

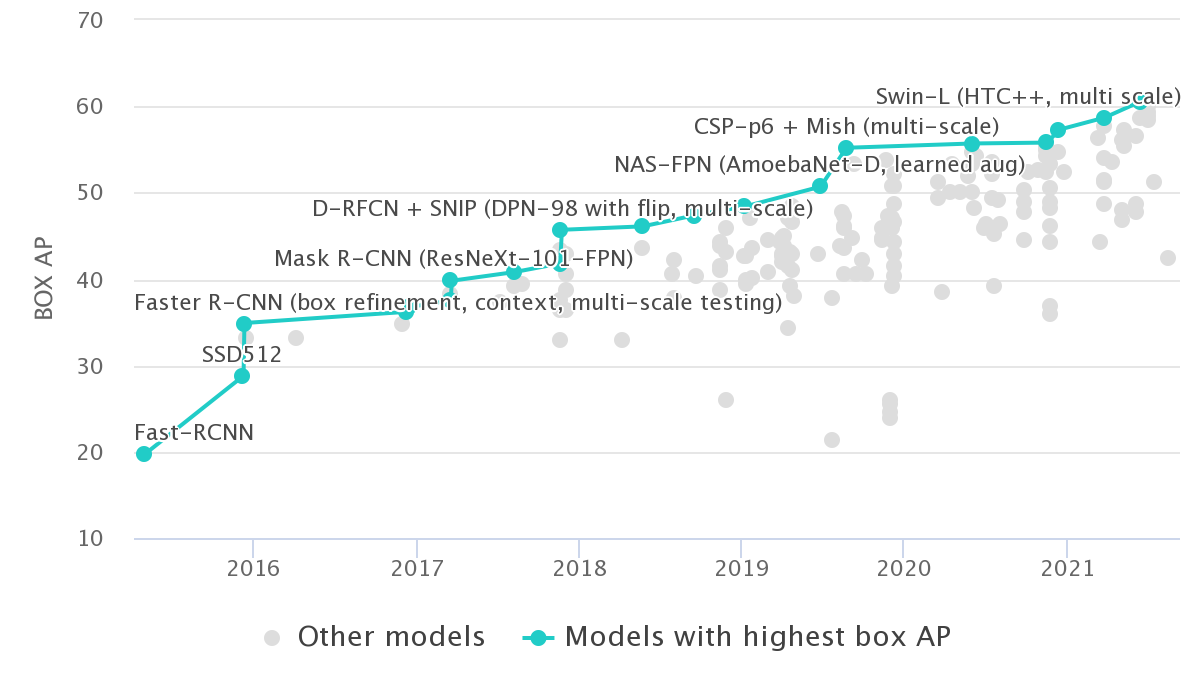

【前言】 近几年目标检测的落地越发成熟,新的sota网络同样层出不穷,不断刷新着coco的记录。本文盘点截止2019-2021年,在coco test-dev上霸榜,且知名度较广的目标检测网络(未完全开源不加入讨论)。
; 1. Swin Transformer V2
title: Swin Transformer V2: Scaling Up Capacity and Resolution
code:https://github.com/ChristophReich1996/Swin-Transformer-V2
paper:https://arxiv.org/pdf/2111.09883v1.pdf
简介: 微软作品,展示了将 Swin Transformer 扩展到 30 亿个参数并使其能够使用高达1,536输入尺寸的图像进行训练的sota探讨。通过扩大网络容量和分辨率,Swin Transformer 在四个具有代表性的视觉基准上创造了新记录:ImageNet-V2 图像分类的 84.0% top-1 准确率,COCO 对象检测的 63.1/54.4 box/mask mAP,ADE20K 语义分割的 59.9 mIoU, Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。Swin Transformer V2使用的技术通常为扩大视觉模型,但它没有像 NLP 语言模型那样被广泛探索,部分原因在于训练和应用方面,存在以下困难:1)视觉模型经常面临大规模不样本不均衡的问题;2)许多下游视觉任务需要高分辨率图像或滑动窗口,目前尚不清楚如何有效地将低分辨率预训练的模型转换为更高分辨率的模型;3)当图像分辨率很高时,GPU 内存消耗也是一个问题。为了解决这些问题,该研究团队提出了几种技术,并通过使用 Swin Transformer 作为案例研究来说明:1)后归一化技术和缩放余弦注意方法来提高大型视觉模型的稳定性;2) 一种对数间隔的连续位置偏差技术,可有效地将在低分辨率图像和窗口上预训练的模型转移到其更高分辨率的对应物上。此外,团队分享了关键实现细节,这些细节可以显著节省 GPU 内存消耗,从而使使用常规 GPU 训练大型视觉模型的方案变得可行。

