

哈喽,大家好。
我们现在做数据分析的时候,不可避免地会与文本数据打交道,今天跟大家分享在数据分析中,如何挖掘出相似的文本。
本文从提出问题,到解决问题,再到算法原理三个方面来介绍。
1. 提出问题
假设在一个电商APP里,我们想要找出某款商品评价里,关于” 快递很差” 的评论,该怎么做?
如果只用字符串匹配的方式,你可能会遍历所有的评论,判断每条评论里是否包含” 快递很差“字符串。
但这种做法对下面几条评论就失效了
- 快递真差劲
- 快递一点不好
- 物流真差
所以,单纯的字符串匹配会漏掉很多评论。
2. 解决问题
要解决上面的问题,需要借助 潜在语义索引(Latent Semantic Indexing, 以下简称LSI) 算法。
LSI 算法可以挖掘相似文本,因此,通过 LSI 算法可以找到与” 快递很差“相似的评论。
下面我们以之前一篇文章《挖掘张同学视频评论主题》为例,实践 LSI 算法。
2.1 构建 LSI 模型
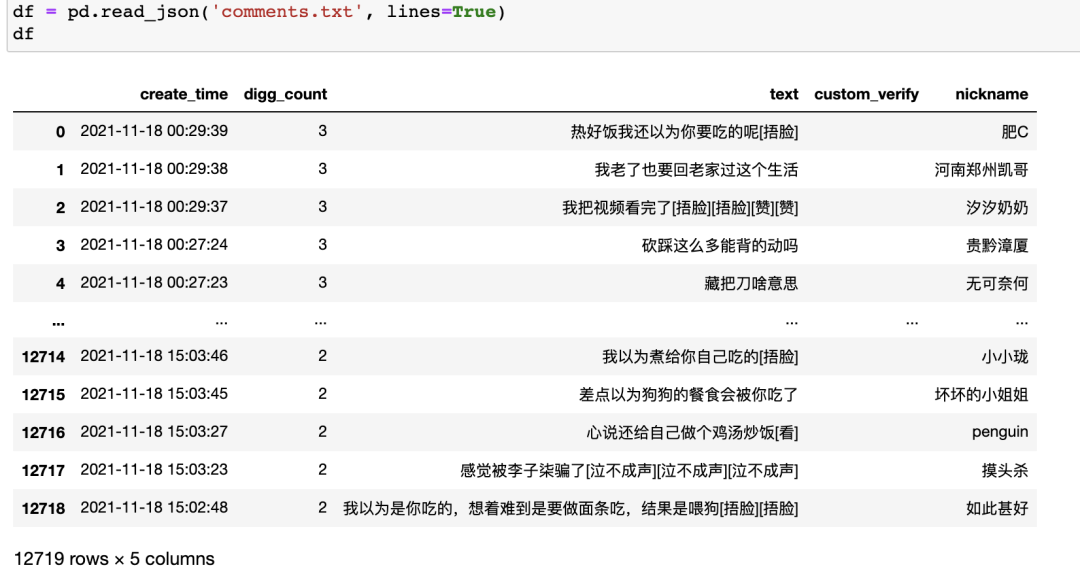

张同学视频评论
上篇文章抓取了张同学抖音视频 1.2w 条评论,对应上图 text 列。
首先,对评论分词,并去掉停用词。
origin_docs = df['text'].values
documents = [jieba.lcut(doc) for doc in origin_docs]
texts = [[word for word in doc if word not in filter_wrods] for doc in documents]

texts变量
然后,用 gensim构建评论词典,并统计每条评论中每个词出现的次数( 词频)。
from gensim import corpora, models, similarities
# 构建词典,给每个词编号
dictionary = corpora.Dictionary(texts)
# 每条评论里每个词的出现频次
corpus = [dictionary.doc2bow(text) for text in texts]

