

目录
hidden_layers=7,hidden_dim=256
hidden_layers=12,hidden_dim=512
数据集
音位分类预测(Phoneme classification) ,通过语音数据,预测音位。音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的音位系统。
一帧frame设定为长25ms的音段,每次滑动10ms截得一个frame。每个frame经过MFCC
处理,变成长度为39的向量。对于每个frame向量,数据集都提供了标签。标签有41类, 每个类代表一个phoneme
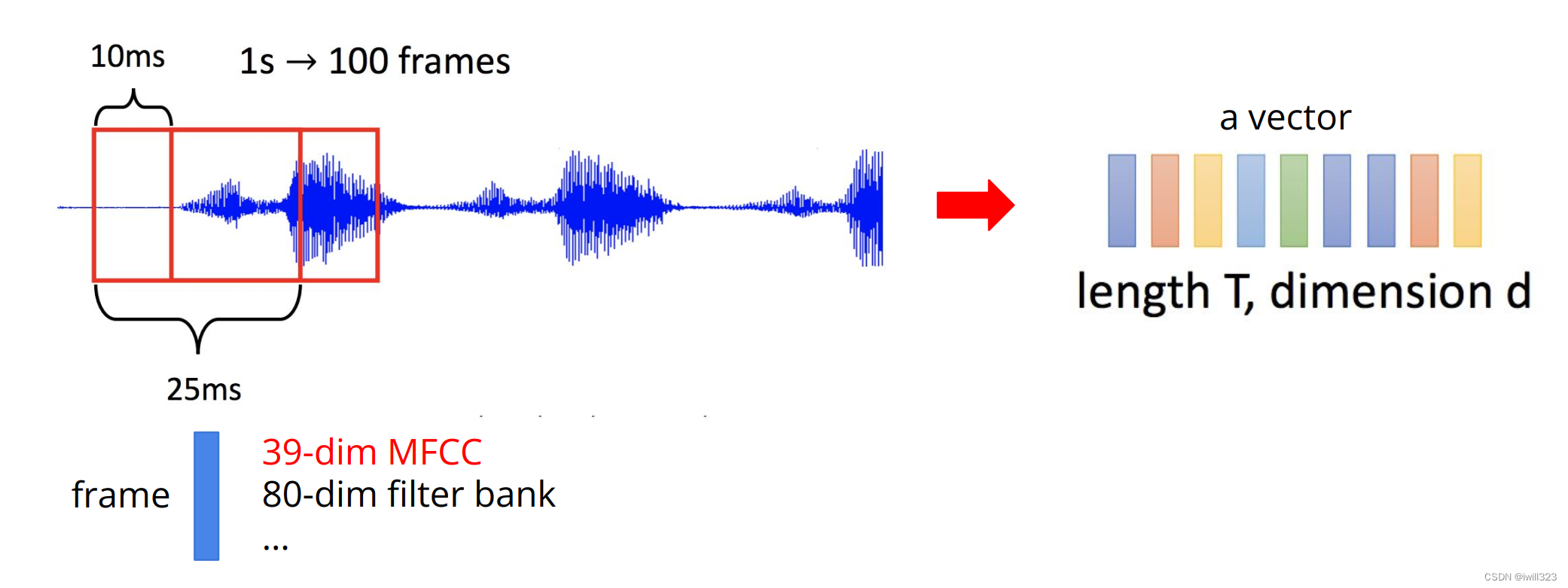

整个训练集是train-clean-100数据集的子集(LibriSpeech),总共有2644158个frame,经过预处理,这些frame被整合进了4268个pt文件


比如,使用作业代码中的load_feat函数,将19-198-0008.pt读入后得到一个tensor变量,它的形状是[284, 39],在train_labels.txt文件中找到19-198-0008这一行,共包含284个数字标签。
同理,测试集总共有646268个frame,被整合成1078个pt文件
导包
import numpy as np
import os
import random
import pandas as pd
import torch
from tqdm import tqdm
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader, TensorDataset
from d2l import torch as d2l
辅助函数
设定种子
#fix seed
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
数据预处理
一个音位可能横跨多个frame,因此需要合并临近的frame,来预测中心frame的音位。