注:box AP 63.1%为添加额外数据集情况。
2. Dynamic Head
title:Dynamic Head: Unifying Object Detection Heads with Attentions
code:https://github.com/microsoft/DynamicHead
paper:https://openaccess.thecvf.com/content/CVPR2021/papers/Dai_Dynamic_Head_Unifying_Object_Detection_Heads_With_Attentions_CVPR_2021_paper.pdf
简介: 微软作品,在目标检测中结合定位和分类的方式一直处在发展之中,以前的工作为了提高各种检测头的性能,但未能形成统一的观点。在本文中,团队提出了一种新颖的动态头部框架来统一检测头和注意力。通过在用于尺度感知的特征级别之间、在用于空间感知的空间位置之间以及在用于任务感知的输出通道内,连贯地结合多种自注意力机制,所提出的方法显着提高了检测头的表达能力,而无需任何计算开销。

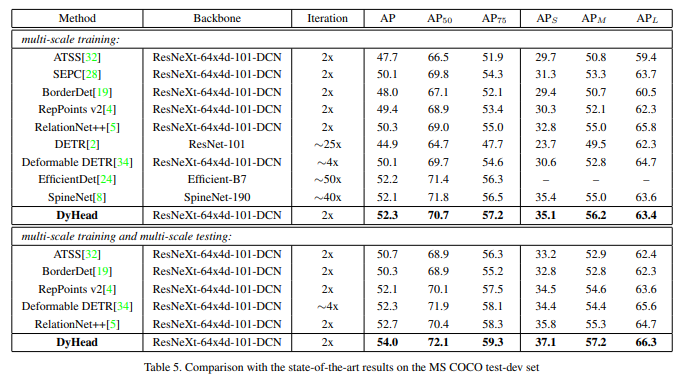
coco test-dev: box AP = 54.00%
; 3. Swin Transformer
title:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
code:https://github.com/microsoft/Swin-Transformer
paper:https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.pdf
简介: 微软作品,2021年CVPR的best paper,曾在知乎刮起一阵讨论热风,该paper介绍了一种名为 Swin Transformer 的新视觉 Transformer,能够作为计算机视觉的通用主干,将 Transformer 从语言nlp引入到cv中。作者提出了一种hierarchical Transformer,其表示通过移位窗口计算。移位窗口方案通过将self-attention计算限制在不重叠的局部窗口内,同时还允许跨窗口连接,带来了更高的效率。这种分层体系结构可以在不同尺度上建模,并且在图像大小方面的计算复杂度为O(N)。