corpus变量
dictionary将 texts变量中的文本变成了数字编号。如: 热好 的编号为 0, 饭 的编号为 1。
doc2bow()中的 bow 是 Bag-of-Words的缩写,代表 词袋模型,该模型用来统计评论中的词频。
corpus变量与 texts变量相对应。 corpus[0]中的第一个元组 (0, 1)代表第一条评论中 热好一词的出现的次数是1,第二个元组 (1, 1)代表 饭出现的次数是1。
接着,构建 LSI 模型
lsi = models.LsiModel(
         corpus, 
         id2word=dictionary,
         power_iters=100,
         num_topics=10
)
num_topics是评论的主题数,上篇文章我们挖掘出来8个主题比较好, 这里我们设置的主题数是10个,稍微大一些对后面挖掘相似文本更好。
最后,构建每条评论 向量的索引,方便后面查询。
# lsi[corpus] 是所有评论对应的向量
index = similarities.MatrixSimilarity(lsi[corpus])  
2.2 查询相似文本
张同学的视频评论中,很多人都对”喂狗”镜头印象深刻。
下面我们来查询与” 以为自己吃,结果喂狗“相似的评论。 直销百晓生
query = '以为自己吃,结果喂狗'
# 词袋模型,统计词频
vec_bow = dictionary.doc2bow(jieba.lcut(query))
# 计算 query 对应的向量
vec_lsi = lsi[vec_bow]
# 计算每条评论与query的相似度
sims = index[vec_lsi] 
经过 LSI 处理后,每条评论都可以用 向量表示,同样的, query也可以用 向量表示。
所以, index[vec_lsi]其实是计算 向量之间的相似度,这里用的方法是 余弦相似度。结果越靠近1说明 query与该评论越相似。
下面按照相似度倒排,输出与 query相似的评论。
# 输出(原始文档,相似度)二元组
result = [(origin_docs[i[0]],i[1]) for i in enumerate(sims)]
# 按照相似度逆序排序
sorted(result ,key=lambda x: -x[1])
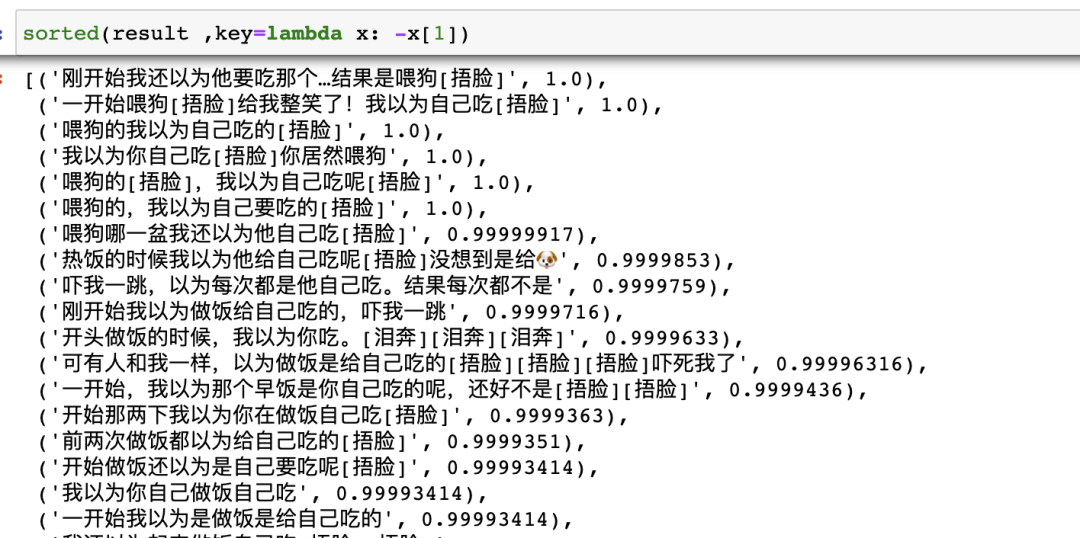
相似文本
可以看到,效果还是不错的,能够挖掘出很多相似的文本。
3. LSI 算法原理
LSI 与我们之前讲的 LDA 类似,都能用来计算每篇文本的主题。
LSI 是基于 奇异值分解(SVD)的方法来得到文本的主题的。SVD 的近似公式为:
其中,m代表所有评论中词的数量,n代表评论的条数,k代表分解后得到的主题数。
矩阵 对应n篇评论,每篇评论下有m个词。
矩阵 对应k个主题,每个主题下,m个词的概率分布。
矩阵 转置后是 n*k 的矩阵,对应 n 篇文档,每篇文档下,k 个主题的概率分布。
因此, 中每行其实就是每条评论的 向量,该矩阵对应到上述代码中,是 lsi[corpus]。
上面我们提到用 余弦相似度计算向量相似度。在高中数学中,两个向量的余弦相似度其实就是两个向量的夹角
- 夹角0度时,两向量重合(相等),相似度为1
- 夹角90度时,两向量垂直(不相关),相似度为0
- 夹角180度时,两向量反向,相似度为-1
到这里,基于 LSI 的相似文本挖掘就介绍完了。经过本篇的学习,你可以发现 LSI 不仅可以挖掘相似文本,甚至还可以做文本推荐、搜索引擎之类的事。
当然它也有缺点,有兴趣的朋友可以继续深入研究。
撰于 百晓生 www.lannakj.cn
Original: https://blog.csdn.net/qq_42766267/article/details/122117307
Author: 叶玄哥
Title: 数据分析中,用Python轻松挖掘相似评论(文本)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544934/
转载文章受原作者版权保护。转载请注明原作者出处!