

Flink快速入门之批计算的WordCount案例
原创
wx62be9d88ce294博主文章分类:大数据 ©著作权
文章标签 flink scala big data apache 文章分类 Hadoop 大数据
©著作权归作者所有:来自51CTO博客作者wx62be9d88ce294的原创作品,请联系作者获取转载授权,否则将追究法律责任
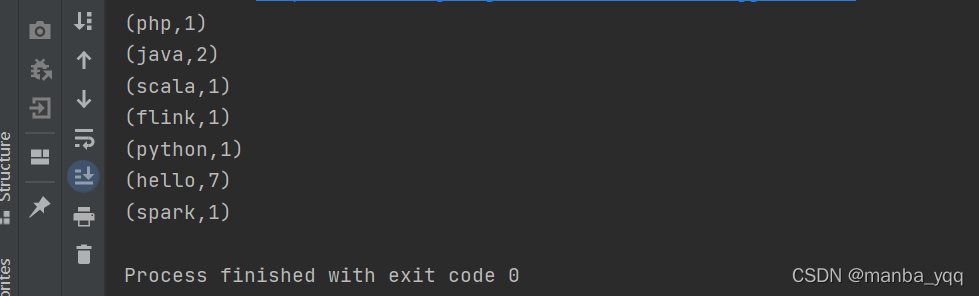
数据源wc.txt
hello sparkhello flinkhello javahello javahello phphello pythonhello scala
package streamimport org.apache.flink.api.scala.ExecutionEnvironment object BatchWordCount { def main(args: Array[String]): Unit = { val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ val set: DataSet[String] = environment.readTextFile("data/wc.txt") set.flatMap(_.split(" ")) .map((_,1)) .groupBy(0) .sum(1) .print() }}

- 赞
- 收藏
- 评论
- *举报
上一篇:Flink 的特点和优势
Original: https://blog.51cto.com/u_15704423/5434838
Author: wx62be9d88ce294
Title: Flink快速入门之批计算的WordCount案例
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516982/
转载文章受原作者版权保护。转载请注明原作者出处!