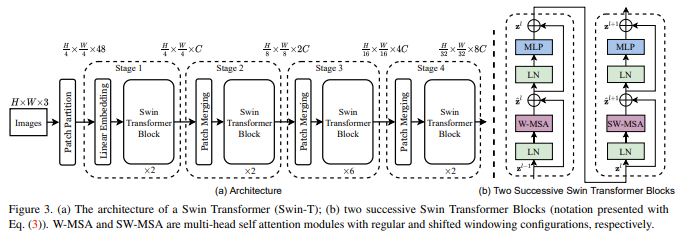
该网络结构作为目标检测的主干网络,当年发布时实现了对之前其他sota网络的碾压。
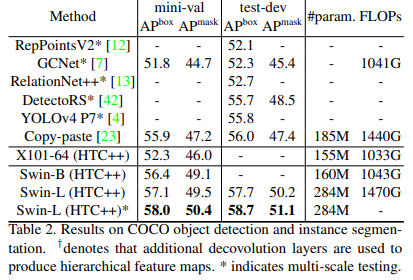
注:box AP = 58.70%为添加了额外数据集
4. DetectoRS
title: DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
code:https://github.com/joe-siyuan-qiao/DetectoRS
paper:https://openaccess.thecvf.com/content/CVPR2021/papers/Qiao_DetectoRS_Detecting_Objects_With_Recursive_Feature_Pyramid_and_Switchable_Atrous_CVPR_2021_paper.pdf
简介: 许多现代物体检测器通过使用两次观察和思考的机制表现出出色的性能。在本文中,作者在目标检测的主干设计中探索了这种机制。在宏观层面,提出了递归特征金字塔,将来自特征金字塔网络的额外反馈连接合并到自下而上的主干层中。
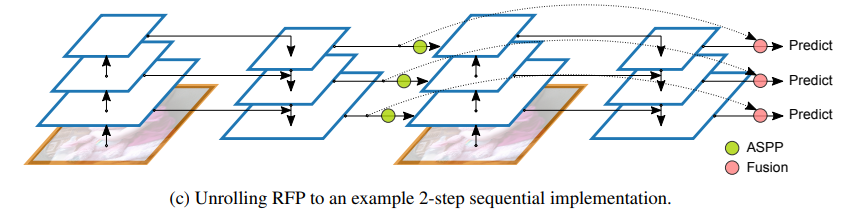
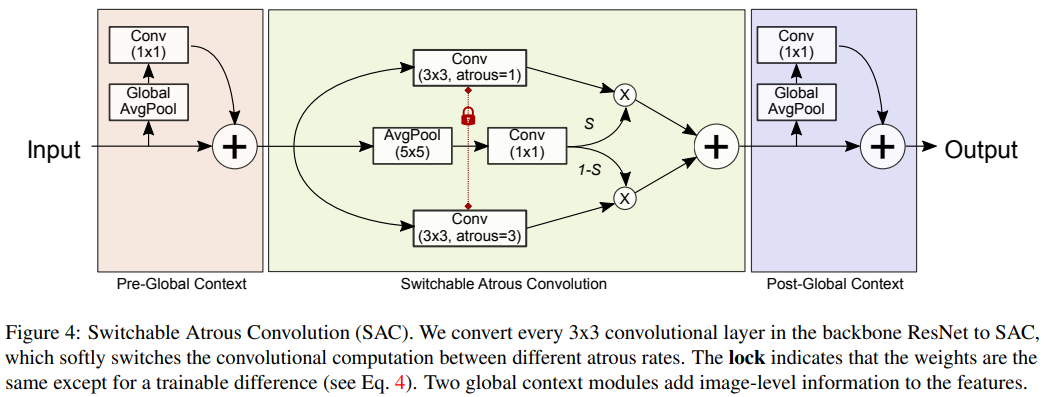
在微观层面,作者提出了 Switchable Atrous Convolution,它对不同 atrous 率的特征进行卷积,并使用 switch 函数收集结果。将它们结合起来会产生 DetectoRS,显着提高了对象检测的性能。
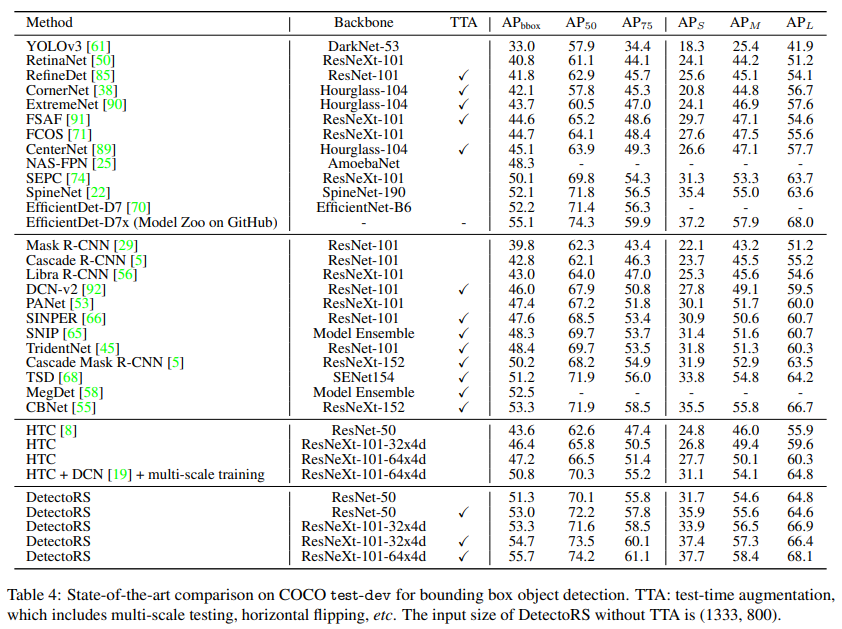
coco test-dev with TTA: box AP= 55.70%
; 5. YOLOF
