

一、为什么?
对样本做回归分析的 核心是使用最小二乘法去估计模型里的 参数,比如核心解释变量前面的系数。我们通过最小二乘法使得残差平方和最小,求得 样本估计系数。如果进行一次估计,由于 干扰项e的存在,估计值与真实值之间一定存在差异。样本估计值与真实值之间的差别中, 误差项起了关键作用。
误差项是一个随机变量,每次估计都会得到不同的差异值。关于样本估计系数性质的讨论,都以 误差项为核心。我们希望样本估计系数特别好,接近真实值,所以必须有良好的性质,而良好的性质需要有前提条件,也就是一些假设。
比如,我们希望反复抽取多个样本得到多个样本估计系数,之后求平均值就等于真实系数,即无偏性,那么就需要 干扰项e满足均值为零的假设(反复抽样消除干扰项的影响),就可以使得误差项均值为零,那么就可以使得样本估计系数的期望等于真实值。
由于每次抽样得到的估计系数都会不同,我们希望知道估计系数值分布的分散度,或者估计系数平均偏离真实值的程度,或者估计系数可能的误差范围,或者估计系数的精确程度。
如果误差范围越小,样本估计系数接近真实值的可能性就越大。这个用标准差来衡量,估计系数的标准差称为系数标准误。
1.1 异方差
1.1.1 异方差的后果


