

基础概念:
自然语言处理 (NLP) 是机器学习的一个子领域,它使计算机能够理解、分析、操纵和生成人类语言。
在本文中,小普将向您展示如何使用自然语言工具包 (NLTK) 开发您自己的 NLP 项目,但在我们深入本教程之前,让我们看一些 NLP 的日常用例。
NLP 机器学习示例
- 垃圾邮件过滤器
- 自动更正
- 预测文本
- 语音识别
- 信息检索
- 信息抽取
- 机器翻译
- 文字简化
- 情绪分析
- 文字摘要
- 查询响应
- 自然语言生成
NLP 入门
NLTK 是一个流行的 Python 库开源套件。NLTK 不是从头开始构建所有 NLP 工具,而是提供所有常见的 NLP 任务,因此您可以直接进入。在本教程中,我将向您展示如何执行基本的 NLP 任务并使用机器学习分类器来预测 SMS是垃圾邮件(有害的、恶意的或不需要的消息)
首先,您需要安装 NLTK。
键入 !pip install nltk在Jupyter笔记本。如果它在 cmd 中不起作用,请键入 conda install -c conda-forge nltk. 除此之外,您不需要进行太多的故障排除。
导入 NLTK 库
import nltk
nltk.download()
这段代码为我们提供了一个 NLTK 下载器应用程序,它对所有 NLP 任务都有帮助。
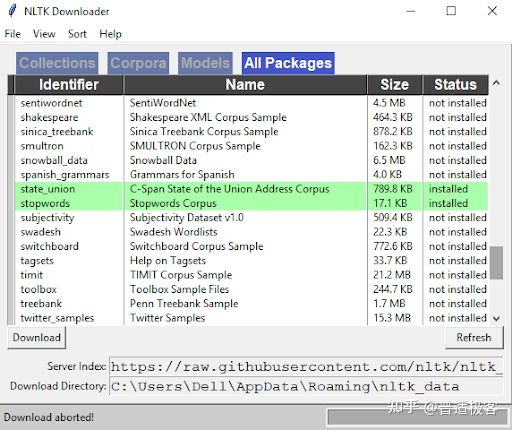

如您所见,已经在我的系统中安装了停用词语料库,它有助于删除多余的词。您还能够安装其他对您的项目有用的软件包。

为 NLP 准备数据
读取文本数据
我们的数据以结构化或非结构化格式提供给我们。结构化格式具有明确定义的模式。例如 Excel 和 Google Sheets 是结构化数据。或者,非结构化数据没有可辨别的模式(例如图像、音频文件、社交媒体帖子)。
在这两种数据类型之间,我们可能会发现我们有一种半结构化格式。语言是半结构化数据的一个很好的例子。

从上面的代码可以看出,当我们读取半结构化数据时,计算机(和人类!)很难解释。我们可以使用 Pandas 来帮助我们理解我们的数据。
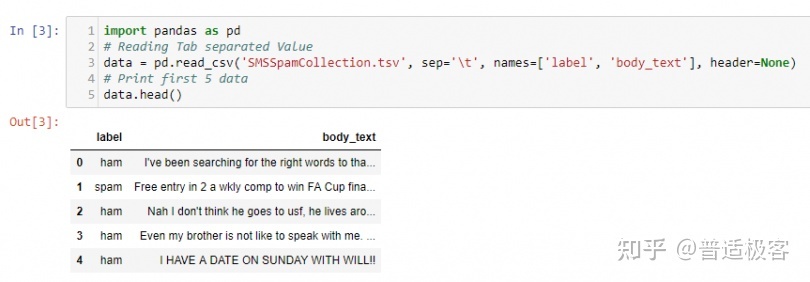
在 Pandas 的帮助下,我们现在可以更清楚地查看和解释我们的半结构化数据。
如何清理您的数据