title:You Only Look One-level Feature
code:https://github.com/megvii-model/YOLOF
paper:NULL
简介: 论文重新审视了一阶段检测器的特征金字塔网络(FPN),并指出 FPN 的成功是由于其对目标检测优化问题的分而治之的解决方案,而不是多尺度特征融合。从优化的角度来看,作者引入了一种替代方法来解决该问题,而不是采用复杂的特征金字塔。论文提出了两个关键组件,即扩张编码器和均匀匹配,并带来了相当大的改进。

在 COCO 基准上的大量实验证明了所提出模型的有效性。在没有 Transformer 层的情况下,YOLOF 可以以单级特征的方式匹配 DETR 的性能更少的训练时期。图像大小为608×608的情况下, YOLOF 在 2080Ti 上以 60 fps 运行时实现了 44.3 mAP,比 YOLOv4 更快。在使用多尺度训练和测试的情况下,实现了47.1 mAP
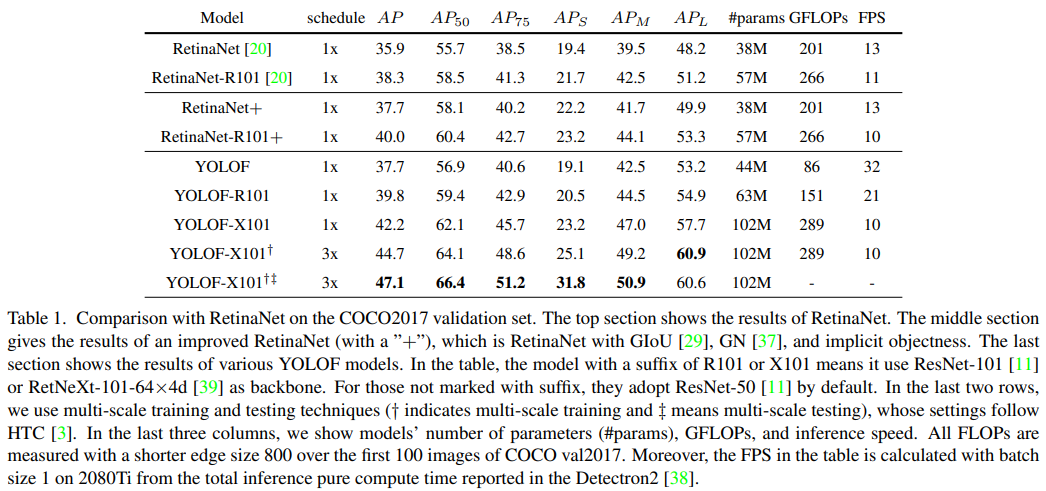
coco test-dev with multi-scale training and multi-scale testing: box AP=47.10%
6. YOLOR
title:You Only Learn One Representation: Unified Network for Multiple Tasks
code:https://github.com/WongKinYiu/yolor
paper:https://arxiv.org/pdf/2105.04206v1.pdf
简介: 人们通过视觉、听觉、触觉以及过去的经验来”理解”这个世界。人类经验可以通过正常学习(称之为显性知识)或潜意识(称之为隐性知识)来学习。这些通过显性知识或隐性知识学习的经验将被编码并存储在大脑中。
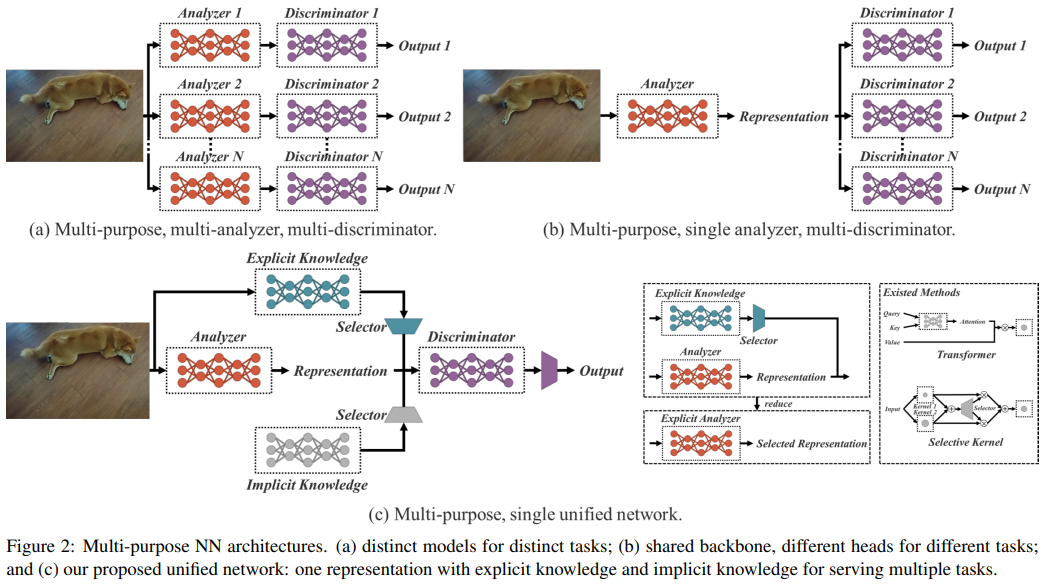