这项工作主要由concat_feat函数完成
读取pt文件
def load_feat(path):
feat = torch.load(path)
return feat
def shift(x, n):
if n < 0:
left = x[0].repeat(-n, 1)
right = x[:n]
elif n > 0:
right = x[-1].repeat(n, 1)
left = x[n:]
else:
return x
return torch.cat((left, right), dim=0)
def concat_feat(x, concat_n):
assert concat_n % 2 == 1 # n must be odd
if concat_n < 2:
return x
seq_len, feature_dim = x.size(0), x.size(1)
x = x.repeat(1, concat_n)
x = x.view(seq_len, concat_n, feature_dim).permute(1, 0, 2) # concat_n, seq_len, feature_dim
mid = (concat_n // 2)
for r_idx in range(1, mid+1):
x[mid + r_idx, :] = shift(x[mid + r_idx], r_idx)
x[mid - r_idx, :] = shift(x[mid - r_idx], -r_idx)
return x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim)
def preprocess_data(split, feat_dir, phone_path, concat_nframes, train_ratio=0.8, train_val_seed=1337):
class_num = 41 # NOTE: pre-computed, should not need change
mode = 'train' if (split == 'train' or split == 'val') else 'test'
label_dict = {}
if mode != 'test':
phone_file = open(os.path.join(phone_path, f'{mode}_labels.txt')).readlines()
for line in phone_file:
line = line.strip('\n').split(' ')
label_dict[line[0]] = [int(p) for p in line[1:]]
if split == 'train' or split == 'val':
# split training and validation data
usage_list = open(os.path.join(phone_path, 'train_split.txt')).readlines() #获取标签列表
random.seed(train_val_seed) # 固定住seed,使得划分出的验证集和训练集没有交集
random.shuffle(usage_list)
percent = int(len(usage_list) * train_ratio)
usage_list = usage_list[:percent] if split == 'train' else usage_list[percent:] # 划分出验证集
elif split == 'test':
usage_list = open(os.path.join(phone_path, 'test_split.txt')).readlines()
else:
raise ValueError('Invalid \'split\' argument for dataset: PhoneDataset!')
usage_list = [line.strip('\n') for line in usage_list]
print('[Dataset] - # phone classes: ' + str(class_num) + ', number of utterances for ' + split + ': ' + str(len(usage_list)))
max_len = 3000000
# X就是最终要得到的样本数据,其中每一行就是一个样本。每一行包含了concat_nframe个frame
X = torch.empty(max_len, 39 * concat_nframes)
if mode != 'test':
y = torch.empty(max_len, dtype=torch.long) # 标签数据
idx = 0
for i, fname in tqdm(enumerate(usage_list)):
feat = load_feat(os.path.join(feat_dir, mode, f'{fname}.pt')) # 读取每一个pt文件,得到一个tensor变量
cur_len = len(feat) # 统计该tensor有多少行,后面对X进行截取
feat = concat_feat(feat, concat_nframes) # 得到以每个frame为中心,扩展了concat_nframes个邻近frame的向量。如果一个frame在边缘,则以他自身代替邻近frame进行扩展
if mode != 'test':
label = torch.LongTensor(label_dict[fname]) # 获取label
X[idx: idx + cur_len, :] = feat # 存入X
if mode != 'test':
y[idx: idx + cur_len] = label
idx += cur_len
X = X[:idx, :] # X有3000000行,超出的部分不要
if mode != 'test':
y = y[:idx]
print(f'[INFO] {split} set')
print(X.shape)
if mode != 'test':
print(y.shape)
return X, y
else:
return X
测试一下concat_feat函数,大体就能知道上面在做什么
x = torch.tensor([[1,2,3],[4,5,6],[7,8,9],[10,11,12],[13,14,15],[16,17,18]])
res = concat_feat(x, 3)
res
tensor([[ 1, 2, 3, 1, 2, 3, 4, 5, 6],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9],
[ 4, 5, 6, 7, 8, 9, 10, 11, 12],
[ 7, 8, 9, 10, 11, 12, 13, 14, 15],
[10, 11, 12, 13, 14, 15, 16, 17, 18],
[13, 14, 15, 16, 17, 18, 16, 17, 18]])
数据集加载