清理文本数据对于突出我们希望机器学习系统获取的属性是必要的。清理(或预处理)数据通常包括三个步骤。
如何为 NLP 清理数据
- 删除标点符号
- 代币化
- 删除停用词
- 词干化
- 词形还原
1. 删除标点符号
标点符号可以为支持人类理解的句子提供语法上下文。但是对于我们的矢量化器,它计算单词的数量而不是上下文,标点符号不会增加价值。所以我们需要删除所有特殊字符。例如,”你好吗?” 变成:你好吗
如何实现的:
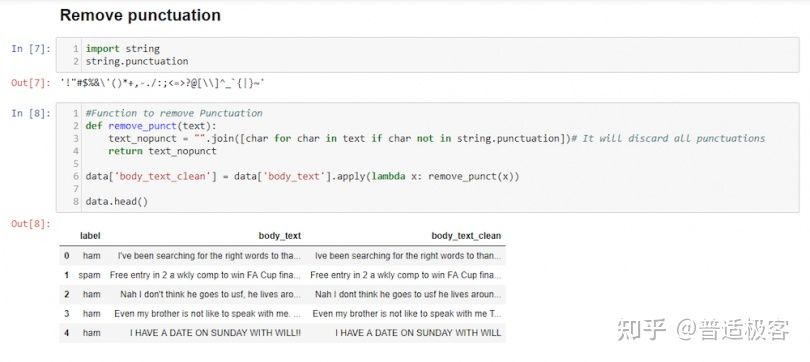
在 中 body_text_clean,您可以看到我们删除了所有标点符号。我已经变成了 Ive 并且 WILL!!成为意志。
2.代币化
标记化将文本分成句子或单词等单位。换句话说,此功能为以前的非结构化文本提供了结构。例如:Plata o Plomo 变成 ‘Plata’,’o’,’Plomo’。
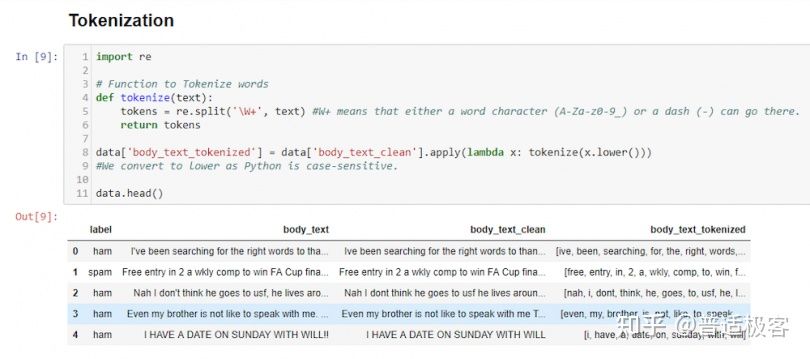
在 中 body_text_tokenized,我们已将所有单词生成为标记。
3. 删除停用词
停用词是可能出现在任何文本中的常用词。他们不会告诉我们太多关于我们的数据的信息,所以我们将其删除。同样,这些词对人类理解很有帮助,但会混淆您的机器学习程序。例如:银或铅对我来说很好变成了银,铅,很好。
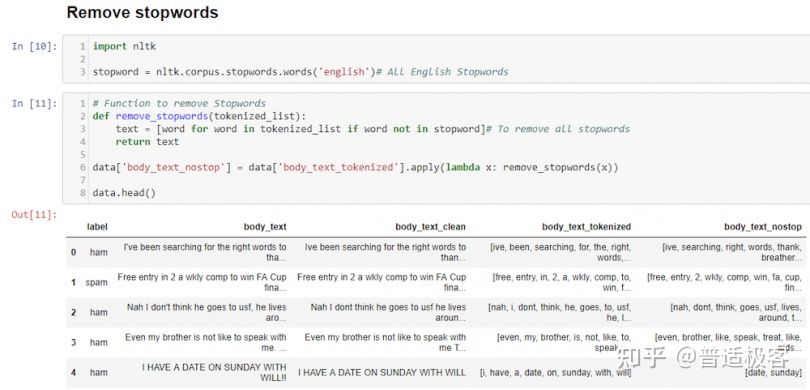
在 中 body_text_nostop,我们删除了所有不必要的词,例如”been”、”for”和”the”。
4. 词干化
词干化有助于将单词简化为词干形式。以相同的方式处理相关词通常是有意义的。它通过简单的基于规则的方法删除后缀,如”ing”、”ly”、”s”。从某种意义上说,词干减少了单词的语料库,但通常会丢失实际的单词。例如:”Entitling”或”Entitled”变成”Entitl”。
注意:某些搜索引擎将具有相同词干的单词视为同义词。
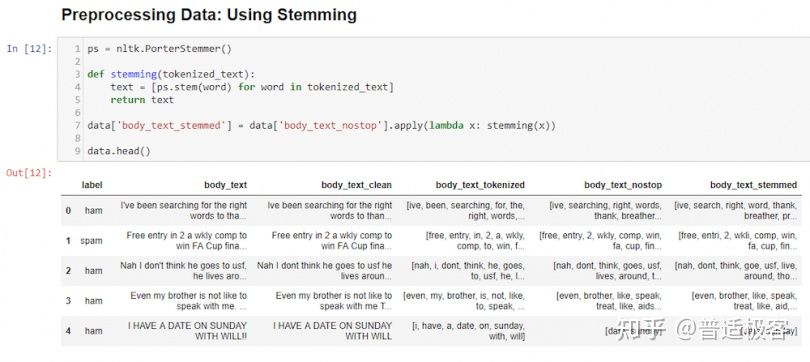
在 中 body_text_stemmed,entri 和 goe 之类的词的词干是 entri 和 goe,即使它们在英语中没有任何意义。
5. 词形还原