将这些丰富的经验作为一个庞大的数据库,人类可以有效地处理数据,即使是事先看不到的数据。在论文中,作者提出了一个统一的网络,将隐性知识和显性知识编码在一起,就像人脑可以从正常学习和潜意识学习中学习知识一样。统一网络可以生成统一的表示以服务于各种任务。我们可以执行内核空间对齐、预测细化、和卷积神经网络中的多任务学习。结果表明,当将隐式知识引入神经网络时,它有利于所有任务的性能。作者进一步分析了从所提出的统一网络中学习到的隐式表示,它在捕捉不同任务的物理意义表现出很强的能力。
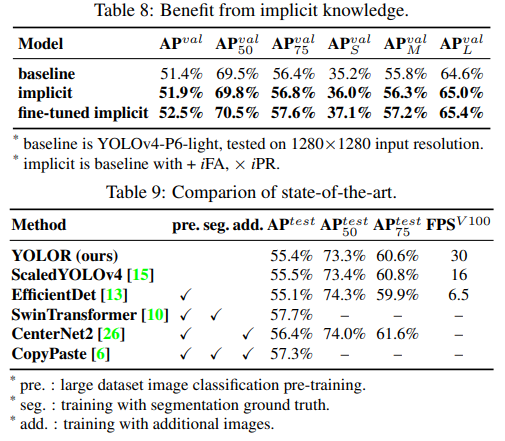
coco test-dev with TTA and 1536×1536: box AP= 55.40%
; 7. YOLOX
title:YOLOX: Exceeding YOLO Series in 2021
code:https://github.com/Megvii-BaseDetection/YOLOX
paper:https://arxiv.org/pdf/2107.08430v2.pdf
简介: 旷视出品,介绍了 YOLO 系列的一些经验改进,形成了一种新的高性能检测器——YOLOX。主要将 YOLO 检测器切换为Anchor free方式并将检测头替换成解耦头,使用领先的标签分配策略 SimOTA,以在大规模模型范围内实现最先进的结果。
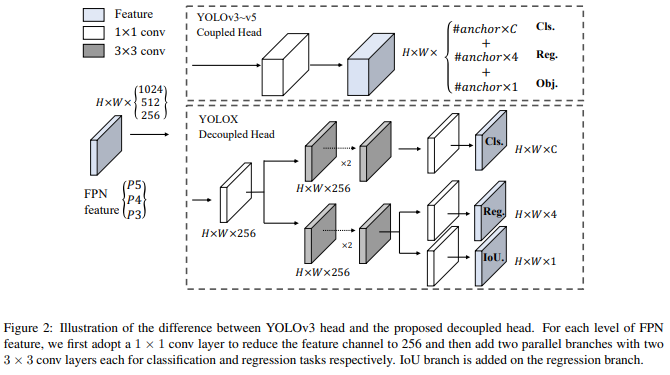
对于参数量与 YOLOv4-CSP、YOLOv5-L 大致相同的 YOLOX-L,在 Tesla V100 上以 68.9 FPS 的速度在 COCO 上实现 50.0%的 AP,超过 YOLOv5-L 1.8% AP。使用单个 YOLOX-L 模型赢得了当年Streaming Perception Challenge 比赛(CVPR 2021 自动驾驶研讨会)的第一名。
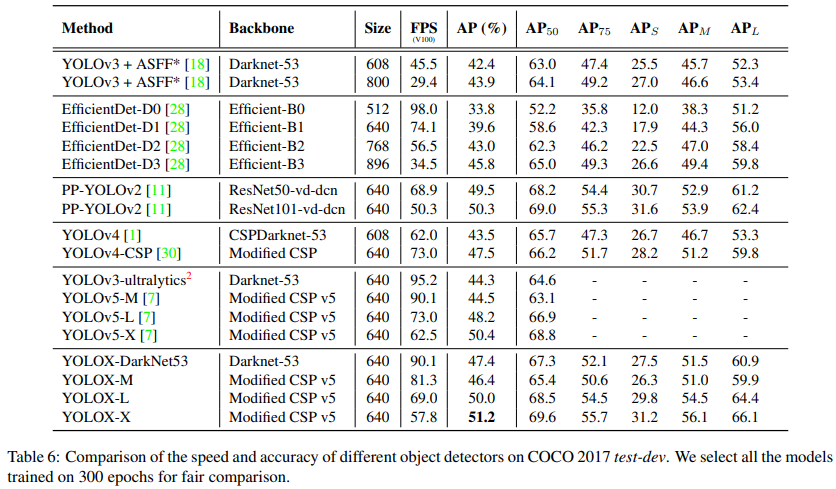
coco test-dev: 目前官网更新到 box AP= 51.50%
8. Scaled-YOLOv4
title:Scaled-YOLOv4: Scaling Cross Stage Partial Network
code:https://github.com/WongKinYiu/ScaledYOLOv4
