

拟合,顾名思义就是通过对数据的分析,找到数据之间的数学关系,把这种关系的本质理解的越深,得到的拟合度就越高,越能清晰描述数据间的相互联系。拟合有线性拟合和非线性拟合(多项式拟合)。本文着重线性拟合的思想,因为非线性拟合通过一定方法可以转换为线性拟合。演示代码用python实现。
我们有一组点序列(x0,y0),(x1,y1),(x2,y2),…(xn,yn)。假如y与x是线性关系,可以表示为y=ax+b(直线方程),那么拟合就是要得到a和b这两个参数的值。得到最佳的a与b,从而使得点序列中所有点到此直线的距离之和最短。
完成一个拟合的练习,这里练习代码的思路是:
-
指定好a和b的值,即模型已知(便于对比最后结果的准确度),生成一组数据X和Y。
-
给数据增加噪声,生成待拟合的样本数据。
-
本代码中提供了三种方法来拟合样本。



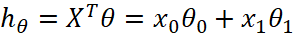
三种方法中选择1种进行拟合,从样本数据中计算权重参数a_和b_。
4.将拟合到的结果可视化
import numpy as np
from sklearn.linear_model import LinearRegression
from matplotlib import pyplot as plt
SAMPLE_NUM = 100
print("您当前的样本数目为:",SAMPLE_NUM)
先预设一个结果,假定拟合的结果为 y=-6x+10
X = np.linspace(-10, 10, SAMPLE_NUM)
a = -6
b = 10
Y = list(map(lambda x: a * x + b, X))
print("标准答案为:y={}*x+{}".format(a, b))
增加噪声,制造数据
Y_noise = list(map(lambda y: y + np.random.randn()*10, Y))
plt.scatter(X, Y_noise)
plt.title("data to be fitted")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
A = np.stack((X, np.ones(SAMPLE_NUM)), axis=1) # shape=(SAMPLE_NUM,2)
b = np.array(Y_noise).reshape((SAMPLE_NUM, 1))
print("方法列表如下:"
"1.最小二乘法 least square method "
"2.常规方程法 Normal Equation "
"3.线性回归法 Linear regression")
method = int(input("请选择您的拟合方法: "))
Y_predict=list()
if method == 1:
theta, _, _, _ = np.linalg.lstsq(A, b, rcond=None)
# theta=np.polyfit(X,Y_noise,deg=1) 也可以换此函数来实现拟合X和Y_noise,注意deg为x的最高次幂,线性模型y=ax+b中,x最高次幂为1.
# theta=np.linalg.solve(A,b) 不推荐使用
theta = theta.flatten()
a_ = theta[0]
b_ = theta[1]
print("拟合结果为: y={:.4f}*x+{:.4f}".format(a_, b_))
Y_predict = list(map(lambda x: a_ * x + b_, X))
elif method == 2:
AT = A.T
A1 = np.matmul(AT, A)
A2 = np.linalg.inv(A1)
A3 = np.matmul(A2, AT)
A4 = np.matmul(A3, b)
A4 = A4.flatten()
a_ = A4[0]
b_ = A4[1]
print("拟合结果为: y={:.4f}*x+{:.4f}".format(a_, b_))
Y_predict=list(map(lambda x:a_*x+b_,X))
elif method == 3:
# 利用线性回归模型拟合数据,构建模型
model = LinearRegression()
X_normalized = np.stack((X, np.ones(SAMPLE_NUM)), axis=1) # shape=(50,2)
Y_noise_normalized = np.array(Y_noise).reshape((SAMPLE_NUM, 1)) #
model.fit(X_normalized, Y_noise_normalized)
# 利用已经拟合到的模型进行预测
Y_predict = model.predict(X_normalized)
# 求出线性模型y=ax+b中的a和b,确认是否和我们的设定是否一致
a_ = model.coef_.flatten()[0]
b_ = model.intercept_[0]
print("拟合结果为: y={:.4f}*x+{:.4f}".format(a_, b_))
else:
print("请重新选择")
plt.scatter(X, Y_noise)
plt.plot(X, Y_predict, c='green')
plt.title("method {}: y={:.4f}*x+{:.4f}".format(method, a_, b_))
plt.show()

结果分析,代码中生成的样本为100个点,上图为得到的拟合结果。如果要得到更准确的拟合结果,不妨设置SAMPLE_NUM为更大的数,会得到更好的拟合效果。我这里做了一组测试对比:可以明显看出,随着样本点数目的增多,拟合结果越来越逼近 y= -6*x+10这个标准答案了。
拟合结果对比 样本点数目ab5
-6.0153
10.6758
50
-5.9589
10.0761
500
-5.9856
9.9706
5000
-6.0021
10.0086
50000
-6.0002
10.0002
Original: https://blog.csdn.net/u010824101/article/details/122027055
Author: 布鲁斯度
Title: 使用python来完成数据的线性拟合
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/613470/
转载文章受原作者版权保护。转载请注明原作者出处!