词形还原派生出一个词的词根形式(”引理”)。这种做法比词干提取更可靠,因为它对词根使用基于字典的方法(即形态分析)。例如,”Entitled”或”Entitled”变成”Entitle”。
简而言之,词干提取通常更快,因为它只是将单词的结尾切掉,但不了解单词的上下文。词形还原速度较慢但更准确,因为它需要对单词的上下文进行知情分析。
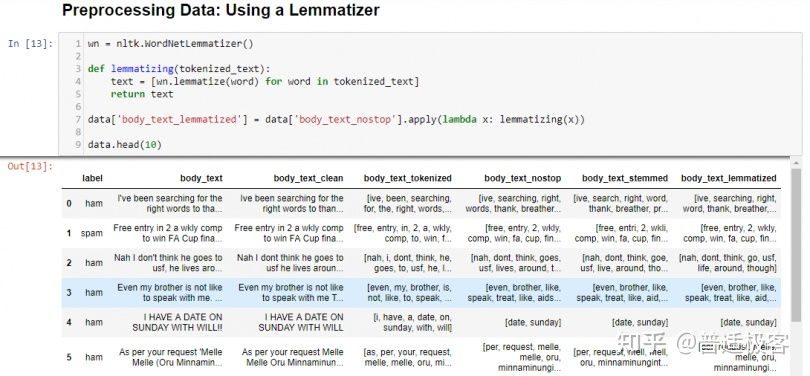
在 中 body_text_stemmed,我们可以看到像”chances”这样的词词形化为”chance”,但词干变为”chanc”。
矢量化数据
向量化是将文本编码为整数以创建特征向量以便机器学习算法可以理解语言的过程。
NLP 数据向量化方法
- Bag-of-Words (BoW) 或 CountVectorizer
- N-Grams
- TF-IDF
1. Bag-of-Words (BoW) 或 CountVectorizer
Bag-of-Words (BoW) 或 CountVectorizer 描述了文本数据中单词的存在。如果句子中存在,则此过程给出结果为 1,如果不存在则给出结果为 0。因此,该模型在每个文本文档中创建了一个带有文档矩阵计数的词袋。
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(analyzer=clean_text)
X_counts = count_vect.fit_transform(data['body_text'])
print(X_counts.shape)
print(count_vect.get_feature_names())
我们将 BoW 应用于 , body_text因此每个单词的计数都存储在文档矩阵中。
2. N-GRAM
N-gram 只是 n我们在源文本中找到的相邻单词或长度字母的所有组合。N-grams n=1被称为 unigrams, n=2是bigrams,等等。

与二元组或三元组相比,一元组通常不包含太多信息。N-grams 背后的基本原则是它们捕获哪个字母或单词可能跟在给定的单词之后。N-gram 越长(越高 n),你需要处理的上下文就越多。
from sklearn.feature_extraction.text import CountVectorizer