paper:https://openaccess.thecvf.com/content/CVPR2021/papers/Wang_Scaled-YOLOv4_Scaling_Cross_Stage_Partial_Network_CVPR_2021_paper.pdf
简介: Scale的作者是YOLOv4的二作,YOLOv4的作者是Scaled-YOLOv4的二作(绕柱子),YOLOv4和Scaled-YOLOv4相似,该文也展示了基于CSP方法构建的YOLOv4目标检测神经网络,可向上和向下扩展,适用于小型和大型网络,同时保持最佳速度和准确性。
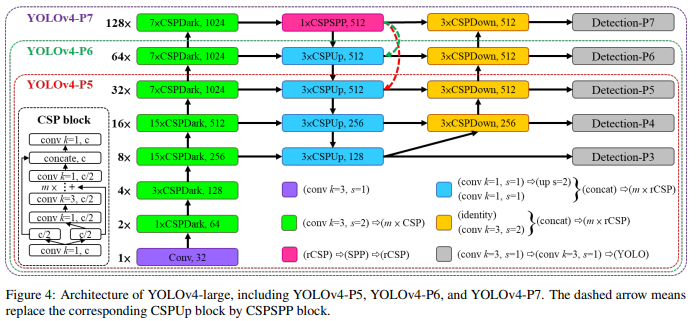
YOLOv4-large 模型取得了最先进的结果:MS COCO 数据集在 Tesla V100 上以 ~16 FPS 的速度获得 55.5% AP(73.4% AP50),而随着测试尺度的增加,YOLOv4-large 达到 55.5 百分比 AP (73.3 AP50)。
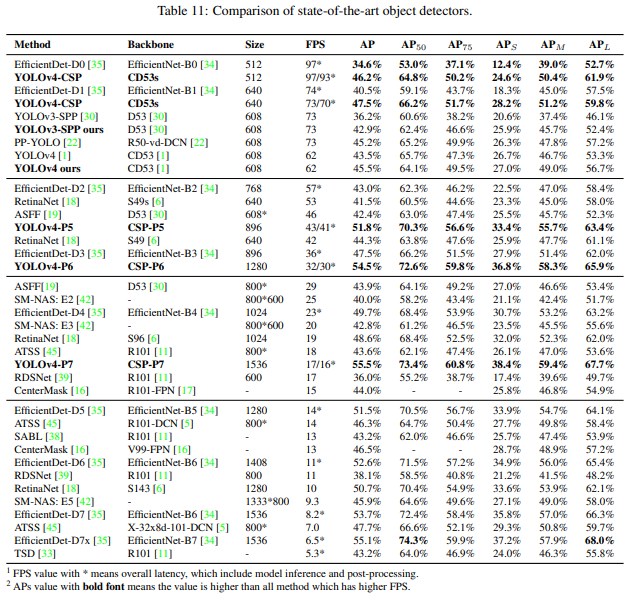
coco test-dev with TTA: box AP= 55.80%
; 9.Scale-Aware Trident Networks for Object Detection
code:https://github.com/tusimple/simpledet
paper:https://openaccess.thecvf.com/content_ICCV_2019/papers/Li_Scale-Aware_Trident_Networks_for_Object_Detection_ICCV_2019_paper.pdf
简介: 尺度变化是目标检测的关键挑战之一。在论文中,作者首先提出一个对照实验来研究感受野对目标检测中尺度变化的影响。基于探索实验的结果,提出了一种新的三叉戟网络(TridentNet),旨在生成具有统一表示能力的特定尺度特征图。通过构建了一个并行的多分支架构,其中每个分支共享相同的转换参数但具有不同的感受野。然后,采用尺度感知训练方案,通过对适当尺度的对象实例进行采样来专门化每个分支进行训练。
