonerURL <http: 2003 jena.hpl.hp.com owlfbrulereasoner>];
.
<#tdbgraph> rdf:type tdb:GraphTDB ;
tdb:dataset <#tdbdataset> ;
.
<#tdbdataset> rdf:type tdb:DatasetTDB ;
tdb:location "D:/jena/tdb" ;
.</#tdbdataset></#tdbdataset></#tdbgraph></http:></file:d:></#tdbgraph></#model_inf></#model_inf></#dataset></#dataset></http:></http:></http:></http:></http:></http:>
3、到fuseki目录,启动fuseki,运行fuseki-server.bat即可
遇到的问题
(1)Triples not terminated by DOT,截图如下:
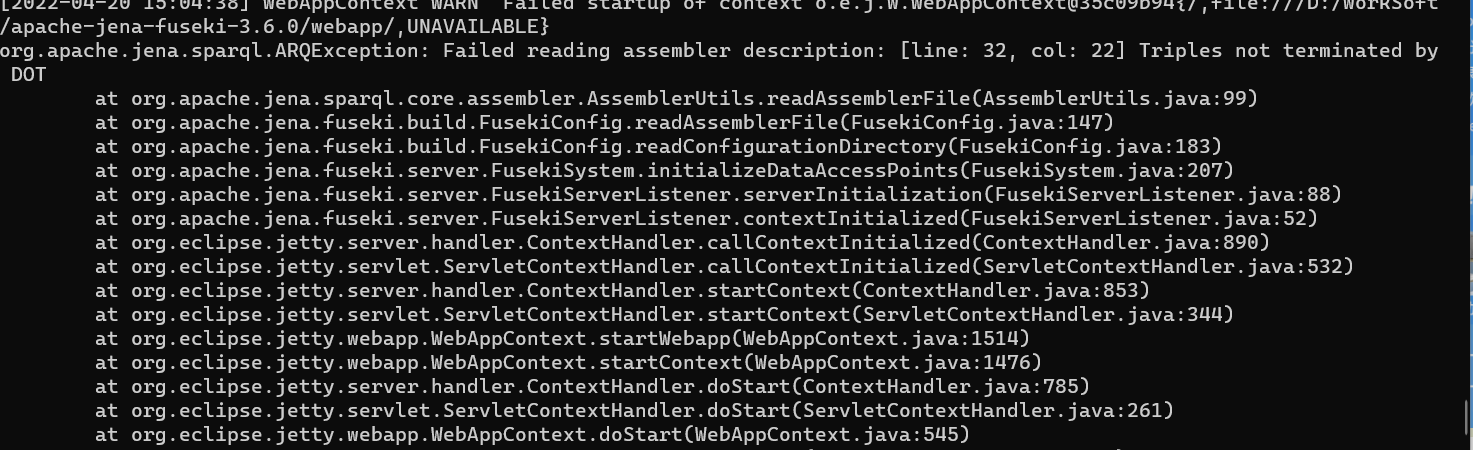
提示的含义是:三元组不是以.结尾的,这个还是去查看ttl文件。
(2) DatasetPrefixesTDB WARN Mangled prefix map: graph name=
java.lang.NullPointerException,截图如下:
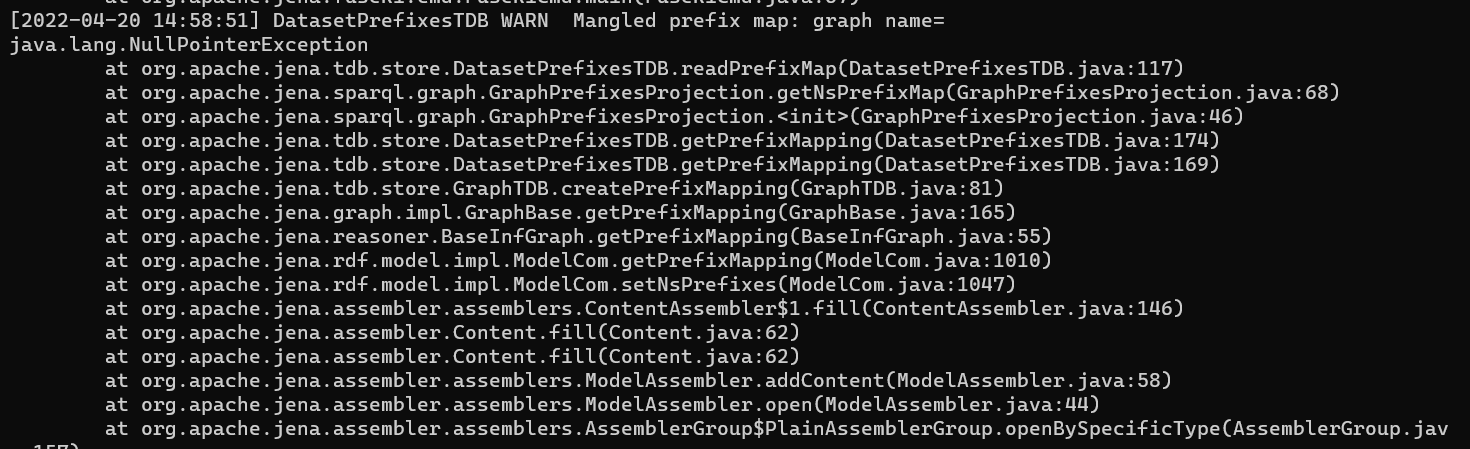
这种大多数原因都是因为上一次关闭Fuseki的时候,使用了Ctrl+Z或者直接kill掉了。 下次再启动的时候,就会报这个,有两个解决办法:
第一个:到tdb目录下,把所有prefix文件都删除掉,然后再启动
第二个:修改ttl文件,把ja:baseModel
其他小问题,参考这篇博客。
个人总结
再梳理下基本流程:
1、使用protege或者手工或者api创建本体文件,说白了,就是定义各种类、关系、属性,就是模式层,按照owl的规范些一个配置文件出来,后缀改成.ttl,这个本体文件需要放到fuseki/run/databases/ 目录下
2、使用D2RQ将数据库中的关系型数据的表创建出对应的 mapping.ttl文件,然后对mapping文件进行修改,主要是修改URI、d2rq:class 、d2rq:property,说白了就是修改本体名字、关系名字和属性名字以及他们的命名空间,这个命名空间就是URI,和本体配置保持一致即可
3、修改好的mapping.ttl文件,使用D2RQ的dump-rdf命令生成对应的RDF文件,默认是N-TRIPLE序列化方式的.nt文件。