import gc
def loadData(concat_nframes, train_ratio, batch_size):
# preprocess data
train_X, train_y = preprocess_data(split='train', feat_dir='./libriphone/feat', phone_path='./libriphone',
concat_nframes=concat_nframes, train_ratio=train_ratio)
val_X, val_y = preprocess_data(split='val', feat_dir='./libriphone/feat', phone_path='./libriphone',
concat_nframes=concat_nframes, train_ratio=train_ratio)
# get dataset
train_set = TensorDataset(train_X, train_y)
val_set = TensorDataset(val_X, val_y)
print('训练集总长度是 {:d}, batch数量是 {:.2f}'.format(len(train_set), len(train_set)/ batch_size))
print('验证集总长度是 {:d}, batch数量是 {:.2f}'.format(len(val_set), len(val_set)/ batch_size))
# remove raw feature to save memory
del train_X, train_y, val_X, val_y
gc.collect()
# get dataloader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, drop_last=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False, drop_last=True)
return train_loader, val_loader
定义模型
模块化定义模型,Classifier可以指定有多少个隐藏层
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.BatchNorm1d(output_dim),
nn.Dropout(0.3)
)
def forward(self, x):
x = self.block(x)
return x
class Classifier(nn.Module):
def __init__(self, input_dim, output_dim=41, hidden_layers=1, hidden_dim=256):
super(Classifier, self).__init__()
self.fc = nn.Sequential(
BasicBlock(input_dim, hidden_dim),
*[BasicBlock(hidden_dim, hidden_dim) for _ in range(hidden_layers)],
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
x = self.fc(x)
return x
训练函数
采用AdamW优化函数,并且使用CosineAnnealingWarmRestarts来调整lr。使用《动手学深度学习》这本书中的d2l工具包,在训练过程画出loss和accuracy
def trainer(show_num, train_loader, val_loader, model, config, devices):
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=config['learning_rate'])
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=2, T_mult=2, eta_min=config['learning_rate']/50)
n_epochs, best_acc, early_stop_count = config['num_epoch'], 0.0, 0
num_batches = len(train_loader)
if not os.path.isdir('./models'):
os.mkdir('./models') # Create directory of saving models.
legend = ['train loss', 'train acc']
if val_loader is not None:
legend.append('valid loss')
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[0, n_epochs], legend=legend)
for epoch in range(n_epochs):
train_acc, train_loss = 0.0, 0.0
count = 0
# training
model.train() # set the model to training mode
for i, (data, labels) in enumerate(train_loader):
data, labels = data.to(devices[0]), labels.to(devices[0])
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
count += 1
if (i + 1) % (num_batches // show_num) == 0:
train_acc = train_acc / count / len(data)
train_loss = train_loss / count
print('train_acc {:.3f}'.format(train_acc))
animator.add(epoch + (i + 1) / num_batches, (train_loss, train_acc, None, None))
train_acc, train_loss, count = 0.0, 0.0, 0
scheduler.step()
# validation
if val_loader != None:
model.eval() # set the model to evaluation mode
val_acc, val_loss = 0.0, 0.0
with torch.no_grad():
for i, (data, labels) in enumerate(val_loader):
data, labels = data.to(devices[0]), labels.to(devices[0])
outputs = model(data)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1)