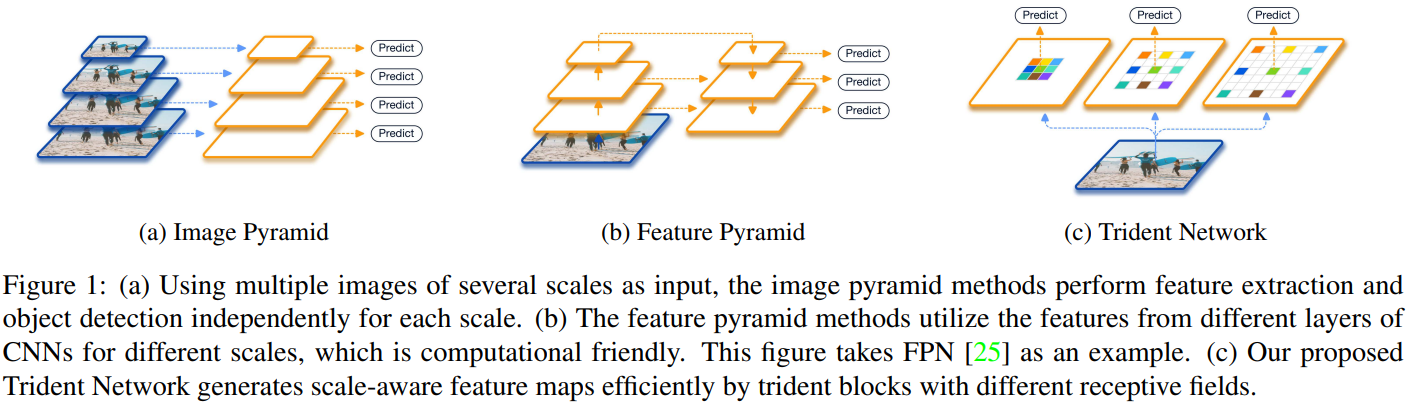
与普通检测器相比,TridentNet 的快速版本可以在没有任何额外参数和计算成本的情况下实现显着改进。在 COCO 数据集上,带有 ResNet-101 主干的 TridentNet 实现了 48.4 mAP 的最先进的单模型结果。
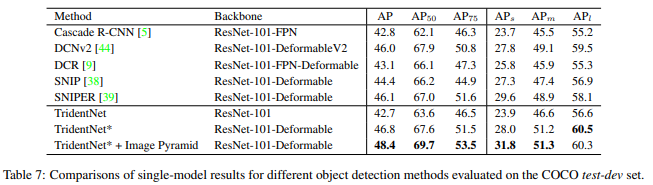
coco test-dev : box AP= 48.40%
10. Detr
title:End-to-End Object Detection with Transformers
code:https://github.com/facebookresearch/detr
paper:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123460205.pdf
简介: 论文提出了一种将目标检测视为直接集合预测问题的新方法,该方法方法简化了检测流程,有效地消除了对许多手工设计op的需求,例如显式编码,包括非最大抑制过程或anchor生成。新框架的主要成分,称为 DEtection TRansformer 或 DETR,是基于集合的全局损失,通过二分匹配强制进行独特的预测,以及encoder-decoder架构。给定一组固定的学习对象查询,DETR 推理对象的关系和全局图像上下文以直接并行输出最终的预测集。与许多其他现代探测器不同,新模型在概念上很简单,不需要专门的库。
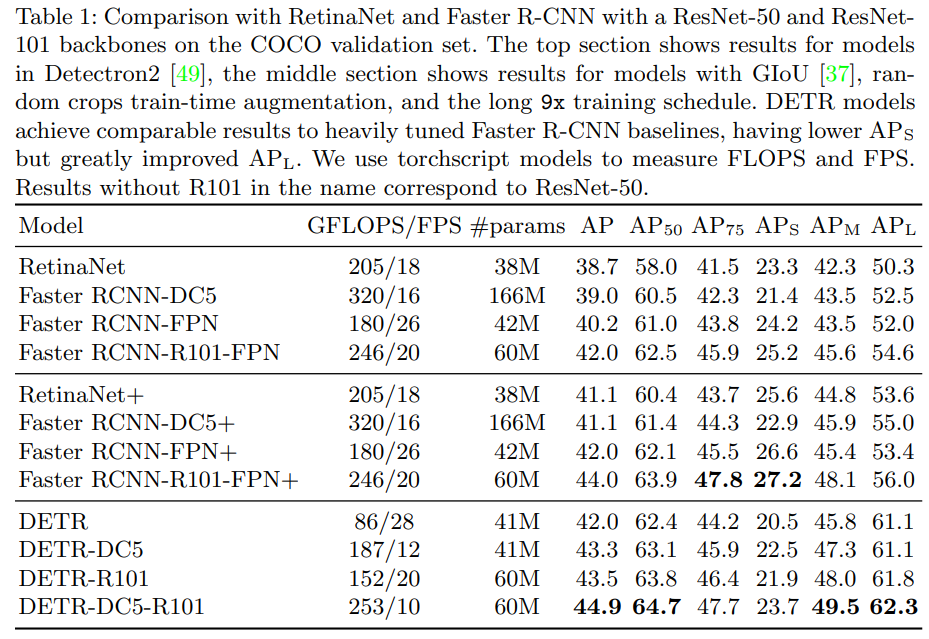
DETR 在COCO 对象检测数据集上展示了与高度优化的 Faster RCNN 基线相当的准确性和运行时性能。
; 11. YOLOv5
code:https://github.com/ultralytics/yolov5
paper:NULL
简介: YOLOv5目前出到了v6.1版本,作者commit相当频繁,目前该仓库的共同开发者有三百多人,且从5.0版本开始,YOLOv5逐渐往落地部署发展,网上关于YOLOv5的讲解也颇多,此处不做复述。
coco test-dev with TTA and 1536×1536: box AP= 55.80%