4、使用Jean的tdbloader.bat命令将.nt文件加载到Jean识别的TDB中,TDB是Jean的存储系统
5、在fuseki的fuseki/run/configuration/目录下新增一个xxx.ttl文件,创建一个DataSet的配置文件,主要是设置dataset的名称、支持的方法,比如:query/sparql/get/update等。同时指定对应的本体文件、推理规则、tdb数据库地址。 【注意,这里也可以不指定DataSet的配置文件,直接通过fuseki-server.bat启动的时候指定tdb位置也可以】
6、在fuseki目录下,fuseki-server.bat启动
7、在浏览器中输入:http://localhost:3030,进入控制台,可以进行查询相关操作
其他
在上面的步骤中,当我们已经从关系型数据库的数据将数据转换并加载到.nt文件后,可以直接通过命令行的方式启动一个只读和查询的DateSet,例如通过如下方式启动:
.\fuseki-server.bat --file=D:\kg_demo_movie.nt --debug /kgmovie
#或者使用如下命令,不要--dubug也可以
.\fuseki-server.bat --file=D:\kg_demo_movie.nt /kgmovie
–file指定.nt文件位置
–dubug 后面是固定的/xxx,是DateSet的名称,启动后,查看Fuseki,如下:
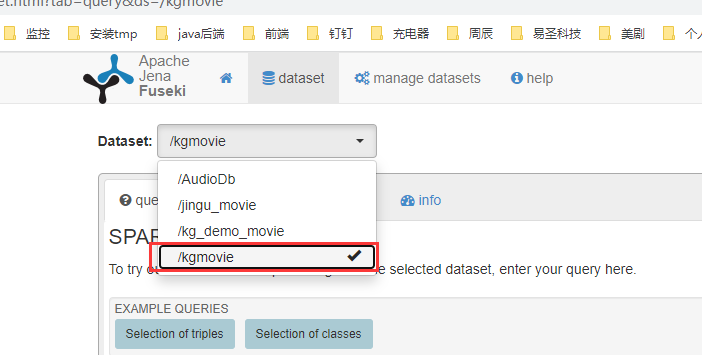
可以看到,/kgmovie已经有了,并且可以进行查询,但是不支持推理,因为没有启动推理机。
参考文献
【2】System Properties Comparison Apache Jena – TDB vs. Neo4j
【3】 创建知识图谱时apache-jena提供了一整套的框架,为什么还要用neo4j数据库?
【4】 SimmerChan/KG-demo-for-movie
【5】 知识存储之Apache Jena
【6】关系数据库到RDF
【7】 数据准备和本体建模
【8】 Apache jena SPARQL endpoint 实践异常解决
Original: https://blog.csdn.net/liangcha007/article/details/124644434
Author: 凉茶冰
Title: 初识Jena
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/554753/
转载文章受原作者版权保护。转载请注明原作者出处!