1.1.2 异方差的例子


1.2.1 自相关的后果
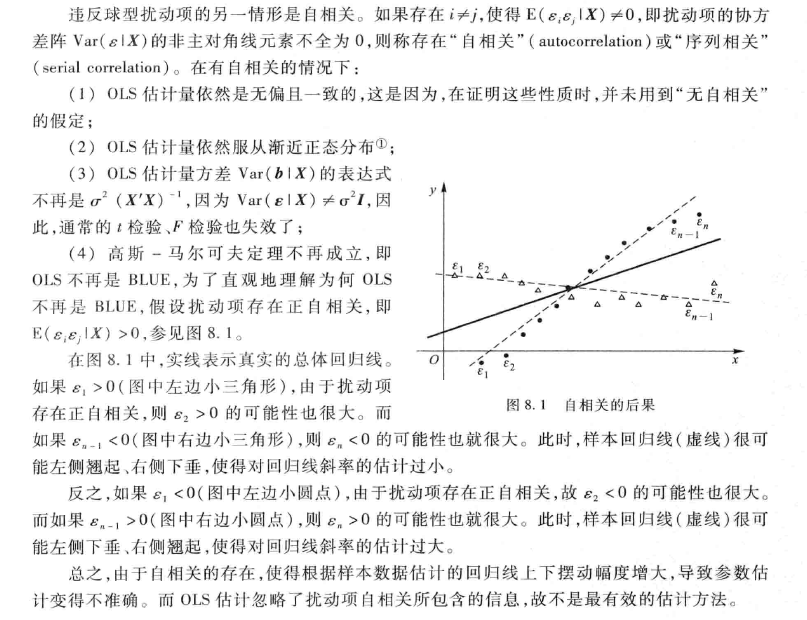
1.2.2 自相关的例子

二、有什么?
2.1 普通标准误——同方差+不相关
干扰项协方差矩阵的形式是决定样本估计系数方差的关键。当求估计系数的方差的时候,需要求得干扰项的协方差矩阵,其主对角线上是第 i 个观测点的干扰项的方差,对角线外的项是第 i 个观测点和第 j 个观测点干扰项的协方差。
我们先提出两个假设来简化协方差矩阵: 干扰项同方差假设和干扰项不相关假设。前者的含义是每个观测点干扰项的方差大小是相同的,后者的含义是不同观测点干扰项是不相关的。两种合起来的 本质就是每个观测点的干扰项是从独立同分布中产生的。
这时候协方差矩阵就变得很简单,主对角线数值相同,主对角线以外是零。但是还有一个问题,里面有干扰项的方差,这是未知的,只能估计,需要利用样本残差值去估计。最终就能得到同方差和不相关假设下的 ols系数估计值方差的估计量,开根号,然后就可以得到系数标准误差的估计量。这就是求得了 系数估计值的标准误。
2.2异方差稳健标准误:异方差+不相关
现实中,会出现异方差的问题,即每个观测点的干扰项方差是不相等的,但是还是干扰项不相关。这意味着每个点的干扰项是从独立但是不相同的分布中产生的。这时候不影响估计系数的无偏性和一致性,但是标准误不能再按照之前的求法了,否则就会 影响我们对系数估计值和真实值之间误差范围的 判断,也就是说误差范围求的不准了。这时候就需要找到在异方差情况下正确的ols系数估计量方差。即求 异方差稳健标准误。
这时候干扰项的协方差矩阵是对角矩阵,主对角线上不同观测点的方差可以是不同值,主对角线之外还是零。这时候计算的难点在于异方差矩阵包含了N个参数,即每个观测点的干扰项e都有自己的方差,但样本的每个观测点只能得到一个残差值。N个残差值无法提供足够的信息估计出N个方差。White指出在大样本下,只需要将干扰项协方差矩阵中的方差用对应的样本残差值替代即可。得到系数估计值方差的估计量,开根号,就可以得到 异方差稳健标准误。
2.3聚类稳健标准误
2.3.1异方差+自相关
当出现自相关时, 即不同观测点的干扰项是相关的。常见于时间序列数据。通常自相关伴随着异方差。这意味着每个观测点的 干扰项是从相关并不相同的分布中产生的。
此时干扰项的协方差矩阵主对角线是不同的,对角线外也不为零。这时候估计方法是用相应的样本残差平方替代方差,样本残差乘积替代协方差。
2.3.2聚类稳健标准误:异方差+组内相关+组间不相关
当出现同一个类别内的干扰项相关,不同类别间的干扰项不相关,同时存在异方差,这时候又需要变化标准误的求法,即 聚类稳健标准误。这时候干扰项的协方差矩阵由两层次组成:大的层次是将所有的观测点分组,按组来组成协方差矩阵,主对角线是不同的组的协方差矩阵,主对角线外是零,即 异方差+组间不相关;小的层次是进入每个组,每个组都是一个协方差矩阵,主对角线是各个观测点的方差,主对角线外是协方差,即 异方差+组内相关,类似于异方差+自相关。求法还是按照之前的用残差来估计。最终得到 聚类稳健标准误。当分组到个体层面,那么就变成了自己跟自己相关,以及自己跟别人无关,其实就变成了不相关,即异方差+不相关,即 异方差稳健标准误。
使用聚类标准误的前提是,聚类中的个体数较少,而聚类数很多;此时,聚类标准误是真实标准误的一致估计。
2.4总结
- 估计系数的标准差称为系数标准误,目的是希望了解估计系数平均偏离真实值的程度, 误差范围越小,样本估计系数接近真实值的可能性就越大。
2. 同方差和不相关假设下,用普通标准误;异方差和不相关假设下,用异方差稳健标准误;异方差、组内相关、组间无关假设下,用聚类稳健标准误。
3. 在哪个层面选择聚类?
这里估计系数方差的估计量有一个权衡:偏差与方差。当样本数量一定的时候,规模更大的集群考虑到了更广泛的相关项,偏差更小,但同时造成更少的集群数量,因此集群方差的估计较为不精确,方差更大。 一般的共识是在没有由于集群数量过少引发问题的情况下,尽量使用更大的集群。合适的聚类层级需要依研究情境和数据特征而异。 一个经验法则是:当核心解释变量的数据层级高于被解释变量时,标准误应聚类到核心解释变量所在层级。
此外,还有双向聚类和交互聚类。比如双向聚类在省份与行业层面,或者行业省份聚类。前者的含义是不仅仅要使得同一个省份内的不同个体的干扰项相关,还要使得同一个行业的不同个体的干扰项相关,这比单独的省份层面聚类或行业层面聚类都更加严格。后者的含义是要使得同一个省份以及同一个行业的不同个体的干扰项相关,这个要求就比较宽松。省份与行业双向聚类=省份聚类+行业聚类-省份行业聚类(因为省份聚类中包括省份行业聚类,行业聚类中也包括省份*行业聚类,所以需要减去一份)。
- stata操作
4.1异方差稳健标准误
reg y x,r
=reg y x,robust
=reg y x,vce(robust)
4.2聚类稳健标准误
group是要聚类的层面,比如企业id、省份province、产业industry等
reg y x,cluster(group)
=reg y x,vce(cluster group)
xtreg y x,fe r
=xtreg y x,fe cluster(id)
=xtreg y x,fe vce(cluster id) 个体层面聚类
4.3交叉聚类
比如省份与行业交互,同一省份的同一产业组内相关,组间无关
egen province_industry=group(province industry)
sort province industry
reg y x,vce(cluster province_industry)
reg y x,cluster(province_industry)
4.4双向聚类
参见cgmreg或vce2way或vcemway
4.5 输出标准误结果
outreg2 using Table2,word drop(_I*) dec(3) tdec(3) bdec(3) alpha(0.01,0.05,0.1) symbol(***,**,*) stats(coef tstat) e(r2_a) se append
Original: https://blog.csdn.net/celine0227/article/details/124405756
Author: celine0227
Title: 聚类稳健标准误
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549492/
转载文章受原作者版权保护。转载请注明原作者出处!