12. Dynamic R-CNN
code:https://github.com/hkzhang95/DynamicRCNN
paper:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123600256.pdf
简介: Dynamic R-CNN在训练过程中根据proposal的统计数据自动调整标签分配标准(IoU阈值)和回归损失函数的形状(Smooth L1 Loss的参数)。目的是在之前的两阶段目标检测器中,更好的处理固定网络和动态训练过程之间存在不一致问题。例如,固定的标签分配策略和回归损失函数不能适应检测框的分布变化,因此不利于训练高质量的检测器。Dynamic R-CNN由两个组件组成:Dynamic Label Assignment 和 Dynamic Smooth L1 Loss,分别用于分类和回归分支。
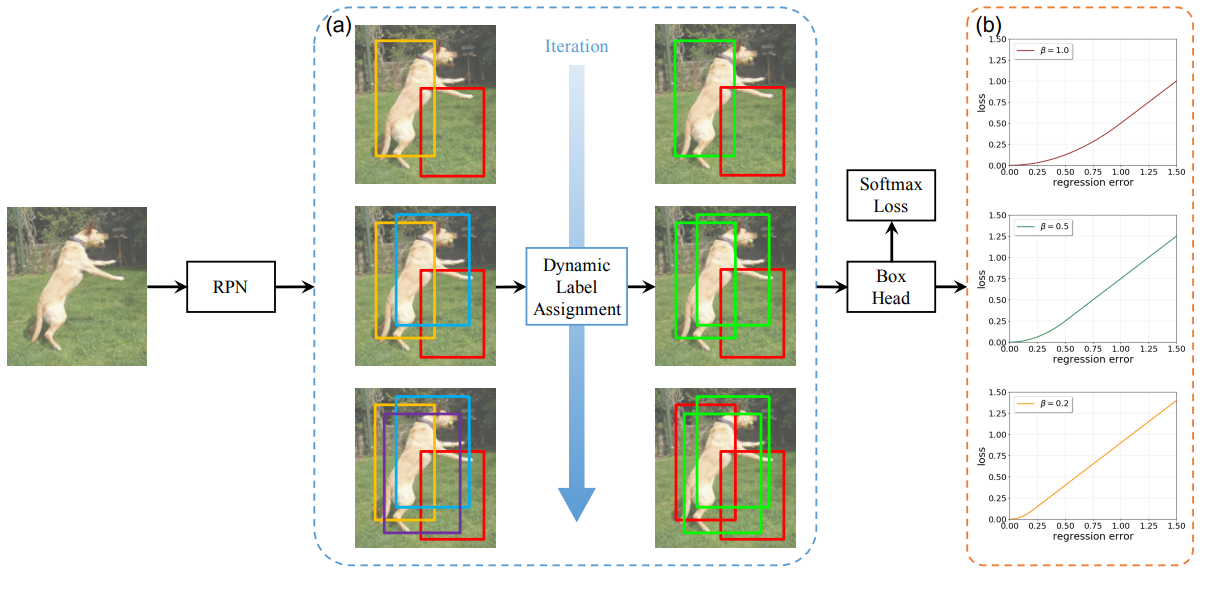
这种动态设计更好地利用了训练样本,并推动检测器拟合更多高质量的样本。该方法方法改进了 ResNet-50-FPN 基线,在 MS COCO 数据集上具有 1.9% 的 AP 和 5.5% 的 AP的提升,没有额外的开销。
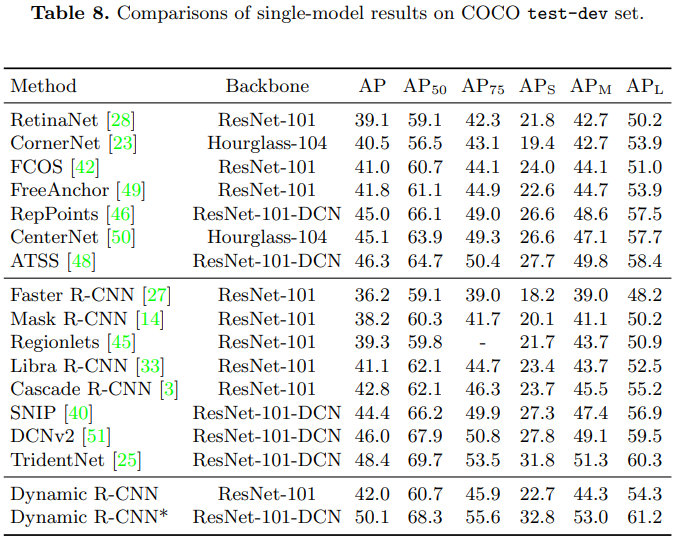
Dynamic R-CNN :FPN-based Faster R-CNN with ResNet-101
Dynamic R-CNN* adopts image pyramid scheme (multi-scale training and testing), deformable convolutions and Soft-NMS.
Original: https://blog.csdn.net/weixin_45829462/article/details/123373053
Author: pogg_
Title: 目标检测2020-2021
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/686520/
转载文章受原作者版权保护。转载请注明原作者出处!