ngram_vect = CountVectorizer(ngram_range=(2,2),analyzer=clean_text) # It applies only bigram vectorizer
X_counts = ngram_vect.fit_transform(data['body_text'])
print(X_counts.shape)
print(ngram_vect.get_feature_names())
我们已将 N-Gram 应用于 body_text,因此句子中每组单词的计数存储在文档矩阵中。(检查回购)。
3. TF-IDF
TF-IDF 计算单词在文档中出现的相对频率与其在所有文档中的频率相比。对于识别每个文档中的关键词(该文档中的高频,其他文档中的低频),它比词频更有用。
注意:我们使用 TF-IDF 进行搜索引擎评分、文本摘要和文档聚类。查看我关于推荐系统的 文章 以了解有关 TF-IDF 的更多信息。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(analyzer=clean_text)
X_tfidf = tfidf_vect.fit_transform(data['body_text'])
print(X_tfidf.shape)
print(tfidf_vect.get_feature_names())
我们在 body_text 中应用了 TF-IDF,因此句子中每个单词的相对计数存储在文档矩阵中。(检查回购)。
注意:向量化器输出稀疏矩阵,其中大多数条目为零。为了高效存储,如果您只存储非零元素的位置,将存储一个稀疏矩阵。
特征工程
功能创建
特征工程是使用数据的领域知识来创建使机器学习算法起作用的特征的过程。因为特征工程需要领域知识,所以特征可能很难创建,但它们当然值得您花时间。

body_len显示消息正文中不包括空格的单词长度。punct%显示邮件正文中标点符号的百分比。
你的功能值得吗?
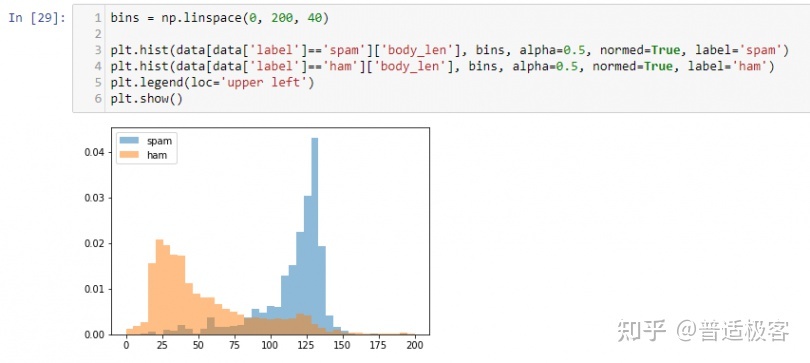
我们可以清楚地看到,与火腿相比,垃圾邮件的字数较多。所以 body_len是一个很好的特征来区分。
现在让我们来看看 punct%。
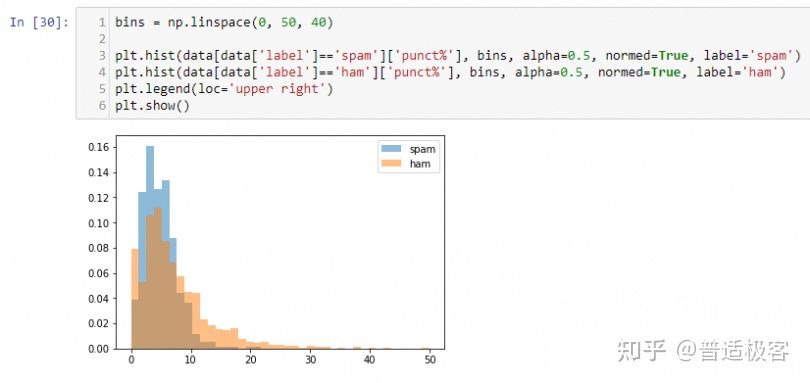