val_acc += (val_pred.cpu() == labels.cpu()).sum().item() # get the index of the class with the highest probability
val_loss += loss.item()
val_acc = val_acc / len(val_loader) / len(data)
val_loss = val_loss / len(val_loader)
print('val_acc {:.3f}'.format(val_acc))
animator.add(epoch + 1, (None, None, val_loss, val_acc))
# if the model improves, save a checkpoint at this epoch
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), config['model_path'])
# print('saving model with acc {:.3f}'.format(best_acc / len(val_loader) / len(labels)))
# if not validating, save the last epoch
if val_loader == None:
torch.save(model.state_dict(), config['model_path'])
# print('saving model at last epoch')
读取数据集和训练
读取数据集
concat_nframes是一个重要的参数。课上助教提到可以设置为11,我看到有人说设置的大一点更有利。
李宏毅2022机器学习作业HW2记录 – 知乎:要尽可能的调大concat_nframes的参数,但是这里的参数不能够过大,太大反而会使模型的准确率下降。
concat_nframes = 17 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.9 # the ratio of data used for training, the rest will be used for validation
batch_size = 8192*4 # batch size
train_loader, val_loader = loadData(concat_nframes, train_ratio, batch_size)
训练
devices = d2l.try_all_gpus()
print(f'DEVICE: {devices}')
fix random seed
seed = 0 # random seed
same_seeds(seed)
config = {
# training prarameters
'num_epoch': 3, # the number of training epoch
'learning_rate': 1e-3, # learning rate
# model parameters
'hidden_layers': 12, # the number of hidden layers
'hidden_dim': 256 # the hidden dim
}
config['model_path'] = './models/model' + str(config['learning_rate']) + '-' + str(config['hidden_layers'])
... + '-' + str(config['hidden_dim']) + '.ckpt' # the path where the checkpoint will be saved
input_dim = 39 * concat_nframes # the input dim of the model, you should not change the value
model = Classifier(input_dim=input_dim, hidden_layers=config['hidden_layers'],
hidden_dim=config['hidden_dim'])
model = nn.DataParallel(model, device_ids = devices).to(devices[0])
trainer(5, train_loader, val_loader, model, config, devices)
删除内存中的数据,节省空间
del train_loader, val_loader
gc.collect()
预测
预测函数
def pred(test_loader, model, devices):
test_acc = 0.0
test_lengths = 0
preds = []
model.eval()
with torch.no_grad():
for batch in tqdm(test_loader):
features = batch[0].to(devices[0])
outputs = model(features)
_, test_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
preds.append(test_pred.cpu())
preds = torch.cat(pred, dim=0).numpy()
return preds
进行预测
load data
test_X = preprocess_data(split='test', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes)
test_set = TensorDataset(test_X)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
load model
model = Classifier(input_dim=input_dim, hidden_layers=config['hidden_layers'],
hidden_dim=config['hidden_dim'])
model = nn.DataParallel(model, device_ids = devices).to(devices[0])
model.load_state_dict(torch.load(config['model_path']))
pred = pred(test_loader, model, devices)
output
with open('prediction.csv', 'w') as f:
f.write('Id,Class\n')
for i, y in enumerate(pred):
f.write('{},{}\n'.format(i, y))
解答
我把concat_nframes固定为17,主要调了hidden_layers和hidden_dim两个参数。如果想达到boss line,需要采用更复杂的模型。可以参考李宏毅2022机器学习HW2解析_机器学习手艺人的博客-CSDN博客_李宏毅机器学习作业2
训练过程:

结果:

这个例子没有认真做,已经比较接近Medium baseline: 0.69747了
我试了一下hidden_layers=12,hidden_dim=256,结果改进有限,于是加大每次的宽度,变成512
训练过程可以看到明显的波浪线,这是因为使用CosineAnnealingWarmRestarts来调整lr的缘故

结果和Strong baseline: 0.75028相差约0.3%,继续训练下去应该能超过Strong baseline

讨论
更宽还是更深
在改变模型参数的时候,有两个选择,是变深还是变宽
李宏毅2022机器学习HW2解析_机器学习手艺人的博客-CSDN博客_李宏毅机器学习作业2
采用了concat_nframes=19,hidden_layers=3,hidden_dim=1024,模型参数量3,958,825,也超过了Strong baseline。
我尝试的concat_nframes=17,hidden_layers=12,hidden_dim=512,模型参数量3,526,185,得分比上面模型低0.7%。层数由3变成了12,因为每一次更窄了,参数量反而减少了11%。
有很多文章提到,网络应该更深,而不是更宽( 可以参考Goodfellow深度学习笔记–神经网络架构_iwill323的博客-CSDN博客_goodfellow深度学习),上面对比可以作为一个印证。
我试着把模型变得右窄又深,hidden_layers=18,hidden_dim=256,但是结果不好
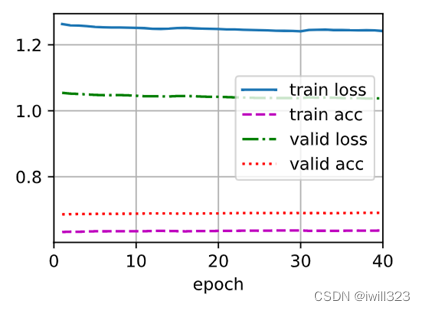

可以看到训练误差比较大,优化做的不够好。可能是因为模型变深了之后,优化的难度加大了
学习率的影响
作为一个小白,感受到,一开始尝试一个学习率太重要了,稍微运行几个epoch就能看出来了。从下面可以发现,1e-3到1e-2比较合适
1e-1

1e-2
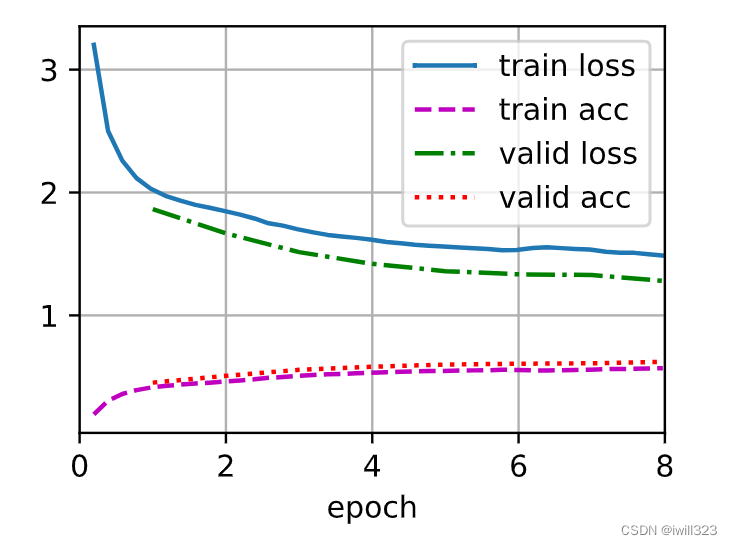
1e-3

1e-4

1e-5

batch size影响
这一块内容老师上课降得很清楚了,直接放图:

可以参考:
Goodfellow花树学习笔记–深度模型中的优化_iwill323的博客-CSDN博客
下面我使用concat_nframes = 5, hidden_layers=1, hidden_dim=64,在CPU上运行3个epoch
batch size耗时(s)8255364449128272 256187
batch size增大n倍,耗时的减少比n倍小一些,比n/2倍大一些。
为了算的快一点,把batch_size = 8192 * 4,算是很大了。曾经把batch size设的特别大,发现len(val_dataloader)=0,不明白为什么,然后发现batch_size比264570还要大,被drop last了。在训练之出,找到一个合适的batch size很重要。
Original: https://blog.csdn.net/iwill323/article/details/127812090
Author: iwill323
Title: 李宏毅机器学习作业2——音位分类预测
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/655864/
转载文章受原作者版权保护。转载请注明原作者出处!