垃圾邮件的标点符号比例更高,但与火腿相差不远。鉴于垃圾邮件通常包含大量标点符号,这令人惊讶。尽管如此,鉴于明显的差异,我们仍然可以称其为有用的功能。
构建机器学习分类器
型号选择
我们使用机器学习的集成方法。通过协同使用多个模型,它们的组合产生比单个模型(例如支持向量机、朴素贝叶斯)更稳健的结果。集成方法是许多 Kaggle 比赛的首选。我们构建随机森林算法(即多个随机决策树)并使用每棵树的聚合体进行最终预测。此过程可用于分类和回归问题,并遵循随机装袋策略。
- 网格搜索:该模型详尽地搜索给定网格中的整体参数组合以确定最佳模型。
- 交叉验证:该模型将一个数据集划分为 k 个子集,并重复该方法 k 次。该模型在每次迭代中也使用不同的子集作为测试集。
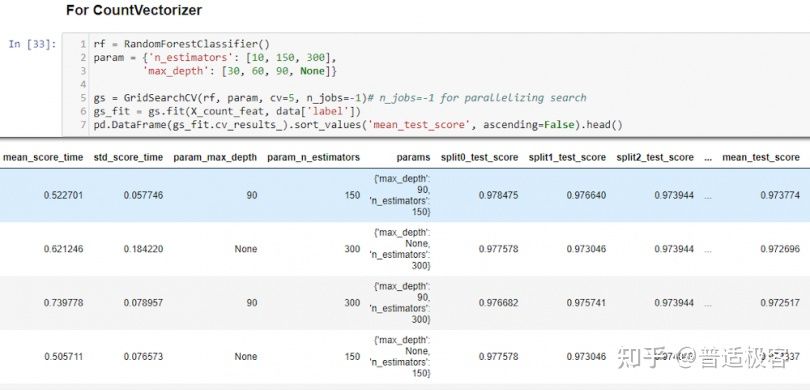
在 mean_test_score为 n_estimators=150和 max_depth提供了最好的结果。这里, n_estimators是森林中的树(决策树组) max_depth的数量,是每个决策树中的最大级别数。
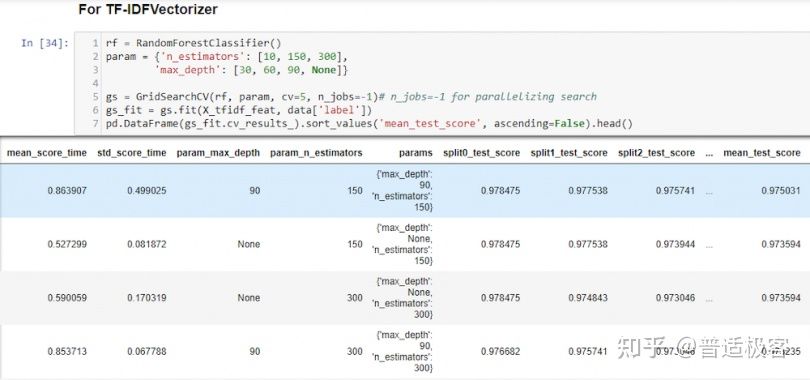
同样, mean_test_scorefor n_estimators=150和 max_depth=90给出最好的结果。
未来的改进
您可以使用 GradientBoosting、XgBoost 进行分类。GradientBoosting 需要一段时间,因为它采用迭代方法,通过组合弱学习器来创建强学习器,从而专注于先前迭代的错误。简而言之,与随机森林相比,GradientBoosting 遵循顺序方法而不是随机并行方法。
以上就是本次小普分享的全部内容,喜欢的小伙伴可以点点赞,收藏,让更多人看到你喜欢的东西。最后,祝大家工作顺利,生活如意。
Original: https://blog.csdn.net/PUSHIAI/article/details/121270989
Author: 极客小普冲呀
Title: 如何使用工具包 (NLTK) 开发NLP 项目?(附教程)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531780/
转载文章受原作者版权保护。转载请注明原作者出处!